
登頂開源AI軟體工程師榜首,UIUC無Agent方案輕鬆解決SWE-bench真實程式設計問題

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-07-17 22:02:051406瀏覽

AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
這篇論文的作者皆來自伊利諾大學香檳分校(UIUC)張令明老師團隊,包括:Steven Xia,四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生,研究方向是四年級博士生基於AI 大模型的自動代碼修復;鄧茵琳,四年級博士生,研究方向是基於AI 大模型的代碼生成;Soren Dunn,科研實習生,目前為UIUC 大三學生。張令明老師現任 UIUC 電腦系副教授,主要從事軟體工程、機器學習、程式碼大模型的相關研究。
更多詳細資訊請見張老師的個人主頁:https://lingming.cs.illinois.edu/
自從Devin(首個全自動AI 軟體工程師)提出以來,針對軟體工程的AI Agent 的設計成為研究的焦點,越來越多基於Agent 的AI 自動軟體工程師被提出,並在SWE-bench 資料集上取得了不俗的表現、自動修復了許多真實的GitHub issue。
然而,複雜的 Agent 系統會帶來額外的開銷和不確定性,我們真的需要使用如此複雜的 Agent 來解決 GitHub issue 嗎?不依賴 Agent 的解決方案能接近它們的效能嗎?
從這兩個問題出發,伊利諾大學香檳分校(UIUC)張令明老師團隊提出了 OpenAutoCoder-Agentless,一個簡單高效並且完全開源的無 Agent 方案,僅需 $0.34 就能解決一個真實的 GitHub issue。 Agentless 在短短幾天內在 GitHub 上已經吸引了超過 300 GitHub Star,並登上了 DAIR.AI 每週最熱 ML 論文榜單前三。

論文:AGENTLESS : Demystifying LLM-based Software Engineering Agents
論文位址:https://huggingface.co/papers/
論文位址:https://huggingface.co/papers/2407.0148899. /OpenAutoCoder/Agentless- AWS 研究科學家Leo Boytsov 表示:「Agentless 框架表現優異,超過所有開源Agent 解決方案,幾乎達到SWE Bench Lite 最高水平(27%)。而且,它以顯著更低的成本擊敗了所有開源方案。 Agentless 是一種自動解決軟體開發問題的方法,它使用簡單的兩階段方法進行定位和修復,以修復程式碼庫中的bug。在定位階段,Agentless 以分層方式逐步縮小到可疑的檔案、類別 / 函數和具體的編輯位置。對於修復,它使用簡單的 diff 格式(參考自開源工具 Aider)來產生多個候選補丁,並對其進行過濾和排序。
 研究者將 Agentless 與現有的 AI Software Agent 進行了比較,其中包括最先進的開源和商業 / 閉源專案。令人驚訝的是,Agentless 可以以更低的成本超越所有現有的開源 Software Agent! Agentless 解決了 27.33% 的問題,是開源方案中最高的,並且解決每個問題平均僅需 $0.29,在所有問題上(包括能解決和未解決的)平均只需要約 $0.34。
研究者將 Agentless 與現有的 AI Software Agent 進行了比較,其中包括最先進的開源和商業 / 閉源專案。令人驚訝的是,Agentless 可以以更低的成本超越所有現有的開源 Software Agent! Agentless 解決了 27.33% 的問題,是開源方案中最高的,並且解決每個問題平均僅需 $0.29,在所有問題上(包括能解決和未解決的)平均只需要約 $0.34。
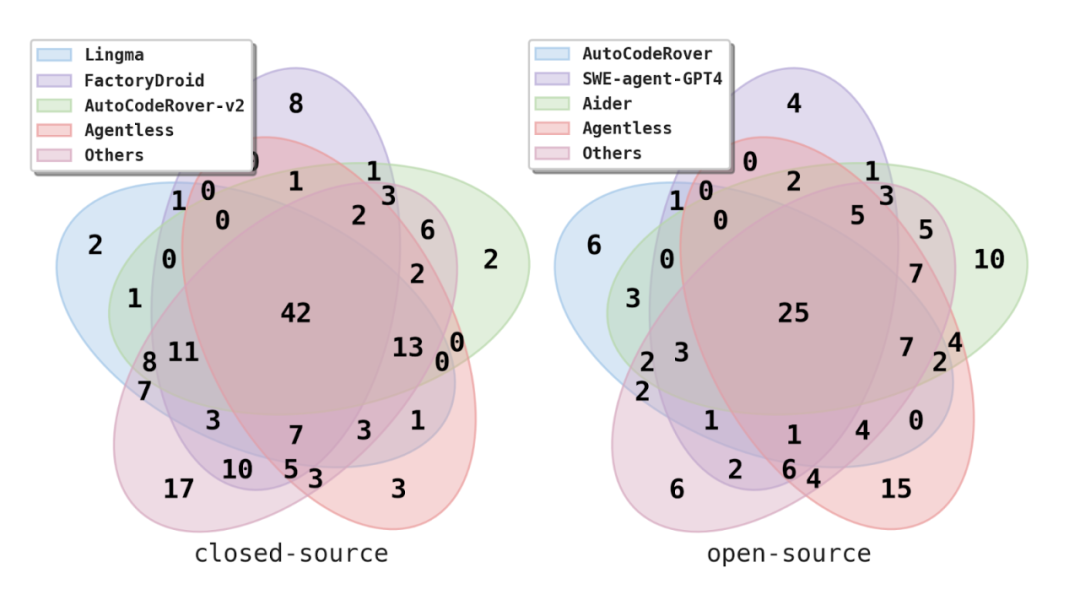
 不僅如此,Agentless 還有改進的潛力。在考慮所有產生的補丁時,Agentless 可以解決 41% 的問題,這個上限表明補丁排序和選擇階段有顯著的改進空間。此外,Agentless 能夠解決一些即使是最好的商業工具(Alibaba Lingma Agent)也無法解決的獨特問題,這表明它可以作為現有工具的補充。
不僅如此,Agentless 還有改進的潛力。在考慮所有產生的補丁時,Agentless 可以解決 41% 的問題,這個上限表明補丁排序和選擇階段有顯著的改進空間。此外,Agentless 能夠解決一些即使是最好的商業工具(Alibaba Lingma Agent)也無法解決的獨特問題,這表明它可以作為現有工具的補充。
SWE-bench Lite 데이터 세트 분석
연구원들은 SWE-bench Lite 데이터 세트에 대한 수동 검사와 상세한 분석도 수행했습니다.
연구에 따르면 SWE-bench Lite 데이터 세트의 문제 중 4.3%가 문제 설명에서 직접 완전한 답변을 제공했으며, 이는 올바른 수정 패치입니다. 질문의 나머지 10%는 올바른 솔루션을 위한 정확한 단계를 설명합니다. 이는 SWE-bench Lite의 일부 문제가 해결하기 더 쉬울 수 있음을 의미합니다.
또한 연구팀은 문제의 4.3%에 사용자가 제안한 해결 방법이나 문제 설명 단계가 포함되어 있지만 이러한 해결 방법이 개발자의 실제 패치와 일치하지 않는 것을 관찰했습니다. 이러한 오해의 소지가 있는 솔루션으로 인해 AI 도구가 단순히 문제 설명을 따르는 것만으로도 잘못된 솔루션을 생성할 수 있기 때문에 이는 이 벤치마크의 잠재적인 문제를 더욱 드러냅니다.
문제 설명 품질 측면에서 연구원들은 SWE-bench Lite의 대부분 작업에 충분한 정보가 포함되어 있고 많은 작업이 오류 재현을 위한 실패 사례를 제공하지만 여전히 9.3%의 문제에 정보가 충분하지 않다는 것을 관찰했습니다. 예를 들어, 새로운 기능을 구현하거나 오류 메시지를 추가해야 하는데 문제 설명에 특정 함수 이름이나 특정 오류 메시지 문자열이 제공되지 않습니다. 즉, 기본 기능이 올바르게 구현되더라도 함수 이름이나 오류 메시지 문자열이 정확히 일치하지 않으면 테스트가 실패합니다.

Princeton University의 연구원이자 SWE-Bench의 저자 중 한 명인 Ofir Press는 자신의 연구 결과를 다음과 같이 확인했습니다. "Agentless는 SWE-bench Lite에 대해 우수한 수동 분석을 수행했습니다. 그들은 Lite에서 이론적으로 가장 높은 점수는 아마도 실제 상한은 더 낮을 수도 있습니다(약 80%). 일부 질문에는 정보가 부족하고 다른 질문에는 너무 엄격하게 테스트되었습니다.”

SWE-bench Lite-S: 필터링된 엄격한 문제 하위 집합입니다.
이러한 문제를 해결하기 위해 연구원들은 엄격한 문제 하위 집합 SWE-bench Lite-S(252개 질문 포함)를 제안했습니다. 특히 정확한 패치가 포함되어 있거나 오해의 소지가 있는 솔루션이 포함되어 있거나 문제 설명에 충분한 정보를 제공하지 않은 문제는 SWE-bench Lite(300개 문제 포함)에서 제외되었습니다. 이는 불합리한 질문을 제거하고 벤치마크의 난이도를 표준화합니다. 필터링된 벤치마크는 원래 SWE-bench Lite와 비교하여 자동화된 소프트웨어 개발 도구의 실제 기능을 더 정확하게 반영합니다.
결론
에이전트 기반 소프트웨어 개발은 매우 유망하지만 저자는 기술 및 연구 커뮤니티가 더 많은 에이전트를 출시하기 위해 서두르기보다는 핵심 설계 및 평가 방법에 대해 잠시 멈추고 생각해야 할 때라고 믿습니다. 연구원들은 Agentless가 향후 소프트웨어 엔지니어링에서 에이전트의 기준과 방향을 재설정하는 데 도움이 되기를 바랍니다.
以上是登頂開源AI軟體工程師榜首,UIUC無Agent方案輕鬆解決SWE-bench真實程式設計問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!