
機器人版的「史丹佛小鎮」來了,專為具身智慧研究打造

- WBOY原創
- 2024-07-22 14:24:11585瀏覽
首個專為各種機器人設計的模擬互動 3D 社會。
還記得史丹佛的 AI 小鎮嗎?這是史丹佛的 AI 研究者打造的一個虛擬環境。在這個小鎮上,25 個 AI 智能體正常生活、工作、社交,甚至談戀愛,每個智能體都有自己的個性和背景故事。智能體的行為和記憶透過大語言模型來驅動,這些模型能夠儲存和檢索智能體的經歷,並根據這些記憶來規劃行動。 (請參閱《史丹佛的「虛擬小鎮」開源了:25 個AI 智能體照進《西方世界》》)
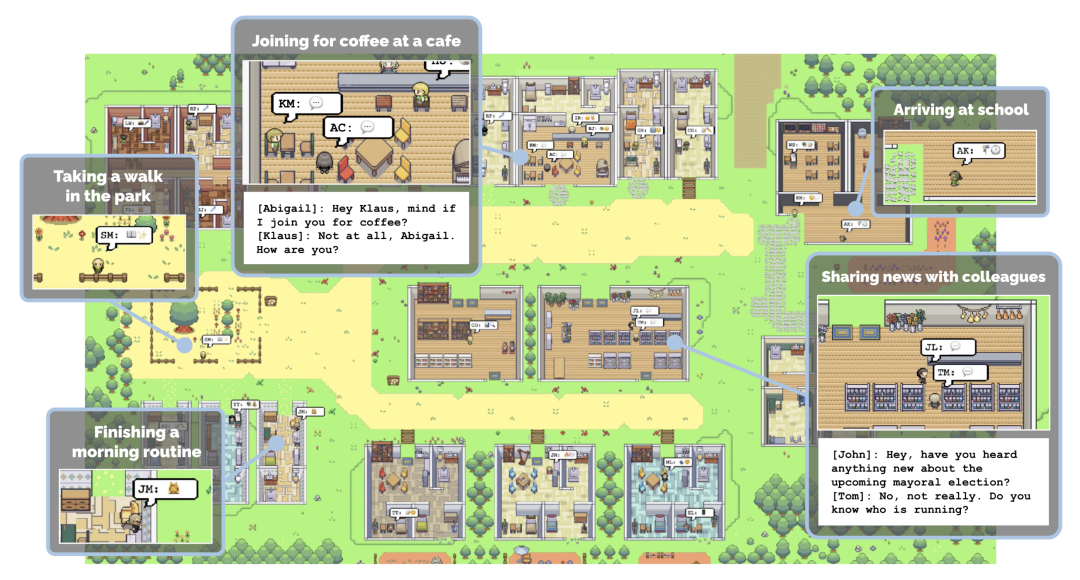
與之類似,最近,來自上海人工智慧實驗室OpenRobotLab 等機構的一批研究者也打造了一個虛擬小鎮。不過,生活在其中的是機器人和 NPC。  這個小鎮包含 10 萬個互動式場景和 89 種不同的場景類別,是第一個專為各種機器人設計的模擬互動 3D 社會。
這個小鎮包含 10 萬個互動式場景和 89 種不同的場景類別,是第一個專為各種機器人設計的模擬互動 3D 社會。

作者表示,他們設計這個環境是為了解決具身智慧領域的資料稀缺問題。眾所周知,由於收集真實世界數據的成本過高,在具身智慧領域探索 scaling law 一直困難重重。因此,從模擬到真實(Sim2Real)的範式成了擴展具身模型學習的關鍵步驟。
他們為機器人設計的這個虛擬環境名叫 GRUtopia,專案主要包括:
1、場景資料集 GRScenes。包含 10 萬個互動式、精細註釋的場景,可自由組合成城市規模的環境。與以往主要關注家庭的工作不同,GRScenes 涵蓋了 89 個不同的場景類別,彌補了服務型環境的空白(一般機器人最初會部署在服務型環境中)。
2、GRResidents。這是一個大型語言模型(LLM)驅動的非玩家角色(NPC)系統,負責社交互動、任務產生和任務分配,從而模擬具身 AI 應用的社交場景。
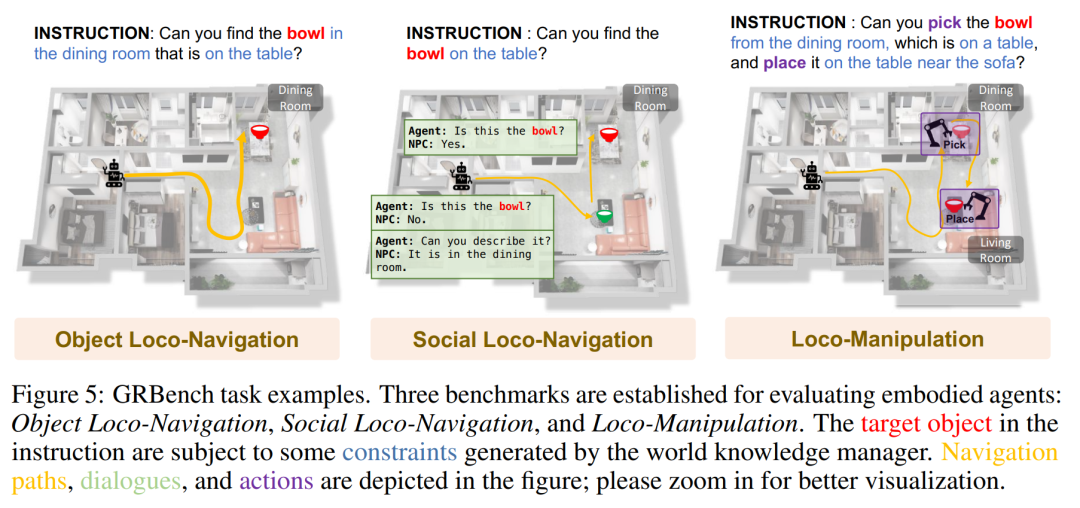
3、基準 GRBench。支援各種機器人,但專注於作為主要智慧體的有腿機器人,並提出了涉及物體定位導航、社交定位導航和定位操縱的中等難度任務。
作者希望這項工作能緩解該領域高品質資料稀缺的問題,並為具身 AI 研究提供更全面的評估。

論文標題:GRUtopia: Dream General Robots in a City at Scale
論文地址:https://arxiv.org/pdf/2407.10943com .com/OpenRobotLab/GRUtopia
- GRScenes:大規模的完全互動環境
要建立一個用於訓練和評估具身智能體的平台,具有不同場景和物體資產的完全交互式環境是必必不可少的。因此,作者收集了一個包含各種物件資產的大規模 3D 合成場景資料集,作為 GRUtopia 平台的基礎。
多樣、逼真的場景由於開源 3D 場景資料的數量和類別有限,作者首先從設計師網站上收集了約 10 萬個高品質的合成場景,從而獲得多樣化的場景原型。然後,他們對這些場景原型進行清理,並對其進行區域和物體級別的語義註釋,最後將它們組合在一起,形成城鎮,作為機器人的基本遊樂場。 如圖 2-(a) 所示,除了常見的家庭場景外,作者建構的資料集中還有 30% 的其他不同類別的場景,如餐廳、辦公室、公共場所、飯店、娛樂等。作者從大規模資料集中初步篩選出 100 個帶有精細註釋的場景,用於開源基準測試。這 100 個場景包括 70 個家庭場景和 30 個商業場景,其中家庭場景由綜合性常見區域和其他不同區域組成,商業場景涵蓋醫院、超市、餐廳、學校、圖書館和辦公室等常見類型。
此外,作者還與幾位專業設計師合作,按照人類的生活習慣來分配物體,使這些場景更加逼真,如圖 1 所示,而這在以前的作品中通常是被忽略的。
具有部件(part)級註釋的交互式物體
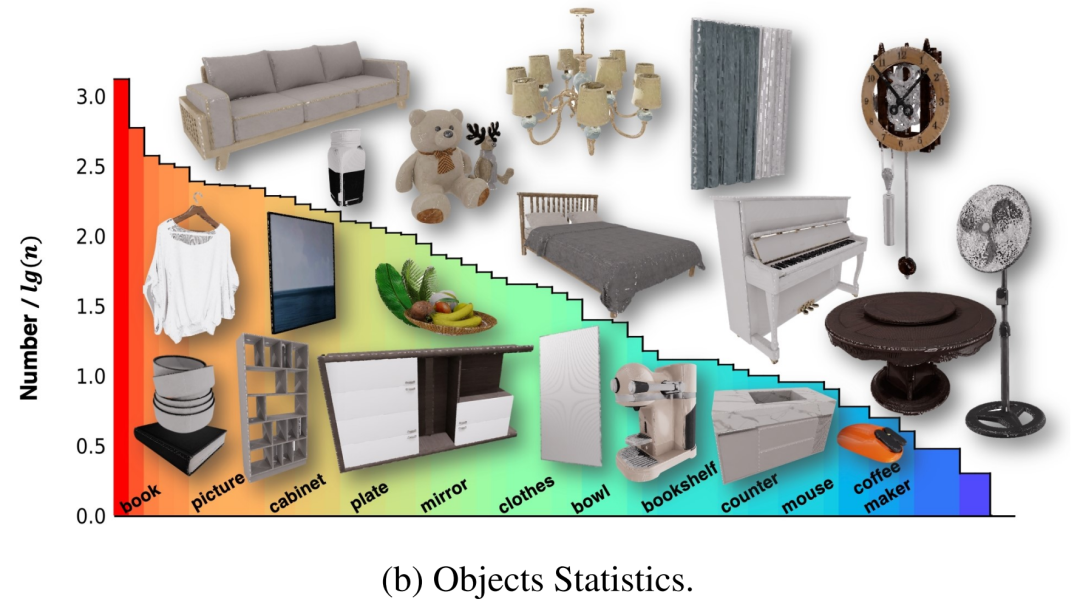
這些場景原本包含多個 3D 物體,但其中一些沒有內部建模,因此無法訓練機器人與這些物體進行交互。為了解決這個問題,作者與專業團隊合作,對這些資產進行修改,並創建完整的物體,使它們能夠以物理上可信的方式進行互動。此外,為了提供更全面的信息,使智能體能夠與這些資產進行交互,作者在英偉達 Omniverse 中以 X 形式為所有物體的交互部件附加了細粒度部件標籤。最後,100 個情境包含 96 個類別的 2956 個互動式物件和 22001 個非互動式物體,其分佈如圖 2-(b) 所示。
分層多模態註釋
最後,為了實現具身智能體與環境以及 NPC 的多模態交互,還需要對這些場景和對象進行語言註釋。與先前的多模態 3D 場景資料集只關注物件層面或物件間關係不同,作者也考慮了場景元素的不同粒度,例如物件與區域的關係。鑑於缺乏區域標籤,作者首先設計了一個使用者介面,在場景鳥瞰圖上用多邊形註釋區域,然後可以在語言註釋中涉及物件 - 區域關係。對於每個對象,他們都會用渲染的多視圖圖像提示強大的 VLM(如 GPT-4v),以初始化註釋,然後由人工進行檢查。由此產生的語言註釋為後續基準測試生成具身任務提供了基礎。
GRResidents3D 環境中的生成式 NPC
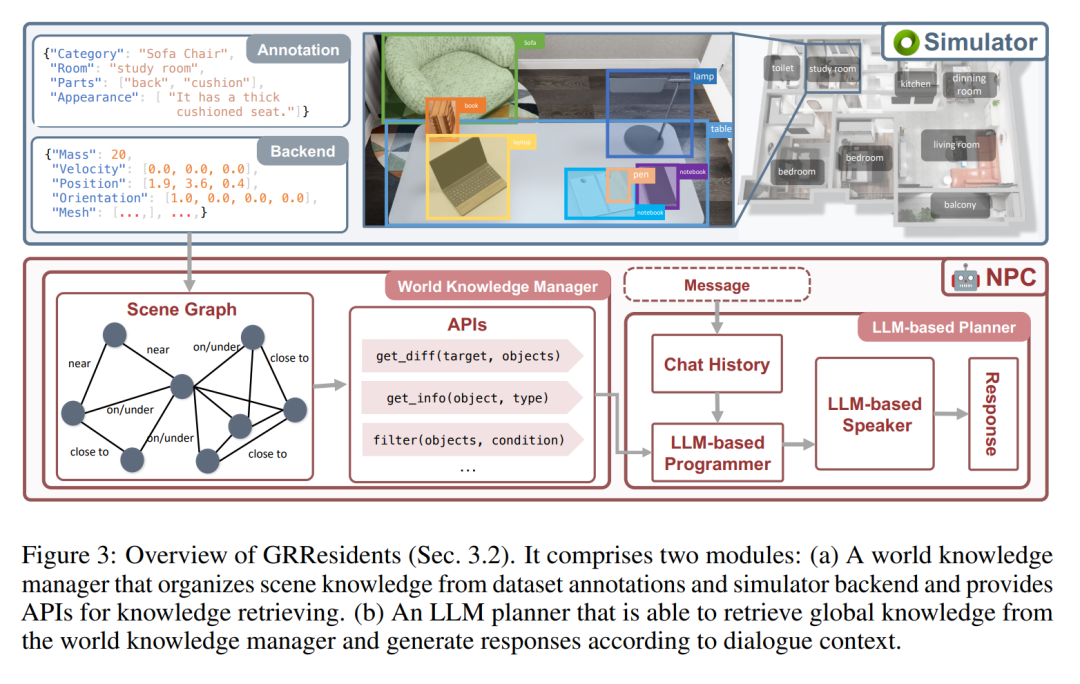
在 GRUtopia 中,作者透過嵌入一些「居民」(即由 LLM 驅動的生成式 NPC)來賦予世界以社交能力,從而模擬城市環境中的社會互動。這個 NPC 系統被命名為 GRResidents。在 3D 場景中建立真實虛擬角色的主要挑戰之一是整合 3D 感知能力。然而,虛擬角色可以輕鬆存取場景註釋和模擬世界的內部狀態,從而實現強大的感知能力。為此,作者設計了一個世界知識管理器(WKM),用於管理即時世界狀態的動態知識,並透過一系列資料介面提供存取。借助 WKM,NPC 可以檢索所需的知識,並透過參數化函數呼叫執行細粒度的物件 grounding,這構成了其感知能力的核心。
世界知識管理器(WKM)
WKM 的主要職責是持續管理虛擬環境知識,並向 NPC 提供高階場景知識。具體來說,WKM 分別從資料集和模擬器後台獲取分層註釋和場景知識,建構場景圖作為場景表示,其中每個節點表示一個物件實例,邊表示物件之間的空間關係。作者採用 Sr3D 中定義的空間關係作為關係空間。 WKM 會在每個模擬步驟中保留該場景圖。此外,WKM 還提供了三個核心資料接口,用於從場景圖中提取知識:
1、find_diff (target, objects):比較目標物件與一組其他物件之間的差異;
2、get_info (object, type):根據所需的屬性類型取得物件的知識;
3、filter (objects, condition)::根據條件過濾物件。
LLM 規劃器
NPC 的決策模組是一個基於LLM 的規劃器,由三個部分組成(圖3):一個儲存模組,用於儲存NPC 與其他智能體之間的聊天歷史記錄;一個LLM 程式設計師,使用WKM 的介面來查詢場景知識;以及一個LLM 發言器,用於消化聊天歷史記錄和查詢到的知識,從而產生回應。當一個 NPC 收到一條訊息時,它會先將訊息儲存在記憶體中,然後將更新的歷史記錄轉發給 LLM 程式設計師。然後,程式設計師會重複呼叫資料介面來查詢必要的場景知識。最後,將知識和歷史記錄發送給 LLM 發言器,由其產生回應。
實驗
作者進行了對象指代、語言grounding 和以對象為中心的QA 等方面的實驗,以證明論文中的NPC 能夠生成對象說明,透過描述定位對象,以及為智能體提供對象資訊。這些實驗中的 NPC 後端 LLM 包括 GPT-4o、InternLM2-Chat-20B 和 Llama-3-70BInstruct。
如圖 4 所示,在指涉實驗中,作者採用了 human-in-the-loop 評估。 NPC 隨機選擇一個物件並對其進行描述,然後人類註釋者根據描述選擇一個物件。如果人類註釋者能找到與描述相對應的正確對象,則指涉成功。在 grounding 實驗中,GPT-4o 扮演了人類註釋者的角色,它提供了一個物體的描述,然後由 NPC 對其進行定位。如果 NPC 能夠找到相應的物體,則 grounding 成功。
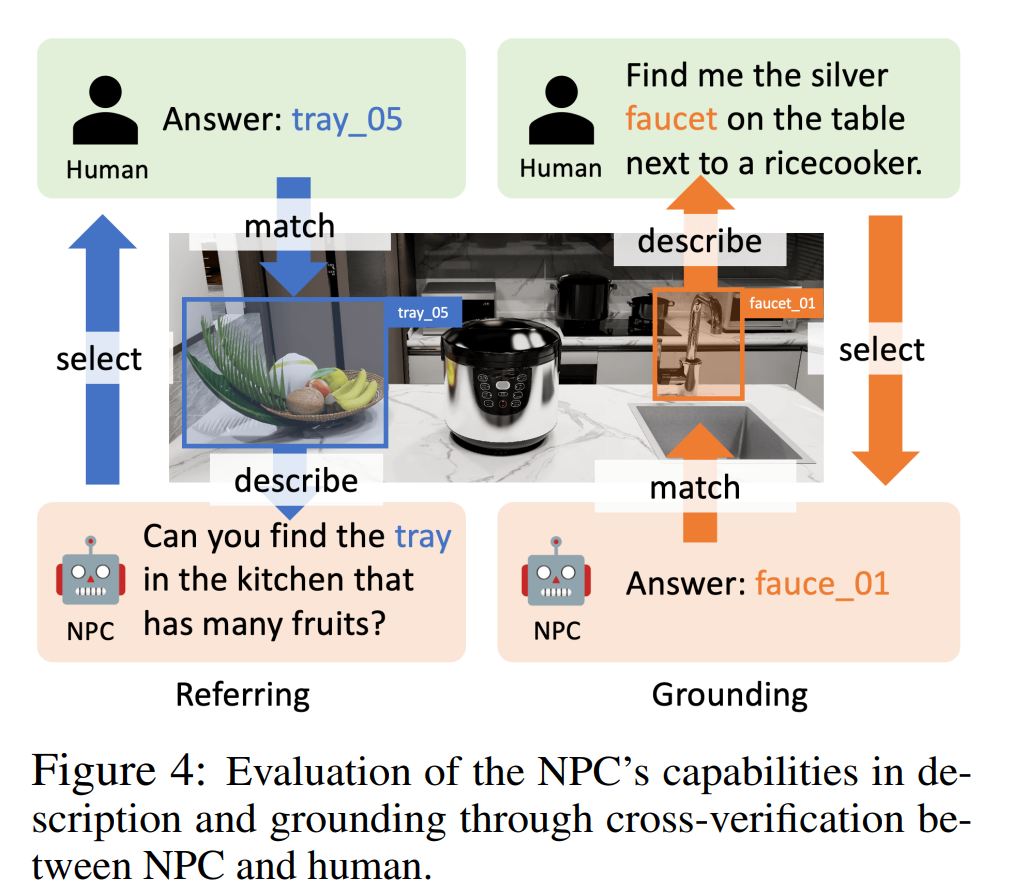
表2 中的成功率(指涉和grounding)顯示,不同LLM 的準確率分別為95.9%-100% 和83.3%-93.2% ,這驗證了我們的NPC 框架在不同LLM 中指稱和接地的準確性。
在以物件為中心的 QA 實驗中,作者評估了 NPC 在導航任務中透過回答問題向智能體提供物件層級資訊的能力。他們設計了一個 pipeline 來產生以物件為中心的導航情節,模擬真實世界的場景。在這些場景中,智能體向 NPC 提問以獲取信息,並根據回答採取行動。在給定智能體問題後,作者根據 NPC 的答案與真實答案之間的語義相似性對其進行評估。表 2(QA)中顯示的總體得分錶明,NPC 可以提供精確且有用的導航幫助。
GRBench:評估具身智能體的基準
GRBench 是評估機器人智能體能力的綜合評估工具。為了評估機器人智能體處理日常任務的能力,GRBench 包括三個基準:物件定位導航、社交定位導航和定位操作。這些基準的難度逐漸增加,對機器人技能的要求也隨之提高。
由於腿式機器人具有卓越的跨地形能力,作者優先考慮將其作為主要智能體。然而,在大規模場景中,要同時執行高階感知、規劃和低階控制並取得令人滿意的結果,對目前的演算法來說具有挑戰性。
GRBench 的最新進展證明了在模擬中針對單項技能訓練高精度策略的可行性,受此啟發,GRBench 的初始版本將重點放在高級任務上,並提供基於學習的控制策略作為API,如行走和拾放。因此,他們的基準提供了更真實的物理環境,縮小了模擬與真實世界之間的差距。
下圖是 GRBench 的一些任務範例。
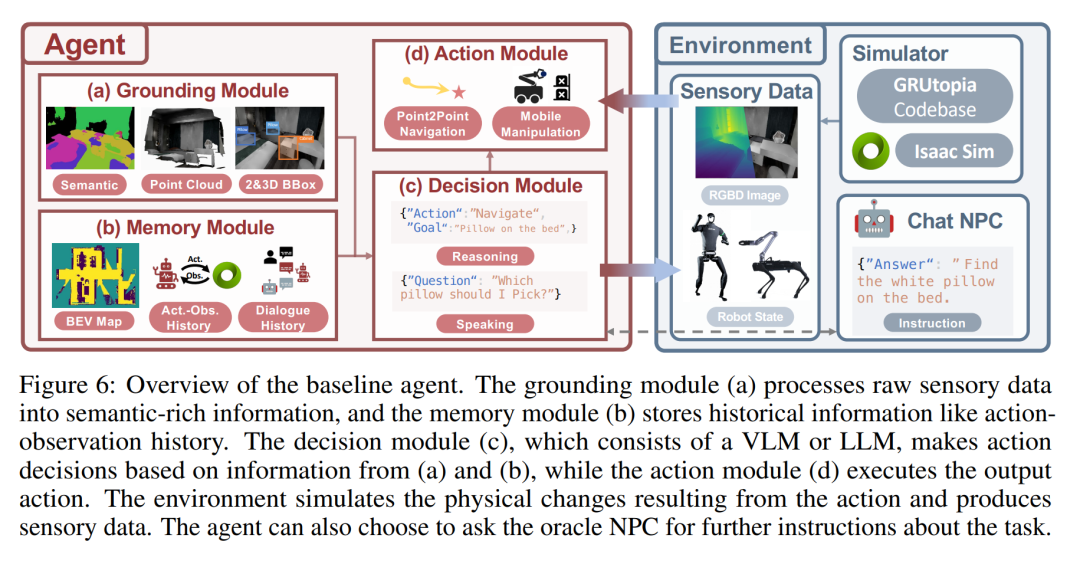
下圖是基準智能體的概覽。 grounding 模組 (a) 將原始感官資料處理成語意豐富的訊息,記憶模組(b)儲存行動觀察歷史等歷史資訊。決策模組(c)由 VLM 或 LLM 組成,根據(a)和(b)的資訊做出行動決策,而行動模組(d)則執行輸出的行動。環境模擬行動帶來的物理變化,並產生感官資料。智能體可以選擇向顧問 NPC 詢問有關任務的進一步指示。
定量評估結果
作者在三個基準測試中對不同大型模型後端下的大型模型驅動智能體框架進行了比較分析。如表 4 所示,他們發現隨機策略的表現接近 0,這表明他們的任務並不簡單。當使用相對較優的大型模型作為後端時,他們在所有三個基準測試中都觀察到了明顯更好的整體性能。值得一提的是,他們觀察到 Qwen 在對話中的表現優於 GPT-4o(見表 5)。
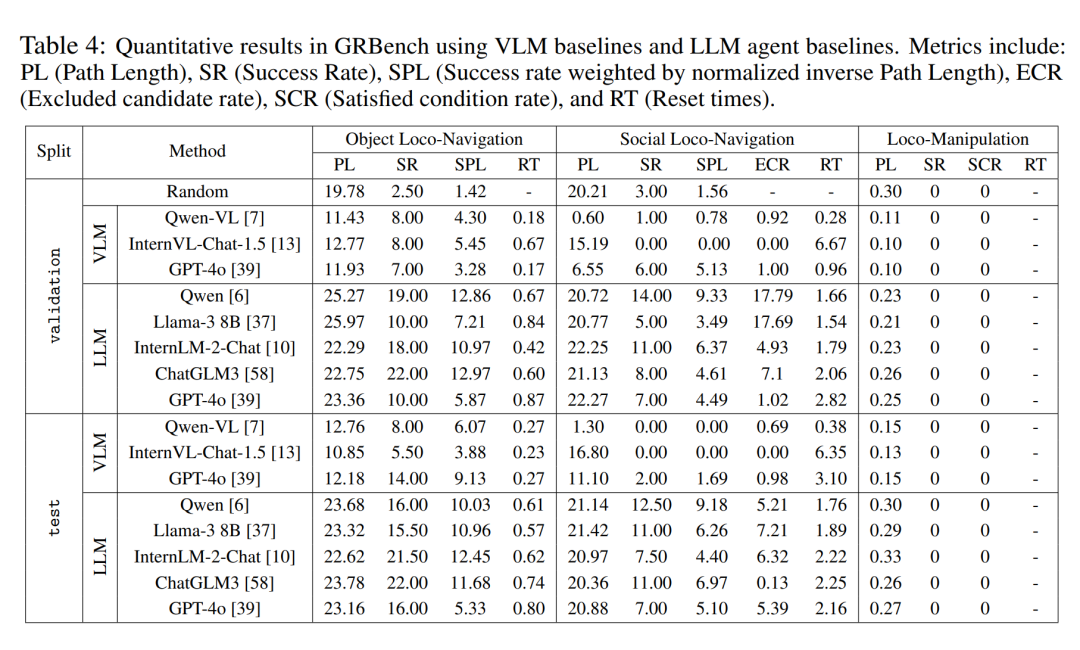

此外,與直接使用多模態大模型進行決策相比,本文提出的智能體框架表現出明顯的優越性。這表明,即使是目前最先進的多模態大型模型,在現實世界的具身任務中也缺乏強大的泛化能力。不過,本文的方法也有相當進步的空間。這表明,當引入更接近真實世界的任務設定時,即使是像導航這樣已經研究多年的任務,仍然遠未完全解決。
定性評估結果
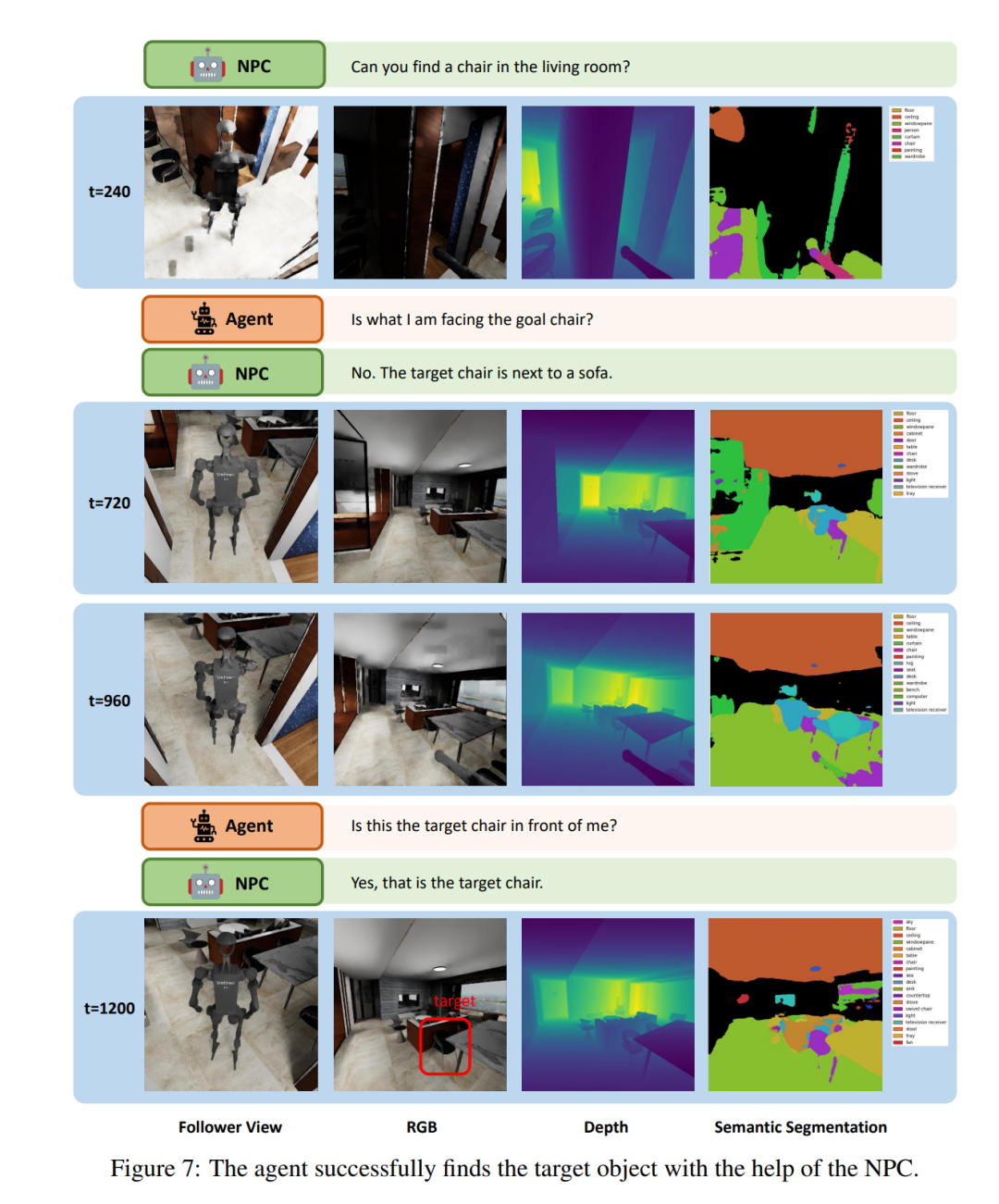
圖 7 展示了 LLM 智能體在「社會定位導航」(Social Loco-Navigation)任務中執行的一個小片段,以說明智能體如何與 NPC 互動。此智能體最多可與 NPC 對話三次,以查詢更多任務資訊。在 t = 240 時,智能體導航到一張椅子前,詢問 NPC 這張椅子是否是目標椅。然後,NPC 提供有關目標的周邊信息,以減少模糊性。在 NPC 的協助下,智能體透過類似人類行為的互動過程成功地辨識了目標椅。這表明,本文中的 NPC 能夠為研究人與機器人的互動和協作提供自然的社會互動。
以上是機器人版的「史丹佛小鎮」來了,專為具身智慧研究打造的詳細內容。更多資訊請關注PHP中文網其他相關文章!