AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
##在大型語言模型的訓練過程中,資料的處理方式至關重要。
傳統的方法通常透過將大量文件拼接並切割成等同於模型的上下文長度的訓練序列。這雖然提高了訓練效率,但也常導致文件的不必要截斷,損害資料完整性,導致關鍵的上下文資訊遺失,進而影響模型學習到的內容的邏輯連貫性和事實一致性,並使模型更容易產生幻覺。
AWS AI Labs 的研究人員針對這一常見的拼接-分塊文字處理方式進行了深入研究, 發現其嚴重影響了模型理解上下文連貫性和事實一致性的能力。這不僅影響了模型在下游任務的表現,也增加了產生幻覺的風險。
針對這個問題,他們提出了一種創新的文件處理策略-最佳適配打包(Best-fit Packing),透過優化文件組合來消除不必要的文字截斷,並顯著地提升了模型的性能且減少模型幻覺。這項研究已被ICML 2024接收。

文章標題:Fewer Truncations Improve Language Modeling
論文連結:https://arxiv.org/pdf/2404.10830
#在傳統的大型語言模型訓練方法中,為了提高效率,研究人員通常會將多個輸入文件拼接在一起,然後將這些拼接的文件分割成固定長度的序列。
這種方法雖然簡單且高效,但它會造成一個重大問題-文件截斷(document truncation),損害了資料完整性(data integrity)。文件截斷會導致文件包含的資訊遺失 (loss of information)。
此外,文件截斷減少了每個序列中的上下文量,可能導致下一個詞的預測與上文不相關,從而使模型更容易產生幻覺( hallucination)。
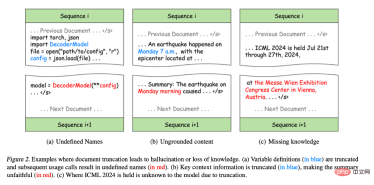
以下的範例展示了文件截斷帶來的問題:
- 圖2 (a):在Python程式設計中,原始程式碼雖然正確,但將變數定義與使用分割到不同的訓練序列中會引入語法錯誤,導致某些變數在後續訓練序列中未定義,從而使得模型學習到錯誤的模式,並可能在下游任務中產生幻覺。例如,在程式合成任務中,模型可能會在沒有定義的情況下直接使用變數。
- 圖2(b):截斷同樣損害了訊息的完整性。例如,摘要中的「Monday morning」無法與訓練序列中的任何上下文匹配,導致內容不實。這種資訊不完整性會顯著降低模型對上下文資訊的敏感度,導致生成的內容與實際情況不符,即所謂的不忠實生成 (unfaithful generation)。
- 圖2(c):截斷也會阻礙訓練期間的知識獲取,因為知識在文本中的表現通常依賴完整的句子或段落。例如,模型無法學習到ICML會議的地點,因為會議名稱和地點分佈在不同的訓練序列中。
圖2. 文檔截斷導致幻覺或知識喪失的例子。
(a) 變數定義(藍色部分)被截斷,隨後的使用呼叫導致未定義名稱(紅色部分)。
(b) 關鍵上下文資訊被截斷(藍色部分),使得摘要不準確於原文(紅色部分)。
(c) 由於截斷,模型不知道ICML 2024的舉辦地點。 #針對此問題,研究者提出了最佳適配打包 (Best-fit Packing)。 此方法使用長度感知的組合最佳化技術,有效地將文件打包到訓練序列中,從而完全消除不必要的截斷。這不僅保持了傳統方法的訓練效率,而且透過減少資料的片段化,實質地提高了模型訓練的品質。 作者首先將每個文本分割成一或多個至多長為模型上下文長度L的序列。這一步限制來自於模型,所以是必須進行的。 現在,基於大量的至多長為L的檔案區塊,研究者希望將它們合理地組合,並獲得盡量少的訓練序列。這個問題可以被看作一個集裝優化(Bin Packing)問題。集裝優化問題是NP-hard的。如下圖演算法所示,這裡他們採用了最佳適配遞減演算法(Best-Fit-Decreasing, BFD) 的啟發式策略。 接下來從時間複雜度 (Time Complexity) 和緊湊性 (Compactness) 的角度來討論BFD的可行性。
BFD的排序和打包的時間複雜度均為O(N log N),其中N為文件區塊的數量。在預訓練資料處理中,由於文件區塊的長度是整數且是有限的 ([1, L]),可以使用計數排序 (count sort) 來實現將排序的時間複雜度降低到O(N)。 在打包階段,透過使用段樹(Segment Tree)的資料結構,使得每次尋找最佳適配容器的操作只需對數時間,即O (log L)。又因為L
緊湊性是衡量打包演算法效果的另一個重要指標,在不破壞原始文檔完整性的同時需要盡可能減少訓練序列的數量以提高模型訓練的效率。 在實際應用中,透過精確控制序列的填充和排布,最佳適配打包能夠產生幾乎與傳統方法相當數量的訓練序列,同時顯著減少了因截斷而造成的資料損失。
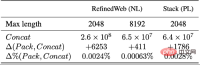
基於在自然語言(RefinedWeb) 和程式語言(The Stack) 資料集上的實驗,我們發現最佳適配打包顯著降低了文字截斷。 值得注意的是,大多數文件包含的token數少於2048個;由於傳統拼接-分塊時造成的截斷主要發生在這一範圍內,而最佳適配打包不會截斷任何長度低於L的文檔,由此有效地保持了絕大多數文檔的完整性。
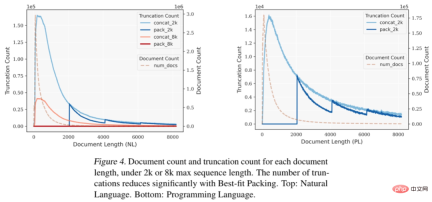
圖4:當最大序列長度設定為2k或8k時,在不同文檔長度下,每個文檔長度對應的文檔數量和截斷數量。使用「最佳適應打包」(Best-fit Packing)技術後,截斷數量明顯減少。上方:自然語言。下方:程式語言。 研究人員詳細報告了使用最佳適配打包與傳統方法(即拼接方法)訓練的語言模型在不同任務上的表現對比,包括:自然語言處理和程式語言任務,如閱讀理解(Reading Comprehension)、自然語言推理(Natural Language Inference)、上下文跟隨(Context Following)、文本摘要(Summarization)、世界知識(Commonsense and Closed-book QA) 和程式合成(Program Synthesis),總計22個子任務。 實驗涉及的模型大小從70億到130億參數不等,序列長度從2千到8千令牌,資料集涵蓋自然語言和程式語言。這些模型被訓練在大規模的資料集上,如Falcon RefinedWeb和The Stack,並使用LLaMA架構進行實驗。
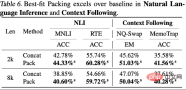
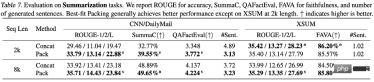
實驗結果表明,使用最佳適配打包在一系列任務中提升了模型效能,尤其是在閱讀理解( 4.7%)、自然語言推理( 9.3%)、情境跟隨( 16.8%) 和程序合成( 15.0%) 等任務中表現顯著(由於不同任務的測量標準的規模各異,作者默認使用相對改進來描述結果。) 經過統計檢驗,研究者發現所有結果要麼統計顯著地優於基線(標記為s),要麼與基線持平(標記為n),且在所有評測的任務中,使用最佳適配打包均未觀察到效能顯著下降。 這個一致性和單調性的提升突顯了最佳適配打包不僅能提升模型的整體表現,還能保證在不同任務和條件下的穩定性。詳細的結果和討論請參考正文。
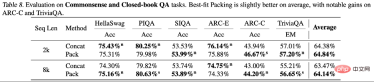
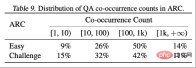
#################################################################################################################在摘要生成中,使用QAFactEval度量发现采用最佳适配打包的模型在生成幻觉方面有显著降低。更为显著的是,在程序合成任务中,使用最佳适配打包训练的模型生成代码时,“未定义名称”(Undefined Name)的错误减少了高达58.3%,这表明模型对程序结构和逻辑的理解更为完整,从而有效减少了幻觉现象。作者们还揭示了模型在处理不同类型知识时的表现差异。如前所述,训练过程中的截断可能影响信息的完整性,从而妨碍知识的获取。但大多数标准评估集中的问题侧重于常见知识 (common knowledge),这类知识在人类语言中频繁出现。因此即使部分知识因截断而丢失,模型仍有很好的机会从文档片段中学习到这些信息。相比之下,不常见的尾部知识(tail knowledge)更容易受到截断的影响,因为这类信息在训练数据中出现的频率本身就低,模型难以从其他来源补充丢失的知识。通过对ARC-C和ARC-E两个测试集的结果分析,研究者发现,相较于含有更多常见知识的ARC-E,使用最佳适配打包会使模型在含有更多尾部知识的ARC-C中有更显著的性能提升。通过计算每对问题-答案组合在 Kandpal et al. (2023) 预处理的Wikipedia实体映射中的共现次数,这一发现得到了进一步验证。统计结果显示,挑战集(ARC-C)包含了更多罕见共现的对,这验证最佳适配打包能有效支持尾部知识学习的假设,也为为何传统的大型语言模型在学习长尾知识时会遇到困难提供了一种解释。
本文提出了大型语言模型训练中普遍存在的文档截断问题。这种截断效应影响了模型学习到逻辑连贯性和事实一致性,并增加了生成过程中的幻觉现象。作者们提出了最佳适配打包(Best-fit Packing),通过优化数据整理过程,最大限度地保留了每个文档的完整性。这一方法不仅适用于处理数十亿文档的大规模数据集,而且在数据紧凑性方面与传统方法持平。 实验结果显示,该方法在减少不必要的截断方面极为有效,能够显著提升模型在各种文本和代码任务中的表现,同时有效减少封闭域的语言生成幻觉。尽管本文的实验主要集中在预训练阶段,最佳适配打包也可广泛应用于其他如微调阶段。这项工作为开发更高效、更可靠的语言模型做出了贡献,推动了语言模型训练技术的发展。有关更多研究细节,请参阅原始论文。如果有意向工作或实习,可邮件联系本文作者 zijwan@amazon.com.以上是ICML 2024 | 大語言模型預訓練新前沿:「最佳適配打包」重塑文件處理標準的詳細內容。更多資訊請關注PHP中文網其他相關文章!