



作为毕业狗想研究下土地出让方面的信息,需要每一笔的土地出让数据。想从中国土地市场网的土地成交结果公告(http://www.landchina.com/default.aspx?tabid=263&ComName=default)中点击每一笔土地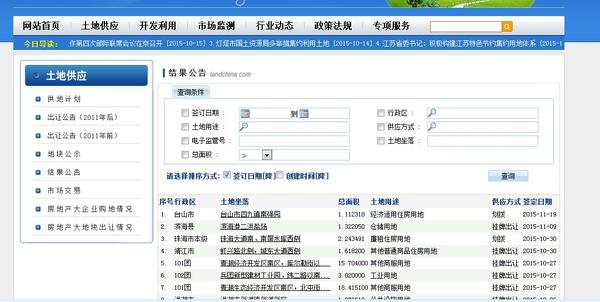 ,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,
,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,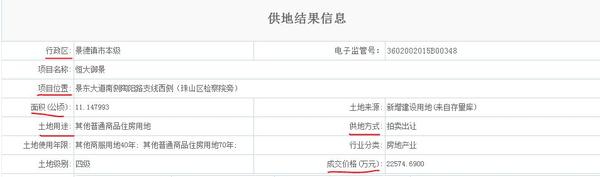 由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
回复内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import random
import sys
def get_post_data(url, headers):
# 访问一次网页,获取post需要的信息
data = {
'TAB_QuerySubmitSortData': '',
'TAB_RowButtonActionControl': '',
}
try:
req = requests.get(url, headers=headers)
except Exception, e:
print 'get baseurl failed, try again!', e
sys.exit(1)
try:
soup = BeautifulSoup(req.text, "html.parser")
TAB_QueryConditionItem = soup.find(
'input', id="TAB_QueryConditionItem270").get('value')
# print TAB_QueryConditionItem
data['TAB_QueryConditionItem'] = TAB_QueryConditionItem
TAB_QuerySortItemList = soup.find(
'input', id="TAB_QuerySort0").get('value')
# print TAB_QuerySortItemList
data['TAB_QuerySortItemList'] = TAB_QuerySortItemList
data['TAB_QuerySubmitOrderData'] = TAB_QuerySortItemList
__EVENTVALIDATION = soup.find(
'input', id='__EVENTVALIDATION').get('value')
# print __EVENTVALIDATION
data['__EVENTVALIDATION'] = __EVENTVALIDATION
__VIEWSTATE = soup.find('input', id='__VIEWSTATE').get('value')
# print __VIEWSTATE
data['__VIEWSTATE'] = __VIEWSTATE
except Exception, e:
print 'get post data failed, try again!', e
sys.exit(1)
return data
def get_info(url, headers):
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "html.parser")
items = soup.find(
'table', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1")
# 所需信息组成字典
info = {}
# 行政区
division = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl").get_text().encode('utf-8')
info['XingZhengQu'] = division
# 项目位置
location = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl").get_text().encode('utf-8')
info['XiangMuWeiZhi'] = location
# 面积(公顷)
square = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl").get_text().encode('utf-8')
info['MianJi'] = square
# 土地用途
purpose = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl").get_text().encode('utf-8')
info['TuDiYongTu'] = purpose
# 供地方式
source = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl").get_text().encode('utf-8')
info['GongDiFangShi'] = source
# 成交价格(万元)
price = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl").get_text().encode('utf-8')
info['ChengJiaoJiaGe'] = price
# print info
# 用唯一值的电子监管号当key, 所需信息当value的字典
all_info = {}
Key_ID = items.find(
'span', id="mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl").get_text().encode('utf-8')
all_info[Key_ID] = info
return all_info
def get_pages(baseurl, headers, post_data, date):
print 'date', date
# 补全post data
post_data['TAB_QuerySubmitConditionData'] = post_data[
'TAB_QueryConditionItem'] + ':' + date
page = 1
while True:
print ' page {0}'.format(page)
# 休息一下,防止被网页识别为爬虫机器人
time.sleep(random.random() * 3)
post_data['TAB_QuerySubmitPagerData'] = str(page)
req = requests.post(baseurl, data=post_data, headers=headers)
# print req
soup = BeautifulSoup(req.text, "html.parser")
items = soup.find('table', id="TAB_contentTable").find_all(
'tr', onmouseover=True)
# print items
for item in items:
print item.find('td').get_text()
link = item.find('a')
if link:
print item.find('a').text
url = 'http://www.landchina.com/' + item.find('a').get('href')
print get_info(url, headers)
else:
print 'no content, this ten days over'
return
break
page += 1
if __name__ == "__main__":
# time.time()
baseurl = 'http://www.landchina.com/default.aspx?tabid=263'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.71 Safari/537.36',
'Host': 'www.landchina.com'
}
post_data = (get_post_data(baseurl, headers))
date = '2015-11-21~2015-11-30'
get_pages(baseurl, headers, post_data, date)
不请自来,知乎首答,同为大四毕业狗之前帮老师爬过这个信息,从1995年-2015年有170多万条,算了下时间需要40多个小时才能爬完。我爬到2000年就没有继续爬了。当时写代码的时候刚学爬虫,不懂原理,发现这个网页点击下一页以及改变日期后,网址是不会变的,网址是不会变的,网址是不会变的Orz,对于新手来说根本不知道是为什么。后来就去找办法,学了点selenium,利用它来模拟浏览器操作,更改日期、点击下一页什么的都可以实现了。好处是简单粗暴,坏处是杀鸡用牛刀,占用了系统太多资源。再到后来,学会了一点抓包技术,知道了原来日期和换页都是通过post请求的。今天下午就把程序修改了一下,用post代替了原来的selenium。废话不说,上代码了。
# -*- coding: gb18030 -*-
'landchina 爬起来!'
import requests
import csv
from bs4 import BeautifulSoup
import datetime
import re
import os
class Spider():
def __init__(self):
self.url='http://www.landchina.com/default.aspx?tabid=263'
#这是用post要提交的数据
self.postData={ 'TAB_QueryConditionItem':'9f2c3acd-0256-4da2-a659-6949c4671a2a',
'TAB_QuerySortItemList':'282:False',
#日期
'TAB_QuerySubmitConditionData':'9f2c3acd-0256-4da2-a659-6949c4671a2a:',
'TAB_QuerySubmitOrderData':'282:False',
#第几页
'TAB_QuerySubmitPagerData':''}
self.rowName=[u'行政区',u'电子监管号',u'项目名称',u'项目位置',u'面积(公顷)',u'土地来源',u'土地用途',u'供地方式',u'土地使用年限',u'行业分类',u'土地级别',u'成交价格(万元)',u'土地使用权人',u'约定容积率下限',u'约定容积率上限',u'约定交地时间',u'约定开工时间',u'约定竣工时间',u'实际开工时间',u'实际竣工时间',u'批准单位',u'合同签订日期']
#这是要抓取的数据,我把除了分期约定那四项以外的都抓取了
self.info=[
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c2_ctrl',#0
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r1_c4_ctrl',#1
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r17_c2_ctrl',#2
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r16_c2_ctrl',#3
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c2_ctrl',#4
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r2_c4_ctrl',#5
#这条信息是土地来源,抓取下来的是数字,它要经过换算得到土地来源,不重要,我就没弄了
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c2_ctrl',#6
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r3_c4_ctrl',#7
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c2_ctrl', #8
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r19_c4_ctrl',#9
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c2_ctrl',#10
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r20_c4_ctrl',#11
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c1_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c2_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c3_0_ctrl',
## 'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f3_r2_c4_0_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r9_c2_ctrl',#12
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f2_r1_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r21_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c2',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r22_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r10_c4_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c2_ctrl',
'mainModuleContainer_1855_1856_ctl00_ctl00_p1_f1_r14_c4_ctrl']
#第一步
def handleDate(self,year,month,day):
#返回日期数据
'return date format %Y-%m-%d'
date=datetime.date(year,month,day)
# print date.datetime.datetime.strftime('%Y-%m-%d')
return date #日期对象
def timeDelta(self,year,month):
#计算一个月有多少天
date=datetime.date(year,month,1)
try:
date2=datetime.date(date.year,date.month+1,date.day)
except:
date2=datetime.date(date.year+1,1,date.day)
dateDelta=(date2-date).days
return dateDelta
def getPageContent(self,pageNum,date):
#指定日期和页数,打开对应网页,获取内容
postData=self.postData.copy()
#设置搜索日期
queryDate=date.strftime('%Y-%m-%d')+'~'+date.strftime('%Y-%m-%d')
postData['TAB_QuerySubmitConditionData']+=queryDate
#设置页数
postData['TAB_QuerySubmitPagerData']=str(pageNum)
#请求网页
r=requests.post(self.url,data=postData,timeout=30)
r.encoding='gb18030'
pageContent=r.text
# f=open('content.html','w')
# f.write(content.encode('gb18030'))
# f.close()
return pageContent
#第二步
def getAllNum(self,date):
#1无内容 2只有1页 3 1—200页 4 200页以上
firstContent=self.getPageContent(1,date)
if u'没有检索到相关数据' in firstContent:
print date,'have','0 page'
return 0
pattern=re.compile(u'<td.*?class="pager".*?>共(.*?)页.*?</td>')
result=re.search(pattern,firstContent)
if result==None:
print date,'have','1 page'
return 1
if int(result.group(1))<=200:
print date,'have',int(result.group(1)),'page'
return int(result.group(1))
else:
print date,'have','200 page'
return 200
#第三步
def getLinks(self,pageNum,date):
'get all links'
pageContent=self.getPageContent(pageNum,date)
links=[]
pattern=re.compile(u'<a.*?href="default.aspx.*?tabid=386(.*?)".*?>',re.S)
results=re.findall(pattern,pageContent)
for result in results:
links.append('http://www.landchina.com/default.aspx?tabid=386'+result)
return links
def getAllLinks(self,allNum,date):
pageNum=1
allLinks=[]
while pageNum<=allNum:
links=self.getLinks(pageNum,date)
allLinks+=links
print 'scrapy link from page',pageNum,'/',allNum
pageNum+=1
print date,'have',len(allLinks),'link'
return allLinks
#第四步
def getLinkContent(self,link):
'open the link to get the linkContent'
r=requests.get(link,timeout=30)
r.encoding='gb18030'
linkContent=r.text
# f=open('linkContent.html','w')
# f.write(linkContent.encode('gb18030'))
# f.close()
return linkContent
def getInfo(self,linkContent):
"get every item's info"
data=[]
soup=BeautifulSoup(linkContent)
for item in self.info:
if soup.find(id=item)==None:
s=''
else:
s=soup.find(id=item).string
if s==None:
s=''
data.append(unicode(s.strip()))
return data
def saveInfo(self,data,date):
fileName= 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')+'/'+datetime.datetime.strftime(date,'%d')+'.csv'
if os.path.exists(fileName):
mode='ab'
else:
mode='wb'
csvfile=file(fileName,mode)
writer=csv.writer(csvfile)
if mode=='wb':
writer.writerow([name.encode('gb18030') for name in self.rowName])
writer.writerow([d.encode('gb18030') for d in data])
csvfile.close()
def mkdir(self,date):
#创建目录
path = 'landchina/'+datetime.datetime.strftime(date,'%Y')+'/'+datetime.datetime.strftime(date,'%m')
isExists=os.path.exists(path)
if not isExists:
os.makedirs(path)
def saveAllInfo(self,allLinks,date):
for (i,link) in enumerate(allLinks):
linkContent=data=None
linkContent=self.getLinkContent(link)
data=self.getInfo(linkContent)
self.mkdir(date)
self.saveInfo(data,date)
print 'save info from link',i+1,'/',len(allLinks)
你可以去神箭手云爬虫开发平台看看。在云上简单几行js就可以实现爬虫,如果这都懒得做也可以联系官方进行定制,任何网站都可以爬,总之是个很方便的爬虫基础设施平台。
这个结构化如此清晰的数据,要采集这个数据是很容易的。 通过多年的数据处理经验,可以给你以下几个建议:1. 多线程
2. 防止封IP
3. 用Mongdb存储大型非结构化数据
了解更多可以访问探码科技大数据介绍页面:http://www.tanmer.com/bigdata 我抓过这个网站的结束合同,还是比较好抓的。抓完生成表格,注意的就是选择栏的异步地区等内容,需要对他的js下载下来队形异步请求。提交数据即可。请求的时候在他的主页有一个id。好像是这么个东西,去年做的,记不清了,我有源码可以给你分享。用java写的 我是爬虫小白,请教下,不是说不能爬取asp的页面吗?
详细内容页的地址是”default.aspx?tabid=386&comname=default&wmguid=75c725。。。“,网站是在default.aspx页读取数据库显示详细信息,不是说读不到数据库里的数据吗?

 Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AMPython cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AMCara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AM
Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AMMemuatkan Fail Pickle di Python 3.6 Kesalahan Laporan Alam Sekitar: ModulenotFoundError: Nomodulenamed ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Dreamweaver CS6
Alat pembangunan web visual

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

