


实例的背景说明
假定一个个人信息系统,需要记录系统中各个人的故乡、居住地、以及到过的城市。数据库设计如下:
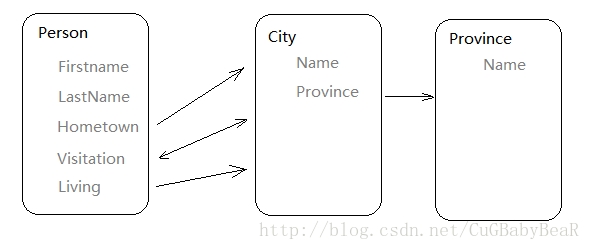
Models.py 内容如下:
from django.db import models class Province(models.Model): name = models.CharField(max_length=10) def __unicode__(self): return self.name class City(models.Model): name = models.CharField(max_length=5) province = models.ForeignKey(Province) def __unicode__(self): return self.name class Person(models.Model): firstname = models.CharField(max_length=10) lastname = models.CharField(max_length=10) visitation = models.ManyToManyField(City, related_name = "visitor") hometown = models.ForeignKey(City, related_name = "birth") living = models.ForeignKey(City, related_name = "citizen") def __unicode__(self): return self.firstname + self.lastname
注1:创建的app名为“QSOptimize”
注2:为了简化起见,`qsoptimize_province` 表中只有2条数据:湖北省和广东省,`qsoptimize_city`表中只有三条数据:武汉市、十堰市和广州市
prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。或许你会说,没有一个叫OneToManyField的东西啊。实际上 ,ForeignKey就是一个多对一的字段,而被ForeignKey关联的字段就是一对多字段了。
作用和方法
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。继续以上边的例子进行说明,如果我们要获得张三所有去过的城市,使用prefetch_related()应该是这么做:
>>> zhangs = Person.objects.prefetch_related('visitation').get(firstname=u"张",lastname=u"三")
>>> for city in zhangs.visitation.all() :
... print city
...
上述代码触发的SQL查询如下:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person` WHERE (`QSOptimize_person`.`lastname` = '三' AND `QSOptimize_person`.`firstname` = '张'); SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
第一条SQL查询仅仅是获取张三的Person对象,第二条比较关键,它选取关系表`QSOptimize_person_visitation`中`person_id`为张三的行,然后和`city`表内联(INNER JOIN 也叫等值连接)得到结果表。
+----+-----------+----------+-------------+-----------+ | id | firstname | lastname | hometown_id | living_id | +----+-----------+----------+-------------+-----------+ | 1 | 张 | 三 | 3 | 1 | +----+-----------+----------+-------------+-----------+ 1 row in set (0.00 sec) +-----------------------+----+-----------+-------------+ | _prefetch_related_val | id | name | province_id | +-----------------------+----+-----------+-------------+ | 1 | 1 | 武汉市 | 1 | | 1 | 2 | 广州市 | 2 | | 1 | 3 | 十堰市 | 1 | +-----------------------+----+-----------+-------------+ 3 rows in set (0.00 sec)
显然张三武汉、广州、十堰都去过。
又或者,我们要获得湖北的所有城市名,可以这样:
>>> hb = Province.objects.prefetch_related('city_set').get(name__iexact=u"湖北省")
>>> for city in hb.city_set.all():
... city.name
...
触发的SQL查询:
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name` FROM `QSOptimize_province` WHERE `QSOptimize_province`.`name` LIKE '湖北省' ; SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` WHERE `QSOptimize_city`.`province_id` IN (1);
得到的表:
+----+-----------+ | id | name | +----+-----------+ | 1 | 湖北省 | +----+-----------+ 1 row in set (0.00 sec) +----+-----------+-------------+ | id | name | province_id | +----+-----------+-------------+ | 1 | 武汉市 | 1 | | 3 | 十堰市 | 1 | +----+-----------+-------------+ 2 rows in set (0.00 sec)
我们可以看见,prefetch使用的是 IN 语句实现的。这样,在QuerySet中的对象数量过多的时候,根据数据库特性的不同有可能造成性能问题。
使用方法
*lookups 参数
prefetch_related()在Django
>>> zhangs = Person.objects.prefetch_related('visitation__province').filter(firstname__iexact=u'张')
>>> for i in zhangs:
... for city in i.visitation.all():
... print city.province
...
触发的SQL:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person` WHERE `QSOptimize_person`.`firstname` LIKE '张' ; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 4); SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name` FROM `QSOptimize_province` WHERE `QSOptimize_province`.`id` IN (1, 2);
获得的结果:
+----+-----------+----------+-------------+-----------+ | id | firstname | lastname | hometown_id | living_id | +----+-----------+----------+-------------+-----------+ | 1 | 张 | 三 | 3 | 1 | | 4 | 张 | 六 | 2 | 2 | +----+-----------+----------+-------------+-----------+ 2 rows in set (0.00 sec) +-----------------------+----+-----------+-------------+ | _prefetch_related_val | id | name | province_id | +-----------------------+----+-----------+-------------+ | 1 | 1 | 武汉市 | 1 | | 1 | 2 | 广州市 | 2 | | 4 | 2 | 广州市 | 2 | | 1 | 3 | 十堰市 | 1 | +-----------------------+----+-----------+-------------+ 4 rows in set (0.00 sec) +----+-----------+ | id | name | +----+-----------+ | 1 | 湖北省 | | 2 | 广东省 | +----+-----------+ 2 rows in set (0.00 sec)
值得一提的是,链式prefetch_related会将这些查询添加起来,就像1.7中的select_related那样。
要注意的是,在使用QuerySet的时候,一旦在链式操作中改变了数据库请求,之前用prefetch_related缓存的数据将会被忽略掉。这会导致Django重新请求数据库来获得相应的数据,从而造成性能问题。这里提到的改变数据库请求指各种filter()、exclude()等等最终会改变SQL代码的操作。而all()并不会改变最终的数据库请求,因此是不会导致重新请求数据库的。
举个例子,要获取所有人访问过的城市中带有“市”字的城市,这样做会导致大量的SQL查询:
plist = Person.objects.prefetch_related('visitation')
[p.visitation.filter(name__icontains=u"市") for p in plist]
因为数据库中有4人,导致了2+4次SQL查询:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person`; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 2, 3, 4); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE(`QSOptimize_person_visitation`.`person_id` = 1 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 2 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 3 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 4 AND `QSOptimize_city`.`name` LIKE '%市%' );
详细分析一下这些请求事件。
众所周知,QuerySet是lazy的,要用的时候才会去访问数据库。运行到第二行Python代码时,for循环将plist看做iterator,这会触发数据库查询。最初的两次SQL查询就是prefetch_related导致的。
虽然已经查询结果中包含所有所需的city的信息,但因为在循环体中对Person.visitation进行了filter操作,这显然改变了数据库请求。因此这些操作会忽略掉之前缓存到的数据,重新进行SQL查询。
但是如果有这样的需求了应该怎么办呢?在Django >= 1.7,可以通过下一节的Prefetch对象来实现,如果你的环境是Django
plist = Person.objects.prefetch_related('visitation')
[[city for city in p.visitation.all() if u"市" in city.name] for p in plist]
Prefetch 对象
在Django >= 1.7,可以用Prefetch对象来控制prefetch_related函数的行为。
注:由于我没有安装1.7版本的Django环境,本节内容是参考Django文档写的,没有进行实际的测试。
Prefetch对象的特征:
- 一个Prefetch对象只能指定一项prefetch操作。
- Prefetch对象对字段指定的方式和prefetch_related中的参数相同,都是通过双下划线连接的字段名完成的。
- 可以通过 queryset 参数手动指定prefetch使用的QuerySet。
- 可以通过 to_attr 参数指定prefetch到的属性名。
- Prefetch对象和字符串形式指定的lookups参数可以混用。
继续上面的例子,获取所有人访问过的城市中带有“武”字和“州”的城市:
wus = City.objects.filter(name__icontains = u"武")
zhous = City.objects.filter(name__icontains = u"州")
plist = Person.objects.prefetch_related(
Prefetch('visitation', queryset = wus, to_attr = "wu_city"),
Prefetch('visitation', queryset = zhous, to_attr = "zhou_city"),)
[p.wu_city for p in plist]
[p.zhou_city for p in plist]
注:这段代码没有在实际环境中测试过,若有不正确的地方请指正。
顺带一提,Prefetch对象和字符串参数可以混用。
None
可以通过传入一个None来清空之前的prefetch_related。就像这样:
>>> prefetch_cleared_qset = qset.prefetch_related(None)
小结
- prefetch_related主要针一对多和多对多关系进行优化。
- prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
- 可以通过可变长参数指定需要select_related的字段名。指定方式和特征与select_related是相同的。
- 在Django >= 1.7可以通过Prefetch对象来实现复杂查询,但低版本的Django好像只能自己实现。
- 作为prefetch_related的参数,Prefetch对象和字符串可以混用。
- prefetch_related的链式调用会将对应的prefetch添加进去,而非替换,似乎没有基于不同版本上区别。
- 可以通过传入None来清空之前的prefetch_related。

 Python腳本可能無法在UNIX上執行的一些常見原因是什麼?Apr 28, 2025 am 12:18 AM
Python腳本可能無法在UNIX上執行的一些常見原因是什麼?Apr 28, 2025 am 12:18 AMPython腳本在Unix系統上無法運行的原因包括:1)權限不足,使用chmod xyour_script.py賦予執行權限;2)Shebang行錯誤或缺失,應使用#!/usr/bin/envpython;3)環境變量設置不當,可打印os.environ調試;4)使用錯誤的Python版本,可在Shebang行或命令行指定版本;5)依賴問題,使用虛擬環境隔離依賴;6)語法錯誤,使用python-mpy_compileyour_script.py檢測。
 舉一個場景的示例,其中使用Python數組比使用列表更合適。Apr 28, 2025 am 12:15 AM
舉一個場景的示例,其中使用Python數組比使用列表更合適。Apr 28, 2025 am 12:15 AM使用Python數組比列表更適合處理大量數值數據。 1)數組更節省內存,2)數組對數值運算更快,3)數組強制類型一致性,4)數組與C語言數組兼容,但在靈活性和便捷性上不如列表。
 在Python中使用列表與數組的性能含義是什麼?Apr 28, 2025 am 12:10 AM
在Python中使用列表與數組的性能含義是什麼?Apr 28, 2025 am 12:10 AM列表列表更好的forflexibility andmixDatatatypes,何時出色的Sumerical Computitation sand larged數據集。 1)不可使用的列表xbilese xibility xibility xibility xibility xibility xibility xibility xibility xibility xibility xibles and comply offrequent elementChanges.2)
 Numpy如何處理大型數組的內存管理?Apr 28, 2025 am 12:07 AM
Numpy如何處理大型數組的內存管理?Apr 28, 2025 am 12:07 AMnumpymanagesmemoryforlargearraysefefticefticefipedlyuseviews,副本和內存模擬文件.1)viewsAllowSinglicingWithOutCopying,直接modifytheoriginalArray.2)copiesCanbecopy canbecreatedwitheDedwithTheceDwithThecevithThece()methodervingdata.3)metservingdata.3)memore memore-mappingfileShessandAstaStaStstbassbassbassbassbassbassbassbassbassbassbb
 哪個需要導入模塊:列表或數組?Apr 28, 2025 am 12:06 AM
哪個需要導入模塊:列表或數組?Apr 28, 2025 am 12:06 AMListsinpythondonotrequireimportingamodule,helilearraysfomthearraymoduledoneedanimport.1)列表列表,列表,多功能和canholdMixedDatatatepes.2)arraysaremoremoremoremoremoremoremoremoremoremoremoremoremoremoremoremoremeremeremeremericdatabuteffeftlessdatabutlessdatabutlessfiblesible suriplyElsilesteletselementEltecteSemeTemeSemeSemeSemeTypysemeTypysemeTysemeTypysemeTypepe。
 可以在Python數組中存儲哪些數據類型?Apr 27, 2025 am 12:11 AM
可以在Python數組中存儲哪些數據類型?Apr 27, 2025 am 12:11 AMpythonlistscanStoryDatatepe,ArrayModulearRaysStoreOneType,and numpyArraySareSareAraysareSareAraysareSareComputations.1)列出sareversArversAtileButlessMemory-Felide.2)arraymoduleareareMogeMogeNareSaremogeNormogeNoreSoustAta.3)
 如果您嘗試將錯誤的數據類型的值存儲在Python數組中,該怎麼辦?Apr 27, 2025 am 12:10 AM
如果您嘗試將錯誤的數據類型的值存儲在Python數組中,該怎麼辦?Apr 27, 2025 am 12:10 AMWhenyouattempttostoreavalueofthewrongdatatypeinaPythonarray,you'llencounteraTypeError.Thisisduetothearraymodule'sstricttypeenforcement,whichrequiresallelementstobeofthesametypeasspecifiedbythetypecode.Forperformancereasons,arraysaremoreefficientthanl
 Python標準庫的哪一部分是:列表或數組?Apr 27, 2025 am 12:03 AM
Python標準庫的哪一部分是:列表或數組?Apr 27, 2025 am 12:03 AMpythonlistsarepartofthestAndArdLibrary,herilearRaysarenot.listsarebuilt-In,多功能,和Rused ForStoringCollections,而EasaraySaraySaraySaraysaraySaraySaraysaraySaraysarrayModuleandleandleandlesscommonlyusedDduetolimitedFunctionalityFunctionalityFunctionality。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

