
美國教授用2歲女兒訓練AI模式登Science!人類幼崽頭戴相機訓練全新AI

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB原創
- 2024-06-03 10:08:09928瀏覽
絕了,為了訓練AI模型,一位紐約州立大學的教授,竟然把類似GoPro的相機綁在了自己女兒頭上!
雖然聽起來不可思議,但這位教授的行為,其實是有據可循的。

要訓練LLM背後的複雜神經網絡,需要大量資料。
目前我們訓練LLM的過程,一定是最簡潔、最有效率的方式嗎?
肯定不是!科學家發現,蹣跚學步的人類兒童,大腦就像海綿吸水一樣,能迅速形成一個連貫的世界觀。

雖然LLM時有驚人的表現,但隨著時間的推移,人類兒童會比模型更聰明、更有創造力!
兒童掌握語言的秘密
如何用更好的方法訓練LLM?
科學家們苦思不得其解之時,人類幼崽讓他們眼前一亮——
他們學習語言的方式,堪稱是語言習得的大師。

咱們都知道這樣的故事:把一個幼年的孩子扔進一個語言文化完全不同的國家,不出幾個月,ta對於當地語言的掌握可能就接近了母語程度。
而大語言模型,就顯得相形見絀了。
首先,它們太費數據了!
如今訓模型的各大公司,快把全世界的數據給薅空了。因為LLM的學習,需要的是從網路和各個地方挖掘的天文數字級的文本。
要讓它們掌握一門語言,需要餵它們數萬億個單字。

Brenden Lake和參與這項研究的NYU學者
其次,興師動眾地砸了這麼多數據進去,LLM也未必學得準確。
許多LLM的輸出,是以一定準確度預測下一個單字。而這種準確度,越來越令人不安。
形成鮮明對比的是,要學會流利使用語言,兒童可不需要這麼多經驗。
紐約州立大學研究人類和AI的心理學家Brenden Lake,就盯上了這一點。
他決定,拿自己1歲9個月的女兒Luna做實驗。

在過去的11個月裡,Lake每週都會讓女兒戴一個小時的相機,以她的角度記錄玩耍時的影片。
透過Luna相機拍攝的視頻,Lake希望透過使用孩子接觸到的相同數據,來訓練模型。

把GoPro綁在蹣跚學步的女兒身上
雖然目前語言學家和兒童專家對於兒童究竟如何習得語言,並未達成一致,但Lake十分確信:讓LLM更有效率的秘訣,就藏在兒童的學習模式裡!
因此,Lake進行了這樣一項研究計畫:研究兒童在學習第一句話時所經歷的刺激,以此提高訓練LLM的效率。
為此,Lake的團隊需要收集來自美國各地的25名兒童的視訊和音訊資料。
這就有了文章開頭的一幕——他們把類似GoPro的相機綁在了這些孩子的頭上,包括Lake的女兒Luna。

Lake解釋道,他們的模型試圖從孩子的角度,將影片片段和孩子的照顧者所說的話聯繫起來,方式類似於OpenAI的Clip模型將標註和影像連結起來。
Clip可以將影像作為輸入,並根據影像-標註對的訓練數據,輸出一個描述性標註作為建議。

論文網址:https://openai.com/index/clip/
另外, Lake團隊的模型還可以根據GoPro鏡頭的訓練資料和照顧者的音頻,將場景的影像作為輸入,然後輸出語言來描述這個場景。
而且,模型還可以將描述轉換為先前在訓練中看到的幀。
乍聽,是不是還蠻簡單的?就是讓模型像人類兒童一樣,學習將口語和在視訊畫面中所觀察到的物體相匹配。
但具體執行起來,還會面臨很多複雜的狀況。
例如,孩子不一定總是看著被描述的物體或動作。
甚至還有更抽象的情況,例如我們給孩子牛奶,但牛奶是裝在不透明的杯子裡,這會導致關聯非常鬆散。
因而,Lake解釋:這個實驗並不是想證明,我們是否可以訓練模型將圖像中的物件與相應的單字相符(OpenAI已經證明了這一點)。
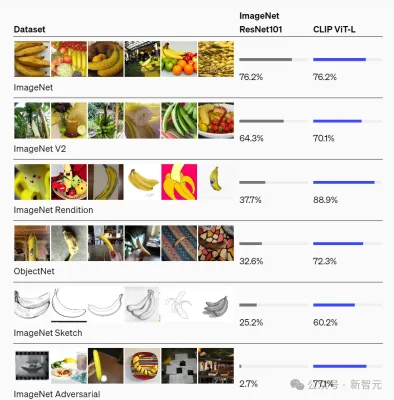
相反,團隊想要做的是,希望知道模型是否可以只用兒童可用的稀疏資料級(稀疏到難以置信的程度),就能真的學習辨識物體。
可以看到,這和OpenAI、Google、Meta等大公司建構模型的想法完全相反。
要知道,Meta訓練Llama 3,用了15兆個token。
如果Lake團隊的實驗成功,或許全世界共同面臨的LLM資料荒,就有解了──因為那時,訓練LLM根本就不需要那麼多的資料!
也就是說,新的想法是,讓AI模型從有限的輸入中學習,然後從我們看到的資料中推廣出來。
我認為我們的關注點,不該局限在從越來越多的資料中訓練越來越大的LLM。是的,你可以透過這種方式讓LLM具有驚人的性能,但它已經離我們所知道的人類智能奇妙之處越來越遠……
##早期實驗已經取得成功
早期的實驗結果,已經證明了Lake團隊的想法可能是對的。
今年2月,他們曾經用了61小時的影片片段訓出一個神經網絡,紀錄一個幼兒的經歷。
研究發現,模型能夠將被試說出的各種單字和短語,與視訊框架中捕獲的體驗聯繫起來——只要呈現要給單字或短語,模型就能回憶起相關圖像。這篇論文已經發表於Science。

論文地址:https://www.science.org/doi/10.1126/science.adi1374
Lake表示,最令人驚訝的是,模型竟然能夠概括出未訓練的影像中的物件名稱!
當然,準確度未必很好。但模型本來也只是為了驗證一個概念。
專案尚未完成,因為模型還沒有學到一個兒童會知道的一切。

畢竟,它只有60小時左右的標註的演講,這僅僅是一個兒童在兩年內所習得經驗的百分之一。而團隊還需要更多的數據,才能搞清楚什麼是可學習的。
而Lake也承認,第一個模型使用的方法還是有限制-
只分析與照顧者話語相關的影片片段,只是鏡頭以每秒5幀的速度轉化為影像,只憑這些,AI並沒有真正學會什麼是動詞,什麼是抽象詞,它獲得的僅僅是關於世界樣子的靜態切片。
因為它對之前發生了什麼事、之後發生了什麼事、談話背景都一無所知,所以很難學習什麼是「走」「跑」「跳」。
但以後,隨著建模影片背後的技術越來越成熟,Lake相信團隊會建立更有效的模型。
如果我們能夠建立一個真正開始習得語言的模型,它就會為理解人類的學習和發展開闢重要的應用程序,或許能幫我們理解發育障礙,或兒童學習語言的情況。
最終,這樣的模型還可以用來測試數百萬種不同的語言治療法。
話說回來,孩子究竟是如何透過自己的眼睛和耳朵,紮實地掌握一門語言的呢?

讓我們仔細看看Lake團隊發在Science上的這篇文章。
將單字和實物、視覺圖像連結起來
人類兒童如何褪去對這個世界的懵懂無知,習得知識?這個「黑箱」的奧秘,不僅吸引教育學家們的不斷求索,也是困於我們每個人心底關於個體智慧來處的追問。
韓國科幻作家金草葉在《共生假說》中寫下這樣的設想:人類兒童在幼年時期所展現的智慧其實承載著一個失落的外星文明,他們選擇用這樣的方式和人類共生,可是時間只有短短的五年,在人類長大擁有真正牢固的記憶之後,便把幼年時期這段瑰麗的記憶抹去了。
也常有網友會在網路上分享出,那些「忘記喝孟婆湯」的人類幼崽故事。
關於謎一樣的幼年時期,那是我們很難說清也難以回返的神祕之地,是一種「鄉愁」。就像金草葉寫下的」不要離開。不要帶走那個美麗的世界。在我長大之後,也請留在我身邊。

幼兒究竟是如何將新單字和特定的物體,或視覺概念連結起來的?
例如,聽到「球」這個字時,兒童是如何想到有彈性的圓形物體的?

為此,Lake的團隊給一個兒童戴上了頭戴式攝影機,追蹤了ta從6到25個月期間的成長過程,記錄了一個61小時的視覺語言資料流。
在這個兒童1.5年的剪輯資料集(包括60萬個視訊幀和37500個轉錄話語配對)上,研究者訓練出了一個模型,即兒童視角對比學習模型CVCL。
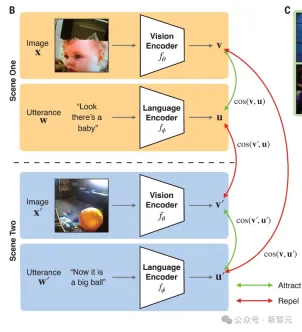
這個模型實例化了跨情境的聯想學習形式,確定了單字和可能的視覺指示物之間的映射。
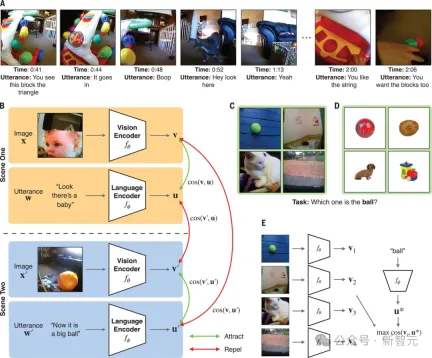
這個模型協調了兩個神經網路、視覺編碼器和語言編碼器的對比目標,以自監督的方式進行訓練(即僅使用兒童視角的錄音,不使用外部標籤),對比目標將視頻幀的嵌入(向量)和時間上同時出現的語言話語結合在一起(處理同時出現的視頻幀和語言話語的嵌入)
當然,這個名為SAYCam-S的資料集是有限的,因為它只捕捉了孩子大約1%的清醒時間,錯過了很多他們的經歷。
但儘管如此,CVCL依然可以從一個兒童的有限經驗中,學習到強大的多模態表徵!
團隊成功地證明了,模型獲取了兒童日常經驗中存在許多的指涉映射,因而能夠零樣本地概括新的視覺指涉,並且調整其中的視覺和語言概念系統。
評估習得的詞義映射
#具體來說,在訓練完成後,團隊評估了CVCL和各種替代模型所學習的單字指涉映射的品質。
結果顯示,CVCL的分類準確率為61.6%。
且圖2D顯示,對於其中22個概念中的11個概念,CVCL的表現和CLIP的誤差在5%以內,但CLIP的訓練數據,卻要多出幾個數量級(4億個來自網路的圖像-文字對)。
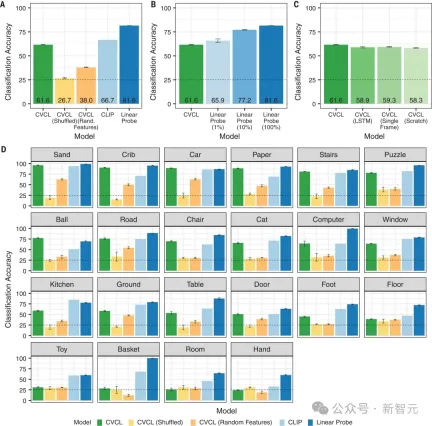
研究結果顯示,許多最早的單字所指映射,可以從至少10到100個自然出現的單字-所指對中獲得。
泛化新的視覺範例
另外,研究者也評估了CVCL學到的單詞,是否可以推廣到分佈外的視覺刺激上。
圖3A顯示,CVCL也同時展現了對這些視覺概念的一些了解,整體準確率在34.7%。
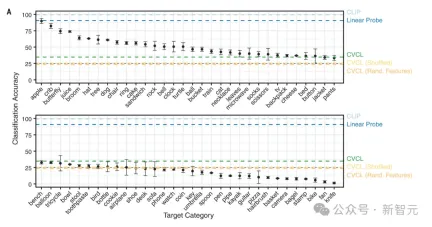
顯然,這個任務需要更大的概念集,以及額外難度的分佈外泛化。

左邊是兩個隨機選擇的訓練案例,右邊是四個測試案例,下面的百分比代表模型識別此圖像的準確度和效能,選取案例從左到右分別是兩個最高值、中位數和最低值。可以看出,當測試案例和訓練案例在色彩、形狀方面相似度更高時,模型識別的準確度也更高
##多模態一致性很好
最後,研究者測試了CVCL的視覺和語言概念系統的一致性。
例如,如果比起「球」, 「汽車」的視覺嵌入和詞嵌入都與「路」更相似,這表明多模態對齊的效果很好。
下圖顯示出,CVCL視覺和語言系統的高度對齊。
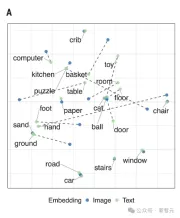
圖像和文字之間的關係,虛線表示每個概念對應的視覺質心與單字嵌入之間的距離
 #
#
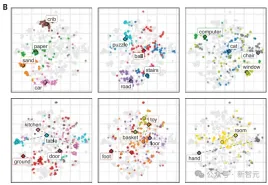
不同的視覺概念在其例子的緊密聚集程度上有所不同。因為嬰兒的視線會在距離很近的物體之間游移,就導致模型在區分“手”和“玩具”時沒有形成清晰的參考映射,“汽車”和“嬰兒床”就有比較好的表現
在每張圖中,研究者直觀地展示了CVCL預測與使用t-SNE的標籤範例的比較。

左邊的藍色點對應屬於一個特定類別的100個幀,右邊的綠色點對應於100個最高的激活幀(基於與CVCL中每個概念嵌入的單字的餘弦相似性)。在每個圖下面,是每個概念中屬於一個或多個子簇的多個範例幀,捕捉了單字嵌入如何與聯合嵌入空間中的圖像嵌入互動。例如,對於“樓梯”這個詞,我們看到一個簇代表室內木製樓梯的圖像,而另一個主要簇代表室外藍色樓梯組的圖像。這些圖中所有的t-SNE圖都來自於同一組聯合圖像和文字嵌入。
下圖顯示,模型可以在不同視圖中,定位目標所指。

在歸一化注意力圖中,黃色表示注意力最高的區域。在前兩個類別(球和車)中,我們可以看到模型可以在不同視圖中定位目標所指。但是,在下面兩個類別(貓和紙)中,注意力圖有時會與所指物錯位,這表明定位所指物的能力並不是在所有類別中都一致的。
當然,兒童的學習和機器學習模型還是有許多不同的。
但Lake團隊的研究,無疑對我們有很大的啟發。
以上是美國教授用2歲女兒訓練AI模式登Science!人類幼崽頭戴相機訓練全新AI的詳細內容。更多資訊請關注PHP中文網其他相關文章!