
Rumah >Peranti teknologi >AI >Semakan! Gabungan model mendalam (LLM/model asas/pembelajaran bersekutu/penalaan halus, dsb.)
Semakan! Gabungan model mendalam (LLM/model asas/pembelajaran bersekutu/penalaan halus, dsb.)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-18 21:43:071047semak imbas
Pada 23 September, kertas kerja "Deep Model Fusion: A Survey" diterbitkan oleh Universiti Teknologi Pertahanan Nasional, JD.com dan Institut Teknologi Beijing.
Penyatuan/penggabungan model mendalam ialah teknologi baru muncul yang menggabungkan parameter atau ramalan berbilang model pembelajaran mendalam ke dalam satu model. Ia menggabungkan keupayaan model yang berbeza untuk mengimbangi bias dan ralat model individu untuk prestasi yang lebih baik. Gabungan model mendalam pada model pembelajaran mendalam berskala besar (seperti LLM dan model asas) menghadapi beberapa cabaran, termasuk kos pengiraan yang tinggi, ruang parameter berdimensi tinggi, gangguan antara model heterogen yang berbeza, dsb. Kertas kerja ini membahagikan kaedah gabungan model dalam sedia ada kepada empat kategori: (1) "Sambungan corak", yang menghubungkan penyelesaian dalam ruang berat melalui laluan pengurangan kerugian untuk mendapatkan permulaan gabungan model yang lebih baik, (2) " Penjajaran", padanan unit antara rangkaian saraf untuk mewujudkan keadaan yang lebih baik untuk gabungan; (3) "Purata berat" ialah kaedah gabungan model klasik yang meratakan berat berbilang model untuk mendapatkan penyelesaian yang lebih dekat dengan penyelesaian yang lebih tepat dan hasil yang lebih tepat; output model yang berbeza, yang merupakan teknologi asas untuk meningkatkan ketepatan dan keteguhan model akhir. Di samping itu, cabaran yang dihadapi oleh gabungan model mendalam dianalisis dan kemungkinan arah penyelidikan untuk gabungan model masa hadapan dicadangkan.
Gabungan model mendalam telah menarik minat yang semakin meningkat disebabkan oleh privasi data dan isu penjimatan data praktikal. Walaupun pembangunan gabungan model mendalam telah membawa banyak penemuan teknologi, ia juga telah mencipta satu siri cabaran, seperti beban pengiraan yang tinggi, kepelbagaian model dan penjajaran pengoptimuman gabungan yang perlahan. Ini memberi inspirasi kepada saintis untuk mengkaji prinsip gabungan model dalam situasi yang berbeza.
Sesetengah kerja hanya memfokuskan pada gabungan model dari satu perspektif (seperti gabungan ciri, dll.) [45, 195] dan adegan tertentu [213], bukannya gabungan parameter. Bersama-sama dengan kemajuan terkini dan aplikasi perwakilan, seperti pembelajaran bersekutu (FL) [160] dan penalaan halus [29], makalah ini membahagikannya kepada empat kategori berdasarkan mekanisme dan tujuan dalaman. Rajah menunjukkan gambarajah skematik keseluruhan proses gabungan model, serta klasifikasi dan sambungan pelbagai kaedah.
Untuk model yang dilatih secara bebas dan tidak bersebelahan antara satu sama lain, "Mode Join" dan "Align" mendekatkan penyelesaian, menghasilkan purata keadaan mentah yang lebih baik. Untuk model yang serupa dengan perbezaan tertentu dalam ruang berat, "purata berat (WA)" cenderung untuk meratakan model secara langsung untuk mendapatkan penyelesaian yang lebih dekat dengan titik optimum dalam kawasan ruang parameter dengan nilai fungsi kehilangan yang lebih rendah. Selain itu, untuk ramalan daripada model sedia ada, "pembelajaran ensemble" menyepadukan ramalan daripada pelbagai bentuk model untuk mencapai hasil yang lebih baik.
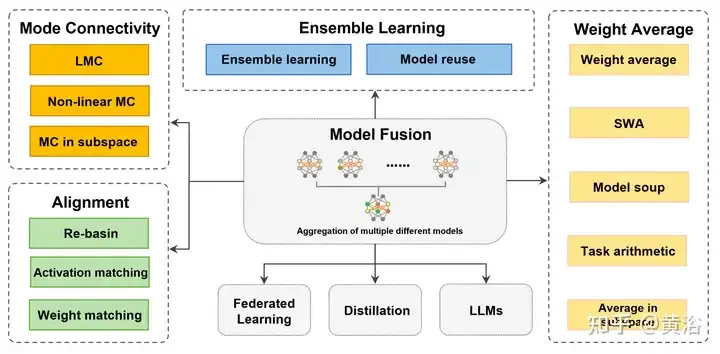
"Penyatuan model, sebagai teknik untuk meningkatkan ketepatan dan keteguhan model mendalam, telah menggalakkan penambahbaikan dalam banyak bidang aplikasi. 'Pembelajaran bersekutu [160]' ialah model yang mengagregatkan model pelanggan pada ketepatan pelayan pusat dan aplikasi keteguhan, membolehkan pihak menyumbang data kepada pengiraan fungsi (cth. pelbagai statistik, pengelas [177]) tanpa risiko kebocoran privasi oleh 'penalaan halus' yang terlatih Pelarasan kecil dibuat pada model dan digabungkan dengan gabungan model untuk mengurangkan kos latihan dan menyesuaikan diri dengan keperluan tugas atau domain tertentu juga melibatkan 'penyulingan', iaitu menggabungkan pengetahuan sasaran lembut pelbagai model kompleks (guru) untuk melatih satu model kepada keperluan khusus. 'Model fusion on base/LLM' termasuk kerja pada model asas besar atau model bahasa besar (LLM), seperti Transformer (ViT) [79], GPT [17], dll. Aplikasi tertumpu membantu pembangun menyesuaikan diri dengan keperluan pelbagai tugas dan domain, menggalakkan pembangunan pembelajaran mendalam." Jumlah perkataan penuh.
Untuk menentukan sama ada keputusan rangkaian terlatih adalah stabil kepada hingar SGD, penghalang kehilangan (halangan ralat) ditakrifkan sebagai perbezaan maksimum antara interpolasi linear kehilangan dua mata dan kehilangan sambungan linear dua titik [50 ]. Halangan kehilangan menentukan sama ada ralat adalah malar atau meningkat sepanjang graf pengoptimuman laluan [56, 61] antara W1 dan W2. Jika terdapat terowong antara dua rangkaian dengan penghalang lebih kurang sama dengan 0, ia adalah bersamaan dengan sambungan mod [46, 59, 60]. Dalam erti kata lain, minima tempatan yang diperolehi oleh SGD boleh disambungkan melalui laluan φ yang meminimumkan kerugian maksimum.
Penyelesaian yang diperoleh daripada pengoptimuman berasaskan kecerunan boleh disambungkan melalui laluan (penyambung) tanpa halangan dalam ruang berat, yang dipanggil sambungan corak[46, 50]. Model lain yang lebih sesuai untuk gabungan model boleh didapati di sepanjang laluan kehilangan rendah. Mengikut bentuk matematik laluan dan ruang di mana penyambung terletak, ia dibahagikan kepada tiga bahagian: "Sambungan Mod Linear (LMC) [66]", "Sambungan Mod Tak Linear" dan "Sambungan Corak Subruang".
Sambungan corak boleh menyelesaikan masalah pengoptimuman tempatan semasa latihan. Hubungan geometri laluan sambungan corak [61, 162] juga boleh digunakan untuk mempercepatkan penumpuan, kestabilan dan ketepatan proses pengoptimuman seperti keturunan kecerunan stokastik (SGD). Secara ringkasnya, sambungan corak menyediakan perspektif baru untuk mentafsir dan memahami tingkah laku gabungan model [66]. Walau bagaimanapun, kerumitan pengiraan dan kesukaran penalaan parameter harus ditangani, terutamanya apabila melatih model pada set data yang besar. Jadual berikut ialah ringkasan prosedur latihan standard untuk Sambungan Mod Linear (LMC) dan Sambungan Mod Bukan Linear.
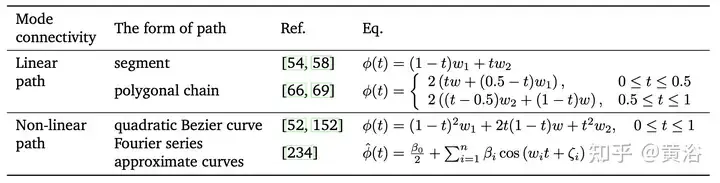
Gambar menunjukkan peta kehilangan dua dimensi dan gambar rajah sambungan corak dalam subruang dimensi lain. Kiri: Interpolasi linear dua minima lembangan menghasilkan halangan kehilangan yang tinggi [46]. Dua nilai optimum yang lebih rendah mengikuti laluan kehilangan rendah yang hampir berterusan (cth. Bezier curve, rantai polibox, dll.) [66]. π(W2) ialah model setara bagi simetri susunan W2, yang terletak dalam lembangan yang sama dengan W1. Re-Basin menggabungkan model dengan menyediakan penyelesaian untuk tadahan air individu [3]. Kanan: Laluan kehilangan rendah menyambungkan berbilang minima dalam subruang (cth., manifold kehilangan rendah yang terdiri daripada baji dimensi d [56], dsb.).
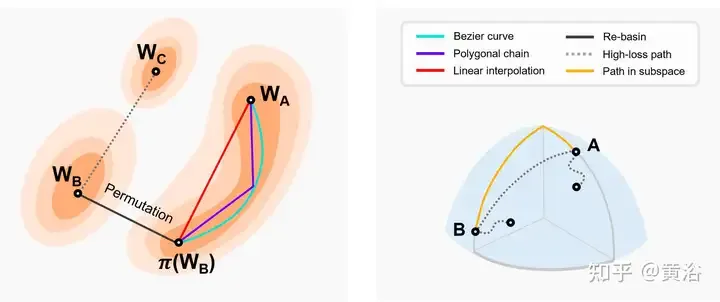
Jadual berikut ialah kaedah mencari terowong antara minima tempatan yang berbeza.
Ringkasnya, sambungan corak menyediakan perspektif yang lebih baharu dan lebih fleksibel untuk gabungan model yang mendalam. Latihan rangkaian saraf dengan mudah boleh jatuh ke dalam optimum tempatan, yang membawa kepada kemerosotan prestasi. Berdasarkan sambungan model, model lain dengan prestasi yang lebih baik boleh ditemui dan digunakan sebagai titik permulaan untuk pengoptimuman dan gabungan selanjutnya. Model yang sudah terlatih boleh digunakan untuk bergerak dalam ruang parameter untuk mencapai model sasaran baharu, yang boleh menjimatkan masa dan overhed pengiraan dan sesuai untuk situasi di mana data terhad. Walau bagaimanapun, apabila menyambungkan model yang berbeza, kerumitan dan fleksibiliti tambahan mungkin diperkenalkan, meningkatkan risiko overfitting. Oleh itu, hiperparameter dan tahap variasi yang berkaitan harus dikawal dengan teliti. Selain itu, penggabungan corak memerlukan penalaan halus atau perubahan parameter, yang boleh meningkatkan masa latihan dan penggunaan sumber. Ringkasnya, ketersambungan model mempunyai banyak kelebihan dalam gabungan model, termasuk membantu mengatasi masalah optimum setempat dan menyediakan perspektif baharu untuk menerangkan tingkah laku rangkaian. Pada masa hadapan, sambungan corak dijangka dapat membantu memahami mekanisme dalaman rangkaian saraf dan memberikan panduan untuk reka bentuk gabungan model dalam yang lebih cekap pada masa hadapan.
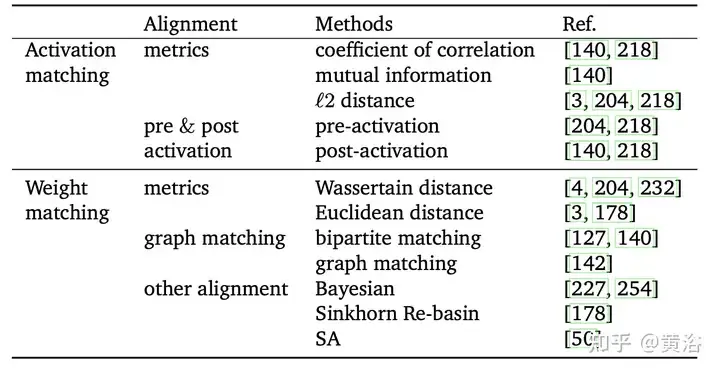
Disebabkan saluran dan komponen rawak dari rangkaian yang berbeza, komponen aktif rangkaian mengganggu antara satu sama lain [204]. Oleh itu, purata wajaran yang tidak sejajar mungkin mengabaikan surat-menyurat antara unit dalam model yang berbeza dan merosakkan maklumat berguna. Sebagai contoh, terdapat hubungan antara dua neuron dalam model berbeza yang mungkin berbeza sama sekali tetapi fungsinya serupa. Penjajaran adalah untuk memadankan unit model yang berbeza untuk mendapatkan keadaan awal yang lebih baik untuk gabungan model dalam. Tujuannya adalah untuk menjadikan perbezaan antara berbilang model lebih kecil, dengan itu meningkatkan kesan gabungan model dalam. Tambahan pula, penjajaran pada asasnya boleh dilihat sebagai masalah pengoptimuman gabungan. Mekanisme perwakilan "Re-basin" yang menyediakan penyelesaian untuk besen individu, menggabungkan model dengan keadaan asal yang lebih baik. Bergantung pada sama ada sasaran penjajaran dipacu data atau tidak, penjajaran dibahagikan kepada dua jenis: "padanan pengaktifan" dan "padanan berat", seperti yang ditunjukkan dalam jadual.
Secara umumnya, walaupun untuk rangkaian saraf cetek, bilangan titik pelana dan optima tempatan meningkat secara eksponen dengan bilangan parameter [10, 66]. Telah didapati bahawa terdapat invarian dalam latihan, menyebabkan beberapa titik dalam optima tempatan ini mempunyai perwakilan yang sama [22, 81, 140]. Khususnya, jika unit lapisan tersembunyi ditukar dengan pilih atur, kefungsian rangkaian tidak berubah, yang dipanggil simetri pilihatur[43, 50].
Simetri pilihatur yang dibawa oleh invarian ini membantu untuk lebih memahami struktur graf kehilangan [22, 66]. Invarian juga boleh dilihat sebagai sumber mata pelana dalam graf kehilangan [14]. [68] mengkaji struktur algebra simetri dalam rangkaian saraf dan bagaimana struktur ini memanifestasikan dirinya dalam geometri graf kehilangan. [14] memperkenalkan titik pilih atur dalam platform berdimensi tinggi di mana neuron boleh ditukar tanpa meningkatkan kerugian atau lompatan parameter. Lakukan penurunan kecerunan pada kehilangan, melaraskan vektor parameter θm dan θn neuron m dan n sehingga vektor mencapai titik penjajaran.
Berdasarkan simetri susunan, penyelesaian di kawasan berbeza dalam ruang berat boleh menjana penyelesaian yang setara. Penyelesaian yang setara terletak di kawasan yang sama dengan penyelesaian asal, dengan penghalang kehilangan rendah (lembangan), dipanggil "Re-basin" [3]. Berbanding dengan sambungan corak, lembangan semula cenderung untuk mengangkut titik ke dalam lembangan melalui penjajaran dan bukannya terowong kehilangan rendah. Pada masa ini, penjajaran adalah kaedah perwakilan Re-basin [3, 178]. Walau bagaimanapun, cara mencari dengan cekap semua kemungkinan simetri pilih atur supaya semua penyelesaian menghala ke lembangan yang sama adalah cabaran semasa.
Gambar ialah gambarajah skematik [14] yang memperkenalkan neuron pertukaran titik sejajar. Kiri: Proses penjajaran am, model A diubah menjadi model Ap dengan merujuk kepada model B, dan kemudian gabungan linear Ap dan B menghasilkan C. Kanan: Laraskan vektor parameter θm dan θn bagi dua neuron dalam lapisan tersembunyi yang berbeza berhampiran dengan titik penjajaran Pada titik penjajaran [14] θ′m = θ′n, kedua-dua neuron mengira fungsi yang sama, yang bermaksud kedua-duanya. neuron Boleh ditukar.
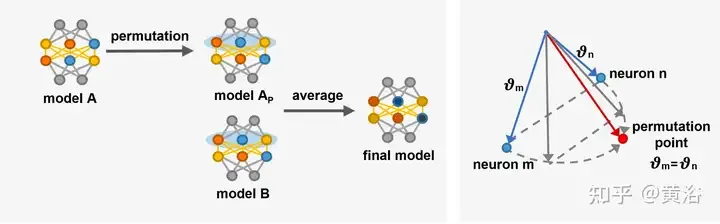
Penjajaran menjadikan model lebih serupa dengan melaraskan parameter model, yang boleh meningkatkan perkongsian maklumat antara model, dengan itu meningkatkan keupayaan generalisasi model gabungan. Selain itu, penjajaran membantu meningkatkan prestasi model dan keteguhan pada tugas yang kompleks. Walau bagaimanapun, kaedah penjajaran menghadapi masalah pengoptimuman gabungan yang perlahan. Penjajaran memerlukan overhed pengiraan tambahan untuk melaraskan parameter model, yang mungkin membawa kepada proses latihan yang lebih kompleks dan memakan masa, terutamanya dalam model kedalaman yang besar [142, 204].
Ringkasnya, penjajaran boleh meningkatkan ketekalan dan kesan keseluruhan antara model yang berbeza. Dengan kepelbagaian senario aplikasi DL, penjajaran akan menjadi salah satu kaedah utama untuk mengoptimumkan gabungan model yang mendalam dan meningkatkan keupayaan generalisasi. Pada masa hadapan, penjajaran boleh memainkan peranan dalam pembelajaran pemindahan, penyesuaian domain [63], penyulingan pengetahuan dan bidang lain. Sebagai contoh, penjajaran boleh mengurangkan perbezaan antara domain sumber dan sasaran dalam pembelajaran pemindahan dan meningkatkan pembelajaran domain baharu.
Disebabkan lebihan parameter rangkaian saraf yang tinggi, biasanya tiada korespondensi satu-dengan-satu antara berat rangkaian saraf yang berbeza. Oleh itu, purata wajaran (WA) biasanya tidak dijamin untuk berprestasi baik secara lalai. Purata biasa berprestasi buruk untuk rangkaian terlatih dengan perbezaan berat yang besar [204]. Dari perspektif statistik, WA membenarkan kawalan parameter model individu dalam model, dengan itu mengurangkan varians model akhir dan dengan itu mempunyai kesan yang boleh dipercayai pada sifat regularisasi dan hasil output [77, 166].
Jadual berikut ialah kaedah perwakilan WA:
Diinspirasikan oleh Fast Geometry Ensemble(FGE) [66] dan pusat pemeriksaan purata pembelajaran atau tempoh masa [149], [99]ikota yang berterusan kadar purata di atas berbilang titik trajektori SGD, yang dikenali sebagai purata berat stokastik (SWA). SWA menambah baik latihan pada pelbagai garis dasar yang penting, memberikan skalabilitas temporal yang lebih baik. Daripada melatih koleksi model (seperti gabungan biasa), SWA melatih satu model untuk mencari penyelesaian yang lebih lancar daripada SGD. Kaedah berkaitan SWA disenaraikan dalam jadual berikut. Tambahan pula, SWA boleh digunakan pada mana-mana seni bina atau set data dan menunjukkan prestasi yang lebih baik daripada Snapshot Ensemble(SSE) [91] dan FGE. Pada akhir setiap tempoh, model SWA dikemas kini dengan purata wajaran yang baru diperolehi dengan wajaran sedia ada.
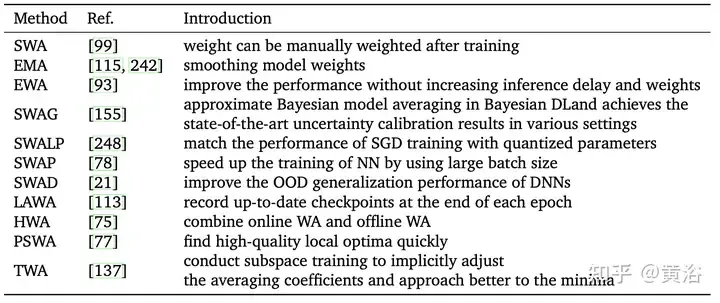
Walau bagaimanapun, SWA hanya boleh purata mata berhampiran titik optimum tempatan, dan akhirnya memperoleh nilai minimum relatif, tetapi tidak boleh menganggarkan nilai optimum dengan tepat. Di samping itu, disebabkan faktor tertentu (seperti penumpuan awal yang lemah, kadar pembelajaran yang tinggi, kadar perubahan berat yang cepat, dll.), sisihan sampel input akhir mungkin besar atau tidak mencukupi, mengakibatkan keputusan keseluruhan yang lemah. Kerja yang meluas cenderung untuk mengubah kaedah persampelan SWA.
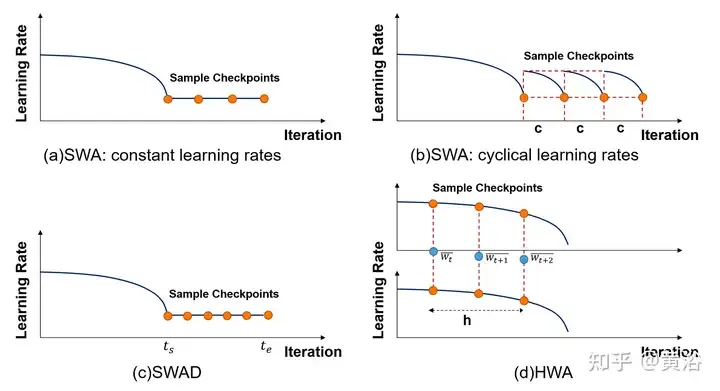
Seperti yang ditunjukkan dalam rajah, susunan persampelan dan kadar pembelajaran kaedah berkaitan SWA berbeza dibandingkan. (a) SWA: kadar pembelajaran berterusan. (b)SWA: Kadar pembelajaran berkala. (c)SWAD: persampelan padat. (d) HWA: Menggunakan WA dalam talian dan luar talian, pensampelan pada tempoh penyegerakan yang berbeza, panjang tetingkap gelongsor ialah h.
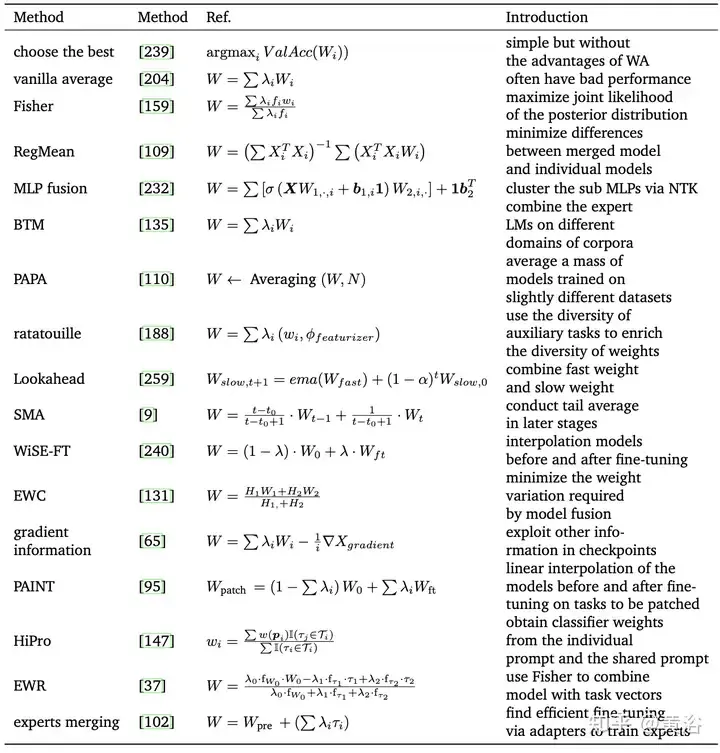
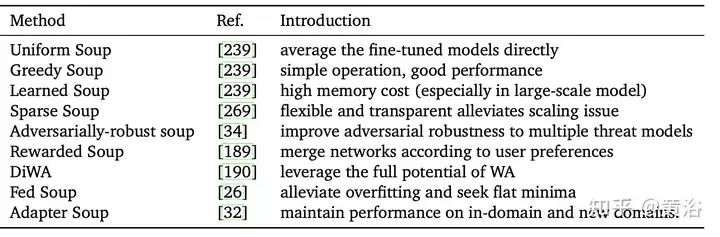
Sup model [239] merujuk kepada kaedah purata model yang diperhalusi dengan hiperparameter berbeza. Ia mudah tetapi berkesan, mencapai ketepatan 90.94% pada ImageNet-1K, mengatasi kerja sebelumnya pada CoAtNet-7 (90.88%) [38] dan ViT-G (90.45%) [255]. Jadual meringkaskan kaedah sup model yang berbeza.
Dalam pembelajaran berbilang tugas (MTL), model pra-latihan dan vektor tugasan (iaitu, τi = Wft − Wpre, perbezaan antara model pra-latihan dan model diperhalusi) digabungkan untuk memperoleh prestasi yang lebih baik pada semua tugasan. Berdasarkan pemerhatian ini, Aritmetik Tugasan[94] menambah baik prestasi model pada tugasan dengan memperhalusi vektor tugasan melalui penambahan dan gabungan linear, yang telah menjadi kaedah yang fleksibel dan cekap untuk mengedit model pra-latihan secara langsung, seperti yang ditunjukkan dalam rajah: Mengguna pakai tugas Aritmetik dan LoraHub (Hab penyesuaian peringkat rendah).
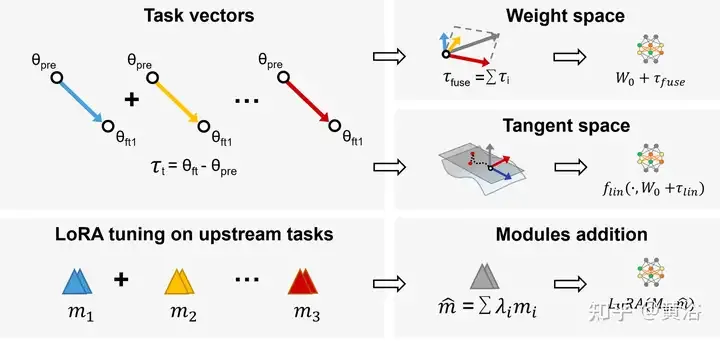
Selain itu, gabungan model dalam subruang mengehadkan trajektori latihan kepada subruang berdimensi rendah, yang boleh mengurangkan beban dan kesukaran.
WA memperoleh model akhir dengan membuat purata berat model kedalaman yang berbeza tanpa kerumitan pengiraan tambahan atau proses latihan [109, 159]. Secara umum, jika model rawak berbeza dengan ketara dalam keupayaan perwakilan, struktur, atau data latihan, hasil gabungan mungkin tidak mencapai prestasi yang diharapkan. Interpolasi linear model dari awal menggunakan konfigurasi hiperparameter yang sama tetapi dengan susunan data yang berbeza adalah kurang berkesan daripada model stokastik [59]. Oleh itu, sejumlah besar kaedah yang dicadangkan bertujuan untuk mengoptimumkan proses WA dalam cara matematik yang lain.
Selain itu, apabila model berkongsi sebahagian daripada trajektori pengoptimuman mereka (mis., purata pusat pemeriksaan, purata ekor, SWA [99, 149], dsb.) atau ditala halus pada model pra-latihan yang sama (cth., sup model [ 239], dsb. ), ketepatan model interpolasi menunjukkan prestasi yang lebih baik [167]. Tambahan pula, sup model [239] purata model dengan konfigurasi hiperparameter berbeza untuk mendapatkan hasil akhir. Selain itu, memilih pemberat yang sesuai dalam purata model juga boleh menjadi satu cabaran, yang selalunya penuh dengan subjektiviti. Mekanisme pemilihan berat yang lebih canggih mungkin memerlukan eksperimen dan pengesahan silang yang meluas dan kompleks.
WA ialah teknologi yang menjanjikan dalam pembelajaran mendalam Ia boleh digunakan sebagai teknologi pengoptimuman model pada masa hadapan untuk mengurangkan turun naik berat antara lelaran yang berbeza dan meningkatkan kestabilan dan kelajuan penumpuan. WA boleh meningkatkan peringkat pengagregatan pembelajaran bersekutu (FL) untuk melindungi privasi dengan lebih baik dan mengurangkan kos komunikasi masa hadapan. Di samping itu, dengan melaksanakan pemampatan rangkaian pada peranti akhir, ia dijangka mengurangkan ruang storan dan overhed pengiraan model pada peranti yang dikekang sumber [250]. Ringkasnya, WA ialah teknologi DL yang menjanjikan dan kos efektif yang boleh digunakan dalam bidang seperti FL untuk meningkatkan prestasi dan mengurangkan overhed storan.
Pembelajaran ensemble, atau sistem pengelas berbilang, ialah teknik yang menyepadukan berbilang model tunggal untuk menjana ramalan akhir, termasuk pengundian, purata [195], dsb. Ia meningkatkan prestasi keseluruhan dan mengurangkan varians model, menyelesaikan masalah seperti overfitting, ketidakstabilan dan volum data terhad.
Berdasarkan model sumber pra-latihan sedia ada, Penggunaan semula model[266] menyediakan model yang diperlukan untuk digunakan pada tugasan baharu tanpa perlu melatih semula model baharu dari awal. Ia menjimatkan masa dan sumber pengkomputeran dan memberikan prestasi yang lebih baik di bawah keadaan sumber yang terhad [249]. Di samping itu, memandangkan fokus pembelajaran pemindahan adalah untuk menyelesaikan tugas ramalan pada domain sasaran, penggunaan semula model boleh dianggap sebagai sejenis pembelajaran pemindahan. Walau bagaimanapun, pembelajaran pemindahan memerlukan data berlabel daripada domain sumber dan domain sasaran, manakala dalam penggunaan semula model, hanya data tidak berlabel boleh dikumpul, tetapi data daripada domain sumber tidak boleh digunakan [153].
Tidak seperti pembelajaran ensembel berbilang pengelas, kebanyakan kaedah semasa menggunakan semula ciri, label atau modaliti sedia ada untuk mendapatkan ramalan akhir [176, 266] tanpa menyimpan sejumlah besar data latihan [245]. Satu lagi cabaran utama dalam penggunaan semula model ialah mengenal pasti model yang berguna daripada set model pra-latihan untuk tugas pembelajaran yang diberikan.
Menggunakan model tunggal untuk penggunaan semula model menghasilkan terlalu banyak maklumat homogen (cth., model yang dilatih dalam satu domain mungkin tidak sesuai dengan data domain lain), dan sukar untuk mencari satu model pra-latihan yang sesuai sepenuhnya untuk domain sasaran. Secara umum, menggunakan set model yang serupa untuk menghasilkan prestasi yang lebih baik daripada model tunggal diwakili sebagai Multiple Model Reuse (MMR)[153].
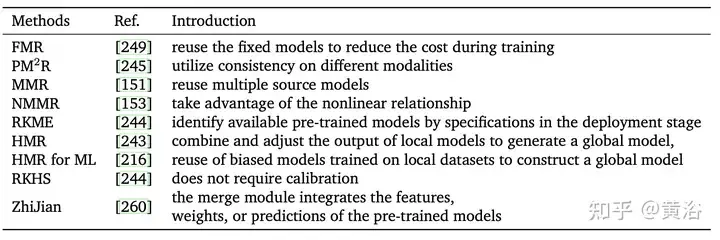
Jadual berikut membandingkan ciri kaedah penggunaan semula yang berbeza Secara ringkasnya, penggunaan semula model boleh mengurangkan jumlah data yang diperlukan untuk menggunakan model pra-latihan dan menyelesaikan masalah penggunaan lebar jalur yang besar apabila menghantar data antara hujung yang berbeza. Penggunaan semula berbilang model juga mempunyai pelbagai aplikasi, seperti pengecaman pertuturan, sistem interaktif selamat dan peribadi, retina digital [64], dsb.
Berbanding dengan algoritma gabungan model yang berkaitan seperti pembelajaran bersekutu [88, 89, 160] yang mempunyai keperluan tertentu pada parameter dan skala model, kaedah pembelajaran ensemblemenggunakan ramalan untuk menggabungkan pelbagai pengelas lemah heterogen, dan terdapat tiada had sedemikian. Di samping itu, rangkaian dengan seni bina yang berbeza dalam kaedah penyepaduan akan mempunyai kesan perbandingan yang lebih jelas daripada WA. Walau bagaimanapun, pendekatan ensemble memerlukan mengekalkan dan menjalankan berbilang model terlatih dan menjalankannya bersama-sama pada masa ujian. Memandangkan saiz dan kerumitan model pembelajaran mendalam, pendekatan ini tidak sesuai untuk aplikasi dengan sumber dan kos pengkomputeran yang terhad [204].
Disebabkan kepelbagaian rangka kerja pembelajaran ensemble, kepelbagaian model boleh dicapai dan keupayaan generalisasi boleh dipertingkatkan. Pada masa hadapan, ini akan menjadi penting untuk mengendalikan perubahan data dan serangan musuh. Pembelajaran ensemble dalam pembelajaran mendalam dijangka memberikan anggaran keyakinan dan langkah ketidakpastian untuk ramalan model, yang penting untuk keselamatan dan kebolehpercayaan sistem sokongan keputusan, pemanduan autonomi [74], diagnosis perubatan, dsb.
Dalam beberapa tahun kebelakangan ini, sejumlah besar penyelidikan baharu telah muncul dalam bidang gabungan model mendalam, yang turut menggalakkan pembangunan bidang aplikasi yang berkaitan.
Pembelajaran Bersekutu
Untuk menangani cabaran keselamatan dan pemusatan penyimpanan data, Pembelajaran Bersekutu (FL) [160, 170] membenarkan banyak model yang mengambil bahagian untuk melatih model global yang dikongsi secara kolaboratif sambil melindungi privasi data tanpa memerlukan pengumpulan dipusatkan pada pelayan pusat. Ia juga boleh dilihat sebagai masalah pembelajaran pelbagai pihak [177]. Khususnya, agregasi ialah proses penting FL, yang mengandungi kemas kini model atau parameter yang dilatih oleh pelbagai pihak (seperti peranti, organisasi atau individu). Angka tersebut menunjukkan dua kaedah pengagregatan berbeza dalam FL terpusat dan terdesentralisasi. , Kiri: Pembelajaran bersekutu berpusat antara pelayan pusat dan terminal pelanggan, memindahkan model atau kecerunan dan akhirnya mengagregatkan pada pelayan. Kanan: Pemindahan pembelajaran bersekutu terdesentralisasi dan model agregat antara terminal pelanggan tanpa memerlukan pelayan pusat.
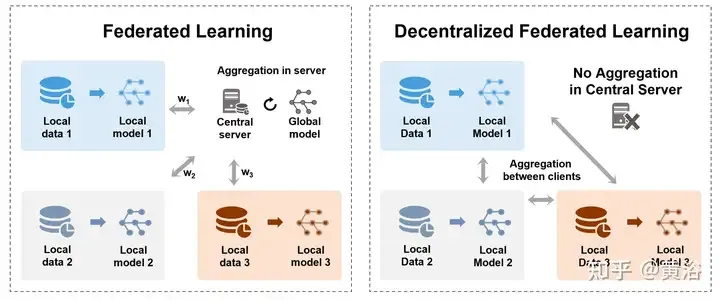
Jadual berikut menunjukkan kaedah pengagregatan berbeza bagi pembelajaran bersekutu:
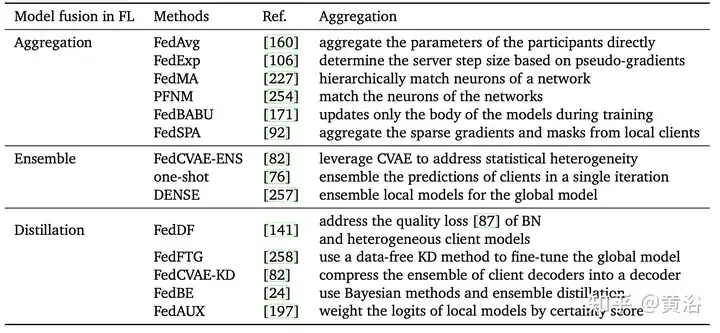
Ringkasnya, intipati langkah pengagregatan dalam FL ialah teknik gabungan model. Memilih kaedah gabungan model yang munasabah boleh mengurangkan kesan peserta tertentu atau data individu pada model akhir, dengan itu meningkatkan keupayaan generalisasi model dan kebolehsuaian dalam skop global. Kaedah pengagregatan yang baik diharapkan dapat membantu menangani pelbagai cabaran dalam pembelajaran bersekutu pada masa hadapan. Kaedah pengagregatan berkualiti tinggi dan berskala dijangka menghadapi satu siri cabaran FL, seperti heterogeniti pelanggan, data heterogen bukan IID, sumber pengkomputeran terhad [141], dsb. FL dijangka menunjukkan potensinya dalam lebih banyak bidang, seperti pemprosesan bahasa semula jadi, sistem pengesyoran [146], analisis imej perubatan [144], dsb.
Penalaan halus
Penalaan halus ialah corak asas (seperti model pra-latihan) dan merupakan cara yang berkesan untuk menala model untuk melaksanakan tugas hiliran [23, 41], yang boleh mencapai generalisasi yang lebih baik menggunakan data yang kurang berlabel dan Output yang lebih tepat. Model pralatihan dilatih dengan set data yang agak khusus tugas, yang sentiasa menjadi titik permulaan yang lebih baik untuk kriteria latihan daripada pemulaan rawak. walaupun. Secara purata, model diperhalusi sedia ada [28, 29] adalah model asas yang lebih baik daripada model pra-latihan biasa untuk menala halus tugas hiliran.
Selain itu, terdapat banyak karya terbaru yang menggabungkan WA dengan penalaan halus, seperti yang ditunjukkan dalam rajah, seperti sup model [239], DiWA [190], dll. Penalaan halus meningkatkan ketepatan pengedaran sasaran, tetapi selalunya mengakibatkan pengurangan keteguhan kepada perubahan pengedaran. Strategi untuk purata model yang ditala halus mungkin mudah, tetapi mereka tidak mengeksploitasi sepenuhnya hubungan antara setiap model yang ditala halus. Oleh itu, latihan mengenai tugas pertengahan sebelum latihan mengenai tugas sasaran boleh meneroka keupayaan model asas [180, 185, 224]. Diilhamkan oleh strategi latihan bersama [185], [188] memperhalusi model untuk tugas tambahan untuk mengeksploitasi tugas bantu yang berbeza dan meningkatkan keupayaan generalisasi luar pengedaran (OOD).
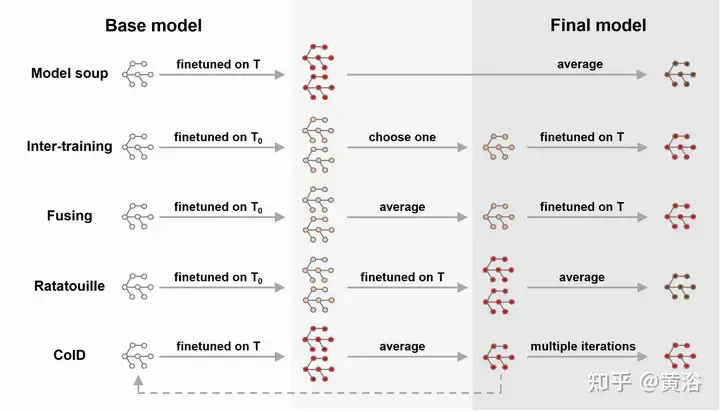
Menala halus min model mengurangkan masa latihan yang diperlukan untuk mencapai matlamat [28] dan menghasilkan model umum yang lebih tepat dan lebih baik. Pada asasnya, kaedah penalaan halus yang berbeza (contohnya, penalaan halus lapisan beku, penalaan halus peringkat atas, dll.) juga akan memberi kesan tertentu pada ketepatan akhir dan anjakan pengedaran [240]. Walau bagaimanapun, gabungan WA dan penalaan halus adalah mahal dan mempunyai had tertentu pada aplikasi tertentu. Tambahan pula, ia mungkin menghadapi masalah letupan pusat pemeriksaan yang disimpan atau pelupaan bencana [121], terutamanya apabila digunakan untuk pemindahan pembelajaran.
Penyulingan Pengetahuan
Penyulingan Pengetahuan (KD) [83] ialah kaedah penting untuk menyepadukan berbilang model, yang melibatkan dua jenis model berikut. Model guru merujuk kepada model besar dan berkuasa yang dilatih pada data berskala besar, dengan keupayaan ramalan dan ekspresif yang tinggi. Model pelajar ialah model yang agak kecil dengan parameter dan sumber pengiraan yang lebih sedikit [18, 199]. Menggunakan pengetahuan guru (seperti taburan kebarangkalian keluaran, perwakilan lapisan tersembunyi, dll.) untuk membimbing latihan, pelajar boleh mencapai keupayaan ramalan hampir dengan model besar dengan sumber yang lebih sedikit dan kelajuan yang lebih pantas [2, 119, 124, 221]. Memandangkan berbilang guru atau pelajar dijangka berprestasi lebih baik daripada model tunggal [6], KD dibahagikan kepada dua kategori berdasarkan objektif pengagregatan, seperti yang ditunjukkan dalam rajah.
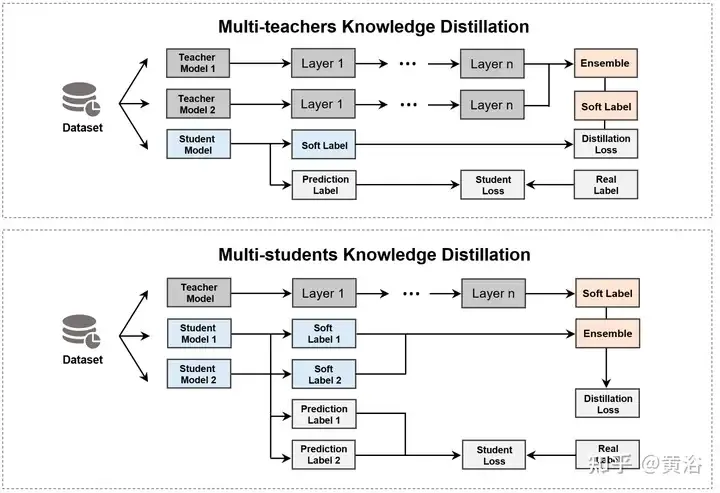
Jenis kaedah pertama ialah menggabungkan berbilang model guru dan mengekstrak terus model pelajar, seperti yang ditunjukkan dalam jadual. Pada masa ini, kerja baru-baru ini terutamanya mengintegrasikan output guru (cth., logit [6, 49, 252] atau pengetahuan asas ciri [143, 241], dsb.).

Pendekatan lain ialah menggunakan model guru untuk mengekstrak berbilang pelajar dan kemudian menggabungkan model pelajar ini. Walau bagaimanapun, penggabungan berbilang pelajar juga mempunyai beberapa masalah, seperti keperluan sumber pengiraan yang tinggi, kebolehtafsiran yang lemah dan terlalu bergantung pada model asal.
Model gabungan model asas/LLM
Model asas menunjukkan prestasi yang kukuh dan keupayaan yang muncul apabila menangani tugas yang rumit Model asas yang besar dicirikan oleh skala besarnya, yang mengandungi berbilion parameter, membantu mempelajari corak kompleks data dalam . Terutamanya, dengan kemunculan LLM baharu [200, 264] baharu, seperti GPT-3 [17, 172], T5 [187], BERT [41], Megatron-LM, aplikasi WA [154, 212, 256 ] ] LLM menarik lebih perhatian.
Selain itu, karya terbaharu [120, 256] cenderung untuk mereka bentuk rangka kerja dan modul yang lebih baik untuk disesuaikan dengan penggunaan LLM. Disebabkan oleh prestasi tinggi dan sumber pengiraan yang rendah, penalaan halus model asas yang besar boleh meningkatkan keteguhan kepada perubahan pengedaran [240].
Atas ialah kandungan terperinci Semakan! Gabungan model mendalam (LLM/model asas/pembelajaran bersekutu/penalaan halus, dsb.). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!