
Rumah >Peranti teknologi >AI >LeCun di bulan? Nankai dan Byte sumber terbuka StoryDiffusion untuk menjadikan komik berbilang gambar dan video panjang lebih koheren
LeCun di bulan? Nankai dan Byte sumber terbuka StoryDiffusion untuk menjadikan komik berbilang gambar dan video panjang lebih koheren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-05-06 16:10:311153semak imbas
Dua hari lalu, pemenang Anugerah Turing Yann LeCun menyiarkan semula komik panjang "Go to the Moon and Explore Yourself", yang membangkitkan perbincangan hangat di kalangan netizen.

Dalam kertas kerja "Story Diffusion: Konsisten Perhatian Diri untuk imej jarak jauh dan penjanaan video", pasukan penyelidik mencadangkan kaedah baharu yang dipanggil Story Diffusion untuk menghasilkan imej dan video yang konsisten Huraikan situasi yang kompleks. Penyelidikan mengenai komik ini datang dari institusi seperti Universiti Nankai dan ByteDance.

- Alamat kertas: https://arxiv.org/pdf/2405.01434v1
- Laman utama projek: https://storydiffusion.github.io/🜎 sudah dihidupkan semulaprojek
dihidupkan GitHub Mendapat amaun 1k Bintang.
Alamat GitHub: https://github.com/HVision-NKU/StoryDiffusion
Menurut demonstrasi projek, StoryDiffusion boleh menjana komik pelbagai gaya, cerita yang konsisten gaya dan pakaian.

StoryDiffusion boleh mengekalkan identiti berbilang watak secara serentak dan menjana watak yang konsisten merentas siri imej.

Selain itu, StoryDiffusion mampu menjana video berkualiti tinggi yang dikondisikan pada imej konsisten yang dihasilkan atau imej yang dimasukkan pengguna.


Kami tahu bahawa mengekalkan konsistensi kandungan merentas siri imej yang dijana, terutamanya yang mengandungi topik dan butiran yang kompleks, merupakan satu cabaran yang ketara untuk model generatif berasaskan resapan .
Oleh itu, pasukan penyelidik mencadangkan kaedah pengiraan perhatian kendiri baharu, yang dipanggil Perhatian Kendiri Konsisten, dengan mewujudkan hubungan antara imej dalam satu kelompok apabila menjana imej yang konsisten dan menjana imej yang konsisten secara tema tanpa latihan.
Untuk memanjangkan kaedah ini kepada penjanaan video yang panjang, pasukan penyelidik memperkenalkan peramal gerakan semantik (Semantic Motion Predictor), yang mengekod imej ke dalam ruang semantik dan meramalkan gerakan dalam ruang semantik untuk menghasilkan video. Ini lebih stabil daripada ramalan gerakan hanya berdasarkan ruang terpendam.
Kemudian lakukan penyepaduan rangka kerja, menggabungkan perhatian kendiri yang konsisten dan peramal gerakan semantik untuk menjana video yang konsisten dan menceritakan kisah yang kompleks. StoryDiffusion boleh menjana video yang lebih lancar dan lebih koheren daripada kaedah sedia ada.

Rajah 1: Imej dan video yang dijana oleh StroyDiffusion pasukan
Tinjauan keseluruhan kaedah
yang ditunjukkan dalam dua peringkat dan Rajah 3. Pasukan penyelidik boleh dibahagikan kepada dua peringkat.
Pada peringkat pertama, StoryDiffusion menggunakan Perhatian Kendiri Konsisten untuk menjana imej konsisten topik dengan cara tanpa latihan. Imej yang konsisten ini boleh digunakan secara langsung dalam bercerita atau sebagai input kepada peringkat kedua. Pada peringkat kedua, StoryDiffusion mencipta video peralihan yang konsisten berdasarkan imej yang konsisten ini.
🎜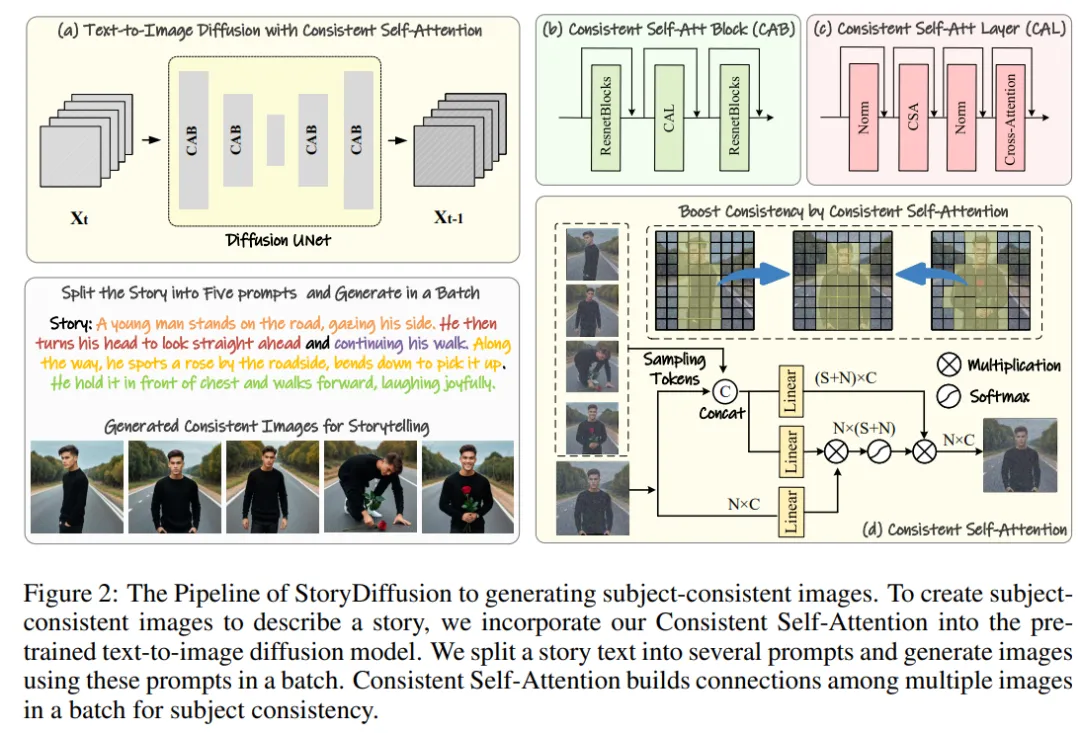
Rajah 2: Gambaran keseluruhan proses StoryDiffusion untuk menghasilkan imej yang konsisten tema
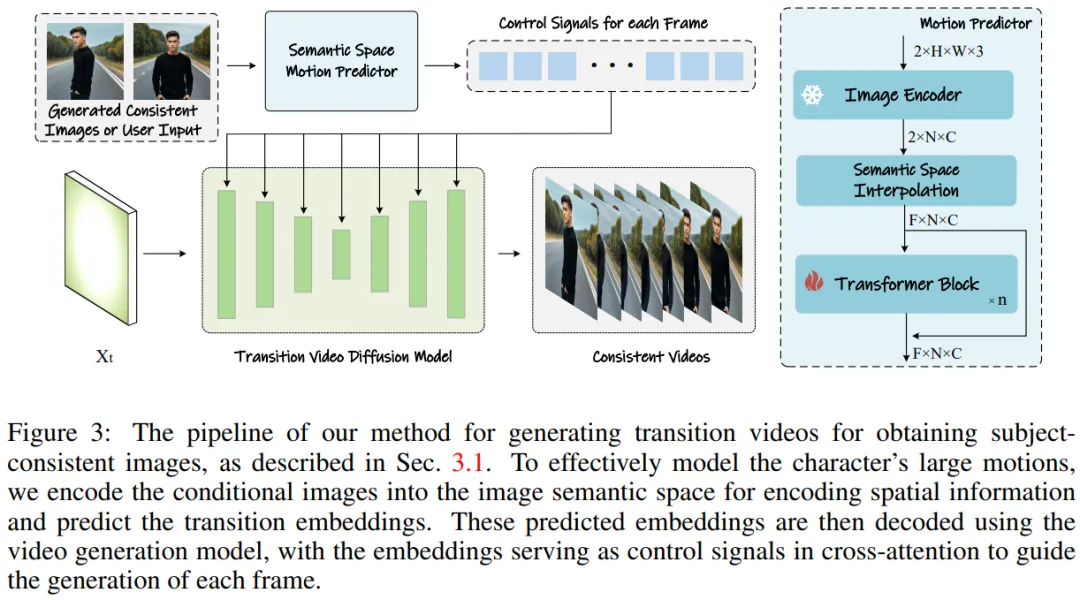 Rajah 3: Kaedah untuk menjana video peralihan untuk mendapatkan imej yang konsisten tema.
Rajah 3: Kaedah untuk menjana video peralihan untuk mendapatkan imej yang konsisten tema.
Penjanaan imej yang konsisten tanpa latihan
Pasukan penyelidik memperkenalkan kaedah "cara menghasilkan imej yang konsisten dengan tema tanpa latihan". Kunci untuk menyelesaikan masalah di atas ialah bagaimana untuk mengekalkan konsistensi watak dalam kumpulan imej. Ini bermakna semasa proses penjanaan, mereka perlu mewujudkan hubungan antara kumpulan imej.
Selepas meneliti semula peranan mekanisme perhatian yang berbeza dalam model penyebaran, mereka telah diilhamkan untuk meneroka penggunaan perhatian kendiri untuk mengekalkan ketekalan imej dalam kumpulan imej, dan mencadangkan Perhatian Kendiri Konsisten -Perhatian ).
Pasukan penyelidik memasukkan perhatian kendiri yang konsisten ke dalam kedudukan perhatian diri asal dalam seni bina U-Net model penjanaan imej sedia ada dan menggunakan semula pemberat perhatian kendiri asal untuk mengekalkan tiada latihan dan pasang dan main Ciri yang digunakan.
Memandangkan token berpasangan, kaedah pasukan penyelidik melakukan perhatian kendiri pada sekumpulan imej, menggalakkan interaksi antara ciri imej yang berbeza. Jenis interaksi ini mendorong penumpuan model pada watak, wajah dan pakaian semasa penjanaan. Walaupun kaedah perhatian diri yang konsisten adalah mudah dan tidak memerlukan latihan, ia boleh menjana imej yang konsisten secara tematik dengan berkesan.
Untuk menggambarkan dengan lebih jelas, pasukan penyelidik menunjukkan pseudokod dalam Algoritma 1.

Semantic Motion Predictor for Video Generation
Pasukan penyelidik mencadangkan Semantic Motion Predictor (Semantic Motion Predictor), yang membolehkan maklumat ruang untuk menangkap semantik imej yang lebih tepat. ramalan daripada bingkai permulaan dan bingkai akhir yang diberikan.
Secara lebih khusus, dalam peramal gerakan semantik yang dicadangkan oleh pasukan, mereka mula-mula menggunakan fungsi E untuk mewujudkan pemetaan daripada imej RGB kepada vektor ruang semantik imej untuk mengekod maklumat spatial.
Pasukan tidak secara langsung menggunakan lapisan linear sebagai fungsi E. Sebaliknya, ia menggunakan pengekod imej CLIP terlatih sebagai fungsi E untuk memanfaatkan keupayaan tangkapan sifarnya untuk meningkatkan prestasi.
Menggunakan fungsi E, bingkai mula yang diberikan F_s dan bingkai akhir F_e dimampatkan ke dalam vektor ruang semantik imej K_s dan K_e.

Hasil eksperimen
Dari segi penjanaan imej konsisten topik, memandangkan kaedah pasukan tidak memerlukan latihan dan plug-and-play, mereka menggunakan dua versi Stable Diffusion XL dan Stable Diffusion 1.5 melaksanakan kaedah ini. Untuk selaras dengan model yang dibandingkan, mereka menggunakan pemberat pra-latihan yang sama pada model Stable-XL sebagai perbandingan.
Untuk menjana video yang konsisten, para penyelidik melaksanakan kaedah penyelidikan mereka berdasarkan model khusus Stable Diffusion 1.5 dan menyepadukan modul temporal yang telah terlatih untuk menyokong penjanaan video. Semua model yang dibandingkan menggunakan skor bimbingan bebas pengelas 7.5 dan pensampelan DDIM 50 langkah.
Perbandingan Penjanaan Imej Konsisten
Pasukan menilai pendekatan mereka untuk menjana imej yang konsisten secara tema dengan membandingkannya dengan dua kaedah pemeliharaan ID terkini – Penyesuai IP dan Pembuat Foto.
Untuk menguji prestasi, mereka menggunakan GPT-4 untuk menghasilkan dua puluh arahan peranan dan seratus arahan aktiviti untuk menerangkan aktiviti tertentu.
Hasil kualitatif ditunjukkan dalam Rajah 4: "StoryDiffusion mampu menghasilkan imej yang sangat konsisten. Manakala kaedah lain, seperti Penyesuai IP dan PhotoMaker, mungkin menghasilkan imej dengan pakaian yang tidak konsisten atau kebolehkawalan teks yang berkurangan." Rajah 4: Perbandingan penjanaan imej yang konsisten dengan kaedah semasa Pengkaji menunjukkan hasil perbandingan kuantitatif dalam Jadual 1. Keputusan menunjukkan: "StoryDiffusion pasukan mencapai prestasi terbaik pada kedua-dua metrik kuantitatif, menunjukkan bahawa kaedah itu boleh sesuai dengan penerangan segera sambil mengekalkan ciri watak dan menunjukkan keteguhannya." penjanaan imej yang konsisten Dari segi penjanaan video peralihan, pasukan penyelidik membandingkan dua kaedah terkini - SparseCtrl dan SEINE - Perbandingan dibuat untuk menilai prestasi. Mereka menjalankan perbandingan kualitatif penjanaan video peralihan dan menunjukkan keputusan dalam Rajah 5. Keputusan menunjukkan: "StoryDiffusion pasukan adalah jauh lebih baik daripada SEINE dan SparseCtrl, dan video peralihan yang dihasilkan adalah lancar dan konsisten dengan prinsip fizikal Rajah 5: Peralihan yang sedang menggunakan pelbagai keadaan terkini." -kaedah seni Perbandingan penjanaan video Mereka juga membandingkan kaedah ini dengan SEINE dan SparseCtrl, dan menggunakan empat metrik kuantitatif termasuk LPIPSfirst, LPIPS-frame, CLIPSIM-first dan CLIPSIM-frame, seperti yang ditunjukkan dalam Jadual 2. Jadual 2: Perbandingan kuantitatif dengan model penjanaan video peralihan terkini Sila rujuk kertas asal untuk mendapatkan butiran lanjut teknikal dan eksperimen. 
 Perbandingan penjanaan video peralihan
Perbandingan penjanaan video peralihan

Atas ialah kandungan terperinci LeCun di bulan? Nankai dan Byte sumber terbuka StoryDiffusion untuk menjadikan komik berbilang gambar dan video panjang lebih koheren. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!