
Rumah >Peranti teknologi >AI >ReFT (Representation Fine-tuning): teknologi penalaan halus model bahasa besar baharu yang lebih baik daripada PeFT
ReFT (Representation Fine-tuning): teknologi penalaan halus model bahasa besar baharu yang lebih baik daripada PeFT

- WBOYke hadapan
- 2024-04-15 15:30:021312semak imbas
ReFT (Representation Finetuning) ialah kaedah terobosan yang menjanjikan untuk mentakrifkan semula cara kami memperhalusi model bahasa besar.
Penyelidik dari Universiti Stanford baru-baru ini (April) menerbitkan kertas kerja mengenai arxiv, ReFT sangat berbeza daripada kaedah penalaan halus berasaskan berat tradisional, dan ia menyediakan kaedah yang lebih cekap dan berkesan untuk menyesuaikan diri dengan model berskala besar ini untuk menyesuaikan diri dengan tugas dan domain baharu!

Sebelum memperkenalkan kertas kerja ini, mari kita lihat PeFT.
PeFT Penalaan Halus Cekap Parameter
Petala Halus Cekap Parameter (PEFT) ialah kaedah penalaan halus yang cekap untuk memperhalusi nombor kecil atau parameter model tambahan. Berbanding dengan kaedah penalaan halus rangkaian ramalan tradisional, menggunakan PEFT untuk penalaan halus boleh mengurangkan kos pengkomputeran dan penyimpanan dengan ketara, sambil memastikan prestasi setanding dengan penalaan halus penuh. Teknologi ini mempunyai pelbagai aplikasi dan boleh mencapai prestasi yang setanding dengan pemangkasan penuh.
Berdasarkan idea PeFT, LoRA yang sangat kami kenali telah dihasilkan, dan terdapat pelbagai varian LoRA Selain LoRA yang terkenal, kaedah PeFT yang biasa digunakan termasuk:
. Penalaan Awalan: melalui Token maya membina gesaan tersirat berterusan, iaitu kaedah yang dikeluarkan oleh Stanford pada 2021.
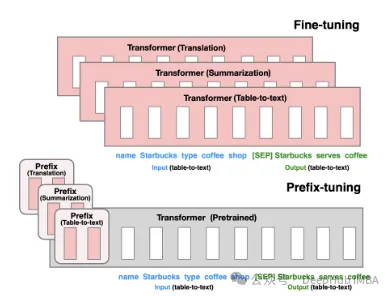
P-Tuning V1/V2 ialah teknologi yang dicadangkan oleh Universiti Tsinghua pada 2021, bertujuan untuk menukar model diskret bahasa semula jadi kepada gesaan tersirat yang boleh dilatih (masalah pengoptimuman parameter berterusan). Versi V2 meningkatkan lagi prestasi versi V1 dengan menambahkan parameter boleh tala halus pada setiap lapisan sebelum input. Kaedah ini meluaskan skop aplikasi dan fleksibiliti model dengan berkesan.
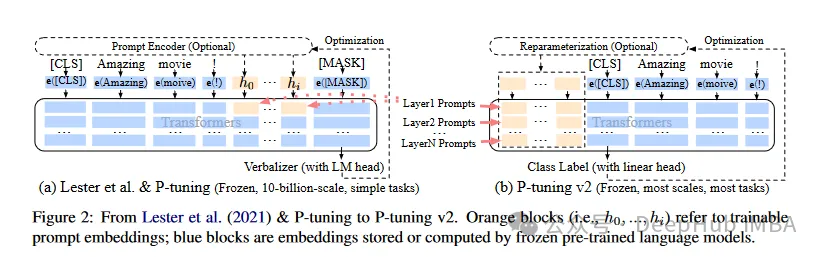
Kemudian ada LoRA, yang kita kenal dan paling lama saya tidak akan memperkenalkannya secara terperinci di sini. yang boleh menjadi lebih baik untuk ReFT yang kami perkenalkan di bawah. .
 Tidak seperti kaedah penalaan halus tradisional yang mengemas kini keseluruhan set parameter model, ReFT beroperasi dengan memanipulasi bahagian kecil perwakilan model secara strategik, membimbing tingkah lakunya untuk menyelesaikan tugas hiliran dengan lebih cekap.
Tidak seperti kaedah penalaan halus tradisional yang mengemas kini keseluruhan set parameter model, ReFT beroperasi dengan memanipulasi bahagian kecil perwakilan model secara strategik, membimbing tingkah lakunya untuk menyelesaikan tugas hiliran dengan lebih cekap.
Idea teras di sebalik ReFT diilhamkan oleh penyelidikan terkini tentang kebolehtafsiran model bahasa: maklumat semantik yang kaya dikodkan dalam perwakilan yang dipelajari oleh model ini. Dengan campur tangan dalam perwakilan ini, ReFT bertujuan untuk membuka kunci dan mengeksploitasi pengetahuan yang dikodkan ini, membolehkan penyesuaian model yang lebih cekap dan berkesan.
Kelebihan utama ReFT ialah kecekapan parameternya: kaedah penalaan halus tradisional memerlukan pengemaskinian sebahagian besar parameter model, yang boleh mahal dari segi pengiraan dan intensif sumber, terutamanya untuk model bahasa besar dengan berbilion parameter . Kaedah ReFT biasanya memerlukan susunan latihan dengan parameter yang lebih sedikit, menghasilkan masa latihan yang lebih cepat dan kurang keperluan memori.
Cara ReFT berbeza dengan PeFT
ReFT berbeza daripada kaedah PEFT tradisional dalam beberapa aspek utama:
1 Sasaran Intervensi
. yang memberi tumpuan kepada mengubah suai pemberat model atau memperkenalkan matriks berat tambahan. Kaedah ReFT tidak mengubah suai pemberat model secara langsung; ia mengganggu perwakilan tersembunyi yang dikira oleh model semasa hantaran hadapan.
2. Mekanisme penyesuaian
Kaedah PEFT seperti LoRA dan DoRA mempelajari kemas kini berat atau anggaran peringkat rendah bagi matriks berat model. Kemas kini berat ini kemudiannya dimasukkan ke dalam pemberat model asas semasa inferens, menyebabkan tiada overhed pengiraan tambahan. Kaedah ReFT belajar untuk campur tangan, memanipulasi perwakilan model pada lapisan dan lokasi tertentu semasa inferens. Proses campur tangan ini memerlukan beberapa overhed pengiraan tetapi membolehkan penyesuaian yang lebih cekap.
3. Motivasi
Motivasi utama kaedah PEFT ialah keperluan untuk penyesuaian parameter yang berkesan, yang mengurangkan kos pengiraan dan keperluan memori untuk menala model bahasa besar. Kaedah ReFT, sebaliknya, diilhamkan oleh penyelidikan terkini tentang kebolehtafsiran model bahasa, yang menunjukkan bahawa maklumat semantik yang kaya dikodkan dalam perwakilan yang dipelajari oleh model ini. Matlamat ReFT adalah untuk memanfaatkan dan mengeksploitasi pengetahuan yang dikodkan ini agar sesuai dengan model dengan lebih cekap.
4. Kecekapan parameter
Kedua-dua kaedah PEFT dan ReFT direka untuk kecekapan parameter, tetapi kaedah ReFT telah terbukti kecekapan parameter yang lebih tinggi dalam amalan. Sebagai contoh, kaedah LoReFT (ReFT subruang linear peringkat rendah) biasanya memerlukan 10-50 kali lebih sedikit parameter untuk dilatih daripada kaedah PEFT (LoRA) yang terkini, sambil mencapai prestasi kompetitif atau lebih baik pada pelbagai penanda aras NLP.
5. Kebolehtafsiran
Walaupun kaedah PEFT tertumpu terutamanya pada penyesuaian yang cekap, kaedah ReFT memberikan kelebihan tambahan dari segi kebolehtafsiran. Dengan campur tangan dalam perwakilan yang diketahui mengekod maklumat semantik tertentu, kaedah ReFT boleh memberikan cerapan tentang cara model bahasa memproses dan memahami bahasa, yang berpotensi membawa kepada sistem kecerdasan buatan yang lebih telus dan boleh dipercayai.
ReFT Architecture
Seni bina model ReFT mentakrifkan konsep umum campur tangan, yang pada asasnya bermaksud pengubahsuaian perwakilan tersembunyi semasa lulus hadapan model. Kami mula-mula mempertimbangkan model bahasa berasaskan pengubah yang menjana perwakilan kontekstual bagi jujukan token.
Memandangkan jujukan n token input x = (x₁,…,xn), model mula-mula membenamkannya ke dalam senarai perwakilan, dari segi h₁,…,hn. Kemudian lapisan m secara berterusan mengira perwakilan tersembunyi jth Setiap perwakilan tersembunyi ialah vektor h∈λ, dengan d ialah dimensi perwakilan.
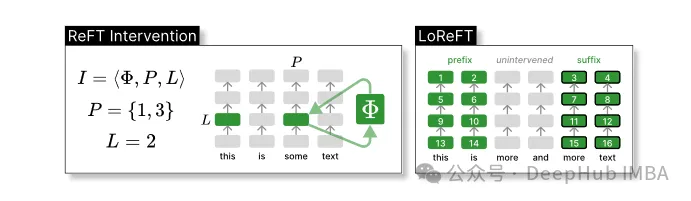
ReFT mentakrifkan konsep campur tangan yang mengubah suai perwakilan tersembunyi semasa hantaran hadapan model.
Intervensi I ialah tuple ⟨Φ, P, L , yang merangkumi tindakan campur tangan bagi masa inferens tunggal yang diwakili oleh pengiraan LM berasaskan pengubah Fungsi ini mengandungi tiga parameter:
Intervensi: mewakili fungsi. oleh parameter yang dipelajari Φ (Φ).
Set kedudukan input P≤{1,…,n} yang mana intervensi digunakan.
Campur tangan pada lapisan L∈{1,…,m}.
Kemudian, tindakan intervensi adalah seperti berikut:
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}Intervensi ini dilakukan sejurus selepas pengiraan perambatan hadapan selesai, jadi ia akan menjejaskan perwakilan yang dikira dalam lapisan seterusnya.
Untuk meningkatkan kecekapan pengiraan, pemberat intervensi juga boleh diuraikan kepada peringkat rendah, iaitu untuk mendapatkan subruang linear peringkat rendah ReFT (LoReFT).
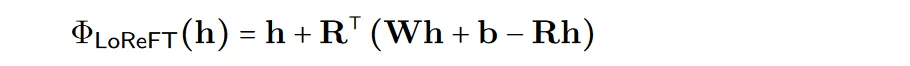
Gunakan sumber unjuran yang dipelajari Rs = Wh +b dalam formula di atas. LoReFT menyunting perwakilan dalam subruang R-dimensi lajur R untuk mengambil nilai yang diperoleh daripada unjuran linear Wh + b kami.
Untuk tugas penjanaan, kertas ReFT menggunakan objektif latihan pemodelan bahasa, memfokuskan pada meminimumkan kehilangan entropi silang merentas semua kedudukan output.
contoh kod perpustakaan pyreft
Bersama dengan kertas kerja mereka, penyelidik Universiti Stanford turut mengeluarkan perpustakaan pyreft, perpustakaan yang dibina di atas pyvene untuk melaksanakan dan melatih campur tangan pengaktifan pada model PyTorch sewenang-wenangnya.
pyreft serasi dengan mana-mana model bahasa pra-latihan yang tersedia pada HuggingFace dan boleh diperhalusi menggunakan kaedah ReFT. Berikut ialah contoh kod cara melakukan satu intervensi pada keluaran lapisan ke-19 model lama-27b:
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()Kod yang selebihnya tidak berbeza daripada model latihan HuggingFace Mari buat demonstrasi lengkap:
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
Setelah latihan selesai, anda boleh menyemak maklumat model:
prompt = tokenizer("GO->", return_tensors="pt").to("cuda") base_unit_location = prompt["input_ids"].shape[-1] - 1# last position _, reft_response = reft_model.generate( prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True))Ujian prestasi LoReFT
Akhirnya mari kita lihat prestasi cemerlangnya dalam pelbagai penanda aras NLP Berikut adalah data yang ditunjukkan oleh penyelidik dari Universiti Stanford.
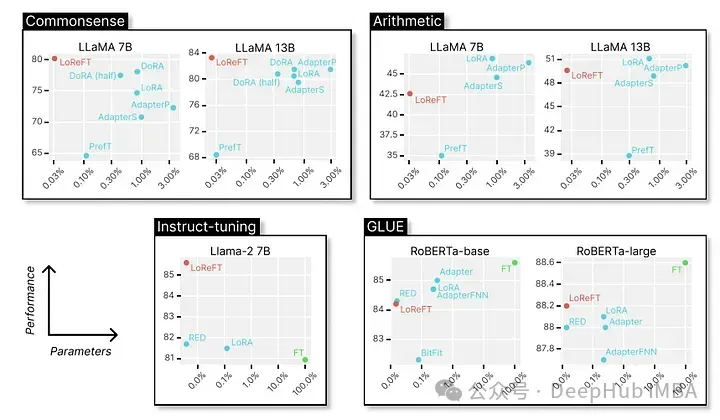
LoReFT mencapai prestasi terkini pada 8 set data yang mencabar, termasuk BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c dan OBQA. Walaupun menggunakan parameter yang jauh lebih sedikit daripada kaedah PEFT sedia ada (10-50x lebih sedikit), LoReFT dengan ketara mengatasi semua kaedah lain, menunjukkan keberkesanannya dalam menangkap dan memanfaatkan pengetahuan akal yang dikodkan dalam kebolehan bahasa yang besar.
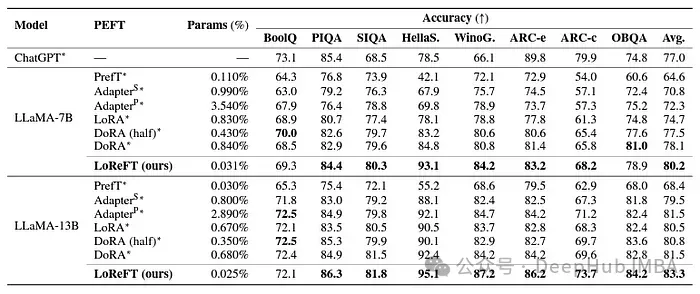
Walaupun LoReFT tidak mengatasi kaedah PEFT sedia ada pada tugasan penaakulan matematik, ia menunjukkan prestasi kompetitif pada set data seperti AQuA, GSM8K, MAWPS dan SVAMP. Para penyelidik mendapati bahawa prestasi LoReFT bertambah baik dengan saiz model, menunjukkan bahawa keupayaannya berkembang apabila model bahasa terus berkembang.
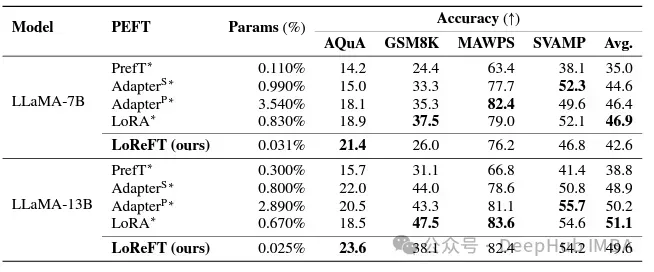
Dalam bidang pematuhan arahan, LoReFT telah mencapai hasil yang luar biasa, mengatasi semua kaedah penalaan halus, termasuk penalaan halus lengkap, pada penanda aras Alpaca-Eval v1.0 (ini harus diperhatikan). Apabila dilatih pada model llama-27b, LoReFT adalah 1% lebih baik daripada model GPT-3.5 Turbo, sambil menggunakan parameter yang jauh lebih sedikit daripada kaedah PEFT yang lain.
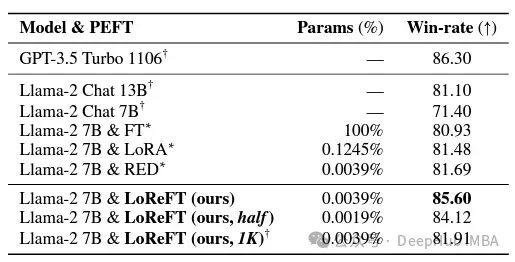
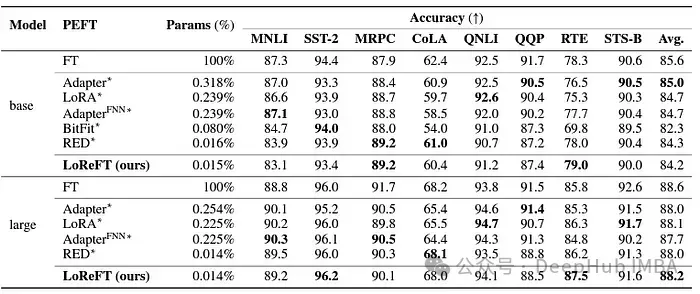
LoReFT juga menunjukkan keupayaannya dalam tugas pemahaman bahasa semula jadi, mencapai prestasi yang setanding dengan kaedah PEFT sedia ada pada penanda aras GLUE apabila digunakan pada model RoBERTa-base dan RoBERTa-besar.
Apabila memadankan kaedah PEFT yang paling berkesan sebelum ini dalam bilangan parameter, LoReFT mencapai markah yang sama merentas pelbagai tugas, termasuk analisis sentimen dan penaakulan bahasa semula jadi.
Ringkasan
Kejayaan ReFT, terutamanya LoReFT, sangat penting kepada masa depan pemprosesan bahasa semula jadi dan aplikasi praktikal model bahasa besar. Kecekapan parameter ReFT menjadikannya penyelesaian yang berkesan untuk menyesuaikan model bahasa yang besar kepada tugas atau domain tertentu sambil meminimumkan sumber pengiraan dan masa latihan.
Dan ReFT juga menyediakan perspektif unik untuk meningkatkan kebolehtafsiran model bahasa besar. Kejayaan dalam tugas seperti penaakulan akal, penaakulan aritmetik, dan arahan mengikut menunjukkan keberkesanan pendekatan ini. Pada masa ini, ReFT dijangka membuka kemungkinan baharu dan mengatasi batasan kaedah penalaan tradisional.
Atas ialah kandungan terperinci ReFT (Representation Fine-tuning): teknologi penalaan halus model bahasa besar baharu yang lebih baik daripada PeFT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Kecerdasan buatan am, persepsi kecerdasan buatan dan model bahasa besar
- AMD melancarkan GPU Instinct MI300X: Direka untuk model bahasa besar dan pengkomputeran AI
- Kunlun Wanwei melancarkan Tiangong AI Search: alat carian AI domestik pertama yang menyepadukan model bahasa berskala besar
- Microsoft memperkenalkan model 2.7 bilion parameter Phi-2, yang mengatasi banyak model bahasa besar
- Perbezaan antara model bahasa besar dan model pembenaman perkataan