
一文看懂Python爬蟲

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-01-25 06:30:013584瀏覽
本篇文章為大家帶來了關於Python的相關知識,其中主要介紹了關於爬蟲的相關知識,爬蟲簡單的來說就是用程式獲取網路上資料這個過程的一種名稱,下面一起來看一下,希望對大家有幫助。

爬蟲是什麼
爬蟲簡單的來說就是用程式取得網路上資料這個過程的一種名稱。
爬蟲的原理
如果要取得網路上數據,我們要給爬蟲一個網址(程式中通常叫URL),爬蟲會傳送一個HTTP請求給目標網頁的伺服器,伺服器回傳數據給客戶端(也就是我們的爬蟲),爬蟲再進行資料解析、保存等一系列操作。
流程
爬蟲可以節省我們的時間,例如我要取得豆瓣電影Top250 名單,如果不用爬蟲,我們要先在瀏覽器上輸入豆瓣電影的URL ,客戶端(瀏覽器)透過解析查到豆瓣電影網頁的伺服器的IP 位址,然後與它建立連接,瀏覽器再創造一個HTTP 請求發送給豆瓣電影的伺服器,伺服器收到請求之後,把Top250 名單從資料庫中提出,封裝成一個HTTP 回應,然後將回應結果傳回給瀏覽器,瀏覽器顯示回應內容,我們看到資料。我們的爬蟲也是根據這個流程,只不過改成了程式碼形式。
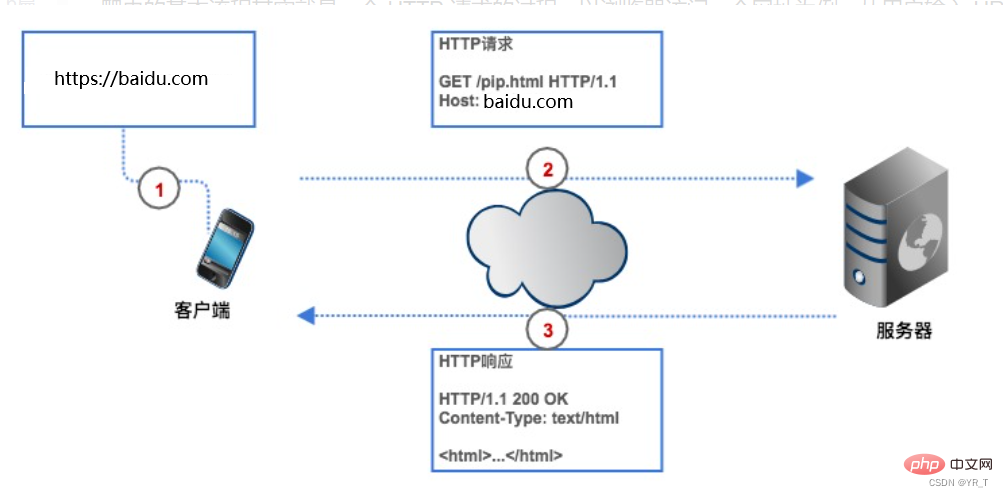
HTTP請求
HTTP 請求由請求行、請求頭、空白行、請求體組成。

請求行由三個部分組成:
1.請求方式,因此常見的請求方式有GET、POST、PUT、DELETE、HEAD
2.客戶端要取得的資源路徑
3.是使用客戶端所使用的HTTP 協定版本號
請求頭是客戶端傳送請求請求的補充說明,例如說明訪客身份,此下方會講到。
請求體是客戶端向伺服器提交的數據,例如使用者登入時需要提高的帳號密碼資訊。請求頭與請求體之間以空白行隔開。請求體並不是所有的請求都有的,例如一般的GET都不會帶有請求體。
上圖就是瀏覽器登入豆瓣時傳送給伺服器的HTTP POST 請求,請求體中指定了使用者名稱和密碼。
HTTP 回應
HTTP 回應格式與請求的格式很相似,也是由回應行、回應頭、空白行、回應體組成。

回應列也包含三個部分,分別是服務端的 HTTP 版本號碼、回應狀態碼和狀態說明。
這裡狀態碼有一張表,對應了各個狀態碼的意思

 #
# 
第二部就是回應頭,回應頭與請求頭對應,是伺服器對該回應的一些附加說明,例如回應內容的格式是什麼,回應內容的長度有多少、什麼時間回傳給客戶端的、甚至還有一些Cookie 資訊也會放在響應頭裡面。
第三部分是響應體,它才是真正的回應數據,這些數據其實就是網頁的 HTML 原始碼。
爬蟲程式碼怎麼寫
爬蟲可以用很多語言例如Python、C 等等,但我覺得Python是最簡單的,
因為Python有現成可用的函式庫,已經封裝到幾乎完美,
C 雖然也有現成的函式庫,但是它的爬蟲還是比較小眾,僅有的函式庫也不足以算上簡單,而且程式碼在各個編譯器上,甚至同一個編譯器上不同版本的相容性不強,所以不是特別好用。所以今天主要介紹python爬蟲。
安裝requests庫
cmd運行:pip install requests ,安裝 requests。
然後在 IDLE 或編譯器(個人推薦 VS Code 或 Pycharm )上輸入
import requests 運行,如果沒有報錯,證明安裝成功。
安裝大部分函式庫的方法都是:pip install xxx(函式庫的名字)
requests的方法
| requests.request() | 建構一個請求,支撐各方法的基本方法 |
| requests.get() | 取得HTML網頁的主要方法,對應HTTP的GET |
requests.head() |
取得HTML網頁頭資訊的方法,對應HTTP的HEAD |
| #requests.post() | 向HTML網頁提交POST請求的方法,對應HTTP的POST |
| requests.put() | 向HTML網頁提交PUT請求的方法,對應於HTTP的PUT |
| requests.patch( ) | 向HTML網頁提交局部修改請求,對應於HTTP的PATCT |
| requests. delete() | 向HTML網頁提交刪除請求,對應HTTP的DELETE |
最常用的get方法
r = requests .get(url)
包含兩個重要的物件:
建構一個向伺服器請求資源的Request物件;傳回一個包含伺服器資源的Response物件
| r.status_code | HTTP請求的回傳狀態,200表示連線成功,404表示失敗 |
| HTTP回應內容的字串形式,即,url對應的頁面內容 | |
| 從HTTP header中猜測的回應內容編碼方式(如果header中不存在charset,則認為編碼為ISO-8859-1) | |
| 從內容分析的回應內容編碼方式(替代編碼方式) | |
| HTTP回應內容的二進位形式 |
| 網路連線錯誤異常,如DNS查詢失敗、拒絕連線等 | |
| #HTTP錯誤異常 | |
| URL缺失異常 | |
| ##超過最大重定向次數,產生重定向異常 | |
| 連接遠端伺服器逾時異常 | |
| 請求URL逾時,產生超時異常 |
requests是最基礎的爬蟲庫,但是我們可以做一個簡單的翻譯
我先把我做的一個爬蟲的小專案的專案結構放上,完整原始碼可以私聊我下載。
 以下是翻譯部分的原始碼
以下是翻譯部分的原始碼
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])
程式碼詳解:
匯入requests模組,設定 url為百度翻譯網頁的網址。
 接著透過 post 方法傳送請求,再把回傳的結果打成一個 dic (字典),但這個時候我們印出來結果發現是這樣的。
接著透過 post 方法傳送請求,再把回傳的結果打成一個 dic (字典),但這個時候我們印出來結果發現是這樣的。
 這是一個字典裡套列表套字典的樣子,大概就是這樣的
這是一個字典裡套列表套字典的樣子,大概就是這樣的
{ xx:xx , xx:
[{xx:xx} , {xx:xx} , {xx:xx} , {xx:xx} ] }我標紅的地方是我們需要的資訊。
假如說我標藍色的列表裡面有 n 個字典,我們可以透過 len() 函數取得 n 的數值,
並使用 for 迴圈遍歷,得到結果。
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])
最後
好了,今天的分享就到這裡了,拜拜~
哎?忘了一件事,再給你們一個爬取天氣的代碼!
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')
【相關推薦:以上是一文看懂Python爬蟲的詳細內容。更多資訊請關注PHP中文網其他相關文章!