AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
#人類跳舞影片生成是一項引人注目且具有挑戰性的可控視訊合成任務,旨在根據輸入的參考影像和目標姿勢序列產生高品質逼真的連續影片。隨著影片生成技術的快速發展,特別是生成模型的迭代演化,跳舞影片生成任務取得了前所未有的進展,並展示了廣泛的應用潛力。
現有的方法可以大致分成兩組。第一組通常基於
生成對抗網路(GAN),其利用中間的姿勢引導表示來扭曲參考外觀,並透過先前扭曲的目標生成合理的視訊畫面。然而,基於生成對抗網路的方法通常存在訓練不穩定和泛化能力差的問題,導致明顯的偽影和幀間抖動。 第二組則使用
擴散模型(Diffusion model)來合成逼真的影片。這些方法兼具穩定訓練和強大遷移能力的優勢,相較於基於 GAN 的方法表現較好,典型方法如 Disco、MagicAnimate、Animate Anyone、Champ 等。 儘管基於擴散模型的方法取得了顯著進展,但現有的方法仍有兩個限制:
一是需要額外的參考網路(ReferenceNet)來編碼參考影像特徵並將其與3D-UNet 的主幹分支進行表觀對齊,導致增加了訓練難度和模型參數;二是它們通常採用時序Transformer 來建模視訊幀之間時序依賴關係,但Transformer 的複雜度隨產生的時間長度成二次方的計算關係,限制了產生影片的時序長度。典型方法只能產生 24 幀視頻,限制了實際部署的可能性。儘管採用了時序重合的滑動視窗策略可以產生更長的視頻,但團隊作者發現這種方式容易導致片段重合連接處通常存在不流暢的轉換和外貌不一致性的問題。 為了解決這些問題,來自華中科技大學、阿里巴巴、中國科學技術大學的研究團隊提出了
UniAnimate 框架,以實現高效且長時間的人類視訊生成。 
- 論文網址:https://arxiv.org/abs/2406.01188
- 計畫首頁: https://unianimate.github.io/
UniAnimate 框架首先將參考影像、姿勢指導和雜訊視訊映射到特徵空間中,然後利用
統一的視訊擴散模型(Unified Video Diffusion Model)同時處理參考影像與視訊主幹分支表觀對齊和視訊去噪任務,實現高效特徵對齊和連貫的視訊生成。 其次,研究團隊也提出了一個統一的雜訊輸入,其支援隨機雜訊輸入和基於第一幀的條件雜訊輸入,隨機雜訊輸入可以配合參考影像和姿態序列產生一段視頻,而基於第一幀的條件噪聲輸入(First Frame Conditioning)則以視頻第一幀作為條件輸入延續生成後續的視頻。透過這種方式,推理時可以透過把前一個影片片段(segment)的最後一幀當作後一個片段的第一幀來進行生成,並以此類推在一個框架中實現長影片生成。
最後,為了進一步高效處理長序列,研究團隊探索了基於狀態空間模型(Mamba)的時間建模架構,作為原始的計算密集型時序Transformer 的一種替代。實驗發現基於時序 Mamba 的架構可以取得和時序 Transformer 類似的效果,但是所需的顯存開銷更小。
透過 UniAnimate 框架,使用者可以產生高品質的時序連續人類跳舞影片。值得一提的是,透過多次使用 First Frame Conditioning 策略,可以產生持續一分鐘的高清影片。與傳統方法相比,UniAnimate 具有以下優勢:
- 無需額外的參考網絡:UniAnimate 框架通過統一的視頻擴散模型,消除了對額外參考網路的依賴,降低了訓練難度和模型參數的數量。
- 引入了參考影像的姿態圖作為額外的參考條件,促進網路學習參考姿態和目標姿態之間的對應關係,實現良好的表觀對齊。
- 統一框架內產生長序列視頻:透過增加統一的噪音輸入,UniAnimate 能夠在一個框架內生成長時間的視頻,不再受到傳統方法的時間限制。
- 具有高度一致性:UniAnimate 框架透過迭代利用第一幀作為條件生成後續幀的策略,保證了生成視頻的平滑過渡效果,使得視頻在外觀上更加一致和連貫。這項策略也讓使用者可以產生多個影片片段,並選取產生結果好的片段的最後一幀作為下一個生成片段的第一幀,方便了使用者與模型互動和按需調整產生結果。而利用先前時序重合的滑動視窗策略產生長視頻,則無法進行分段選擇,因為每一段視頻在每一步擴散過程中都相互耦合。
以上這些特點使得UniAnimate 框架在合成高品質、長時間的人類跳舞影片方面表現出色,為實現更廣泛的應用提供了新的可能性。
7. 一分鐘跳舞影片生成。 取得原始MP4 影片和更多高畫質影片範例請參考論文的專案首頁 https://unianimate.github .io/。 #1. 和現有方法在TikTok數據集上的定量對比實驗。
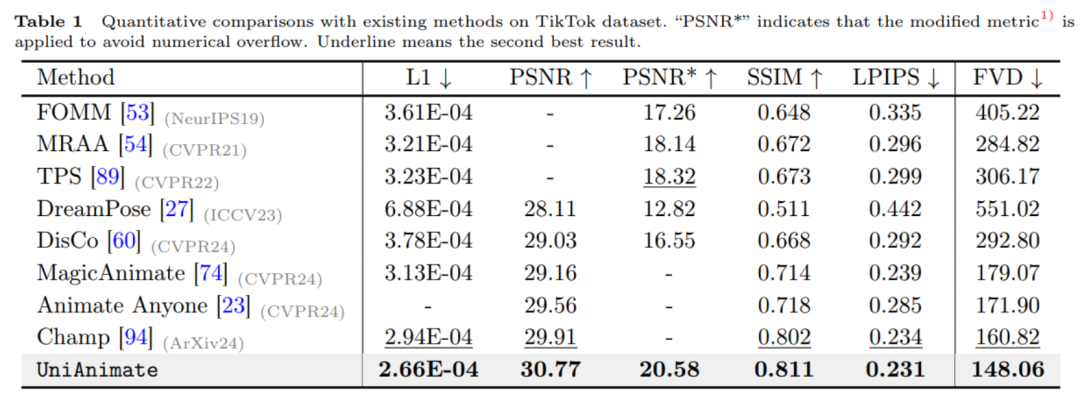
如上表所示,UniAnimate 方法在圖片指標如L1、PSNR、SSIM、LPIPS 上和影片指標FVD 上都取得了最好的結果,說明了UniAnimate 可以產生高保真的結果。
從上述定性對比實驗也可以看出,相較於MagicAnimate、Animate Anyone, UniAnimate 方法可以產生更好的連續結果,沒有出現明顯的artifacts,顯示了UniAnimate 的有效性。
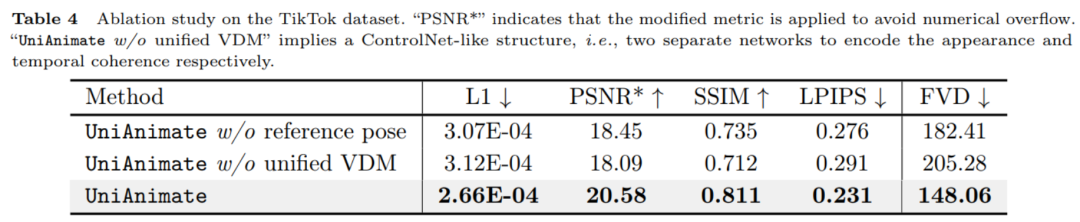
從上表的數值結果可以看出,UniAnimate 中用到的參考姿態和統一視訊擴散模型對效能提升起到了很關鍵的作用。
從上圖可以看出先前常用的時序重合滑動視窗策略產生長影片容易導致不連續的過渡,研究團隊認為這是因為不同窗口在時序重合部分去噪難度不一致,使得生成結果不同,而直接平均會導致有明顯的變形或扭曲等情況發生,而這種不一致會進行錯誤傳播。而本文利用的首幀影片延續生成方法則可以產生平滑的轉場。 總而言之,UniAnimate 的範例結果表現和定量對比結果很不錯,期待UniAnimate 在各個領域的應用,如影視製作、虛擬實境和遊戲產業等,為用戶帶來更逼真、更精彩的人類形象動畫體驗。 以上是支持合成一分鐘高清視頻,華科等提出人類跳舞視頻生成新框架UniAnimate的詳細內容。更多資訊請關注PHP中文網其他相關文章!