
微博為何讓人上癮?幕後推薦演算法解密

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-10 18:21:03971瀏覽
2021年7月13日,勞累了一天的年輕人們,正準備躺平拿出手機,打開那熟悉的小破站App,一鍵三連自己最喜愛的up主的最新視頻。
結果突然發現,自己的眼前一黑:

#時隔一年,B站終於揭曉了這其中的奧秘:一個「詭計多端的0」。

不過,你有沒有想過,就算是經歷著用戶的瘋狂湧入,為啥這個微博,它沒崩呢?

AI和微博有啥關係?
在揭開這個謎底之前,還需要從人工智慧的發展說起。
7月27日,由中國網路協會指導、微博和新浪新聞主辦的「融合生態 價值共創」2022新智者大會順利召開。
在「智驅萬物:AI推動萬物互聯的加速到來」議題中,微博COO、新浪移動CEO、新浪AI媒體研究院院長王巍發表了題為《雲端為數智技術融合應用賦能微博複雜業務場景》的主題演講。
#王巍表示,如果我們回顧機器學習的發展歷程,可以看出AI的整體發展趨勢為:訓練資料的海量化及多樣化,AI模型的複雜化及通用化,算力的高效化及規模化。

第一,是多模態資料融合。
隨著5G的快速發展,圖片、影片類型模態內容在網路內容中佔比越來越高,所以進行模態融合非常必要。
對微博來說,如果能同時對文字、圖片、影片進行多模態融合,也就可以更理解這條微博所講的內容了。
第二,是超大規模圖計算。
相對其他機器學習模型,超大規模圖運算有個特殊的優點:透過資訊在網路中的傳遞,促進資訊的流動、匯聚與整合。
例如對於行為少的冷啟動用戶,我們可以透過他關注清單中的人,以及這些人發布的內容,透過資訊傳播來推導這個用戶的興趣。

第三,是AI研發的啞鈴模式。
目前的AI研發重點,一個是越來越大的超級大模型,一個是模型小型化技術。
我們都知道,目前隨著模型參數規模越來越大,模型效果越來越好,高精度模型仍在持續增大,例如2018年Google的Bert剛出來的時候,模型參數規模是3億,不算太大,但之後這個數字一直在快速成長。
OpenAI研發的GPT-2模型,參數規模15億,GPT-3模型,參數規模1750億,而到了2021年Google發布的Switch Transformer,參數規模已經達到了1.6兆。

另一方面,雖然說模型越大效果越好,但是因為模型過大,有時會導致無法讓實際應用落地。所以研發的另一個重點,就是將這些大模型小型化、輕量化,例如模型蒸餾、模型剪枝等技術。
第四,是AI模型從專用模型走向通用模型。
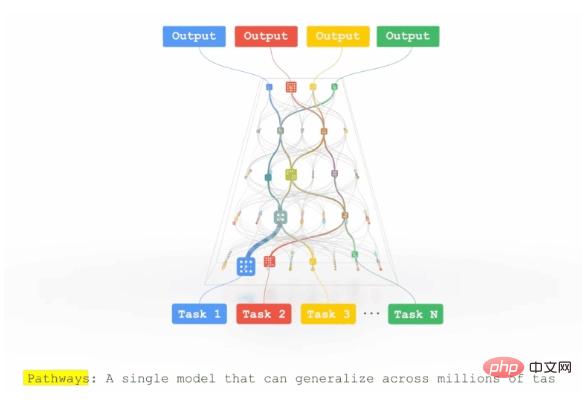
Google在2021年下半年公開了Pathways模型框架,首先提出了這個構想,希望透過建構一個通用的大模型,達到「一個模型做千萬件事」的目標。
具體的想法是,不同任務資料輸入後,透過路由演算法,選擇神經網路的部分路徑,到達模型輸出層。不同任務既有參數共享,也有任務獨有的模型參數。
10億節點 100億邊的超大規模圖
為何講了這麼半天機器學習?因為接下來要登場的,就是「微博特色推薦系統」了。
眾所周知,作為國內最大的社群媒體網絡,微博目前的月活用戶已經達到5.82億了!這樣大的使用者規模,必然會讓微博上的網路環境十分複雜。
再加上內容時效性強、多元性高,現在的網路大事都會第一時間在微博上引爆。
另外,微博面臨的場景還很多元化,需要在關係流、熱點流、視訊串流等眾多場景中給用戶分發他們感興趣的「千人千面”的內容。

我可以沒有手指,但不能沒有手機
面對複雜的業務場景,微博是怎麼透過AI和大數據,做出能隨機應變的推薦系統的呢?
王巍向我們介紹說,微博推薦系統整體由三個部分構成:內容理解、使用者理解,以及推薦系統。
首先,是內容理解。
如果要想搞清楚一個微博到底在說什麼,僅僅理解文本內容是不夠的,必須採用多模態理解技術,融合博文、圖片、視頻等多種媒體資訊。
為此,微博訓練了自己的微博多模態預訓練模型,透過「對比學習」,用這種自監督學習方法,來進行多模態預訓練。
下圖的這例子就展示了微博是怎麼利用自帶的「話題」來自動建構訓練資料的。

例如,我們把兩個都寫著「訓練中的拉什福德」的微博當作正例,隨機選擇一些不同話題的微博作為負例,這樣就能自動建構訓練資料。
對於某條微博,其中的文字內容透過Bert編碼,影像和影片內容透過ViT編碼,然後透過fusion子網路進行資訊融合,形成微博的embedding編碼。這就是一種預訓練過程。
經過預先訓練,學好的微博編碼器可以拿來對新的微博內容進行多模態編碼,形成embedding,應用在推薦等下游任務中。
其次,在用戶理解方面,微博採取了超大規模圖計算,來更好地理解用戶的閱讀興趣。 畢竟微博自備社群媒體屬性,天然地就和大規模圖計算非常匹配。
利用使用者和部落格文章作為圖中的節點,以使用者間的關注關係、使用者和部落格文章的閱讀及轉評讚等互動行為建構圖中的邊,微博建立起了包含10億規模節點、100億規模邊的超大規模圖。
透過大規模圖計算中的信息傳播、匯聚和集成,形成表徵用戶興趣的embedding向量,可以更好地理解用戶興趣。
如此一來,也就可以同時搞定用戶之間的關注關係、用戶和博文的轉評讚等等的互動行為了。
在了解使用者在講什麼、了解微博使用者的興趣之後,微博推薦系統就會將高品質的微博,個人化地分發給有興趣的使用者。
那麼,如何在這種複雜場景下建構高效率的推薦系統呢?
微博採取的是採取了多場景建模的方式。最理想的情況是,只建立一個推薦模型,用它來服務多個場景。
那麼如何表示場景間的共通性和個性呢?可透過網路參數在場景間共享,或是場景自行獨享私有網路參數,體現場景的共通性與個性。

例如這張模型圖,在模型的底層特徵輸入層,以及網路中間的一部分「專家子網路」,這些網路參數是各個場景共享的;而其他子網路參數則是某個場景所獨有的
#透過這種方式,就能夠透過一個模型服務多個場景,節省模型資源。
唐山事件:流量暴漲一倍怎麼辦?
現在,說回到最初的那個「懸念」上來。
對於微博來說,這個保不齊什麼時候就會「炸」的熱點,一直以來都是非常大的挑戰。
例如,最近全民關注的「唐山事件」,事件當天的熱點流量,比日常流量高峰翻了整整一倍。

對此王巍表示,微博在很早就應用了微服務Docker容器化技術,不僅提升服務運維的效率,而且也實現了服務動態擴縮容能力。目前,微博已經具備了10分鐘調度超過一萬台的擴容能力,可以有足夠的伺服器來應付熱點流量。
此外,微博也建立了熱點監控機制和熱點連動體系,並透過微博自研的Weibo Mesh技術,實現不同服務間跨語言的高效調用,提升整體服務的性能,和連動擴容效率。
最後,微博採用了在離線即時混合部署技術。利用CPU即時搶佔式調度技術與容器化技術結合,實現微博服務在離線即時混合部署能力。

綜合了上面這些操作之後,在有熱點流量來襲時,就可以秒級承接核心服務的熱點流量了。最後,讓我們再來回顧下網路的發展歷程。
如果說PC互聯網是網路世界的開端,那麼行動互聯網的興起則讓我們將這無形的資訊空間裝進了口袋。隨著大數據、雲端運算、人工智慧等技術與行動互聯網的疊加融合,我們進入了智慧資訊時代。
而現在,最火的話題就要數元宇宙了。從去年開始,元宇宙就引發了廣泛的討論,例如數位孿生、數位人、XR、區塊鏈技術等。
王巍認為,目前基於AI、區塊鏈、XR等尖端技術的應用場景,已經體現了一些元宇宙的雛形。諸如遊戲、社交等領域,都是元宇宙非常好的應用場景,會引爆大家參與元宇宙的熱情。
以上是微博為何讓人上癮?幕後推薦演算法解密的詳細內容。更多資訊請關注PHP中文網其他相關文章!