
CLIP當RNN用入選CVPR:無需訓練即可分割無數概念|牛津大學&Google研究院

- PHPz原創
- 2024-06-09 12:53:28530瀏覽
循環呼叫CLIP,無需額外訓練就有效分割無數概念。
包括電影動漫人物,地標,品牌,和普通類別在內的任意短語。
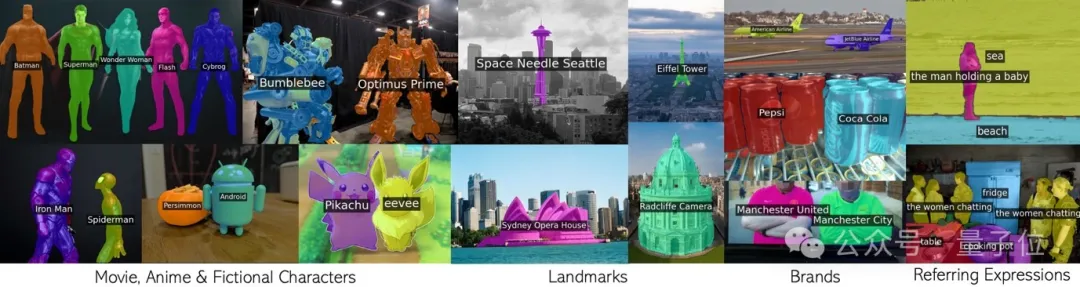
牛津大學與Google研究院聯合團隊的這項新成果,已被CVPR 2024接收,並開源了程式碼。

團隊提出名為CLIP as RNN(簡稱CaR)的新技術,解決了開放詞彙量圖像分割領域中的幾個關鍵問題:
- 無需訓練資料:傳統方法需要大量的遮罩註解或圖像-文字資料集進行微調,CaR技術則無需任何額外的訓練資料即可運作。
- 開放詞彙量的限制:預先訓練的視覺-語言模型(VLMs)在經過微調後,其處理開放詞彙量的能力受到限制。 CaR技術保留了VLMs的廣泛詞彙空間。
- 對非圖像中概念的文字查詢處理:在沒有微調的情況下,VLMs難以對圖像中不存在的概念進行準確分割,CaR透過迭代過程逐步優化,提高了分割品質。
受RNN啟發,循環呼叫CLIP
要理解CaR的原理,需要先回顧一下循環神經網路RNN。
RNN引入了隱藏狀態(hidden state)的概念,就像是一個“記憶體”,儲存了過去時間步的資訊。而每個時間步共享同一組權重,可以很好地建模序列資料。
受RNN啟發,CaR也設計成循環的框架,由兩部分組成:
- 掩膜提議產生器:借助CLIP為每個文本查詢產生一個mask。
- 掩膜分類器:再用一個CLIP模型,評估產生的每個mask和對應的文字查詢的匹配度。如果匹配度低,就把那個文字查詢剔除掉。
就這樣反覆迭代下去,文字查詢會越來越精準,mask的品質也會越來越高。
最後當查詢集合不再變化,就可以輸出最終的分割結果了。

之所以要設計這個遞歸框架,是為了最大限度地保留CLIP預訓練的」知識」。
CLIP預訓練中見過的概念可是海量,涵蓋了從名人、地標到動漫角色等方方面面。如果在分割資料集上微調,詞彙量勢必會大幅縮水。
例如「分割一切」SAM模型就只能認出一瓶可口可樂,百事可樂是一瓶也不認了。

但直接拿CLIP做分割,效果又不盡人意。
這是因為CLIP的預訓練目標本來就不是為密集預測設計的。尤其是當圖像中不存在某些文字查詢時,CLIP很容易產生一些錯誤的mask。
CaR巧妙地透過RNN式的迭代來解決這個問題。透過反覆評估、篩選查詢,同時完善mask,最終實現了高品質的開放詞彙分割。
最後再來跟隨團隊的解讀,了解CaR框架的細節。
CaR技術細節
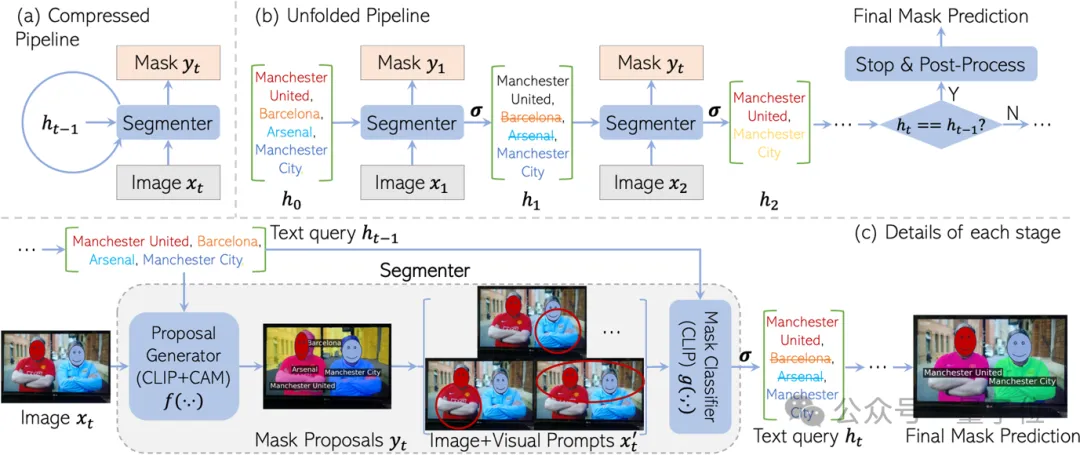
- 循环神经网络框架:CaR采用了一个新颖的循环框架,通过迭代过程不断优化文本查询与图像之间的对应关系。
- 两阶段分割器:由掩膜提议生成器和掩膜分类器组成,均基于预训练的CLIP模型构建,且权重在迭代过程中保持不变。
- 掩膜提议生成:使用gradCAM技术,基于图像和文本特征的相似度得分来生成掩膜提议。
- 视觉提示:应用如红圈、背景模糊等视觉提示,以增强模型对图像特定区域的关注。
- 阈值函数:通过设置相似度阈值,筛选出与文本查询对齐程度高的掩膜提议。
- 后处理:使用密集条件随机场(CRF)和可选的SAM模型进行掩膜细化。
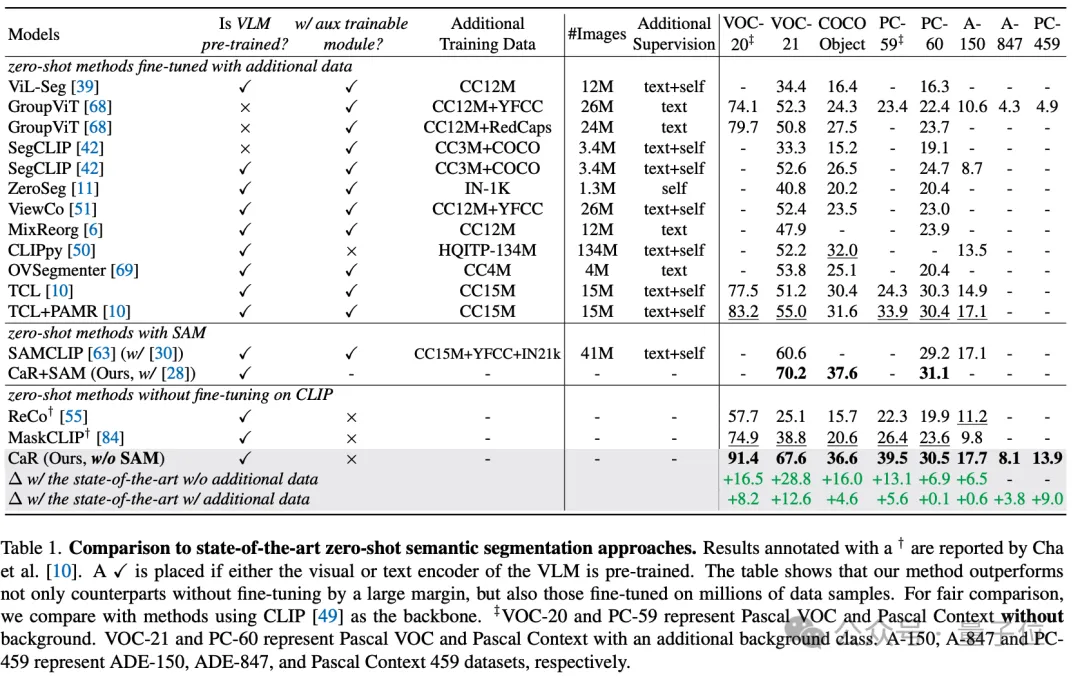
通过这些技术手段,CaR技术在多个标准数据集上实现了显著的性能提升,超越了传统的零样本学习方法,并在与进行了大量数据微调的模型相比时也展现出了竞争力。如下表所示,尽管完全无需额外训练及微调,CaR在零样本语义分割的8个不同指标上表现出比之前在额外数据上进行微调过的方法更强的性能。
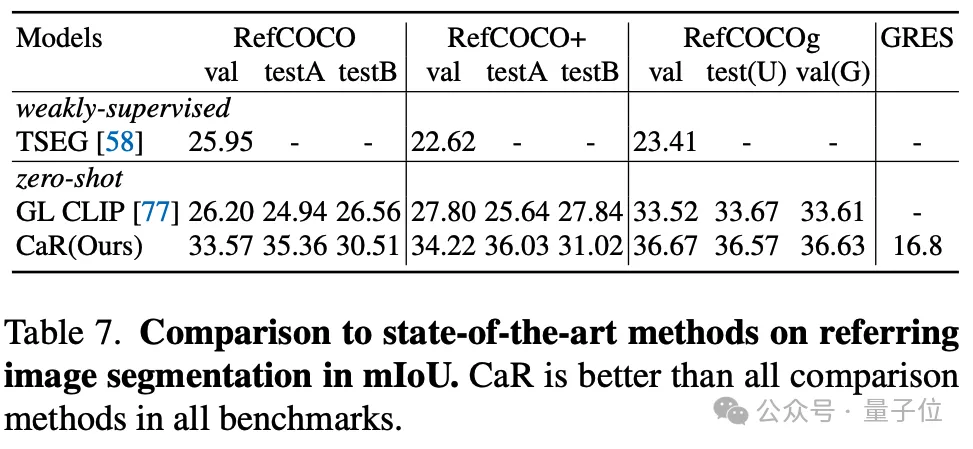
作者还测试了CaR在零样本Refering segmentation的效果,CaR也表现出了相较之前零样本的方法表现出更强的性能。
综上所述,CaR(CLIP as RNN)是一种创新的循环神经网络框架,能够在无需额外训练数据的情况下,有效地进行零样本语义和指代图像分割任务。它通过保留预训练视觉-语言模型的广泛词汇空间,并利用迭代过程不断优化文本查询与掩膜提议的对齐度,显著提升了分割质量。
CaR的优势在于其无需微调、处理复杂文本查询的能力和对视频领域的扩展性,为开放词汇量图像分割领域带来了突破性进展。
论文链接:https://arxiv.org/abs/2312.07661。
项目主页:https://torrvision.com/clip_as_rnn/。
以上是CLIP當RNN用入選CVPR:無需訓練即可分割無數概念|牛津大學&Google研究院的詳細內容。更多資訊請關注PHP中文網其他相關文章!