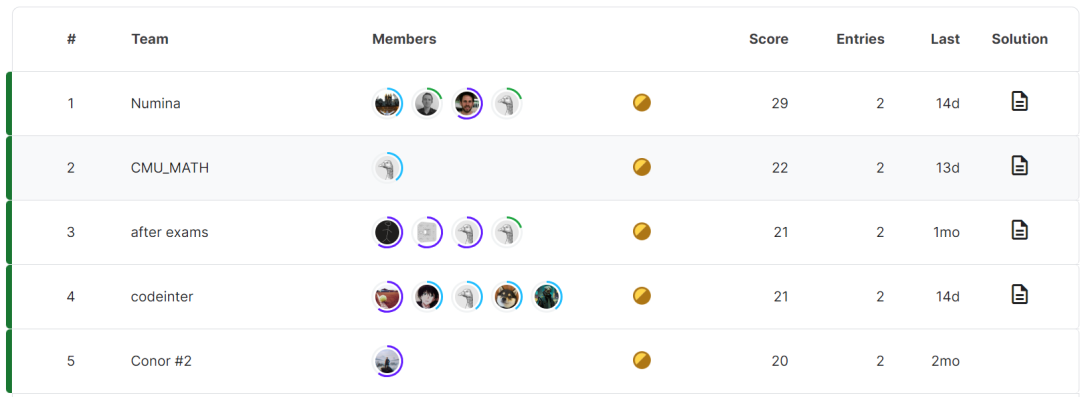
這次比賽共有5 個團隊勝出,獲得第一名的是Numina 的團隊,CMU_MATH 位列第二,after exams 暫居第三,codeinter、Conor #2 團隊分別拿到第四、第五的成績。 圖來源:https://www.kaggle.com/c 這一成績,曾讓陶哲軒感到驚訝。
當時官方隻公佈了獲獎名單,並未透漏背後模型的更多資訊。大家都在好奇,拿到冠軍的隊伍到底是用了哪一種模型?
剛剛,AIMO 進步獎公佈了前四名背後模型。
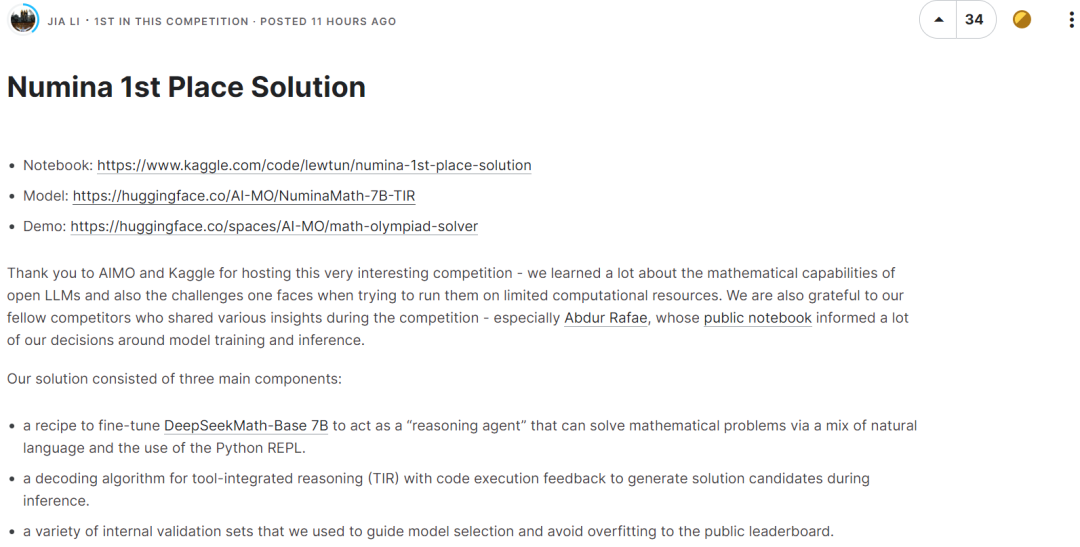
冠軍團隊用到的模型是 NuminaMath 7B TIR,該模型是 deepseek-math-7b-base 的微調版本。
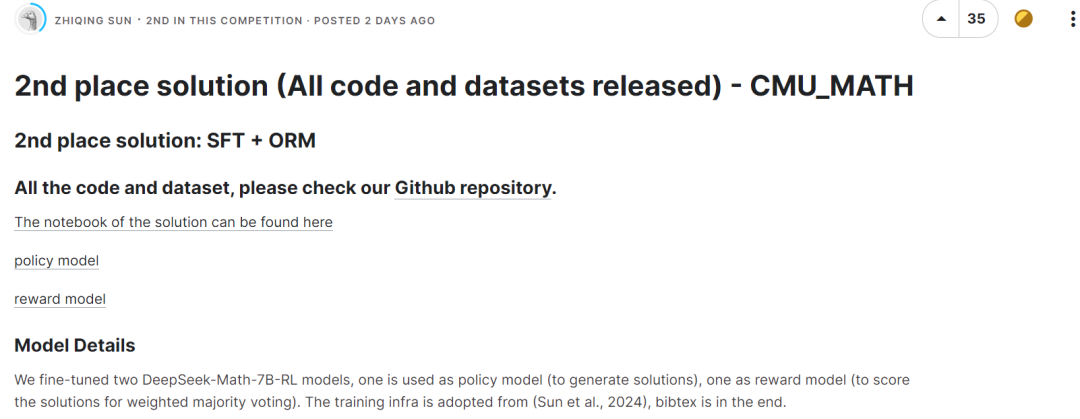
獲得第二名的隊伍微調了兩個DeepSeek-Math-7B-RL 模型,一個用作策略模型(用於生成解決方案),一個用作獎勵模型(用於對加權多數投票的解決方案進行評分)。
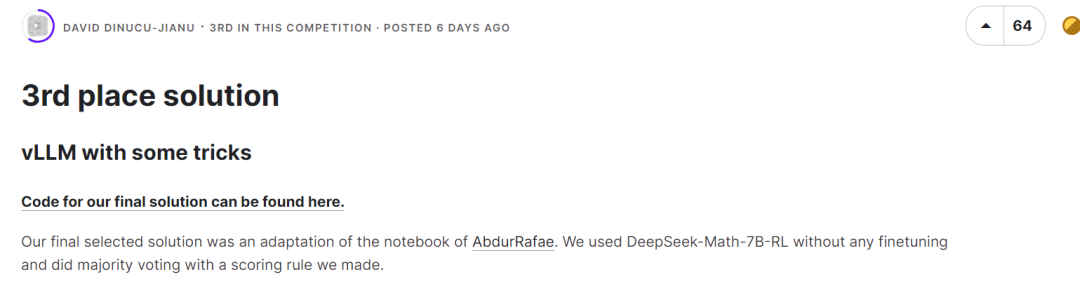
第三名同樣使用了 DeepSeek-Math-7B-RL 模型,沒有進行任何微調,並透過制定的評分規則使用多數投票的策略選擇正確答案。
排名第四的隊伍同樣使用了 deepseek-math-7b-rl,參數設定 temperature 為 0.9、top_p 為 1.0、max tokens 為 2048。模型搭配程式碼工具,在 MATH 基準測試中可達到 58.8%。
我們不難發現,前四名的隊伍都選擇了 DeepSeekMath-7B 作為基礎模型,並取得了較好的成績。此模型數學推理能力逼近 GPT-4,在 MATH 基準上超過一眾 30B~70B 的開源模型。
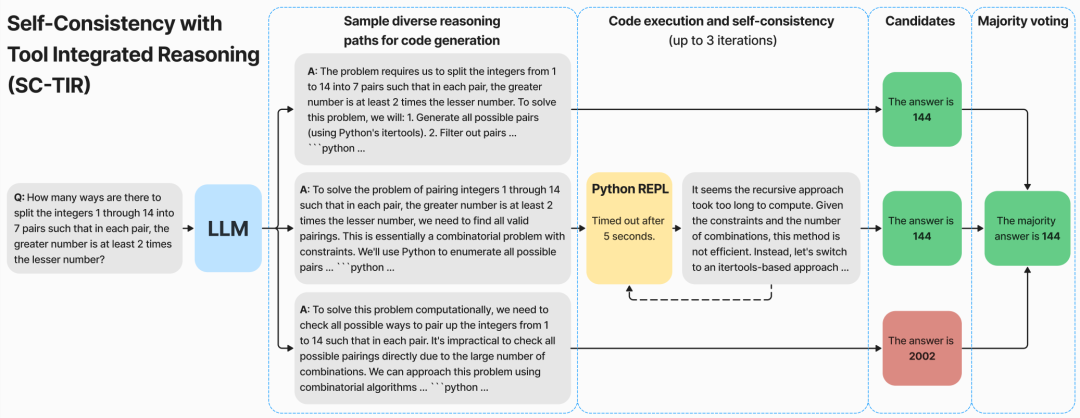
NuminaMath 是一系列語言模型,經過訓練可以使用工具整合推理(TIR)解決數學問題。
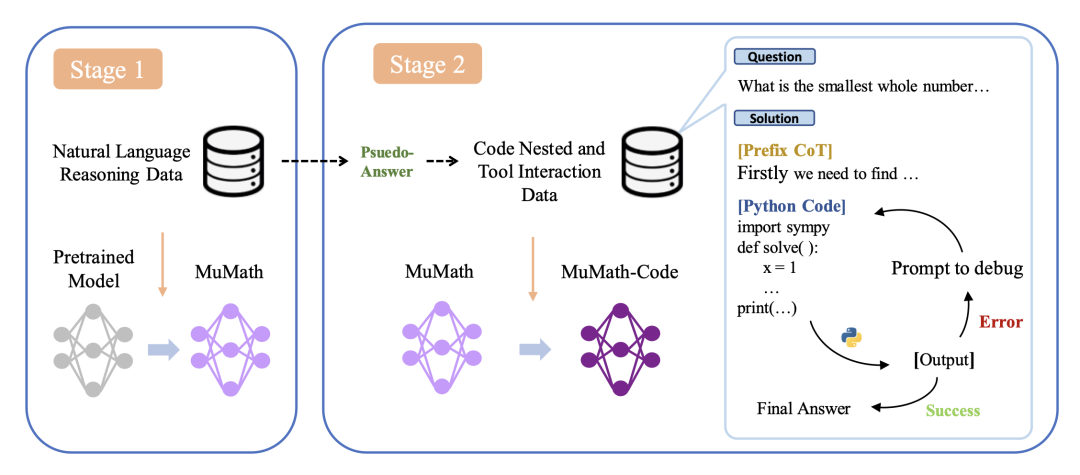
NuminaMath 7B TIR 是deepseek-math-7b-base 的微調版本,進行了兩個階段的監督微調:
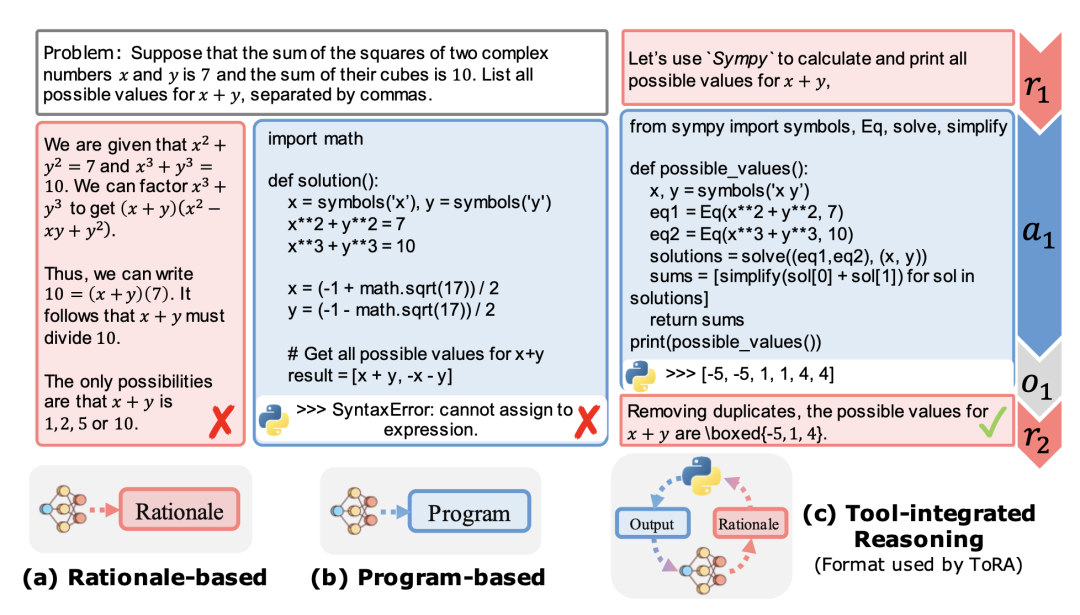
、多樣化資料集上微調基本模型,其中每個解決方案都使用思維鏈(CoT) 進行模板化以促進推理。 - 第 2 階段:在工具整合推理(TIR)的合成資料集上微調第 1 階段所得到的模型,其中每個數學問題都分解為一系列基本原理、Python 程式及其輸出。這裡會 prompt GPT-4 產生具有程式碼執行回饋的 ToRA 格式(微軟)解決方案。在這些數據上進行微調會產生一個推理智能體,它可以透過結合自然語言推理和使用 Python REPL 來計算中間結果,以解決數學問題。
值得注意的是,NuminaMath 7B TIR 是專門為了解決競賽級別數學問題而創建的。因此,該模型不應用於一般聊天應用程式。透過貪婪解碼(greedy decoding),冠軍團隊發現該模型能夠解決 AMC 12 級別的問題,但通常很難為 AIME 和數學奧林匹克級困難問題產生有效的解決方案。該模型也難以解決幾何問題,可能是因為其容量有限且缺乏視覺等模態。 以上是首屆AI奧數競賽方案公佈:4支得獎隊伍,竟都選擇國產模型DeepSeekMath的詳細內容。更多資訊請關注PHP中文網其他相關文章!