
Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?

- PHPz原創
- 2024-08-22 16:37:32530瀏覽
基於有限的臨床數據,數百種醫療演算法已被批准。科學家們正在討論由誰來測試這些工具,以及如何最好地進行測試。
- Devin Singh 在急診室目睹了一名兒科患者因長時間等待救治而心臟驟停,這促使他探索 AI 在縮短等待時間中的應用。
- Singh 利用了 SickKids 急診室的分診數據,與同事們建立了一系列 AI 模型,用於提供潛在診斷和推薦測試。
- 一項研究表明,這些模型可以加快 22.3% 的就診速度,將每位需要進行醫學檢查的患者的結果處理速度加快近 3 小時。
- 然而,人工智慧演算法在研究中的成功只是驗證此類幹預措施是否會在現實生活中幫助人們的第一步。
利用機器學習醫療指示(MLMD)在急診室(ED)自主訂購測試的方法(資料來源:jamanetwork.com)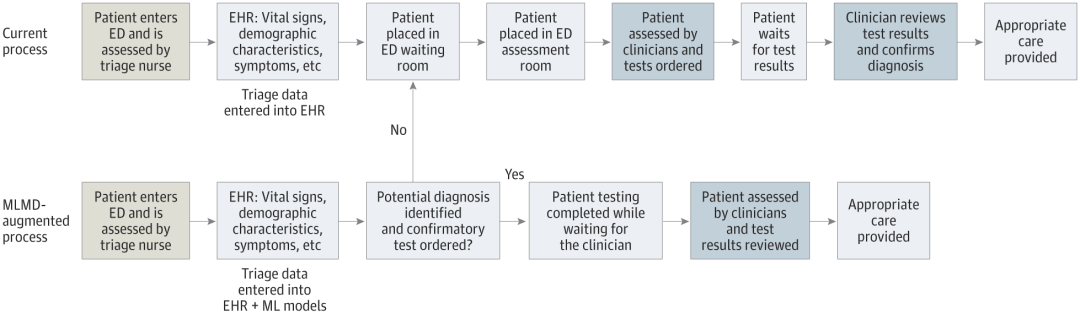
誰在測試醫療AI 系統?
基於 AI 的醫療應用,例如 Singh 正在開發的應用,通常被藥品監管機構視為醫療設備,包括美國 FDA 和英國藥品和保健產品監管局。因此,審查和授權使用的標準通常不如藥物標準嚴格。只有一小部分設備(可能對患者構成高風險的設備)需要臨床試驗數據才能獲得批准。
許多人認為門檻太低了。當費城賓州大學的重症監護醫生 Gary Weissman 審查其領域內 FDA 批准的 AI 設備時,他發現,在他確定的十種設備中,只有三種在授權中引用了已發布的數據。只有四個提到了安全評估,沒有一個包括偏見評估,該評估分析該工具的結果是否對不同患者群體公平。 「令人擔憂的是,這些設備確實可以並且確實會影響床邊護理。」他說,「病人的生命可能取決於這些決定。」
缺乏數據使得醫院和醫療系統在決定是否使用這些技術時處於困境。在某些情況下,財務激勵措施會發揮作用。例如,在美國,健康保險計劃已經為醫院使用某些醫療 AI 設備提供報銷,這使得它們在經濟上具有吸引力。這些機構也可能傾向於採用承諾節省成本的 AI 工具,即使它們不一定能改善患者護理。
Ouyang 說,這些激勵措施可能會阻止 AI 公司投資臨床試驗。 「對於許多商業企業來說,你可以想像,他們會更努力確保他們的 AI 工具可以報銷。」他說。
不同市場的情況可能有所不同。例如,在英國,由政府資助的全國性健康計畫可能會在醫療中心購買特定產品之前設定更高的證據門檻,英國伯明翰大學研究人工智慧負責任創新的臨床研究員 Xiaoxuan Liu 說,「這樣,企業就有動力進行臨床試驗。然而,一些機構認識到,監管部門的批准並不能保證該設備真正有益。所以他們選擇自己測試。 Ouyang 說,目前許多這樣的努力都是由學術醫療中心進行和資助的。
阿姆斯特丹大學醫學中心重症醫學主任 Alexander Vlaar 和同一機構的麻醉師 Denise Veelo 於 2017 年開始了這樣的嘗試。他們的目標是測試一種旨在預測手術期間低血壓發生的演算法。這種被稱為術中低血壓的狀況可能導致危及生命的併發症,如心肌損傷、心臟病發作和急性腎衰竭,甚至死亡。
該演算法由位於加州的 Edwards Lifesciences 公司開發,使用動脈波形資料——急診室或重症監護室監視器上顯示的帶有波峰和波谷的紅線。該方法可以在低血壓發生前幾分鐘預測到它,從而實現早期幹預。
低血壓預測(HYPE)試驗中的參與者流量。 (資料來源:jamanetwork.com)Vlaar、Veelo 及其同事進行了一項隨機臨床試驗,在 60 名接受非心臟手術的患者身上測試該工具。在手術期間使用該設備的患者平均經歷 8 分鐘的低血壓,而對照組患者平均經歷近 33 分鐘。
團隊進行了第二次臨床試驗,證實該設備與明確的治療方案相結合,在更複雜的環境中也有效,包括心臟手術期間和重症監護室。結果尚未公佈。
成功不只是因為演算法的精確性。麻醉師對警報的反應也很重要。因此,研究人員確保醫生做好充分準備:「我們有一個診斷流程圖,上面列出了收到警報時應採取的步驟。」Veelo 說。另一家機構進行的臨床試驗中,同樣的演算法未能顯示出益處。在那種情況下,「當警報響起時,床邊醫生沒有遵從指示採取行動。」Vlaar 說。
人類參與其中一個完美的演算法可能會因為人類行為的變化而失敗,無論是醫療保健專業人員還是接受治療的人。
明尼蘇達州羅徹斯特的梅奧診所(Mayo Clinic)測試了一種內部開發的演算法,用於檢測低射血分數的心臟病,該中心的人機交互研究員Barbara Barry 負責彌合開發人員與使用該技術的初級保健提供者之間的差距。
該工具旨在標記可能患上這種疾病高風險的個人,這種疾病可能是心臟衰竭的徵兆,可以治療,但經常無法診斷。一項臨床試驗表明,該演算法確實增加了診斷率。然而,在與提供者的對話中,Barry 發現他們希望得到進一步的指導,以了解如何與患者討論演算法的結果。這導致建議,如果廣泛實施該應用程序,應包括與患者溝通的重要資訊的要點,以便醫療保健提供者不必每次都考慮如何進行這種對話。 「這是我們從務實試驗轉向實施策略的一個例子。」Barry 說。
另一個可能限制某些醫療 AI 設備成功的問題是「警報疲勞」——當臨床醫生接觸到大量 AI 生成的警告時,他們可能會對它們變得麻木。梅奧診所家庭醫學部主任 David Rushlow 表示,在測試過程中應該考慮到這一點。
「我們每天都會收到很多有關患者可能面臨風險的疾病的警報。對於忙碌的一線臨床醫生來說,這實際上是一項非常艱鉅的任務。」他說,「我認為其中許多工具將能夠幫助我們。
考慮偏見
測試醫療人工智慧的另一個挑戰是臨床試驗結果很難在不同人群推廣。 「眾所周知,當人工智慧演算法用於與訓練資料不同的資料時,它們會非常脆弱。」Liu 說。
她指出,只有當臨床試驗參與者代表了該工具將要使用的族群時,才能安全地推斷出結果。
此外,在資源豐富的醫院收集的資料上訓練的演算法在資源匱乏的環境中應用時可能效果不佳。例如,Google Health 團隊開發了一種用於檢測糖尿病視網膜病變(一種導致糖尿病患者視力喪失的疾病)的演算法,理論上準確率很高。但當該工具在泰國的診所使用時,其表現顯著下降。
一項觀察性研究顯示,泰國診所的照明條件導致眼部影像品質低下,從而降低了該工具的有效性。

目前,大多數醫療人工智慧工具可幫助醫療保健專業人員進行篩檢、診斷或製定治療計畫。患者可能不知道這些技術正在接受測試或常規用於他們的護理,而且目前任何國家都沒有要求醫療服務提供者披露這一點。
關於應該告訴患者什麼有關人工智慧技術的爭論仍在繼續。其中一些應用程式將患者同意的問題推到了開發人員關注的焦點。 Singh 團隊正在開發的人工智慧設備就是這種情況,該設備旨在簡化 SickKids 急診室對兒童的護理。
這項技術的顯著不同之處在於,它將臨床醫生從整個過程中移除,讓孩子(或他們的父母或監護人)成為最終用戶。
「該工具的作用是獲取緊急分類數據,做出預測,並讓家長直接批准——是或否——是否可以對孩子進行檢測。」Singh 說。這減輕了臨床醫生的負擔,加速了整個過程。但也帶來了許多前所未有的問題。如果患者出現問題,誰來負責?如果進行了不必要的檢查,誰來支付費用?
「我們需要以自動化的方式獲得家屬的知情同意。」Singh 表示,而且同意必須是可靠和真實的。 「這不能像你註冊社交媒體時那樣,有20 頁小字,你只需點擊接受。」
在Singh 和他的同事等待資金開始對患者進行試驗的同時,該團隊正在與法律專家合作,並讓該國的監管機構加拿大衛生部參與審查其提案並考慮監管影響。電腦科學家、SickKids 兒童醫學人工智慧計畫聯合主席 Anna Goldenberg 表示,目前,「監管方面的情況有點像西部荒野」。

醫療機構審慎採用 AI 工具,進行自主測試。
成本因素促使研究人員和醫療機構探索替代方案。
大型醫療機構難度較小,小型機構面臨更大挑戰。
梅奧診所測試 AI 工具,針對社區醫療機構使用。
健康 AI 聯盟成立保障實驗室,評估模型。
杜克大學提出內部測試能力,本地驗證 AI 模型。
放射科醫生 Nina Kottler 強調本地驗證的重要性。
人為主因素需重視,確保人工智慧和最終用戶準確性。
參考內容:https://www.nature.com/articles/d41586-024-02675-0
以上是Nature觀點,人工智慧在醫學上的測試一片混亂,該怎麼做?的詳細內容。更多資訊請關注PHP中文網其他相關文章!