|
|
#模型 |
發佈時間 |
層數 |
#頭數 |
|
|
詞向量長度 |
參數量 |
預訓練資料量################################################## ##GPT-1############2018 年6 月############12###########12### |
768 |
1.17 億 |
約5GB |
GPT-2 |
2019 年2 月 |
48 |
- |
1600 |
15 億 |
40GB |
GPT-3 |
2020 年5 月 |
96 |
##96
|
12888
|
1,750 億
| ##45TB |
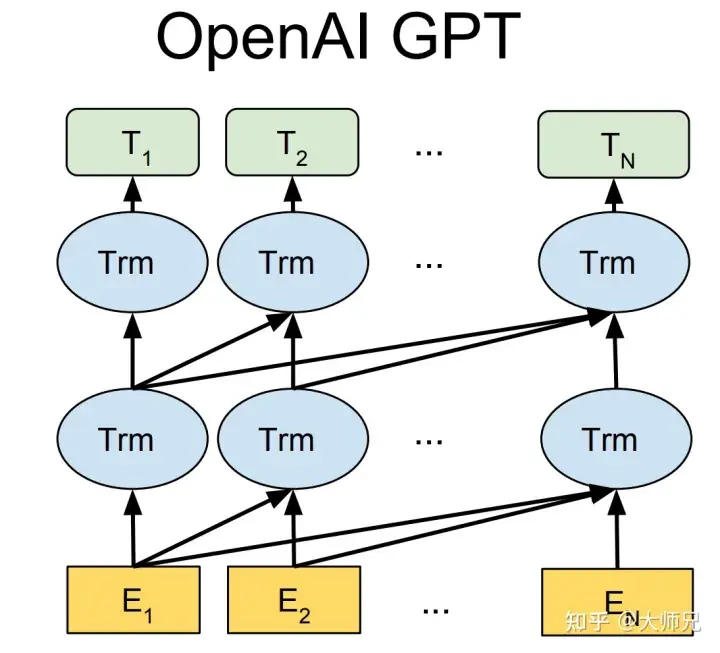
##GPT-1比BERT出生略早幾個月。它們都是採用了Transformer為核心結構,不同的是GPT-1透過自左向右生成式的建構預訓練任務,然後得到一個通用的預訓練模型,這個模型和BERT一樣都可用來做下游任務的微調。 GPT-1當時在9個NLP任務上取得了SOTA的效果,但GPT-1所使用的模型規模和資料量都比較小,這也促使了GPT-2的誕生。
比較GPT-1,GPT-2並未在模型結構上大作文章,只是使用了更多參數的模型和更多的訓練資料(表1)。 GPT-2最重要的想法是提出了「所有的監督學習都是無監督語言模型的一個子集」的思想,這個思想也是提示學習(Prompt Learning)的前身。 GPT-2在誕生之初也引發了不少的轟動,它產生的新聞足以欺騙大多數人類,達到以假亂真的效果。甚至當時被稱為“AI界最危險的武器”,許多門戶網站也命令禁止使用GPT-2產生的新聞。
GPT-3被提出時,除了它遠超GPT-2的效果外,引起更多討論的是它1750億的參數量。 GPT-3除了能完成常見的NLP任務外,研究者意外的發現GPT-3在寫SQL,JavaScript等語言的程式碼,進行簡單的數學運算上也有不錯的表現效果。 GPT-3的訓練使用了情境學習(In-context Learning),它是元學習(Meta-learning)的一種,元學習的核心思想在於透過少量的資料尋找一個合適的初始化範圍,使得模型能夠在在有限的資料集上快速擬合,並獲得不錯的效果。
透過上面的分析我們可以看出從性能角度上講,GPT有兩個目標:
- #提升模型在常見NLP任務上的表現效果;
- 提升模型在其他非典型NLP任務(例如程式碼編寫,數學運算)上的泛化能力。
另外,預訓練模型自誕生之始,一個備受批評的問題就是預訓練模型的偏見性。因為預訓練模型都是透過海量資料在超大參數量級的模型上訓練出來的,對比完全由人工規則控制的專家系統來說,預訓練模型就像一個黑盒子。沒有人能夠保證預訓練模型不會產生一些包含種族歧視,性別歧視等危險內容,因為它的幾十GB甚至幾十TB的訓練資料裡幾乎肯定包含類似的訓練樣本。這也就是InstructGPT和ChatGPT的提出動機,論文中用3H概括了它們的最佳化目標:
- 有用的(Helpful);
- #可信的(Honest);
- 無害的(Harmless)。
OpenAI的GPT系列模型並沒有開源,但是它們提供了模型的試用網站,有條件的同學可以自行試用。
1.2 指示學習(Instruct Learning)和提示(Prompt Learning)學習
指示學習是GoogleDeepmind的Quoc V.Le團隊在2021年的一篇名為《Finetuned Language Models Are Zero-Shot Learners》[5]文章中提出的想法。指示學習和提示學習的目的都是去挖掘語言模式本身所具備的知識。不同的是Prompt是激發語言模型的補全能力,例如根據上半句產生下半句,或是完形填空等。 Instruct是激發語言模型的理解能力,它透過給予更明顯的指令,讓模型去做出正確的行動。我們可以透過下面的例子來理解這兩個不同的學習方式:
- 提示學習:給女朋友買了這個項鍊,她很喜歡,這個項鍊太____了。
- 指示學習:判斷這句話的情感:給女朋友買了這個項鍊,她很喜歡。選項:A=好;B=一般;C=差。
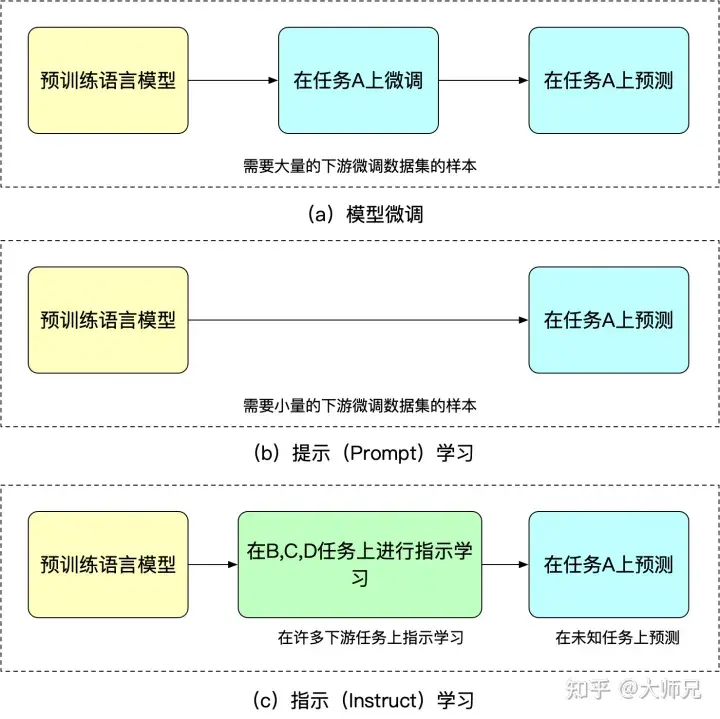
指示學習的優點是它經過多任務的微調後,也能夠在其他任務上做zero-shot,而提示學習都是針對一個任務的。泛化能力不如指示學習。我們可以透過圖2來理解微調,提示學習和指示學習。

圖2:模型微調,提示學習,指示學習三者的異同
1.3 人工回饋的強化學習
因為訓練得到的模型並不是非常可控制的,模型可以看做訓練集分佈的一個擬合。那麼回饋到生成模型中,訓練資料的分佈便是影響生成內容的品質最重要的因素。有時候我們希望模型並非只受訓練資料的影響,而是人為可控的,從而保證產生資料的有用性,真實性和無害性。論文中多次提到了對齊(Alignment)問題,我們可以理解為模型的輸出內容和人類喜歡的輸出內容的對齊,人類喜歡的不止包括生成內容的流暢性和語法的正確性,還包括生成內容的有用性、真實性和無害性。
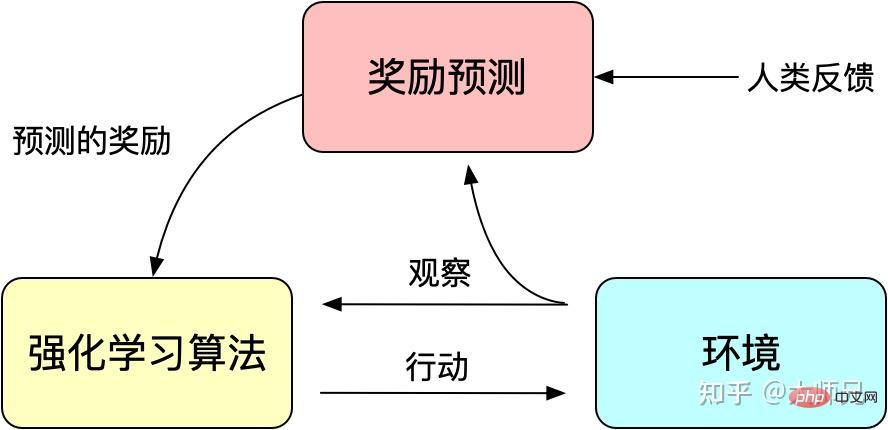
我們知道強化學習透過獎勵(Reward)機制來引導模型訓練,獎勵機制可以看做傳統模訓練機制的損失函數。獎勵的計算要比損失函數更靈活和多樣(AlphaGO的獎勵是對局的勝負),這帶來的代價是獎勵的計算是不可導的,因此不能直接拿來做反向傳播。強化學習的想法是透過對獎勵的大量取樣來擬合損失函數,從而實現模型的訓練。同樣人類回饋也是不可導的,那麼我們也可以將人工回饋視為強化學習的獎勵,基於人工回饋的強化學習便應運而生。
RLHF最早可以追溯到Google在2017年發表的《Deep Reinforcement Learning from Human Preferences》[6],它透過人工標註作為回饋,提升了強化學習在模擬機器人以及雅達利遊戲上的表現效果。
圖3:人工回饋的強化學習的基本原理
InstructGPT/ChatGPT中也用到了強化學習中一個經典的演算法:OpenAI提出的最近策略優化(Proximal Policy Optimization,PPO)[7]。 PPO演算法是一種新型的Policy Gradient演算法,Policy Gradient演算法對步長十分敏感,但是又難以選擇合適的步長,在訓練過程中新舊策略的變化差異如果過大則不利於學習。 PPO提出了新的目標函數可以在多個訓練步驟中實現小批量的更新,解決了Policy Gradient演算法中步長難以確定的問題。其實TRPO也是為了解決這個想法但是比起TRPO演算法PPO演算法更容易求解。
2. InstructGPT/ChatGPT原理解讀
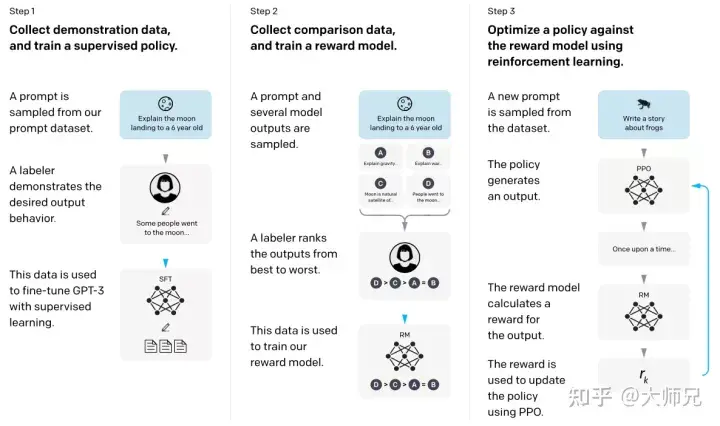
有了上面這些基礎知識,我們再去了解InstructGPT和ChatGPT就會簡單很多。簡單來說,InstructGPT/ChatGPT都是採用了GPT-3的網路結構,透過指示學習建構訓練樣本來訓練一個反應預測內容效果的獎勵模型(RM),最後透過這個獎勵模型的評分來引導強化學習模型的訓練。 InstructGPT/ChatGPT的訓練流程如圖4所示。
圖4:InstructGPT的計算流程:(1)有監督微調(SFT);(2)獎勵模型(RM)訓練;(3)透過PPO根據獎勵模型進行強化學習。
從圖4我們可以看出,InstructGPT/ChatGPT的訓練可以分成3步,其中第2步和第3步是的獎勵模型和強化學習的SFT模型可以重複迭代優化。
- 根據所擷取的SFT資料集對GPT-3進行有監督的微調(Supervised FineTune,SFT);
- 收集人工標註的對比數據,訓練獎勵模型(Reword Model ,RM);
- 使用RM作為強化學習的最佳化目標,利用PPO演算法微調SFT模型。
根據圖4,我們將分別介紹InstructGPT/ChatGPT的資料集擷取和模型訓練兩個面向的內容。
2.1 資料集擷取
如圖4所示,InstructGPT/ChatGPT的訓練分成3步,每一步所需的資料也有些許差異,以下我們分別介紹它們。
2.1.1 SFT數據集
SFT數據集是用來訓練第1步有監督的模型,即使用採集的新數據,按照GPT-3的訓練方式對GPT- 3進行微調。因為GPT-3是一個基於提示學習的生成模型,因此SFT資料集也是由提示-答案對組成的樣本。 SFT資料一部分來自使用OpenAI的PlayGround的用戶,另一部分來自OpenAI僱用的40名標註工(labeler)。並且他們對labeler進行了培訓。在這個資料集中,標註工的工作是根據內容自己寫指示,並且要求所寫的指示滿足下面三點:
- 簡單任務:labeler給予任一簡單的任務,同時確保任務的多樣性;
- Few-shot任務:labeler給予一個指示,以及該指示的多個查詢-對應對;
- 使用者相關的:從介面中取得用例,然後讓labeler根據這些用例編寫指示。
2.1.2 RM資料集
RM資料集用來訓練步驟2的獎勵模型,我們也需要為InstructGPT/ChatGPT的訓練設定一個獎勵目標。這個獎勵目標不必可導,但是一定要盡可能全面且真實的對齊我們需要模型產生的內容。很自然的,我們可以透過人工標註的方式來提供這個獎勵,透過人工對可以給那些涉及偏見的生成內容更低的分從而鼓勵模型不去生成這些人類不喜歡的內容。 InstructGPT/ChatGPT的做法是先讓模型產生一批候選文本,讓後透過labeler根據產生資料的品質對這些生成內容進行排序。
2.1.3 PPO資料集
InstructGPT的PPO資料沒有進行標註,它皆來自GPT-3的API的使用者。既不同使用者提供的不同種類的生成任務,其中佔比最高的包括生成任務(45.6%),QA(12.4%),腦力激盪(11.2%),對話(8.4%)等。
2.1.4 資料分析
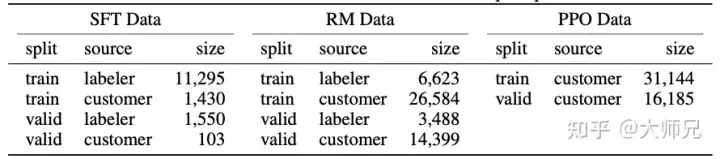
因為InstructGPT/ChatGPT是在GPT-3基礎上做的微調,而且因為涉及了人工標註,它們資料總量並不大,表2展示了三份資料的來源及其資料量。
表2:InstructGPT的資料分佈
論文的附錄A對資料的分佈進行了更詳細的討論,這裡我列出幾個可能影響模型效果的幾項:
- 資料中96%以上是英文,其它20個語種例如中文,法語,西班牙語等加起來不到4%,這可能導致InstructGPT/ChatGPT能進行其它語種的生成,但效果應該遠不如英文;
- 提示種類共有9種,而且絕大多數是生成類任務,可能會導致模型有覆蓋不到的任務類型;
- 40名外包員工來自美國和東南亞,分佈比較集中且人數較少, InstructGPT/ChatGPT的目標是訓練一個價值觀正確的預訓練模型,它的價值觀是由這40個外包員工的價值觀組合而成。而這個比較窄的分佈可能會產生一些其他地區比較在意的歧視,偏見問題。
此外,ChatGPT的部落格中講到ChatGPT和InstructGPT的訓練方式相同,不同點僅僅是它們採集資料上有所不同,但是並沒有更多的資料來講資料擷取上有哪些細節上的不同。考慮到ChatGPT僅被用在對話領域,這裡我猜測ChatGPT在資料收集上有兩個不同:1. 提高了對話類任務的佔比;2. 將提示的方式轉換Q&A的方式。當然這裡也只是猜測,更準確的描述要等到ChatGPT的論文、源碼等更詳細的資料公佈我們才能知道。
2.2 訓練任務
我們剛剛介紹到InstructGPT/ChatGPT有三步驟訓練方式。這三步驟訓練會涉及三個模型:SFT,RM以及PPO,以下我們將詳細介紹它們。
2.2.1 有監督微調(SFT)
這一步的訓練和GPT-3一致,而且作者發現讓模型適當過擬合有助於後面兩步的訓練。
2.2.2 獎勵模型(RM)
因為訓練RM的資料是一個labeler根據生成結果排序的形式,所以它可以看做一個迴歸模型。 RM結構是將SFT訓練後的模型的最後的嵌入層去掉後的模型。它的輸入是prompt和Reponse,輸出是獎勵值。具體的講,對弈每個prompt,InstructGPT/ChatGPT會隨機產生K 個輸出( 4≤K≤9 ),然後它們向每個labeler成對的展示輸出結果,也就是每個prompt共展示CK2 個結果,然後使用者從中選擇效果更好的輸出。在訓練時,InstructGPT/ChatGPT將每個prompt的CK2 個響應對作為一個batch,這種按prompt為batch的訓練方式要比傳統的按樣本為batch的方式更不容易過擬合,因為這種方式每個prompt會且僅會輸入到模型中一次。
獎勵模型的損失函數表示為式(1)。這個損失函數的目標是最大化labeler偏好的響應和不喜歡的響應之間的差異。
(1)loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)) )]
其中 rθ(x,y) 是提示 x 和回應 y 在參數為 θ 的獎勵模型下的獎勵值, yw 是labeler偏好的反應結果, yl 是labeler不喜歡的反應結果。 D 是整個訓練資料集。
2.2.3 強化學習模式(PPO)
強化學習與預訓練模式是最近兩年最為火熱的AI方向之二,之前不少科研工作者說強化學習並不是一個非常適合應用到預訓練模型中,因為很難透過模型的輸出內容建立獎勵機制。而InstructGPT/ChatGPT反直覺的做到了這一點,它透過結合人工標註,將強化學習引入到預訓練語言模型是這個演算法最大的創新點。
如表2所示,PPO的訓練集完全來自API。它透過第2步驟得到的獎勵模型來指導SFT模型的繼續訓練。很多時候強化學習是非常難訓練的,InstructGPT/ChatGPT在訓練過程中就遇到了兩個問題:
- 問題1:隨著模型的更新,強化學習模型產生的資料和訓練獎勵模型的數據的差異會越來越大。作者的解決方案是在損失函數中加入KL懲罰項 βlog(πϕRL(y∣x)/πSFT(y∣x)) 來確保PPO模型的輸出和SFT的輸出差距不會很大。
- 問題2:只用PPO模型進行訓練的話,會導致模型在通用NLP任務上表現的大幅下降,作者的解決方案是在訓練目標中加入了通用的語言模型目標γEx∼Dpretrain [ log(πϕRL(x))] ,這個變數在論文中被叫做PPO-ptx。
綜上,PPO的訓練目標為式(2)。 (2) objective (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))] γEx∼Dpretrain [log(πϕRL (x))]
3. InstructGPT/ChatGPT的性能分析
不可否認的是,InstructGPT/ChatGPT的效果是非常棒的,尤其是引入了人工標註之後,讓模型的「價值觀」和的正確程度和人類行為模式的「真實性」上都大幅的提升。那麼,僅僅根據InstructGPT/ChatGPT的技術方案和訓練方式,我們就可以分析出它可以帶來哪些效果提升呢?
3.1 优点
- InstructGPT/ChatGPT的效果比GPT-3更加真实:这个很好理解,因为GPT-3本身就具有非常强的泛化能力和生成能力,再加上InstructGPT/ChatGPT引入了不同的labeler进行提示编写和生成结果排序,而且还是在GPT-3之上进行的微调,这使得我们在训练奖励模型时对更加真实的数据会有更高的奖励。作者也在TruthfulQA数据集上对比了它们和GPT-3的效果,实验结果表明甚至13亿小尺寸的PPO-ptx的效果也要比GPT-3要好。
- InstructGPT/ChatGPT在模型的无害性上比GPT-3效果要有些许提升:原理同上。但是作者发现InstructGPT在歧视、偏见等数据集上并没有明显的提升。这是因为GPT-3本身就是一个效果非常好的模型,它生成带有有害、歧视、偏见等情况的有问题样本的概率本身就会很低。仅仅通过40个labeler采集和标注的数据很可能无法对模型在这些方面进行充分的优化,所以会带来模型效果的提升很少或者无法察觉。
- InstructGPT/ChatGPT具有很强的Coding能力:首先GPT-3就具有很强的Coding能力,基于GPT-3制作的API也积累了大量的Coding代码。而且也有部分OpenAI的内部员工参与了数据采集工作。通过Coding相关的大量数据以及人工标注,训练出来的InstructGPT/ChatGPT具有非常强的Coding能力也就不意外了。
3.2 缺点
- InstructGPT/ChatGPT会降低模型在通用NLP任务上的效果:我们在PPO的训练的时候讨论了这点,虽然修改损失函数可以缓和,但这个问题并没有得到彻底解决。
- 有时候InstructGPT/ChatGPT会给出一些荒谬的输出:虽然InstructGPT/ChatGPT使用了人类反馈,但限于人力资源有限。影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用。所以很有可能受限于纠正数据的有限,或是有监督任务的误导(只考虑模型的输出,没考虑人类想要什么),导致它生成内容的不真实。就像一个学生,虽然有老师对他指导,但也不能确定学生可以学会所有知识点。
- 模型对指示非常敏感:这个也可以归结为labeler标注的数据量不够,因为指示是模型产生输出的唯一线索,如果指示的数量和种类训练的不充分的话,就可能会让模型存在这个问题。
- 模型对简单概念的过分解读:这可能是因为labeler在进行生成内容的比较时,倾向于给给长的输出内容更高的奖励。
- 对有害的指示可能会输出有害的答复:例如InstructGPT/ChatGPT也会对用户提出的“AI毁灭人类计划书”给出行动方案(图5)。这个是因为InstructGPT/ChatGPT假设labeler编写的指示是合理且价值观正确的,并没有对用户给出的指示做更详细的判断,从而会导致模型会对任意输入都给出答复。虽然后面的奖励模型可能会给这类输出较低的奖励值,但模型在生成文本时,不仅要考虑模型的价值观,也要考虑生成内容和指示的匹配度,有时候生成一些价值观有问题的输出也是可能的。
图5:ChatGPT编写的毁灭人类计划书。
3.3 未来工作
我们已经分析了InstrcutGPT/ChatGPT的技术方案和它的问题,那么我们也可以看出InstrcutGPT/ChatGPT的优化角度有哪些了。
- 人工標註的降本增效:InstrcutGPT/ChatGPT僱用了40人的標註團隊,但從模型的表現效果來看,這40人的團隊是不夠的。如何讓人類能夠提供更有效的回饋方式,將人類表現和模型表現有機和巧妙的結合起來是非常重要的。
- 模型對指示的泛化/糾錯等能力:指示作為模型產生輸出的唯一線索,模型對他的依賴是非常嚴重的,如何提升模型對指示的泛化能力以及對錯誤指示示的糾錯能力是提升模型體驗的一個非常重要的工作。這不僅可以讓模型能夠擁有更廣泛的應用場景,還可以讓模型變得更「智慧」。
- 避免通用任務表現下降:這裡可能需要設計一個更合理的人類回饋的使用方式,或是更前沿的模型結構。因為我們討論了InstrcutGPT/ChatGPT的許多問題可以透過提供更多labeler標註的資料來解決,但這會導致通用NLP任務更嚴重的效能下降,所以需要方案來讓產生結果的3H和通用NLP任務的效能達到平衡。
3.4 InstrcutGPT/ChatGPT的熱門話題解答
- ChatGPT的出現會不會導致底層程式設計師失業?從ChatGPT的原理和網路上漏出的生成內容來看,ChatGPT產生的程式碼很多可以正確運作。但程式設計師的工作不只寫程式碼,更重要的是找到問題的解決方案。所以ChatGPT並不會取代程式設計師,尤其是高階程式設計師。相反地它會向現在很多的程式碼產生工具一樣,成為程式設計師寫程式碼非常有用的工具。
- Stack Overflow 宣布臨時規則:禁止 ChatGPT。 ChatGPT本質上還是一個文字生成模型,對比生成程式碼,它更擅長產生以假亂真的文字。而且文字產生模型產生的程式碼或解決方案並不能保證是可運行而且是可以解決問題的,但它以假亂真的文字又會迷惑很多查詢這個問題的人。 Stack Overflow為了維持論壇的質量,封鎖ChatGPT也是清理之中。
- 聊天機器人 ChatGPT 在誘導下寫出「毀滅人類計畫書」,並給出程式碼,AI 發展有哪些問題需關注? ChatGPT的「毀滅人類計畫書」是它在不可遇見的指示下根據大量資料強行擬合出來的生成內容。雖然這些內容看起來很真實,表達也很流暢,這說明的只是ChatGPT具有非常強的生成效果,並不表示ChatGPT具備毀滅人類的思想。因為他只是一個文本生成模型,並不是一個決策模型。
4. 總結
就像許多人們演算法剛誕生時一樣,ChatGPT憑藉著有用性,真實性,無害性的效果,引起了業內廣泛的關注和人類對AI的思考。但是當我們看完它的演算法原理之後,發現它並沒有業內宣傳的那麼恐怖。反而我們可以從它的技術方案中學到很多有價值的東西。 InstrcutGPT/ChatGPT在AI界最重要的貢獻是將強化學習和預訓練模型巧妙的結合。而且透過人工回饋提升了模型的有用性,真實性和無害性。 ChatGPT也進一步提升大模型的成本,之前只是比拼數據量和模型規模,現在甚至也引入了僱用的外包這一支出,讓個體工作者更加望而卻步。
參考
- ^Ouyang, Long, et al. "Training language models to follow instructions with human feedback." *arXiv preprint arXiv:2203.02155* (2022). https:/ /arxiv.org/pdf/2203.02155.pdf
- ^Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training https: //www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
- ^Radford, A., Wu, J., Child, R., Luan, D., Amodei, D . and Sutskever, I., 2019. Language models are unsupervised multitask learners. *OpenAI blog*, *1*(8), p.9. https://life-extension.github.io/2020/05/27/ GPT技術初探/language-models.pdf
- ^Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners .」 *arXiv preprint arXiv:2005.14165* (2020). https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418b8ac142f64a-Paper.pdf,cfbed language models are zero-shot learners." *arXiv preprint arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
- #^Christiano, Paul F., et al. " Deep reinforcement learning from human preferences." *Advances in neural information processing systems* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf
- ^Schulman, John, et al. "Proximal policy optimization algorithms." *arXiv preprint arXiv:1707.06347* (2017). https://arxiv.org/pdf/1707.06347.pdf
-