
pandas技巧之 DataFrame中的排序與總結方法

- coldplay.xixi轉載
- 2020-09-17 16:53:224602瀏覽

相關學習推薦:python教學
#今天是pandas資料處理專題的第六篇文章,我們來聊聊DataFrame的排序與總結運算。
在上一篇文章當中我們主要介紹了DataFrame當中的apply方法,如何在一個DataFrame對每一行或是每一列進行廣播運算,使得我們可以在很短的時間內處理整份資料。今天我們來聊聊如何對一個DataFrame根據我們的需要進行排序以及一些匯總運算的使用方法。
排序
排序是我們一個非常基本的需求,在pandas當中將這個需求進一步細分,細分成了依索引排序以及依照值排序。我們先來看看Series當中的排序方法。
Series當中的排序方法有兩個,一個是sort_index,顧名思義根據Series中的索引對這些值進行排序。另一個是sort_values,根據Series中的值來排序。這兩個方法都會傳回一個新的Series:
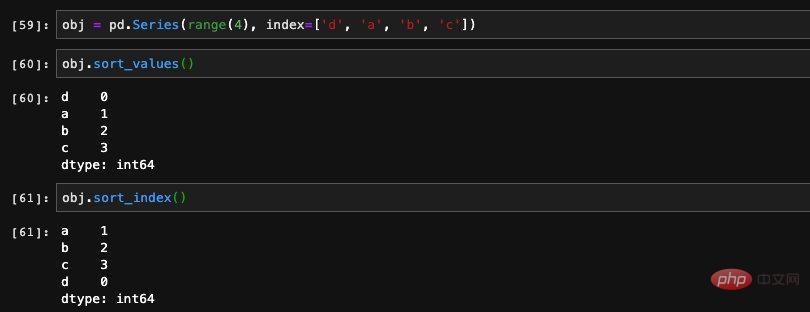
#索引排序
對於DataFrame來說也是一樣,同樣有根據值排序以及根據索引排序這兩個功能。但是由於DataFrame是一個二維的數據,所以在使用上會有些不同。最簡單的差別是在於Series只有一列,我們明確的知道排序的對象,但是DataFrame不是,它當中的索引就分為兩種,分別是行索引以及列索引。所以我們在排序的時候
需要指定我們想要排序的軸
,也就是axis。 ######預設的情況我們是根據行索引進行排序,如果我們要指定根據列索引進行排序,需要傳入參數axis=1。 ###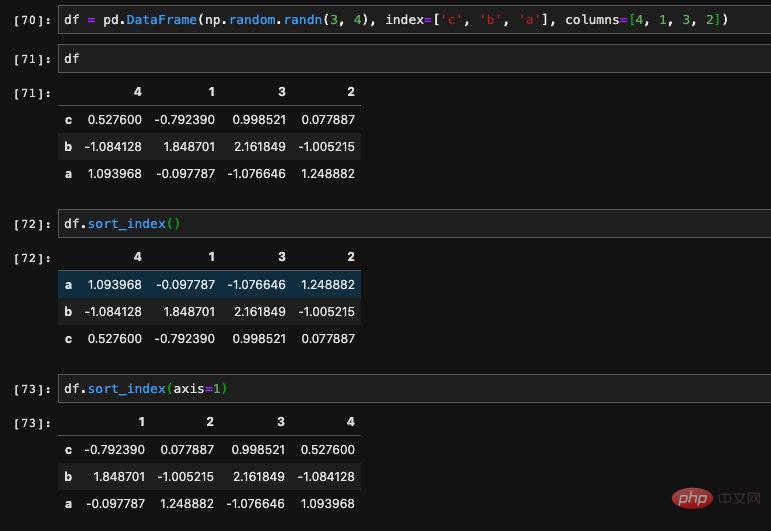
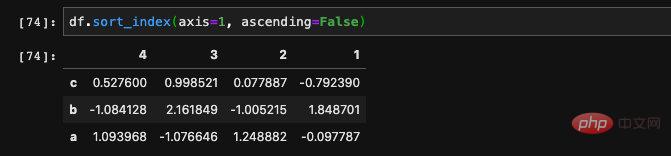
我們也可以傳入ascending這個參數,用來指定我們想要的排序順序是正序還是倒序。
值排序
#DataFrame的值排序有所不同,我們不能對行進行排序,只能針對列。我們透過by參數傳入我們希望排序參照的列,可以是一列或多列。

排名
#有的時候我們希望得到元素的排名,我們會希望知道目前元素在整體當中排第幾,pandas當中也提供了這個功能,它就是rank方法。

我們可以發現我們隨手輸入的一串數字當中,包含兩個7,7是Series當中最大的數字,但是它們的排名為什麼是6.5呢?
其實很簡單,因為7出現了兩次,分別是第6位和第7位,這裡對它所有出現的排名取了平均,所以是6.5。如果我們不希望它取平均,而是根據出現的先後順序給出排名的話,我們可以用method參數指定我們希望的效果。
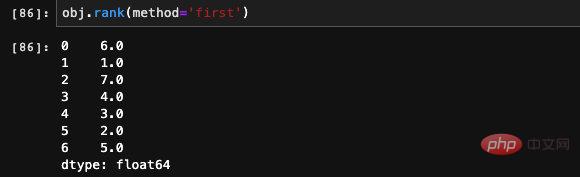
method的合法參數不止first這一種,還有一些其他稍微冷門一些的用法,我們一併列出。

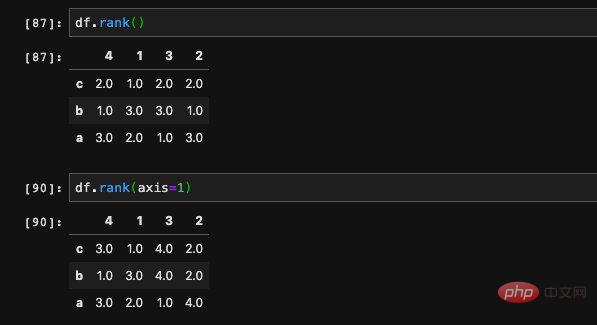
如果是DataFrame的話,預設是以行為單位,計算每一行中元素佔整體的排名。我們也可以透過axis參數指定以列為單位計算:
總計運算
最後我們來介紹DataFrame當中的匯總運算,匯總運算也就是聚合運算,例如我們最常見的sum方法,對一批次資料進行聚合求和。 DataFrame當中同樣有類似的方法,我們一個一個來看。
首先是sum,我們可以使用sum來對DataFrame進行求和,如果不傳任何參數,預設是對每一行進行求和。

除了sum之外,另一個常用的就是mean,可以針對一行或是一列求平均。

由於DataFrame當中常常會有為NA的元素,所以我們可以透過skipna這個參數排除掉缺失值之後再計算平均值。
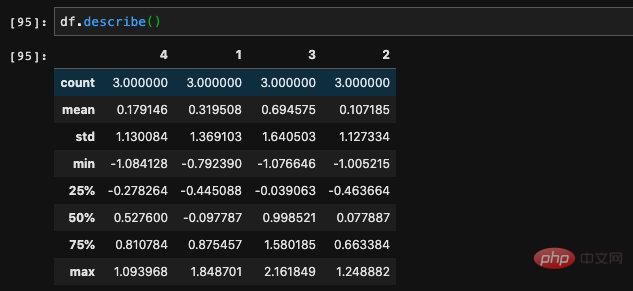
另一個我個人覺得很好用的方法是descirbe,可以回傳DataFrame當中的整體資訊。例如每一列的平均值、樣本數、標準差、最小值、最大值等等。是常用的統計方法,可以用來了解DataFrame當中資料的分佈。
除了介紹的這些方法之外,DataFrame當中還有很多類似的匯總運算方法,比如idxmax,idxmin,var,std等等,大家感興趣可以去查閱相關文檔,但是根據我的經驗一般用不到。
#想了解更多程式設計學習,請關注php培訓欄位!
以上是pandas技巧之 DataFrame中的排序與總結方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!