
詳解MySQL中的count()、union()和group by語句

- 青灯夜游轉載
- 2021-09-03 18:49:304094瀏覽
這篇文章帶大家了解count()、union()和group by語句,補充一下MySQL知識點(不同count()的用法、union執行流程、group by語句)。

一、MySQL中count()的不同用法
count()是一個聚合函數,對於傳回的結果集,一行行判斷,如果count函數的參數不是NULL,累計值就加1,否則不加。最後傳回累計值。 【相關推薦:mysql影片教學】
1.對於count(主鍵id)來說,InnoDB引擎會遍歷整張表,把每一行的id值都取出來,回傳給server層。 server層拿到id後,判斷是不可能為空的,就按行累加
2.對於count(1)來說,InnoDB引擎遍歷整張表,但不取值。 server層對於傳回的每一行,放一個數字1進入,判斷是不可能為空的,按行累加
#3.對於count(字段)來說,如果這個字段是定義為not null的話,一行行地從記錄裡面讀出這個字段,判斷不能為null,按行累加;如果這個字段定義允許為null的話,那麼執行的時候,判斷到有可能是null,還要把值取出來在判斷一下,不是null才累加
4.對於count(*)來說,並不會把全部欄位取出來,而是專門做了最佳化。不取值,count(*)絕對不是null,按行累積


create table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
END分析下面這條SQL語句:(select 1000 as f) union (select id from t1 order by id desc limit 2);
 第三行的Extra字段,表示在對子查詢的結果集做union的時候,使用了臨時表
第三行的Extra字段,表示在對子查詢的結果集做union的時候,使用了臨時表
2.執行第一個子查詢,得到1000這個值
3.執行第二個子查詢:
拿到第一行id=1000,試圖插入臨時表。但由於1000這個值已經存在於臨時表了,違反了唯一性約束,所以插入失敗,然後繼續執行取到第二行id=999,插入臨時表成功
4.從臨時表中按行取出數據,返回結果,並刪除臨時表,結果中包含兩行數據分別是1000和999
這裡的記憶體臨時表起到了暫存資料的作用,而且計算過程還用上了臨時表主鍵id的唯一性約束,實現了union的語意
如果把上面的語句中union改成union all的話,就沒有了去重的語意。這樣執行的時候,就依序執行子查詢,得到的結果直接作為結果集的一部分,發給客戶端。因此也就不需要臨時表了
- 第二行Extra欄位顯示的是Using index,表示只使用了覆蓋索引,沒有用臨時表
- 三、group by語句詳解
還是使用上面的表t1,分析下面這條SQL語句:
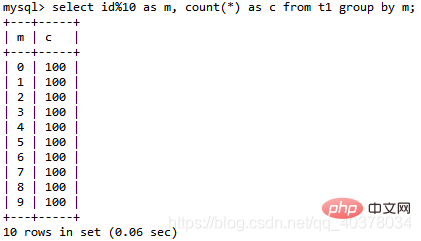
select id%10 as m, count(*) as c from t1 group by m;
- 這個語句的邏輯是把表t1裡的數據,依照id 進行分組統計,並依照m的結果排序後輸出。 explain結果如下:
- 在Extra欄位裡面,可以看到三個資訊:
 Using temporary,表示使用了臨時表
Using temporary,表示使用了臨時表
Using filesort,表示需要排序
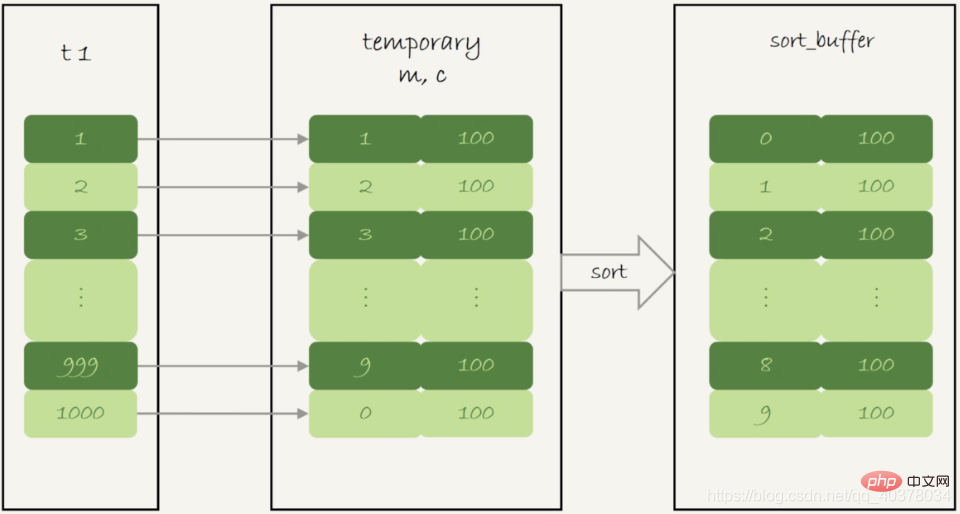
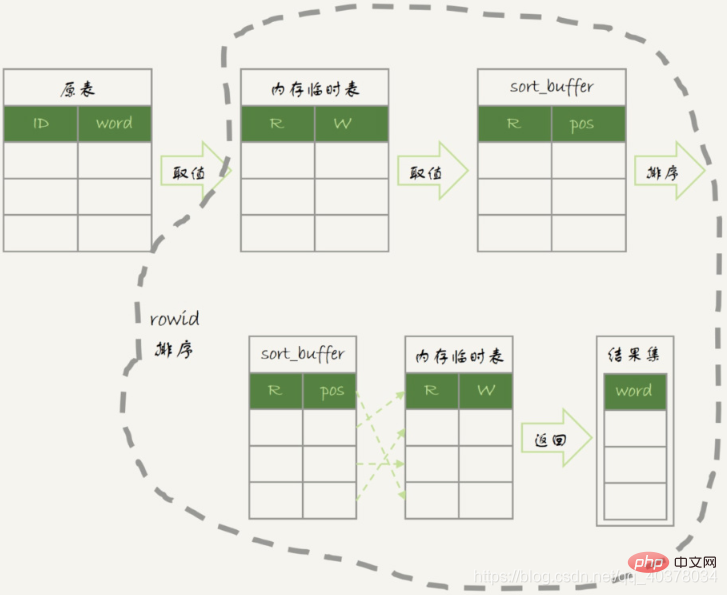
内存临时表排序流程图:
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
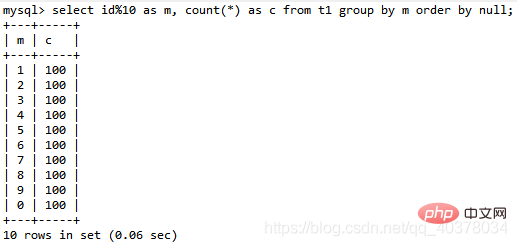
由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
2、group by优化方法——索引
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构

如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:
- 当碰到第一个1的时候,已经知道累积了X个0,结果集里的第一行就是(0,X)
- 当碰到第一个2的时候,已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;

从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了
3、group by优化方法——直接排序
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
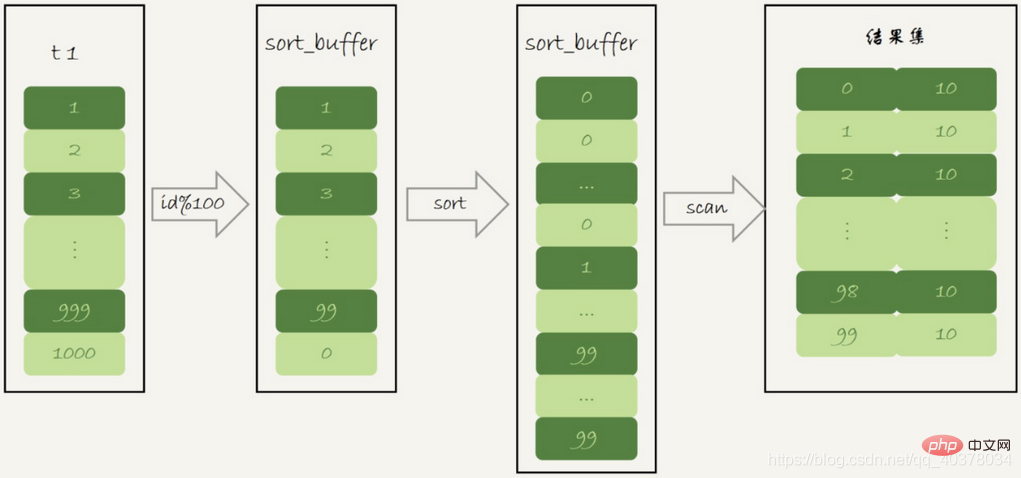
这个语句的执行没有再使用临时表,而是直接用了排序算法
%E3%80%81union()%E5%92%8Cgroup%20by%E8%AA%9E%E5%8F%A5)
更多编程相关知识,请访问:编程入门!!
以上是詳解MySQL中的count()、union()和group by語句的詳細內容。更多資訊請關注PHP中文網其他相關文章!