
Rumah >Peranti teknologi >AI >Indeks model besar berbilang mod teks 8B adalah hampir dengan GPT4V, Huashan dan Huake yang dicadangkan bersama TextSquare
Indeks model besar berbilang mod teks 8B adalah hampir dengan GPT4V, Huashan dan Huake yang dicadangkan bersama TextSquare

- PHPzke hadapan
- 2024-04-25 18:16:011378semak imbas

Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai karya cemerlang yang ingin anda kongsi, sila serahkan artikel atau hubungi e-mel pelaporan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Baru-baru ini, model besar berbilang modal (MLLM) telah mencapai kemajuan yang ketara dalam bidang VQA berpaksikan teks, terutamanya berbilang model sumber tertutup, seperti: GPT4V dan Gemini, malah menunjukkan prestasi luar biasa dalam beberapa aspek. prestasi kebolehan. Walau bagaimanapun, prestasi model sumber terbuka masih jauh di belakang model sumber tertutup Baru-baru ini, banyak kajian terobosan, seperti: MonKey, LLaVAR, TG-Doc, ShareGPT4V, dsb., telah mula memfokuskan kepada masalah kekurangan arahan yang baik-. menala data. Walaupun usaha ini telah mencapai hasil yang luar biasa, masih terdapat beberapa masalah data perihalan imej dan data VQA tergolong dalam domain yang berbeza, dan terdapat ketidakkonsistenan dalam butiran dan skop persembahan kandungan imej. Tambahan pula, saiz data sintetik yang agak kecil menghalang MLLM daripada merealisasikan potensi penuhnya. .
Penjanaan Data VQA 
- Kaedah strategi Kuasa Dua+ merangkumi empat langkah: Penyoalan Kendiri, Menjawab, Penaakulan dan Penilaian Kendiri. Penyoalan Kendiri memanfaatkan keupayaan MLLM dalam analisis imej teks dan pemahaman untuk menjana soalan yang berkaitan dengan kandungan teks dalam imej. Menjawab Kendiri memberikan jawapan kepada soalan-soalan ini menggunakan pelbagai teknik dorongan seperti: CoT dan few-shot. Penaakulan Kendiri menggunakan keupayaan penaakulan yang berkuasa MLLM untuk menjana proses penaakulan di sebalik model. Penilaian Kendiri meningkatkan kualiti data dan mengurangkan berat sebelah dengan menilai soalan untuk kesahihan, kaitan dengan kandungan teks imej dan ketepatan jawapan.
- Berdasarkan kaedah persegi, para penyelidik mengumpulkan pelbagai imej yang mengandungi sejumlah besar teks dari pelbagai sumber awam, termasuk adegan semula jadi, carta, bentuk, resit, buku, ppt, pdf, dll. untuk membina Square-10M, dan berdasarkan set data ini melatih MLLM TextSquare-8B berpusatkan pemahaman Teks.
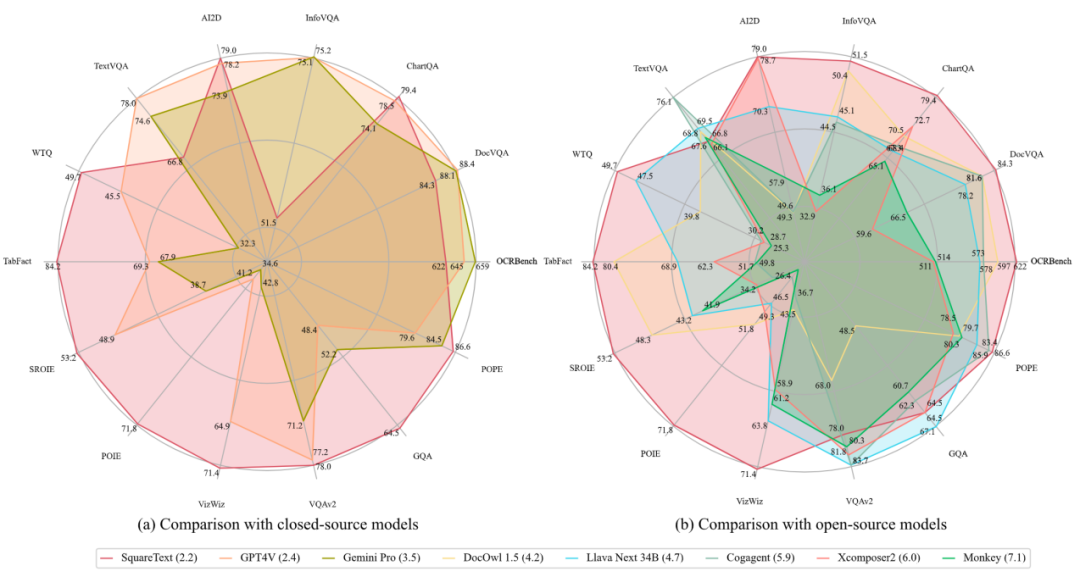
Seperti yang ditunjukkan dalam Rajah 1, TextSquare-8B boleh mencapai hasil yang setanding atau lebih baik daripada GPT4V dan Gemini pada berbilang penanda aras, dan dengan ketara melebihi model sumber terbuka yang lain. Eksperimen TextSquare mengesahkan kesan positif data inferens pada tugas VQA, menunjukkan keupayaannya untuk meningkatkan prestasi model sambil mengurangkan halusinasi.
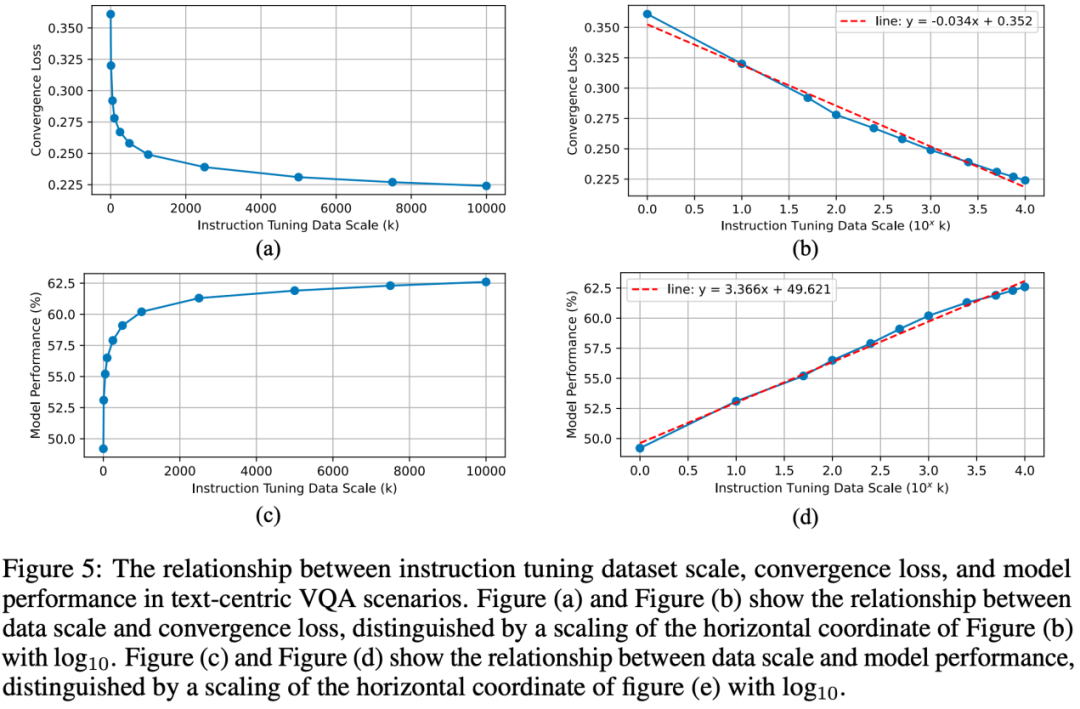
Selain itu, dengan memanfaatkan set data berskala besar, hubungan antara saiz data pelarasan arahan, kehilangan penumpuan latihan dan prestasi model didedahkan. Walaupun sejumlah kecil data pelarasan arahan boleh melatih MLLM dengan baik, kerana data pelarasan arahan terus berkembang, prestasi model boleh ditingkatkan lagi, dan terdapat juga undang-undang skala yang sepadan antara data penalaan halus arahan dan model .合 Rajah 2 Proses sintesis data VQA, termasuk penjanaan data, JAWAPAN, Penaakulan), dan penapisan data
Matlamat utama strategi pengumpulan data adalah untuk merangkumi pelbagai senario kaya teks dunia sebenar. Untuk tujuan ini, para penyelidik mengumpul 3.8 juta imej kaya teks. Imej ini mempamerkan ciri yang berbeza, contohnya, carta dan jadual memfokuskan pada elemen teks dengan maklumat statistik padat, tangkapan skrin dan Imej Web direka untuk interaksi antara teks dan maklumat visual yang diserlahkan, resit dan E-dagang mengandungi imej dengan teks yang terperinci dan padat diperoleh daripada pemandangan semula jadi. Imej yang dikumpul membentuk pemetaan unsur teks dalam dunia sebenar dan membentuk asas untuk mengkaji VQA berpusatkan teks.
Penjanaan data
Penyelidik menggunakan keupayaan pemahaman berbilang mod Gemini Pro untuk memilih imej daripada sumber data tertentu dan menjana VQA dan pasangan konteks inferens melalui tiga peringkat menyoal kendiri, menjawab kendiri dan inferens kendiri.
Soalan Diri: Beberapa gesaan akan diberikan pada peringkat ini Gemini Pro akan menjalankan analisis menyeluruh terhadap imej berdasarkan gesaan ini dan menjana beberapa soalan yang bermakna berdasarkan pemahaman. Memandangkan keupayaan MLLM umum untuk memahami elemen teks biasanya lebih lemah daripada model visual, kami memproses terlebih dahulu teks yang diekstrak menjadi segera melalui model OCR khusus.
Jawab Kendiri: Gemini Pro akan menggunakan rantaian pemikiran (CoT) dan dorongan beberapa pukulan (gerakan beberapa pukulan) dan teknologi lain untuk menjana soalan untuk memperkayakan maklumat kontekstual dan meningkatkan kebolehpercayaan jawapan yang dijana.
Penaakulan Diri: Peringkat ini menjana sebab terperinci untuk jawapan, memaksa Gemini Pro untuk memikirkan lebih lanjut tentang kaitan antara soalan dan elemen visual, dengan itu mengurangkan ilusi dan meningkatkan jawapan yang tepat. . Oleh itu, kami mereka bentuk peraturan penapisan berdasarkan keupayaan penilaian LLM untuk memilih pasangan VQA berkualiti tinggi.
Penilaian Kendiri menggesa Gemini Pro dan MLLM lain untuk menentukan sama ada soalan yang dijana masuk akal dan sama ada jawapannya mencukupi untuk menyelesaikan masalah dengan betul.
- Ketekalan Berbilang Cepat
Selain menilai secara langsung kandungan yang dijana, penyelidik juga menambah gesaan dan ruang konteks secara manual dalam penjanaan data. Pasangan VQA yang betul dan bermakna harus konsisten dari segi semantik apabila gesaan berbeza diberikan.
- Konsistensi Berbilang Konteks
Penyelidik mengesahkan lagi pasangan VQA dengan menyediakan maklumat konteks yang berbeza sebelum soalan.
- TextSquare-8B
TextSquare-8B menarik pada struktur model InternLM-Xcomposer2, termasuk pengekod visual CLIP ViT-L-14-336, dan resolusi imej ditingkatkan lagi; InternLM2-7B-ChatSFT model bahasa besar LLM; projektor jambatan yang menjajarkan token visual dan teks. Latihan
TextSquare-8B merangkumi tiga peringkat SFT:
Peringkat pertama memperhalusi model dengan parameter penuh (Pengekod Visi, Projektor, LLM) pada resolusi 490. Pada peringkat kedua, resolusi input ditingkatkan kepada 700 dan hanya Vision Encoder dilatih untuk menyesuaikan diri dengan perubahan resolusi.
Pada peringkat ketiga, penalaan halus parameter penuh selanjutnya dilakukan pada resolusi 700.
TextSquare mengesahkan bahawa berdasarkan set data Square-10M, model dengan parameter 8B dan resolusi imej bersaiz normal boleh mencapai prestasi yang lebih baik pada VQA tertumpu teks berbanding kebanyakan MLLM, malah model sumber tertutup (GPT4V , Gemini Pro).
Hasil eksperimenRajah 4(a) menunjukkan bahawa TextSquare mempunyai fungsi aritmetik mudah. Rajah 4(b) menunjukkan keupayaan untuk memahami kandungan teks dan menyediakan lokasi anggaran dalam teks padat. Rajah 4(c) menunjukkan keupayaan TextSquare untuk memahami struktur jadual. Penanda Aras MLLM model, dalam data ChartQA Set ini lebih tinggi sedikit daripada GPT4V dan Gemini Pro Resolusi model ini hanya 700, yang lebih kecil daripada kebanyakan MLLM berorientasikan dokumen Jika resolusi dipertingkatkan lagi, saya percaya prestasi model juga akan dipertingkatkan lagi Monyet telah membuktikannya.
Scene Text-centric Benchmark Penanda Aras VQA (TextVQA, AI2D) bagi pemandangan semula jadi telah mencapai keputusan SOTA, tetapi tidak ada peningkatan besar berbanding dengan garis dasar Xcomposer2 Ini mungkin kerana Xcomposer2 telah menggunakan kualiti tinggi dalam-. domain Data dioptimumkan sepenuhnya.
 Tanda Aras VQA Jadual
Tanda Aras VQA Jadual
Tanda Aras KIE bertumpu teks Ekstrak maklumat utama pusat teks daripada penanda aras tugas KIE (SROIE, POIE), tukar tugas KIE kepada tugas VQA dan capai prestasi terbaik dalam kedua-dua set data, dengan peningkatan purata sebanyak 14.8%.
OCRBench Termasuk 29 tugas penilaian berkaitan OCR seperti pengecaman teks, pengecaman formula, VQA berpusat teks, KIE, dsb., mencapai prestasi terbaik model sumber terbuka dan menjadi amaun parameter 10B pertama untuk mencapai 600 mata Model.
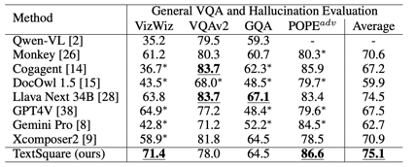
General VQA dan Penilaian Penilaian Hallucination Berbanding dengan XConposer2, TextSquare tidak mempunyai kemerosotan yang signifikan dan masih mengekalkan prestasi terbaik pada penanda aras VQA umum (Vizwiz VQAV2, GQA, POPE). prestasi ketara, 3.6% lebih tinggi daripada kaedah terbaik, yang menyerlahkan keberkesanan kaedah dalam mengurangkan halusinasi model.
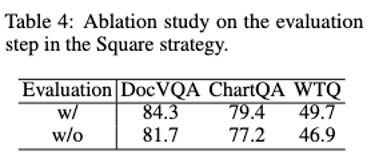
Percubaan Ablation

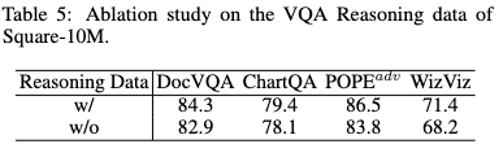
Skala data dan kehilangan penumpuan & perhubungan prestasi model
Ringkasan
Dalam artikel ini, penyelidik mencadangkan strategi Square untuk membina set data talaan arahan berpusatkan teks berkualiti tinggi (Square-10M Menggunakan set data ini, TextSquare-8B berprestasi baik pada berbilang tanda aras It mencapai prestasi yang setanding dengan GPT4V dan dengan ketara mengatasi prestasi model sumber terbuka yang dikeluarkan baru-baru ini pada pelbagai penanda aras. Selain itu, penyelidik memperoleh hubungan antara saiz set data pelarasan arahan, kehilangan penumpuan dan prestasi model untuk membuka jalan untuk membina set data yang lebih besar, mengesahkan bahawa kuantiti dan kualiti data adalah penting untuk prestasi model. Akhirnya, para penyelidik menegaskan bahawa cara untuk meningkatkan lagi kuantiti dan kualiti data untuk mengecilkan jurang antara model sumber terbuka dan model terkemuka dianggap sebagai hala tuju penyelidikan yang sangat menjanjikan.Atas ialah kandungan terperinci Indeks model besar berbilang mod teks 8B adalah hampir dengan GPT4V, Huashan dan Huake yang dicadangkan bersama TextSquare. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!