
Rumah >Peranti teknologi >AI >Siapa kata gajah tidak boleh menari!
Siapa kata gajah tidak boleh menari!

- 王林ke hadapan
- 2024-04-15 15:20:02856semak imbas
Baru-baru ini, penyelidik dari Universiti Monash Australia, Ant Group, IBM Research dan institusi lain telah meneroka aplikasi pengaturcaraan semula model pada model bahasa besar (LLM), dan mencadangkan perspektif baharu: pemprograman semula yang cekap Memprogramkan model bahasa besar untuk ramalan siri masa umum sistem, rangka kerja Time-LLM. Rangka kerja ini boleh mencapai ramalan berketepatan tinggi dan cekap tanpa mengubahsuai model bahasa Ia boleh mengatasi model siri masa tradisional dalam berbilang set data dan tugas ramalan, membolehkan LLM menunjukkan prestasi cemerlang semasa memproses data siri masa silang .

Baru-baru ini, pembangunan model bahasa besar dalam bidang kecerdasan am, hala tuju baharu "model besar + siri masa/data masa" telah menunjukkan banyak kemajuan berkaitan. LLM semasa mempunyai potensi untuk merevolusikan kaedah perlombongan data siri masa/sementara, dengan itu mempromosikan pembuatan keputusan yang cekap dalam sistem kompleks klasik seperti bandar, tenaga, pengangkutan, kesihatan, dll., dan bergerak ke arah bentuk analisis masa/ruang yang lebih pintar sejagat .
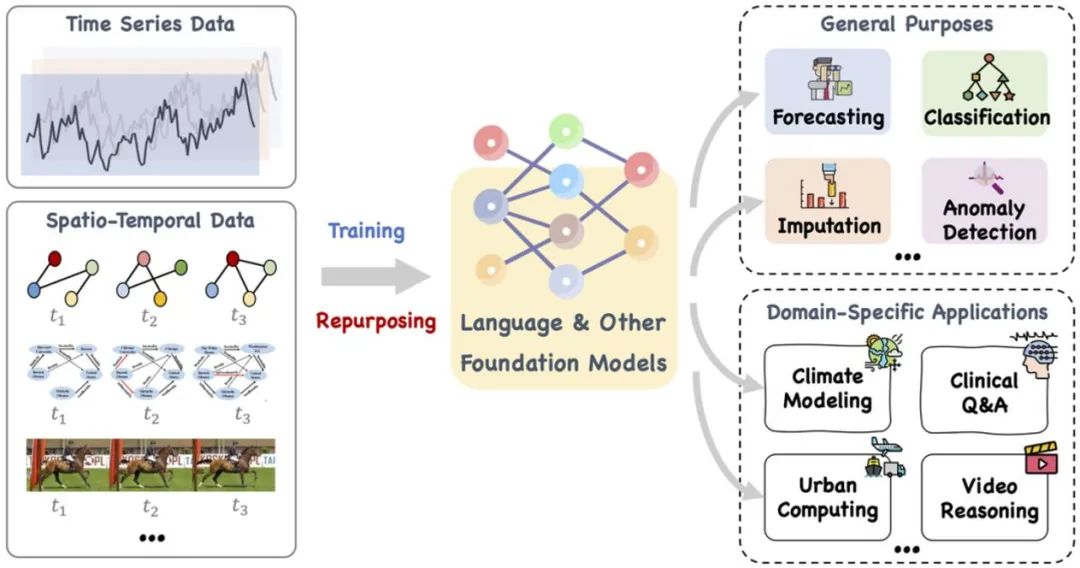
Makalah ini mencadangkan model asas yang besar, seperti bahasa dan model lain yang berkaitan, yang boleh dilatih dan direka semula dengan bijak untuk mengendalikan pelbagai tugas tujuan am dan aplikasi domain khusus masa Data spatial berurutan dan temporal . Rujukan: https://arxiv.org/pdf/2310.10196.pdf.
Penyelidikan terkini telah mengembangkan model bahasa berskala besar daripada memproses bahasa semula jadi kepada siri masa dan tugasan spatio-temporal. Hala tuju penyelidikan baharu ini, iaitu "model besar + data siri masa/spatiotemporal", telah menghasilkan banyak perkembangan berkaitan, seperti LLMTime, yang secara langsung menggunakan LLM untuk inferens ramalan siri masa tangkapan sifar. Walaupun LLM mempunyai keupayaan pembelajaran dan ekspresi yang berkuasa dan boleh menangkap corak kompleks dan kebergantungan jangka panjang dalam data jujukan teks secara berkesan, sebagai "kotak hitam" yang memfokuskan pada pemprosesan bahasa semula jadi, aplikasi LLM dalam siri masa dan tugasan spatiotemporal masih menghadapi masalah. cabaran. Berbanding dengan model siri masa tradisional seperti TimesNet, TimeMixer, dll., LLM adalah setanding dengan "gajah" kerana parameter dan skalanya yang besar.
Apa yang anda tanyakan ialah cara "menjinakkan" model bahasa besar (LLM) yang terlatih dalam bidang bahasa semula jadi supaya mereka boleh memproses data urutan berangka merentas corak teks dan menggunakan penaakulan yang kuat dalam siri masa dan keupayaan Ramalan telah menjadi tumpuan utama penyelidikan semasa. Untuk tujuan ini, analisis teori yang lebih mendalam diperlukan untuk meneroka persamaan pola yang berpotensi antara data linguistik dan temporal dan menggunakannya secara berkesan pada siri masa dan tugasan spatiotemporal tertentu.
LLM Reprogramming ialah teknologi ramalan siri masa umum. Ia mencadangkan dua teknologi utama, iaitu (1) pengaturcaraan semula input temporal dan (2) pra-pengaturcaraan segera, yang menukar tugas ramalan temporal kepada tugas "bahasa" yang boleh diselesaikan dengan berkesan oleh LLM, berjaya mengaktifkan model bahasa besar untuk mencapai tahap tinggi. prestasi. Keupayaan untuk melakukan penaakulan masa yang tepat.

Alamat kertas: https://openreview.net/pdf?id=Unb5CVPtae
Kod kertas: https://github.com/KimMeen/Time-LLM
Latar belakang masalah
1 Data disimpan secara meluas dalam realiti, di mana ramalan masa adalah sangat penting dalam banyak sistem dinamik dunia sebenar dan telah dikaji secara meluas. Tidak seperti pemprosesan bahasa semula jadi (NLP) dan penglihatan komputer (CV), di mana satu model besar boleh mengendalikan berbilang tugas, model ramalan siri masa selalunya perlu direka khas untuk memenuhi keperluan tugasan dan senario aplikasi yang berbeza. Penyelidikan baru-baru ini telah menunjukkan bahawa model bahasa besar (LLM) juga boleh dipercayai apabila memproses urutan temporal yang kompleks. Masih menjadi cabaran untuk menggunakan keupayaan penaakulan model bahasa besar sendiri untuk mengendalikan tugasan analisis temporal. . pada model bahasa besar itu sendiri. Masa-LLM mula-mula menggunakan prototaip teks (Prototaip Teks) untuk memprogram semula data siri masa input, dan menggunakan perwakilan bahasa semula jadi untuk mewakili maklumat semantik data siri masa, dengan itu menjajarkan dua modaliti data yang berbeza, supaya model bahasa besar tidak memerlukan sebarang pengubahsuaian Anda boleh memahami maklumat di sebalik modaliti data yang lain.
Untuk meningkatkan lagi pemahaman LLM tentang input data siri masa dan tugasan yang sepadan, penulis mencadangkan paradigma Prompt-as-Prefix (PaP), yang mengaktifkan sepenuhnya paradigma prompt-as-prefix (PaP) dengan menambahkan gesaan kontekstual tambahan dan arahan tugasan sebelum perwakilan data siri masa keupayaan pemprosesan LLM pada tugasan berurutan. Dalam kerja ini, pengarang menjalankan eksperimen yang mencukupi pada set data penanda aras siri masa arus perdana, dan keputusan menunjukkan bahawa Time-LLM boleh mengatasi model siri masa tradisional dalam kebanyakan kes dan mencapai prestasi yang lebih baik dalam sampel beberapa syot dan sifar sampel (sifar pukulan) tugasan pembelajaran telah bertambah baik.
Sumbangan utama dalam karya ini boleh diringkaskan seperti berikut:
1. Kerja ini mencadangkan konsep baharu pemprograman semula model bahasa besar untuk analisis masa tanpa sebarang pengubahsuaian kepada model bahasa tulang belakang. Pengarang menunjukkan bahawa ramalan siri masa boleh dianggap sebagai satu lagi tugas "linguistik" yang boleh diselesaikan dengan berkesan oleh LLM luar biasa.
2 Kerja ini mencadangkan rangka kerja pengaturcaraan semula model bahasa umum, iaitu Time-LLM, yang terdiri daripada pengaturcaraan semula data temporal input ke dalam perwakilan prototaip teks yang lebih semula jadi dan mengintegrasikannya dengan isyarat deklaratif seperti pengetahuan pakar domain dan penerangan tugas) untuk meningkatkan. konteks input untuk membimbing LLM untuk penaakulan merentas domain yang berkesan. Teknologi ini menyediakan asas yang kukuh untuk pembangunan model asas pemasaan multimodal.
3 Time-LLM secara konsisten mengatasi prestasi model sedia ada terbaik dalam tugas ramalan arus perdana, terutamanya dalam senario beberapa sampel dan sifar. Tambahan pula, Time-LLM mampu mencapai prestasi yang lebih tinggi sambil mengekalkan kecekapan pengaturcaraan semula model yang cemerlang. Buka kunci potensi LLM yang belum diterokai secara dramatik untuk siri masa dan data berjujukan lain.
3. Rangka kerja model
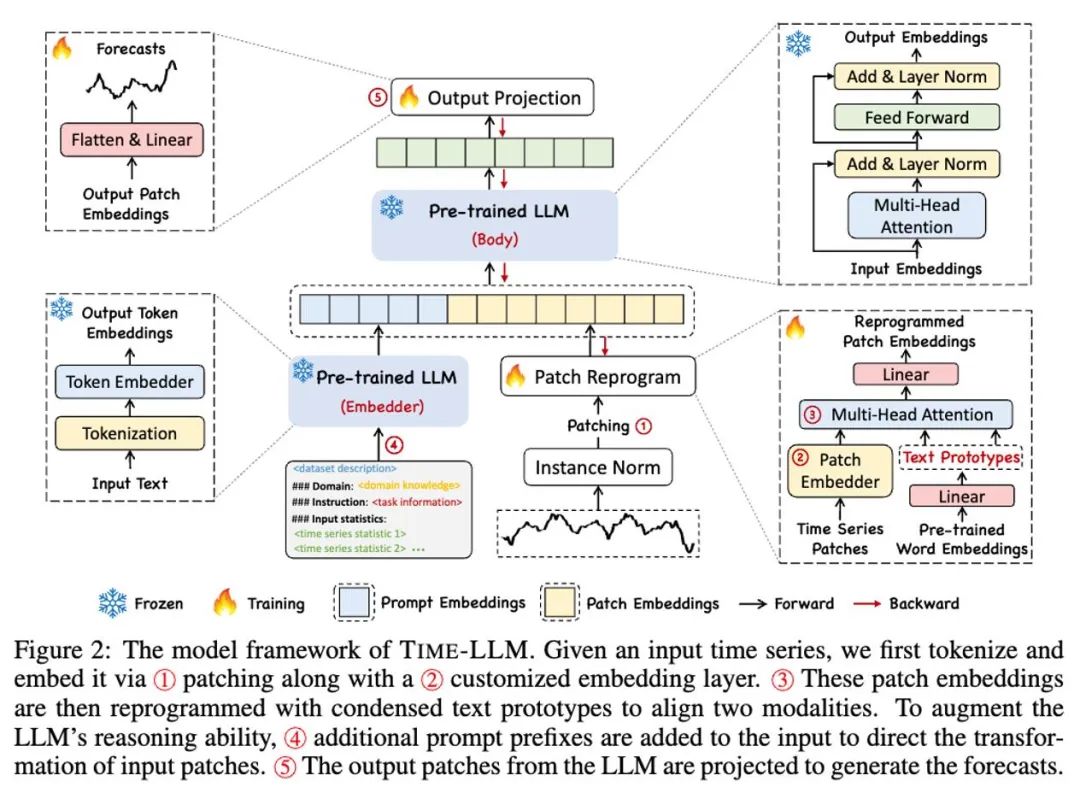
Seperti yang ditunjukkan dalam ① dan ② dalam rajah rangka kerja model di atas, data siri masa input dinormalkan oleh RevIN, dan kemudian dibahagikan kepada patch berbeza dan dipetakan ke ruang terpendam.
Terdapat perbezaan ketara dalam kaedah ungkapan antara data siri masa dan data teks, dan ia tergolong dalam modaliti yang berbeza. Siri masa tidak boleh diedit secara langsung atau diterangkan tanpa kehilangan dalam bahasa semula jadi, yang menimbulkan cabaran besar untuk secara langsung mendorong LLM memahami siri masa. Oleh itu, kita perlu menyelaraskan ciri input temporal kepada domain teks bahasa semula jadi.
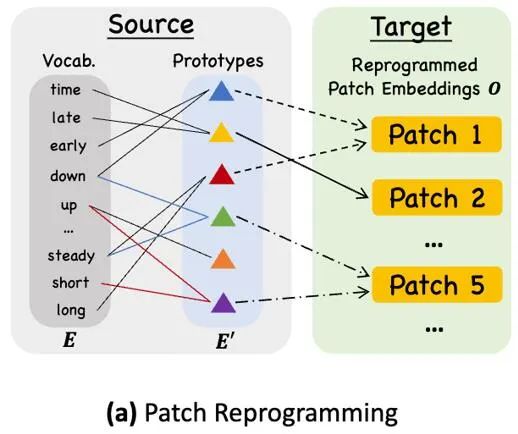
Kaedah biasa untuk menyelaraskan modaliti yang berbeza ialah perhatian silang Seperti yang ditunjukkan dalam ③ dalam rajah rangka kerja model, anda hanya perlu membuat perhatian silang untuk ciri input pembenaman dan pemasaan semua perkataan (di mana pemasaan. ciri input ialah Pertanyaan , pembenaman semua perkataan ialah Kunci dan Nilai). Walau bagaimanapun, perbendaharaan kata yang wujud bagi LLM adalah sangat besar, jadi ia tidak boleh menjajarkan ciri temporal secara langsung dengan semua perkataan dan tidak semua perkataan telah menjajarkan hubungan semantik dengan siri masa. Untuk menyelesaikan masalah ini, kerja ini melakukan gabungan linear perbendaharaan kata untuk mendapatkan prototaip teks Bilangan prototaip teks adalah jauh lebih kecil daripada perbendaharaan kata asal Gabungan boleh digunakan untuk mewakili perubahan ciri-ciri data siri masa, seperti "kenaikan ringkas atau penurunan perlahan."
Untuk mengaktifkan sepenuhnya keupayaan LLM pada tugas pemasaan tertentu, kerja ini mencadangkan paradigma awalan segera, yang merupakan kaedah yang mudah dan berkesan, seperti yang ditunjukkan dalam ④ dalam rajah rangka kerja model. Kemajuan terkini telah menunjukkan bahawa corak data lain seperti imej boleh disepadukan dengan lancar ke dalam awalan isyarat, membolehkan inferens yang cekap berdasarkan input ini. Diilhamkan oleh penemuan ini, pengarang, untuk menjadikan kaedah mereka terpakai secara langsung pada siri masa dunia sebenar, mengemukakan soalan alternatif: Bolehkah petunjuk berfungsi sebagai maklumat awalan untuk memperkaya konteks input dan membimbing transformasi tampung siri masa yang diprogramkan semula? Konsep ini dipanggil Prompt-as-Prefix (PaP), dan tambahan pula, pengarang memerhatikan bahawa ia meningkatkan kebolehsuaian LLM dengan ketara kepada tugas hiliran sambil melengkapkan pengaturcaraan semula tampalan. Dalam istilah orang awam, ini bermakna memberi beberapa maklumat terdahulu set data siri masa, dalam bentuk bahasa semula jadi, sebagai gesaan awalan, dan menyambungkan ciri siri masa yang diselaraskan kepada LLM. Bolehkah ia meningkatkan kesan ramalan?
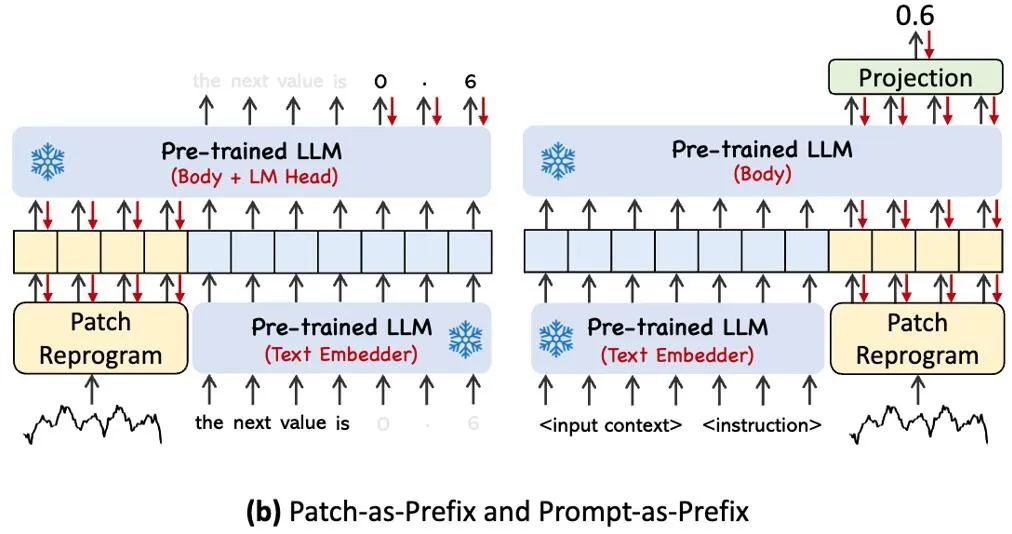
Gambar di atas menunjukkan dua kaedah segera. Dalam Patch-as-Prefix, model bahasa digesa untuk meramalkan nilai berikutnya dalam siri masa, dinyatakan dalam bahasa semula jadi. Pendekatan ini menghadapi beberapa kekangan: (1) Model bahasa sering mempamerkan kepekaan yang rendah apabila memproses nombor berketepatan tinggi tanpa bantuan alat luaran, yang membawa cabaran besar kepada pemprosesan tugas ramalan jangka panjang yang tepat; (2) Pemprosesan pasca tersuai yang kompleks diperlukan untuk model bahasa yang berbeza kerana mereka telah dilatih terlebih dahulu pada korpora yang berbeza dan mungkin menggunakan jenis pembahagian perkataan yang berbeza apabila menjana nombor ketepatan tinggi. Ini menyebabkan ramalan diwakili dalam format bahasa semula jadi yang berbeza, seperti ['0', '.', '6', '1'] dan ['0', '.', '61'], yang mewakili 0.61.
Dalam amalan, pengarang mengenal pasti tiga komponen utama untuk membina gesaan yang berkesan: (1) konteks set data; (2) arahan tugasan untuk menyesuaikan LLM kepada tugasan hiliran yang berbeza, seperti arah aliran, kelewatan masa dan tunggu membolehkan LLM memahami dengan lebih baik ciri-ciri data siri masa. Imej di bawah memberikan contoh gesaan.

4. Keputusan eksperimen
Kami menjalankan ujian komprehensif pada 8 set data awam klasik untuk ramalan jarak jauh Seperti yang ditunjukkan dalam jadual di bawah, Time-LLM dengan ketara mengatasi yang terbaik sebelumnya dalam bidang dalam penanda aras Di samping itu, berbanding dengan GPT4TS yang menggunakan GPT-2 secara langsung, Time-LLM yang menggunakan idea pengaturcaraan semula dan awalan segera (Prompt-as-Prefix) juga telah dipertingkatkan dengan ketara, menunjukkan keberkesanan kaedah ini.
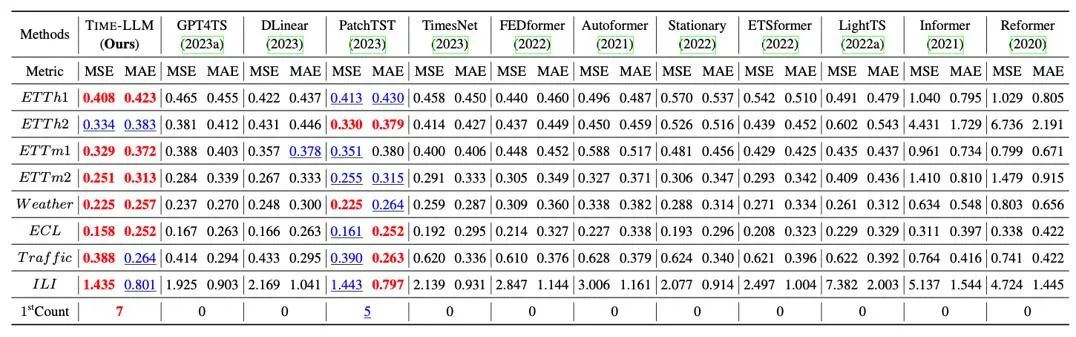
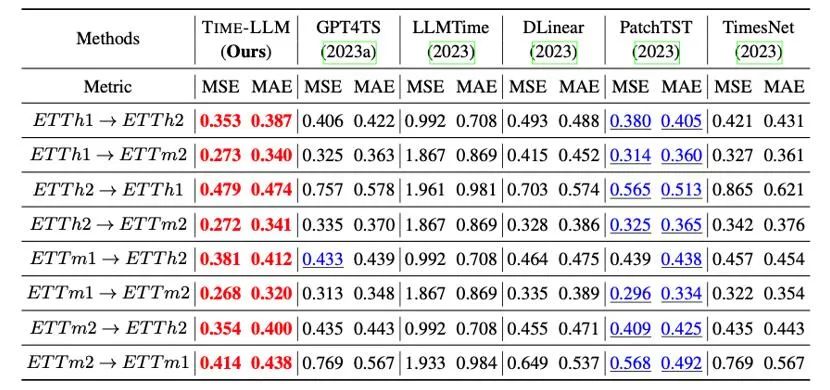
Selain itu, kami menilai keupayaan pembelajaran sifar pukulan sifar LLM yang diprogramkan semula dalam rangka penyesuaian merentas domain Terima kasih kepada keupayaan pengaturcaraan semula, kami mengaktifkan sepenuhnya keupayaan ramalan LLM dalam merentas domain senario Seperti yang ditunjukkan dalam jadual di bawah, Masa-LLM juga menunjukkan hasil ramalan yang luar biasa dalam senario pukulan sifar.
5. Ringkasan
Perkembangan pesat model bahasa besar (LLM) telah banyak mempromosikan kemajuan kecerdasan buatan dalam senario silang modal dan mempromosikan aplikasinya yang meluas dalam pelbagai bidang. Walau bagaimanapun, skala parameter LLM yang besar dan reka bentuknya terutamanya untuk senario pemprosesan bahasa semula jadi (NLP) membawa banyak cabaran kepada aplikasi rentas mod dan rentas domain mereka. Memandangkan perkara ini, kami mencadangkan idea baharu untuk memprogram semula model besar, bertujuan untuk mencapai interaksi silang mod antara teks dan data jujukan, dan menggunakan kaedah ini secara meluas untuk memproses data siri masa dan spatiotemporal berskala besar. Dengan cara ini, kami berharap untuk menjadikan LLM seperti gajah menari yang fleksibel, dapat menunjukkan keupayaan hebat mereka dalam julat senario aplikasi yang lebih luas.
Rakan-rakan yang berminat dialu-alukan untuk membaca kertas kerja (https://arxiv.org/abs/2310.01728) atau lawati halaman projek (https://github.com/KimMeen/Time-LLM) untuk mengetahui lebih lanjut.
Projek ini telah mendapat sokongan penuh daripada NextEvo, jabatan R&D inovasi AI bagi Bahagian Enjin Pintar Kumpulan Ant, terutamanya hasil kerjasama rapat antara pasukan perisikan bahasa dan mesin serta pasukan perisikan pengoptimuman. Di bawah kepimpinan dan bimbingan Zhou Jun, Naib Presiden Bahagian Enjin Pintar, dan Lu Xingyu, Ketua Pasukan Perisikan Pengoptimuman, kami bekerjasama untuk berjaya menyelesaikan pencapaian penting ini.
Atas ialah kandungan terperinci Siapa kata gajah tidak boleh menari!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!