
小編帶你深入解析SQL Server索引的原理

- 无忌哥哥原創
- 2018-07-12 14:11:262442瀏覽
實際上,您可以把索引理解為一種特殊的目錄,下面這篇文章主要給大家介紹了關於SQL Server索引原理的相關資料,文中透過範例程式碼介紹的非常詳細,對大家的學習或者工作有一定的參考學習價值,需要的朋友們下面隨著小編來一起學習學習吧
前言
##此文是我之前的筆記整理而來,以索引為入口進行探討相關資料庫知識(又做了修改以讓人更好消化)。 SQL Server接觸不久的朋友可以只看以下藍色字體字,簡單有用節省時間;如果是資料庫基礎不錯的朋友,可以全看,歡迎探討。
索引的概念
1.聚集索引和非聚集索引
#索引分為聚集索引和非聚集索引#1.1 聚集索引
表格的資料是儲存在資料頁中(資料頁的PageType標記為1),SqlServer一頁是8k,存滿一頁就開闢下一頁儲存。如果表格有聚集索引,那麼一筆一筆實體資料就是按聚集索引欄位的大小升/降排序儲存在頁中。當對聚集索引欄位更新或中間插入/刪除資料時,都會導致表格資料移動(造成效能一定影響),因為它要保持升/降排序。
(D).欄位長度小
聚集索引鍵長度越小,一頁索引頁就可以容納更多索引記錄,進而減少索引B樹結構的深度。例如,一個百萬記錄的表有一個int聚集索引,可能只需要3層的B樹結構。如果把聚集索引定義在較寬的欄位(例如uniqueidentifier欄位需要16 位元組),那麼索引的深度會增加到4層。任何聚集索引查找需要4個I/O操作(確切的說是4個邏輯讀),原先只要3個I/O操作。
同樣,非聚集索引裡會包含聚集索引鍵值,聚集索引鍵長度越小非聚集索引記錄也就越小,一頁索引頁就可以容納更多索引記錄。
1.2 非聚集索引
也是儲存在頁中(PageType標記為2的頁,叫做索引頁)。 例如表T建立了一個非聚集索引Index_A,那麼表T有100條數據的話,那麼索引Index_A也就有100條數據(準確的說是100條葉子節點數據,索引是B樹結構,如果樹的高度大於0,那麼就有根節點頁或中間節點頁數據,這時索引數據就超過100條),如果表T還有非聚集索引Index_B,那麼Index_B也是至少100條數據,所以索引建越多開銷越大。
更新索引欄位、插入一條資料、刪除資料都會造成索引的維護進而造成效能的一定影響。 在不同情況下,效能影響是不同的。例如當你有一個聚集索引,插入的資料又都是在末尾,這樣幾乎是不會造成資料移動,影響較小;如果插入的資料在中間位置,一般會導致資料移動,而且可能產生分頁和頁碎片,影響就會稍大一點(如果插入到的中間頁有足夠的剩餘空間容納插入的數據,而且位置是在頁末,也是不會造成數據移動)
2.索引的結構
都說SqlServer的索引是B樹結構(這邊假定你對B樹結構有一定了解),那它到底長什麼模樣呢,可以用Sql語句來查看它的邏輯呈現。
新建查詢執行語法: DBCC IND(Test,OrderBo,-1) --其中Test庫的OrderBo表有1萬筆數據,有聚集索引Id主鍵字段
# (不妨自己動手建個表,有聚集索引字段,插入1萬表數據,然後執行這個語法看看,會收穫很多,百聞不如一見)
執行結果:
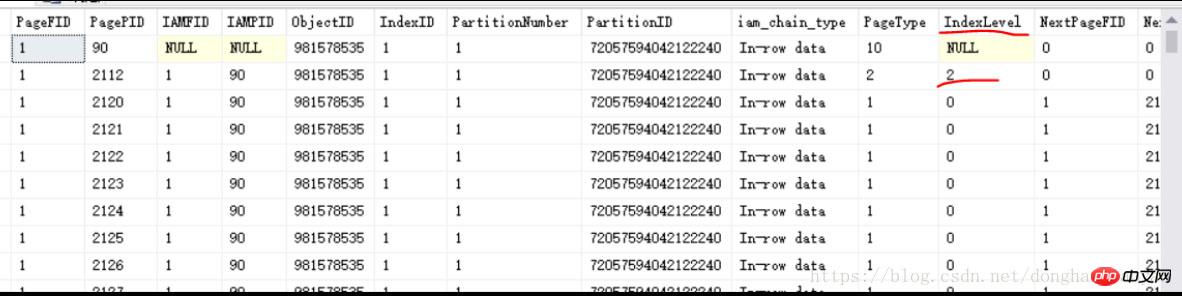
如上圖,看到一個IndexLevel=2的索引頁2112(這邊它就是B樹的根節點,IndexLevel最大的就是根節點,往下就是子級、子子級...只有一個根頁作為B樹結構的訪問入口點),表示一定還有IndexLevel=1的索引頁和IndexLevel=0的葉子頁。由於這邊是聚集索引,因此當IndexLevel=0的葉子頁就是資料頁,儲存的是一筆一筆的實體資料。如上圖也可以看到,IndexLevel=0的行的PageType等於1,就是代表資料頁,上面1.1章講到聚集索引時,也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的葉子頁,PageType是等於2,還是索引頁。
同樣,我們用Sql指令DBCC PAGE看一看
-- DBCC TRACEON(3604,-1) DBCC PAGE(Test,1,2112,3) --根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询 DBCC PAGE(Test,1,2280,3) DBCC PAGE(Test,1,2448,3)

SqlServer索引結構比較像是B 樹,最後是B樹和B 樹的混合版,資料結構都是人定的,不一定就是純粹的B樹或單純的B 樹。
#
3.索引包含列和書籤查找
#談到索引,這邊再講一個SqlServer2005開始增加的“索引包含列”功能,很實用。
例如,在大報表查詢資料時,where條件用到索引欄位Name2,但是要select的欄位是Name1,這時候可以使用「索引包含列」把Name1包含在索引欄位Name2中,大幅提升查詢效能。
語法: Create [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) Include(Name1);
接下來分析為什麼索引包含列可以大大提高效能。仍使用DBCC PAGE指令,查看一個非聚集索引並有包含列的索引資料情況:

#由上圖可知,包含列Name1也儲存在索引數據中。因此,當資料庫用索引欄位Name2定位到要找的某一行時,就可以直接把Name1的值回傳了,不用再根據RID(上圖是【HEAP RID(Key)】列)定位到資料頁中去取值,即減少了書籤查找。當查詢只回傳一條數據,只有一次書籤查找時當然沒什麼,如果查詢返回的數據很大,每一筆都要去數據頁找數據取出來,1000筆就是1000次書籤查找,可想而知性能消耗很大,這時候「索引包含列」價值就大大體現出來了。
關於一次書籤查找,表有聚集索引(例如Id)時就是類似執行了一次select Name1 from Table1 where Id=1 ,利用聚集索引鍵Id查找(查找方式就是索引Id的B樹結構查找),而如果表沒有聚集索引,則是根據資料行指標(由「檔案編號2byte:頁號4byte:槽號2byte」組成)來尋找。聚集索引鍵和行指標一般統稱為RID(Row ID)指標。從這裡我們可以想到,如果你的表沒有很好的聚集索引字段,建議自增長的Id字段做聚集索引主鍵(冗餘出Id字段也行),它符合自增長、不被更改、唯一性、長度小的特性,是聚集索引的很好選擇。
自成長Id絕大部分情況下是適用的,特殊的情況看具體需求而定吧。還有自增長Id要考慮一個缺陷,當對錶大數據量的並發insert記錄時,可以想像每個線程都是要insert到末尾那個頁,就會發生競爭和等待。解決這種情況你可以用uniqueidentifier類型字段(16字節,我是不建議使用)或哈希分區(就是一個表分成多個表,大數據處理中分庫分錶是正常的)等。但我建議先優化你的insert效率(insert效能本身是很快的),測試每秒並發insert數是否滿足生產環境,以保留簡單穩定高效的自增長Id作法。
自增長Id不一定就是用資料庫提供的自增長,你也可以自己寫演算法產生一個並發情況下也能唯一的Id(這時候一般長度是bitint,8位元組整形),這種情況適合場景是分散式資料庫中主從複製時Id欄位是要求一定不能出錯的情況(主從複製的一般模式下,主庫的Id是按主庫增長,從庫Id也是按從庫自己的增長,如果遇到死鎖等原因導致主從複製不同步時,那從庫的Id就和主庫的Id自增長就對不上號了)。如果自增長Id是冗餘出的主鍵,那麼主從庫Id對不上號也就無影響。
另外,上圖最後一列【Row Size】還告訴我們,索引列或索引包含列的size不要太長,否則一頁容不了幾筆記錄,這樣大大增加了索引頁數量,而且索引資料所佔的空間也大大增加了。
#
以上是小編帶你深入解析SQL Server索引的原理的詳細內容。更多資訊請關注PHP中文網其他相關文章!