
mysql的索引底層之實作原理

- 无忌哥哥原創
- 2018-07-12 10:14:291601瀏覽
MySQL索引背後的資料結構及演算法原理
一、定義
索引定義:索引(Index)是幫助MySQL高效取得資料的資料結構。
本質:索引是資料結構。
二、B-Tree
m階B-Tree滿足以下條件:
1、每個節點至多可以擁有m棵子樹。
2、根節點,只有至少有2個節點(要嘛極端情況,就是一棵樹就一個根節點,單細胞生物,即是根,也是葉,也是樹)。
3、非根非葉的節點至少有的Ceil(m/2)個子樹(Ceil表示向上取整,如5階B樹,每個節點至少有3個子樹,也就是至少有3個叉)。
4、非葉節點中的資訊包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示該節點中保存的關鍵字個數,K為關鍵字且Ki
B-Tree特性:
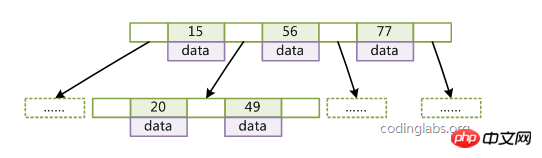
1、關鍵字集合分佈在整顆樹中;
2、任何一個關鍵字出現且只出現在一個節點中;
3、每個節點儲存date和key;
4、搜尋有可能在非葉節點結束;
5、一個節點中的key從左到右非遞減排列;
6、所有葉節點具有相同的深度,等於樹高h。
B-Tree上尋找演算法的偽代碼如下:
#三、B Tree

B Tree與B-Tree的差異在於:
1、B Tree非葉子節點不儲存data,只儲存key;
2、所有的關鍵字全部儲存在葉子節點上;
3、每個葉子節點含有一個指向相鄰葉子節點的指針,帶順序訪問指針的B 樹提高了區間查找能力;
4、非葉子節點可以看成索引部分,節點中僅含有其子樹(根節點)中的最大(或最小)關鍵字;
四、B/B 樹索引的效能分析
##依據:使用磁碟I/O次數評估索引結構的優劣主存和磁碟以頁為單位交換數據,將一個節點的大小設為等於一個頁,因此每個節點只需一次I/O就可以完全載入。
根據B樹的定義,可知檢索一次最多需要存取h個節點
漸進複雜度:O(h)=O(logdN)
dmax=floor(pagesize/(keysize datasize pointsize))
一般實際應用中,出度d是非常大的數字,通常超過100,因此h非常小(通常不超過3,3層可存大約一百萬數據)
B-Tree中一次檢索最多需要h-1次I/O(根節點常駐記憶體)
B Tree內節點不含data域,因此出度d較大,則h較小,I/O次數少,效率較高,故B Tree更適合外存索引。
五、MySQL索引實作1、MyISAM引擎使用B Tree作為索引結構,葉節點的data領域存放的是資料記錄的位址;
MyISAM主索引和輔助索引在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重複;
因為InnoDB的資料檔案本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有明確指定,則MySQL系統會自動選擇一個可以唯一標識資料記錄的資料列作為主鍵,如果不存在這種列,則MySQL會自動為InnoDB表產生一個隱含欄位作為主鍵。
InnoDB的輔助索引data域儲存對應記錄主鍵的值而非位址;
輔助索引搜尋需要檢索兩遍索引:先擷取輔助索引取得主鍵,再以主鍵至主索引擷取記錄;

六、總結
了解不同儲存引擎的索引實作方式對於正確使用和最佳化索引都非常有幫助1、為什麼不建議使用過長的欄位作為主鍵?2、為什麼選擇自增欄位作為主鍵?
3、為什麼常更新是欄位不建議建立索引?
4、為什麼選擇區分度高的欄位作為索引?區分度的公式是count(distinct col)/count(*)
5、盡可能的使用覆蓋索引
七、最佳化LIMIT分頁查詢
#SELECT * FROM table where condition LIMIT offset , rows ;
上述SQL語句的實作機制是:
1、從「table」表讀取offset rows行記錄。
2、 拋棄前面的offset行記錄,返回後面的rows行記錄作為最終的結果。
覆蓋索引:
select a.id, sid, parent_s_id from cashpool_account_relationship a join (select id from cashpool_account_relationship LIMIT 1000000,10)b on a.id = b.id; select id, sid, parent_s_id from cashpool_account_relationship where id >=(select id from cashpool_account_relationship LIMIT 1000000,1) LIMIT 10;
八、Q&A
1、InnoDB支援hash索引嗎? --馬欣
InnoDB是支援hash索引的,不過其支援的hash索引是自適應的,InnoDB儲存引擎會根據資料表的使用自動為表產生hash索引,不能人為幹預是否在一張表中產生hash索引。
2、InnoDB主鍵索引的葉節點含完整的資料記錄,那主鍵索引檔案要比資料檔大嗎? --徐財厚
1).在Innodb 引擎中,主鍵索引中的葉子結點包含記錄數據,主鍵索引檔即為資料檔。
2).在 tables 表中統計的data_length資料為主鍵索引大小,index_length 為統計的這個表中所有輔助索引(二級索引)索引的大小。 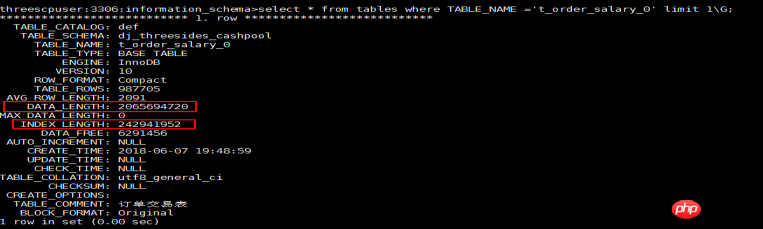
以上是mysql的索引底層之實作原理的詳細內容。更多資訊請關注PHP中文網其他相關文章!