
Ibis 聲明式多引擎資料堆疊

- 王林原創
- 2024-07-19 03:34:101576瀏覽
長話短說
我最近看到了 Julien Hurault 撰寫的關於多引擎資料堆疊的 Ju Data Engineering Newsletter。這個想法很簡單;我們希望輕鬆地將程式碼移植到任何後端,同時保留隨著新後端和功能的開發而擴展管道的靈活性。這至少需要以下高階工作流程:
- 使用 DuckDB、Polars、DataFusion、chdb 等將 SQL 查詢的一部分卸載到無伺服器引擎。
- 適合各種開發和部署場景的適當大小的管道。例如,開發人員可以在本地工作並放心地交付生產。
- 自動將資料庫樣式最佳化套用到您的管道。
在這篇文章中,我們深入探討如何透過程式語言實現多引擎管道;我們建議使用可用於互動式和批次用例的 Dataframe API,而不是 SQL。具體來說,我們展示瞭如何將管道分解為較小的部分,並在 DuckDB、pandas 和 Snowflake 上執行它們。我們也討論了多引擎資料堆疊的優勢,並重點介紹了該領域的新興趨勢。
這篇文章中實作的程式碼可以在 GitHub 上找到^[為了快速嘗試 repo,我還提供了一個 nix flake]。時事通訊中的參考工作以及原始實作在這裡。
概述
多引擎資料堆疊管道的工作原理如下:一些資料進入S3 儲存桶,進行預處理以刪除任何重複項,然後載入到Snowflake 表中,在其中使用ML 或Snowflake 特定函數進一步轉換^[請注意我們不會去實現Snowflake 中可能實現的事物類型,並假設這是工作流程的要求]。該管道將訂單作為 parquet 檔案保存到登陸位置,經過預處理,然後儲存在 S3 儲存桶中的暫存位置。然後,暫存資料會載入到 Snowflake 中,以將下游 BI 工具連接到它。該管道透過 SQL dbt 連接在一起,每個後端都有一個模型,並且時事通訊選擇 Dagster 作為編排工具。
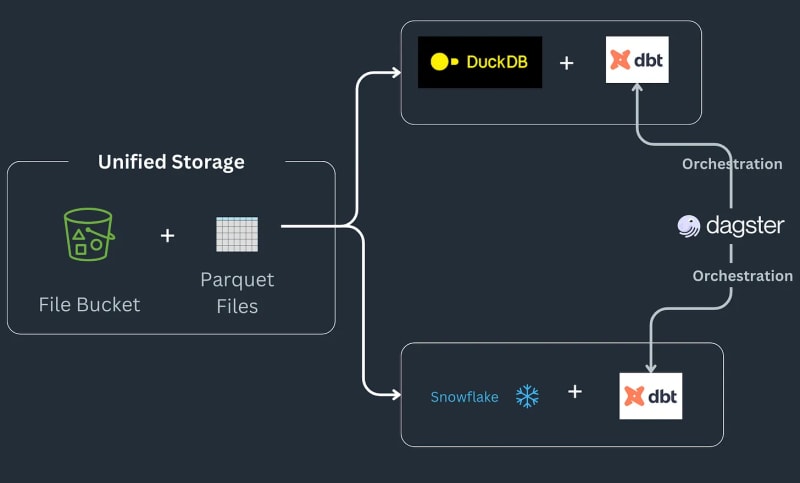
今天,我們將深入研究如何將 pandas 程式碼轉換為 Ibis 表達式,重現 Julien Hurault 的多引擎堆疊範例 1 的完整範例。我們不使用 dbt 模型和 SQL,而是使用 ibis 和一些 Python 從 shell 編譯和編排 SQL 引擎。透過將程式碼重寫為 Ibis 表達式,我們可以以聲明方式建立具有延遲執行的資料管道。此外,Ibis 支援 20 多個後端,因此我們只需編寫一次程式碼即可將 ibis.exprs 移植到多個後端。為了進一步簡化,我們將 Dagster 提供的調度和任務編排2 留給讀者。
多引擎資料堆疊核心概念
以下是 Julien 電子報中概述的多引擎資料堆疊的核心概念:
- 多引擎資料堆疊:這個概念涉及結合不同的資料引擎,如 Snowflake、Spark、DuckDB 和 BigQuery。這種方法旨在降低成本、限制供應商鎖定並提高靈活性。 Julien 提到,對於某些基準查詢,與 Snowflake 相比,使用 DuckDB 可以大幅降低成本。
- 跨引擎查詢層的開發:新聞通訊重點介紹了技術進步,這些進步允許資料團隊將 SQL 或 Dataframe 程式碼從一個引擎無縫轉換到另一個引擎。這一發展對於維持不同引擎的效率至關重要。
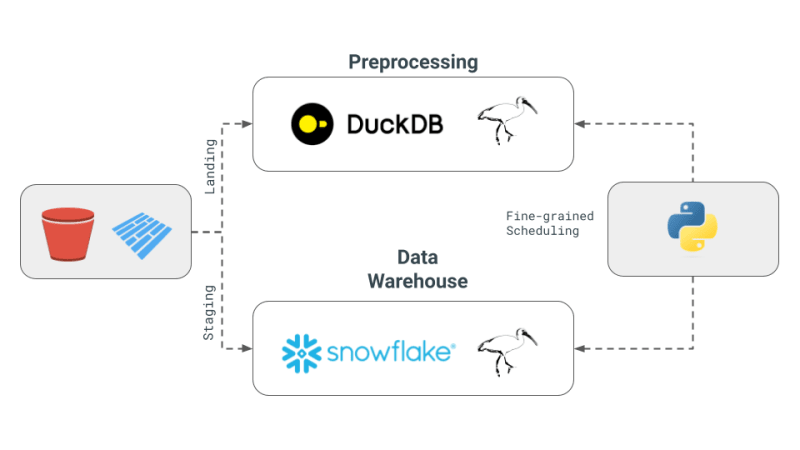
- Apache Iceberg 和替代方案的使用: 雖然 Apache Iceberg 被視為潛在的統一儲存層,但其整合尚未成熟,無法在 dbt 專案中使用。相反,Julien 在他的概念驗證 (PoC) 中選擇使用儲存在 S3 中的 Parquet 文件,由 DuckDB 和 Snowflake 存取。
- PoC 中的編排和引擎: 在這個專案中,Julien 使用 Dagster 作為編排器,這簡化了 dbt 專案中不同引擎的作業調度。此 PoC 中組合的引擎是 DuckDB 和 Snowflake。
為什麼選擇 DataFrames 和 Ibis?
雖然上面的管道對於 ETL 和 ELT 來說很好,但有時我們需要完整的程式語言的功能,而不是像 SQL 這樣的查詢語言,例如偵錯、測試、複雜的 UDF 等。對於科學探索,互動式計算至關重要,因為資料科學家需要快速迭代程式碼、視覺化結果並根據資料做出決策。
DataFrame 是這樣一種資料結構:DataFrame 用於處理有序資料並以互動方式對其應用計算操作。它們提供了能夠透過 SQL 樣式操作處理大數據的靈活性,而且還提供了較低層級的控制來編輯單元格層級變更(如 Excel 工作表)。 通常,期望所有資料都在記憶體中處理並且通常適合記憶體。此外,DataFrame 可以輕鬆地在延遲/批次和互動模式之間來回切換。
DataFrames 擅長^[沒有雙關語] 讓人們能夠應用使用者定義的函數並將使用者從SQL 的限制中釋放出來,即您現在可以重用程式碼,測試您的操作,輕鬆擴展關係機制以執行複雜的操作。 DataFrame 還可以輕鬆地將資料的表格表示快速轉換為機器學習庫所期望的陣列和張量。
專業和進程中的資料庫,例如DuckDB for OLAP3 正在模糊像 Snowflake 這樣的遠端重量級資料庫和像 pandas 這樣符合人體工學的庫之間的界限。我們相信這是一個機會,允許 DataFrame 處理大於記憶體的數據,同時保持本地 Python shell 的互動性期望和開發人員的感覺,讓大於記憶體的數據感覺很小。
技術深入探討
我們的實作重點在於先前提出的 4 個概念:
- 多引擎資料堆疊:我們將使用 DuckDB、pandas 和 Snowflake 作為引擎。
- 跨引擎查詢層:我們將使用 Ibis 編寫表達式並編譯它們以在 DuckDB、pandas 和 Snowflake 上運行。
- Apache Iceberg 和替代方案:我們將使用本地儲存的 Parquet 檔案作為我們的儲存層,並期望使用 s3fs 套件輕鬆擴展到 S3。
- PoC 中的編排和引擎:我們將專注於引擎的細粒度調度,而將編排留給讀者。與編排框架相比,細粒度調度更適合 Ray、Dask、PySpark。 Dagster、氣流等
用pandas實現

pandas 是典型的 DataFrame 函式庫,也許提供了實現上述工作流程最簡單的方法。首先,我們借用時事通訊中的實作來產生隨機資料。
#| echo: false
import pandas as pd
from multi_engine_stack_ibis.generator import generate_random_data
generate_random_data("landing/orders.parquet")
df = pd.read_parquet("landing/orders.parquet")
deduped = df.drop_duplicates(["order_id", "dt"])
pandas 的實作在風格上是命令式的,並且被設計成可以容納記憶體的資料。 pandas API 很難編譯為 SQL 及其所有細微差別,並且很大程度上位於自己的特殊位置,將 Python 視覺化、繪圖、機器學習、AI 和複雜的處理庫結合在一起。
pt.write_pandas(
conn,
deduped,
table_name="T_ORDERS",
auto_create_table=True,
quote_identifiers=False,
table_type="temporary"
)
使用pandas算子去重後,我們準備將資料傳送到Snowflake。 Snowflake 有一個名為 write_pandas 的方法,對於我們的用例來說非常方便。
使用 Ibis aka Ibisify 實施
pandas 的一個限制是它有自己的 API,不能完全映射回關係代數。 Ibis 就是這樣一個函式庫,它實際上是由建構 pandas 的人建構的,以提供可以映射回多個 SQL 後端的健全的表達式系統。 Ibis 從 dplyr R 套件中汲取靈感,建立了一個新的表達式系統,可以輕鬆映射回關係代數,從而編譯為 SQL。它在風格上也是聲明性的,使我們能夠在完整的邏輯計劃或表達式上應用資料庫風格優化。 Ibis 是實現可組合性的關鍵組件,正如優秀的可組合程式碼中所強調的那樣。
#| echo: false
import pathlib
import ibis
import ibis.backends.pandas.executor
import ibis.expr.types.relations
from ibis import _
from multi_engine_stack_ibis.generator import generate_random_data
from multi_engine_stack_ibis.utils import (MyExecutor, checkpoint_parquet,
create_table_snowflake,
replace_unbound)
from multi_engine_stack_ibis.connections import make_ibis_snowflake_connection
ibis.backends.pandas.executor.PandasExecutor = MyExecutor
setattr(ibis.expr.types.relations.Table, "checkpoint_parquet", checkpoint_parquet)
setattr(
ibis.expr.types.relations.Table,
"create_table_snowflake",
create_table_snowflake,
)
ibis.set_backend("pandas")
p_staging = pathlib.Path("staging/staging.parquet")
p_landing = pathlib.Path("landing/orders.parquet")
snow_backend = make_ibis_snowflake_connection(database="MULTI_ENGINE", schema="PUBLIC", warehouse="COMPUTE_WH")
expr = (
ibis.read_parquet(p_landing)
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt]))
.filter(_.row_number == 0)
.checkpoint_parquet(p_staging)
.create_table_snowflake("T_ORDERS")
)
expr
Ibis 表達式將自身列印為類似於資料庫中傳統邏輯計劃的計劃。邏輯計劃是關係代數運算子的樹,描述需要執行的計算。然後,該計劃由查詢最佳化器最佳化,並轉換為由查詢執行器執行的實體計劃。 Ibis 表達式與邏輯計劃類似,它們描述需要執行的計算,但不會立即執行。相反,它們被編譯成 SQL 並在需要時在後端執行。邏輯計劃通常比 Dask 等任務調度框架產生的 DAG 具有更高的粒度。理論上,這個計畫可以編譯成 Dask 的 DAG。
While pandas is embedded and is just a pip install away, it still has much documented limitations with plenty of performance improvements left on the table. This is where the recent embedded databases like DuckDB fill the gap of packing the full punch of a SQL engine, with all of its optimizations and benefiting from years of research that is as easy to import as is pandas. In this world, at minimum we can delegate all relational and SQL parts of our pipeline in pandas to DuckDB and only get the processed data ready for complex user defined Python.
Now, we are ready to take our Ibisified code and compile our expression above to execute on arbitrary engines, to truly realize the write-once-run-anywhere paradigm: We have successfully decoupled our compute engine with the expression system describing our computation.
Multi-Engine Data Stack w/ Ibis
DuckDB + pandas + Snowflake
Let's break our expression above into smaller parts and have them run across DuckDB, pandas and Snowflake. Note that we are not doing anything once the data lands in Snowflake and just show that we can select the data. Instead, we are leaving that up to the user's imagination what is possible with Snowflake native features.
Notice our expression above is bound to the pandas backend. First, lets create an UnboundTable expression to not have to depend on a backend when writing our expressions.

schema = {
"user_id": "int64",
"dt": "timestamp",
"order_id": "string",
"quantity": "int64",
"purchase_price": "float64",
"sku": "string",
"row_number": "int64",
}
first_expr_for = (
ibis.table(schema, name="orders")
.mutate(
row_number=ibis.row_number().over(group_by=[_.order_id], order_by=[_.dt])
)
.filter(_.row_number == 0)
)
first_expr_for
Next, we replace the UnboundTable expression with the DuckDB backend and execute it with to_parquet method4. This step is covered by the checkpoint_parquet operator that we added to pandas backend above. Here is an excellent blog that discusses inserting data into Snowflake from any Ibis backend with to_pyarrow functionality.
data = pd.read_parquet("landing/orders.parquet")
duck_backend = ibis.duckdb.connect()
duck_backend.con.execute("CREATE TABLE orders as SELECT * from data")
bind_to_duckdb = replace_unbound(first_expr_for, duck_backend)
bind_to_duckdb.to_parquet(p_staging)
to_sql = ibis.to_sql(bind_to_duckdb)
print(to_sql)
Once the above step creates the de-duplicated table, we can then send data to Snowflake using the pandas backend. This functionality is covered by create_table_snowflake operator that we added to pandas backend above.
second_expr_for = ibis.table(schema, name="T_ORDERS") # nothing special just a reading the data from orders table
snow_backend.create_table("T_ORDERS", schema=second_expr_for.schema(), temp=True)
pandas_backend = ibis.pandas.connect({"T_ORDERS": pd.read_parquet(p_staging)})
snow_backend.insert("T_ORDERS", pandas_backend.to_pyarrow(second_expr_for))
Finally, we can select the data from the Snowflake table to verify that the data has been loaded successfully.
third_expr_for = ibis.table(schema, name="T_ORDERS") # add you Snowflake ML functions here third_expr_for
We successfully broke up our computation in pieces, albeit manually, and executed them across DuckDB, pandas, and Snowflake. This demonstrates the flexibility and power of a multi-engine data stack, allowing users to leverage the strengths of different engines to optimize their data processing pipelines.
Acknowledgments
I'd like to thank Neal Richardson, Dan Lovell and Daniel Mesejo for providing the initial feedback on the post. I highly appreciate the early review and encouragement by Wes McKinney.
Resources
- The Road to Composable Data Systems
- The Composable Codex
- Apache Arrow
- Multi-Engine Data Stack Newsleter v0 v1
- Ibis, the portable dataframe library
- dbt Docs
- Dagster Docs
- LanceDB
- KuzuDB
- DuckDB
-
In this post, we have primarily focused on v0 of the multi-engine data stack. In the latest version, Apache Iceberg is included as a storage and data format layer. NYC Taxi data is used instead of the random Orders data treated in this and v0 of the posts. ↩
-
Orchestration Vs fine-grained scheduling: ↩
- The orchestration is left to the reader. The orchestration can be done using a tool like Dagster, Prefect, or Apache Airflow.
- The fine-grained scheduling can be done using a tool like Dask, Ray, or Spark.
-
Some of the examples of in-process databases is described in this post extending DuckDB example above to newer purpose built databases like LanceDB and KuzuDB. ↩
-
The Ibis docs use backend.to_pandas(expr) commands to bind and run the expression in the same go. Instead, we use replace_unbound method to show a generic way to just compile the expression and not execute it to said backend. This is just for illustration purposes. All the code below, uses the backend.to_pyarrow methods from here on. ↩
以上是Ibis 聲明式多引擎資料堆疊的詳細內容。更多資訊請關注PHP中文網其他相關文章!