
深入了解Python數據處理及視覺化

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2022-03-21 17:43:432611瀏覽
本篇文章為大家帶來了關於python的相關知識,其中主要介紹了關於資料處理以及視覺化的相關問題,包括了NumPy的初步使用、Matplotlib套件的使用和資料統計的視覺化展示等等,希望對大家有幫助。

推薦學習:python教學
#一、NumPy的初步使用
表格是資料的一般表示形式,但對機器來說是不可理解的,也就是無法辨識的數據,所以我們需要對表格的形式進行調整。
常用的機器學習表示形式為資料矩陣。 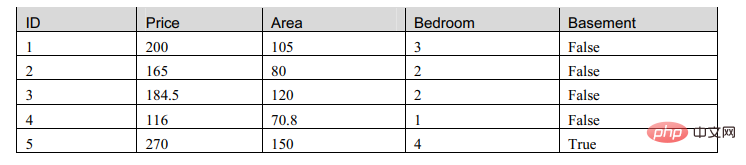
我們觀察這個表格,發現,矩陣中的屬性有兩種,一種是數值型,一種是布林型。那我們現在就建立模型描述這個表格:
# 数据的矩阵化import numpy as np data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])row = 0for line in data: row += 1print( row )print(data.size)print(data)
這裡第一行程式碼的意思就是引入NumPy將其重新命名為np。第二行我們使用NumPy中的mat()方法建立資料矩陣,row是引入的計算行數的變數。
這裡的size意思就是5*5的一個表格,直接列印data就可以看到資料了: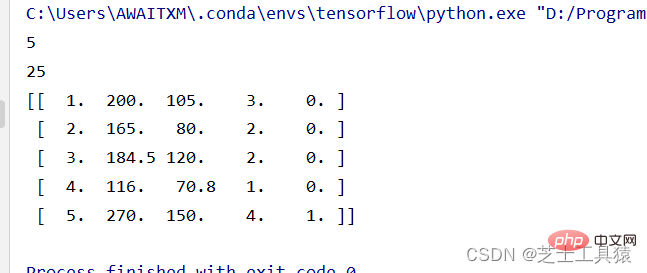
二、Matplotlib套件的使用–圖形化資料處理
我們還是看最上面的表格,第二列是房價的差異,我們想直觀的看出差別是不容易的(因為只有數字),所以我們希望能夠把它畫出來(研究數值差異和異常的方法就是繪製資料的分佈程度):
import numpy as npimport scipy.stats as statsimport pylab data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])coll = []for row in data: coll.append(row[0,1])stats.probplot(coll,plot=pylab)pylab.show()
這個程式碼的結果就是產生一個圖: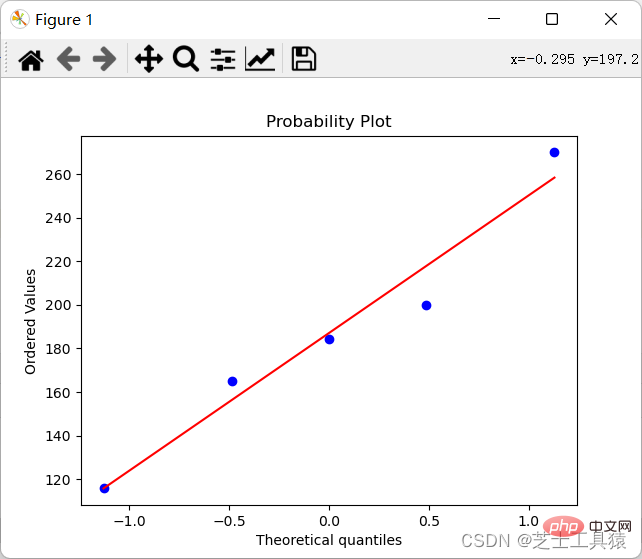
這樣我們就能清楚的看出來差異了。
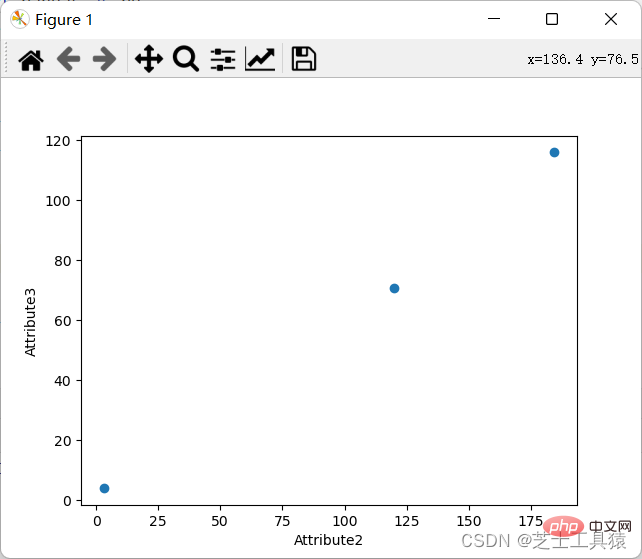
一個座標圖的要求,就是透過不同的行和列來表現資料的具體值。
當然,座標圖我們一樣可以展示: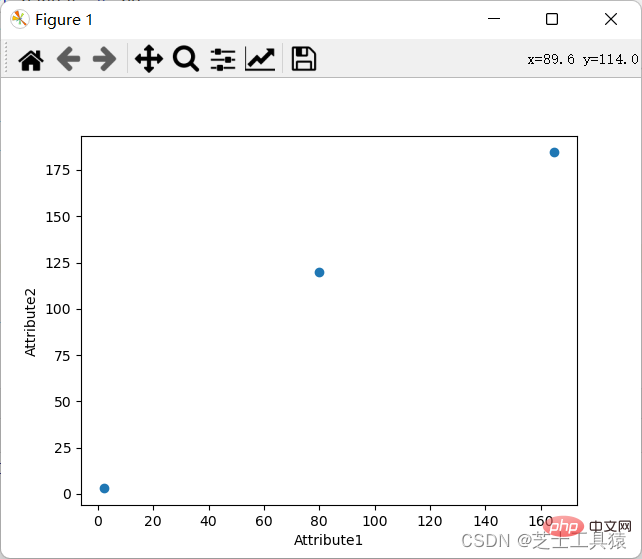
三、深度學習理論方法–相似度計算(可以跳過)
相似度的計算方法有很多,我們選用最常用的兩種,即歐幾里德相似度和餘弦相似度計算。
1、基於歐幾里德距離的相似度計算
歐幾里德距離,用來表示三維空間中兩點的真實距離。公式我們其實都知道,只是名字聽的少: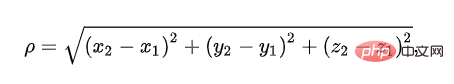
那麼我們來看一看它的實際應用:
這個表格是3個用戶對物品的評分: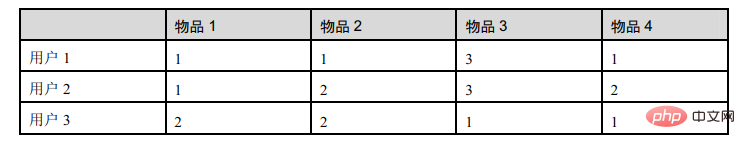
d12表示使用者1和使用者2的相似度,那麼就有: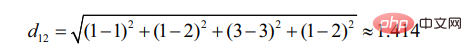
同理,d13: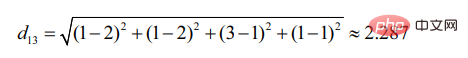
可見,使用者2更相似於用戶1(距離越小,相似度越大)。
2、基於餘弦角度的相似度計算
餘弦角度的計算出發點是夾角的不同。 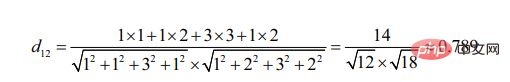
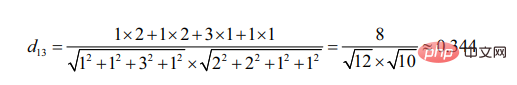
可見相對於用戶3,用戶2與用戶1更為相似(兩個目標越相似,其線段形成的夾角越小)
四、資料統計的視覺化展示(以我們亳州市降水為例)
資料的四分位數
四分位數,是統計學中分位數的一種,也就是把資料由小到大排列,之後分成四等份,處於三個分割點位置的數據,就是四分位數。
第一四分位數(Q1),也稱呼下四分位數;
第二四分位數(Q1),也稱中位數;
第三四分位數(Q1),也稱下四分位數;
第三四分位數與第一四分位數的差距又稱為四分差距(IQR)。
#若n为项数,则:
Q1的位置 = (n+1)*0.25
Q2的位置 = (n+1)*0.50
Q3的位置 = (n+1)*0.75
四分位示例:
关于这个rain.csv,有需要的可以私我要文件,我使用的是亳州市2010-2019年的月份降水情况。
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()print(summary)array = dataFile.iloc[:,:].values
boxplot(array)plot.xlabel("year")plot.ylabel("rain")show()
以下是plot运行结果: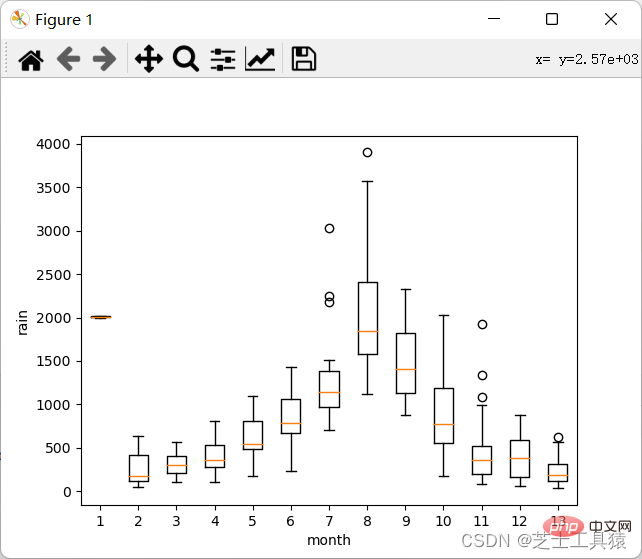
这个是pandas的运行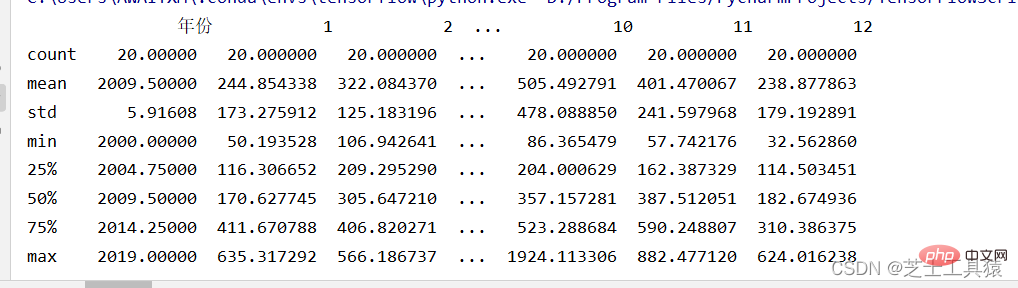
这里就可以很清晰的看出来数据的波动范围。
可以看出,不同月份的降水量有很大差距,8月最多,1-4月和10-12月最少。
那么每月的降水增减程度如何比较?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()minRings = -1maxRings = 99nrows = 11for i in range(nrows):
dataRow = dataFile.iloc[i,1:13]
labelColor = ( (dataFile.iloc[i,12] - minRings ) / (maxRings - minRings) )
dataRow.plot(color = plot.cm.RdYlBu(labelColor),alpha = 0.5)plot.xlabel("Attribute")plot.ylabel(("Score"))show()
结果如图: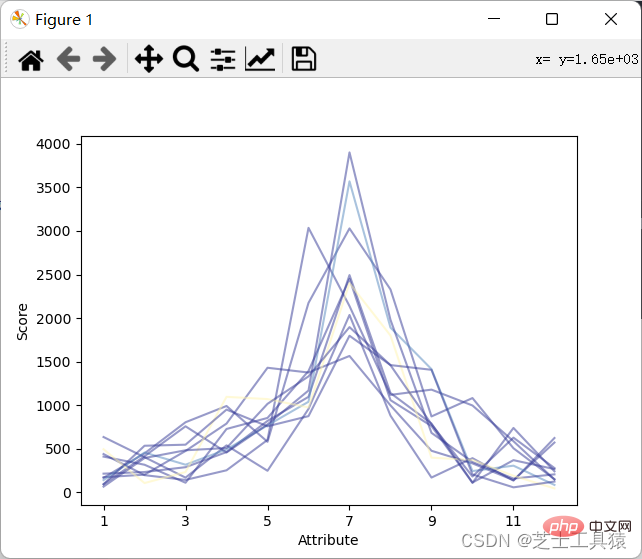
可以看出来降水月份并不规律的上涨或下跌。
那么每月降水是否相关?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()corMat = pd.DataFrame(dataFile.iloc[1:20,1:20].corr())plot.pcolor(corMat)plot.show()
结果如图: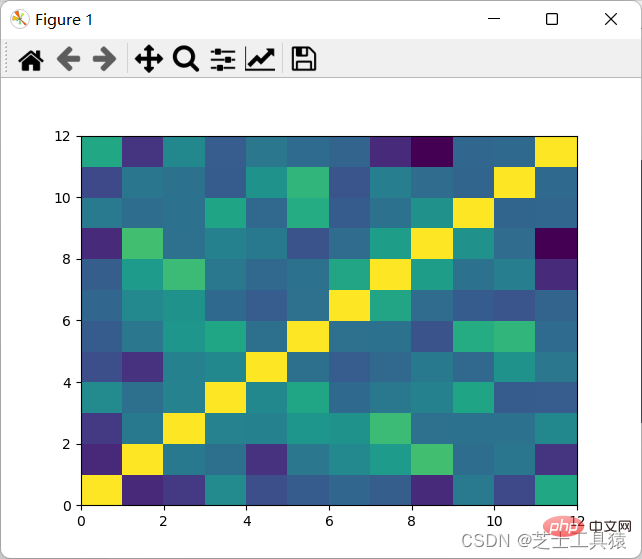
可以看出,颜色分布十分均匀,表示没有多大的相关性,因此可以认为每月的降水是独立行为。
今天就记录到这里了,我们下次再见!希望本文章对你也有所帮助。
推荐学习:python学习教程
以上是深入了解Python數據處理及視覺化的詳細內容。更多資訊請關注PHP中文網其他相關文章!