
Rumah >Peranti teknologi >AI >Menukar kaedah permulaan LoRA, kaedah baharu Universiti Peking PiSSA dengan ketara meningkatkan kesan penalaan halus
Menukar kaedah permulaan LoRA, kaedah baharu Universiti Peking PiSSA dengan ketara meningkatkan kesan penalaan halus

- 王林ke hadapan
- 2024-04-13 08:07:051182semak imbas
Memandangkan bilangan parameter model besar meningkat dari hari ke hari, kos penalaan halus keseluruhan model secara beransur-ansur menjadi tidak boleh diterima.
Oleh itu, pasukan penyelidik Universiti Peking mencadangkan kaedah penalaan halus parameter yang cekap dipanggil PiSSA, yang melebihi kesan penalaan halus LoRA yang kini digunakan secara meluas pada set data arus perdana.

Kertas: PiSSA: Nilai Tunggal Utama dan Penyesuaian Vektor Tunggal Model Bahasa Besar
Pautan kertas: https://arxiv.org/pdf/2404.0
- Co. : https ://github.com/GraphPKU/PiSSA
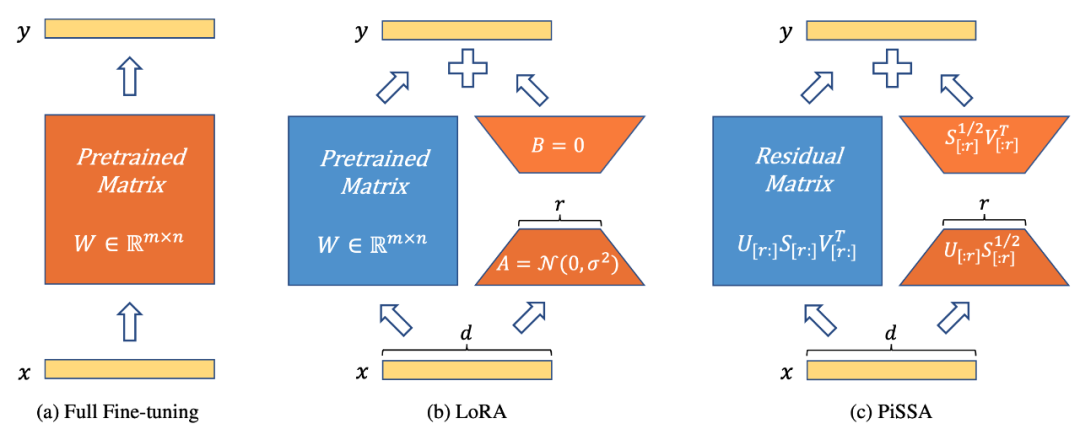
Rajah 1 menunjukkan penalaan halus parameter penuh, LoRA dan PiSSA dari kiri ke kanan. Biru mewakili parameter beku, oren mewakili parameter boleh dilatih dan kaedah permulaan lain. Berbanding dengan penalaan halus parameter penuh, kedua-dua LoRA dan PiSSA mengurangkan bilangan parameter boleh dilatih dengan ketara. Untuk input yang sama, output awal ketiga-tiga kaedah ini adalah sama. Walau bagaimanapun, PiSSA membekukan bahagian kedua model dan memperhalusi bahagian utama secara langsung (nilai r tunggal pertama dan vektor tunggal manakala LoRA boleh dianggap sebagai membekukan bahagian utama model dan memperhalusi bunyi bahagian.
Bandingkan kesan penalaan halus PiSSA dan LoRA pada tugas yang berbeza
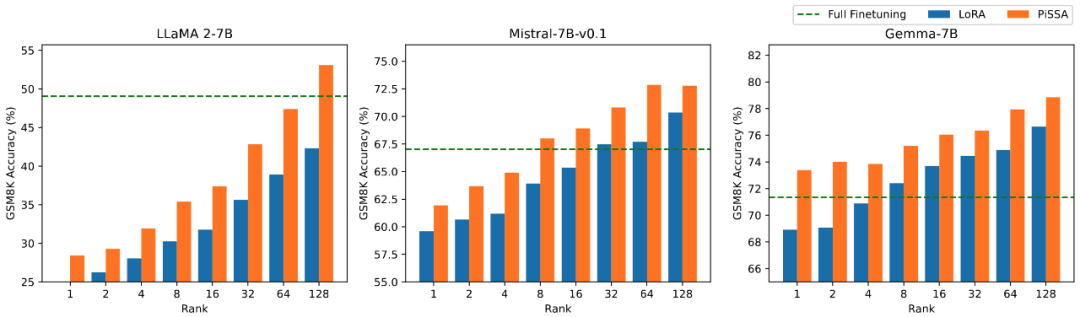
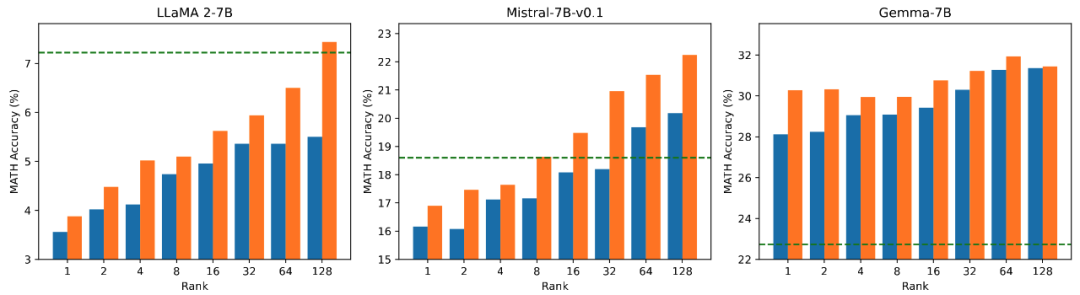
Pasukan penyelidik menggunakan llama 2-7B, Mistral-7B dan Gemma-7B sebagai model asas untuk meningkatkan keupayaan matematik, pengekodan dan dialog mereka melalui penalaan halus. Ini termasuk: latihan tentang MetaMathQA, mengesahkan keupayaan matematik model pada set data GSM8K dan MATH pada CodeFeedBack, mengesahkan keupayaan kod model pada set data HumanEval dan MBPP pada WizardLM-Evol-Instruct; menggunakan MT -Sahkan keupayaan perbualan model di Bangku. Seperti yang dapat dilihat daripada keputusan percubaan dalam jadual di bawah, menggunakan skala parameter boleh dilatih yang sama, kesan penalaan halus PiSSA dengan ketara mengatasi LoRA, malah melepasi penalaan halus parameter penuh.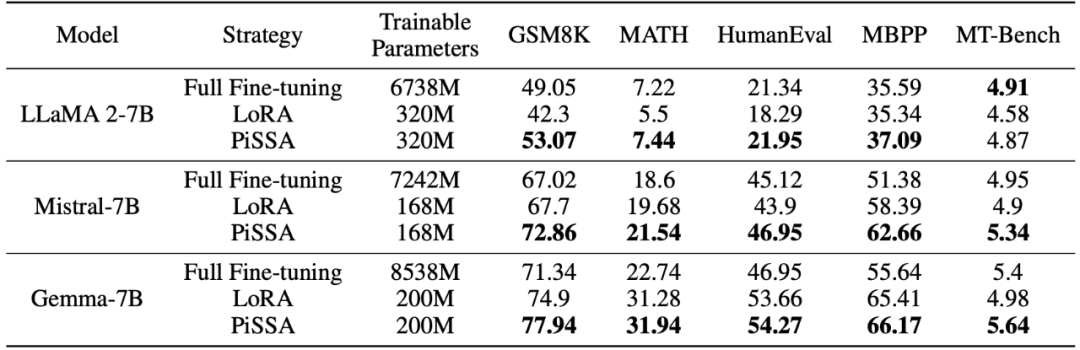
Membandingkan kesan penalaan halus PiSSA dan LoRA di bawah jumlah parameter boleh dilatih yang berbeza
Pasukan penyelidik menjalankan eksperimen ablasi tentang hubungan antara jumlah parameter boleh dilatih dan kesan model pada tugasan matematik. Daripada Rajah 2.1, boleh didapati bahawa pada peringkat awal latihan, kehilangan latihan PiSSA berkurangan dengan cepat, manakala LoRA mempunyai peringkat di mana ia tidak berkurangan malah meningkat sedikit. Di samping itu, kehilangan latihan PiSSA adalah lebih rendah daripada LoRA sepanjang, menunjukkan bahawa ia lebih sesuai dengan set latihan Daripada Rajah 2.2, 2.3, dan 2.4, kita dapat melihat bahawa di bawah setiap tetapan, kehilangan PiSSA sentiasa lebih rendah daripada LoRA, dan ketepatannya adalah. sentiasa lebih tinggi daripada LoRA High, PiSSA boleh mengejar kesan penalaan halus parameter penuh menggunakan lebih sedikit parameter boleh dilatih.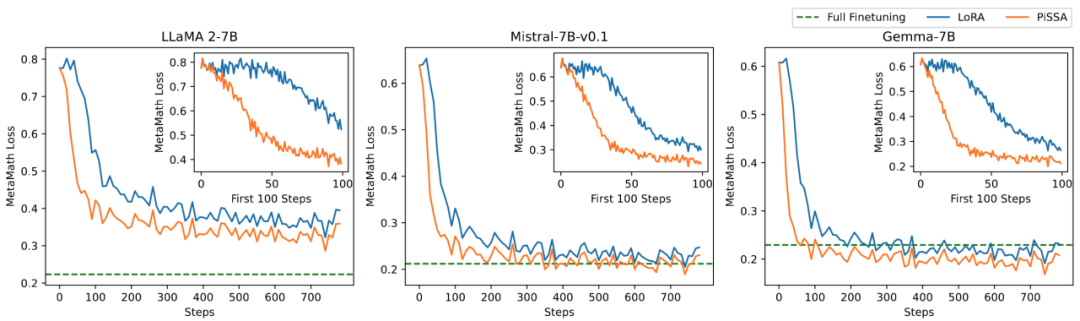
Rajah 2.1) Apabila pangkat 1, kehilangan PiSSA dan LoRA semasa proses latihan. Sudut kanan atas setiap rajah ialah lengkung yang diperbesarkan bagi 100 lelaran pertama. Antaranya, PiSSA diwakili oleh garis oren, LoRA diwakili oleh garis biru, dan penalaan halus parameter penuh menggunakan garis hijau untuk menunjukkan kehilangan akhir sebagai rujukan. Fenomena apabila pangkat adalah [2,4,8,16,32,64,128] adalah konsisten dengan ini. Lihat lampiran artikel untuk butiran.
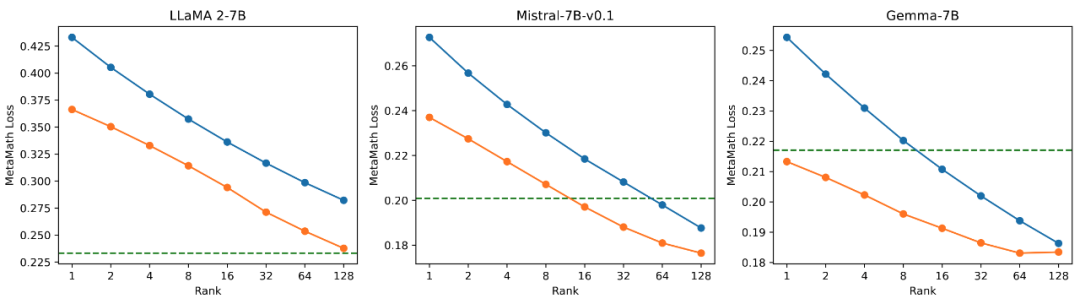
2.2) Kehilangan latihan terakhir PiSSA dan LoRA menggunakan pangkat [1,2,4,8,16,32,64,128].
Ketepatan.
ketepatan dihidupkan.
Penjelasan terperinci kaedah PiSSA
Diinspirasikan oleh Intrinsic SAID [2] "Parameter model besar pra-latihan mempunyai kedudukan rendah", PiSSA melakukan penguraian nilai tunggal pada matriks parameter 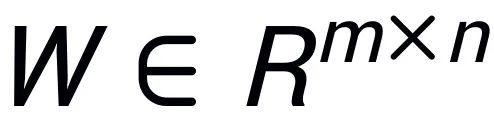 model pra-latihan, di mana nilai r tunggal pertama dan vektor tunggal digunakan untuk memulakan penyesuai ) bagi dua matriks
model pra-latihan, di mana nilai r tunggal pertama dan vektor tunggal digunakan untuk memulakan penyesuai ) bagi dua matriks  dan
dan  ,
,  ; baki nilai tunggal dan vektor tunggal digunakan untuk membina matriks baki
; baki nilai tunggal dan vektor tunggal digunakan untuk membina matriks baki  , supaya
, supaya 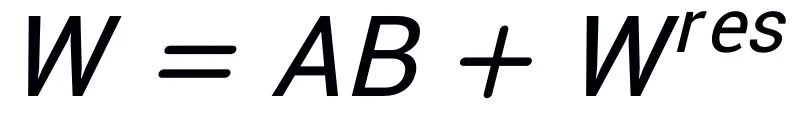 . Oleh itu, parameter dalam penyesuai mengandungi parameter teras model, manakala parameter dalam matriks sisa adalah parameter pembetulan. Dengan memperhalus penyesuai teras A dan B dengan parameter yang lebih kecil dan membekukan baki matriks
. Oleh itu, parameter dalam penyesuai mengandungi parameter teras model, manakala parameter dalam matriks sisa adalah parameter pembetulan. Dengan memperhalus penyesuai teras A dan B dengan parameter yang lebih kecil dan membekukan baki matriks  dengan parameter yang lebih besar, kesan menganggarkan penalaan halus parameter penuh dengan parameter yang sangat sedikit dicapai.
dengan parameter yang lebih besar, kesan menganggarkan penalaan halus parameter penuh dengan parameter yang sangat sedikit dicapai.
Walaupun sama-sama diilhamkan oleh Intrinsic SAID [1], prinsip di sebalik PiSSA dan LoRA adalah berbeza sama sekali.
LoRA percaya bahawa perubahan matriks △W sebelum dan selepas penalaan halus model besar mempunyai pangkat intrinsik r yang sangat rendah, jadi perubahan model △W disimulasikan oleh matriks peringkat rendah yang diperoleh dengan mendarab  dan
dan  . Pada peringkat awal, LoRA memulakan A dengan hingar Gaussian dan memulakan B dengan 0, untuk memastikan keupayaan awal model tidak berubah, dan memperhalusi A dan B untuk mengemas kini W. Sebaliknya, PiSSA tidak mengambil berat tentang △W, tetapi menganggap W mempunyai kedudukan intrinsik r yang sangat rendah. Oleh itu, kami secara langsung melakukan penguraian nilai tunggal pada W dan menguraikannya kepada komponen utama A, B, dan sebutan baki
. Pada peringkat awal, LoRA memulakan A dengan hingar Gaussian dan memulakan B dengan 0, untuk memastikan keupayaan awal model tidak berubah, dan memperhalusi A dan B untuk mengemas kini W. Sebaliknya, PiSSA tidak mengambil berat tentang △W, tetapi menganggap W mempunyai kedudukan intrinsik r yang sangat rendah. Oleh itu, kami secara langsung melakukan penguraian nilai tunggal pada W dan menguraikannya kepada komponen utama A, B, dan sebutan baki  , supaya
, supaya  . Andaikan bahawa penguraian nilai tunggal W ialah
. Andaikan bahawa penguraian nilai tunggal W ialah 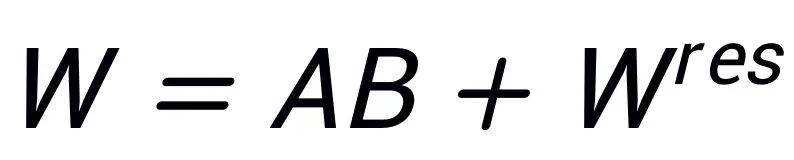 , A dan B dimulakan menggunakan nilai tunggal r dan vektor tunggal dengan nilai tunggal terbesar selepas penguraian SVD:
, A dan B dimulakan menggunakan nilai tunggal r dan vektor tunggal dengan nilai tunggal terbesar selepas penguraian SVD: 
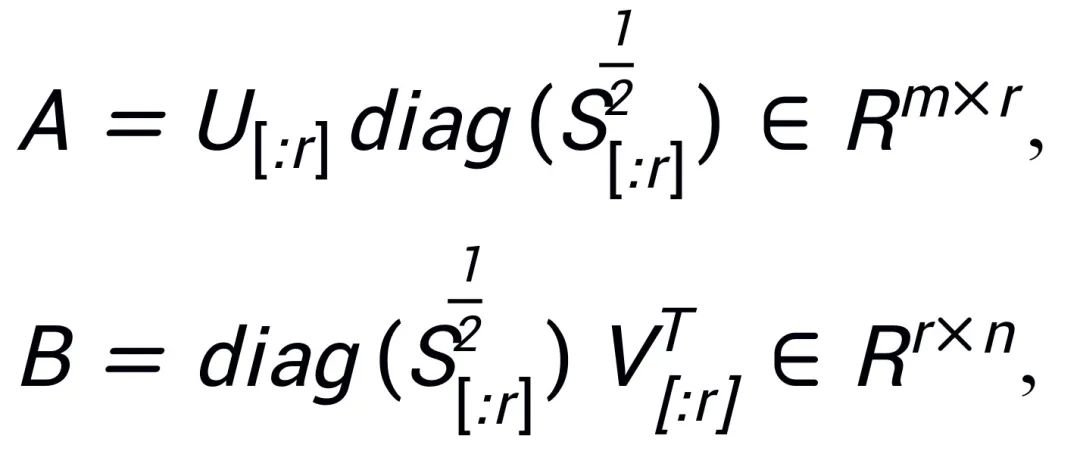
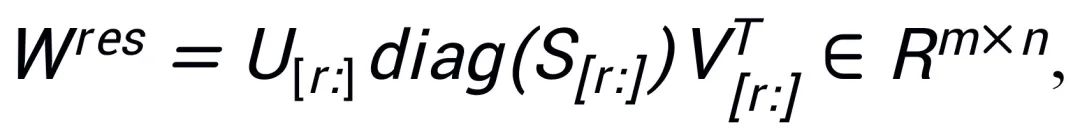
Memandangkan PiSSA menggunakan seni bina yang sama seperti LoRA, ia boleh digunakan sebagai kaedah permulaan pilihan untuk LoRA dan boleh diubah suai dan dipanggil dengan mudah dalam pakej peft (seperti ditunjukkan dalam kod berikut). Seni bina yang sama juga membolehkan PiSSA mewarisi kebanyakan kelebihan LoRA, seperti: menggunakan pengkuantitian 4-bit [3] untuk model baki untuk mengurangkan overhed latihan selepas penalaan halus selesai, penyesuai boleh digabungkan ke dalam baki model tanpa mengubah seni bina model proses inferens ; Tidak perlu berkongsi parameter model yang lengkap, hanya modul PiSSA dengan sebilangan kecil parameter yang perlu dikongsi secara automatik Modul PiSSA; model boleh menggunakan berbilang modul PiSSA pada masa yang sama, dsb. Beberapa penambahbaikan pada kaedah LoRA juga boleh digabungkan dengan PiSSA: contohnya, bukannya menetapkan kedudukan setiap lapisan, mencari kedudukan terbaik melalui pembelajaran [4] menggunakan kemas kini berpandukan PiSSA [5] untuk menembusi had pangkat, dan lain-lain.
# 在 peft 包中 LoRA 的初始化方式后面增加了一种 PiSSA 初始化选项:if use_lora:nn.init.normal_(self.lora_A.weight, std=1 /self.r)nn.init.zeros_(self.lora_B.weight) elif use_pissa:Ur, Sr, Vr = svd_lowrank (self.base_layer.weight, self.r, niter=4) # 注意:由于 self.base_layer.weight 的维度是 (out_channel,in_channel, 所以 AB 的顺序相比图示颠倒了一下)self.lora_A.weight = torch.diag (torch.sqrt (Sr)) @ Vh.t ()self.lora_B.weight = Ur @ torch.diag (torch.sqrt (Sr)) self.base_layer.weight = self.base_layer.weight - self.lora_B.weight @ self.lora_A.weight
Perbandingan percubaan kesan penalaan halus nilai tunggal tinggi, sederhana dan rendah
Untuk mengesahkan kesan penggunaan saiz nilai tunggal dan vektor tunggal yang berbeza untuk memulakan penyesuai pada model, penyelidik menggunakan nilai tunggal tinggi, sederhana dan rendah untuk memulakan LLaMA 2-7B masing-masing , Mistral-7B-v0.1, penyesuai Gemma-7B, dan kemudian diperhalusi pada set data MetaMathQA, dan keputusan percubaan adalah. ditunjukkan dalam Rajah 3. Seperti yang dapat dilihat daripada rajah, kaedah menggunakan pemulaan nilai tunggal primer mempunyai kehilangan latihan terkecil dan mempunyai ketepatan yang lebih tinggi pada set pengesahan GSM8K dan MATH. Fenomena ini mengesahkan keberkesanan penalaan halus nilai tunggal utama dan vektor tunggal.
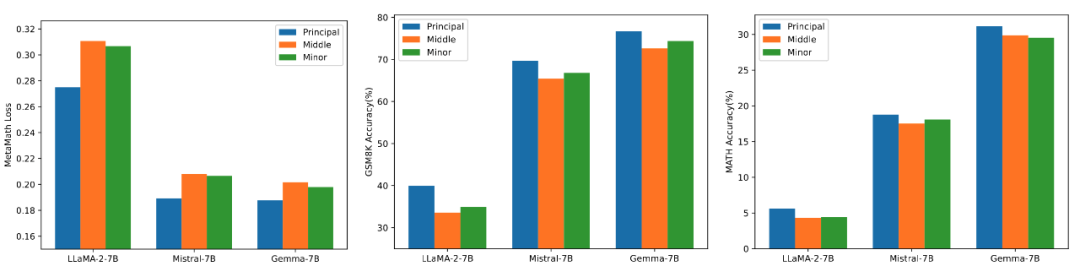
Rajah 3) Dari kiri ke kanan adalah kehilangan latihan, ketepatan pada GSM8K, dan ketepatan pada MATH. Biru mewakili nilai tunggal maksimum, oren mewakili nilai tunggal sederhana, dan hijau mewakili nilai tunggal minimum.
Penguraian Nilai Tunggal Pantas
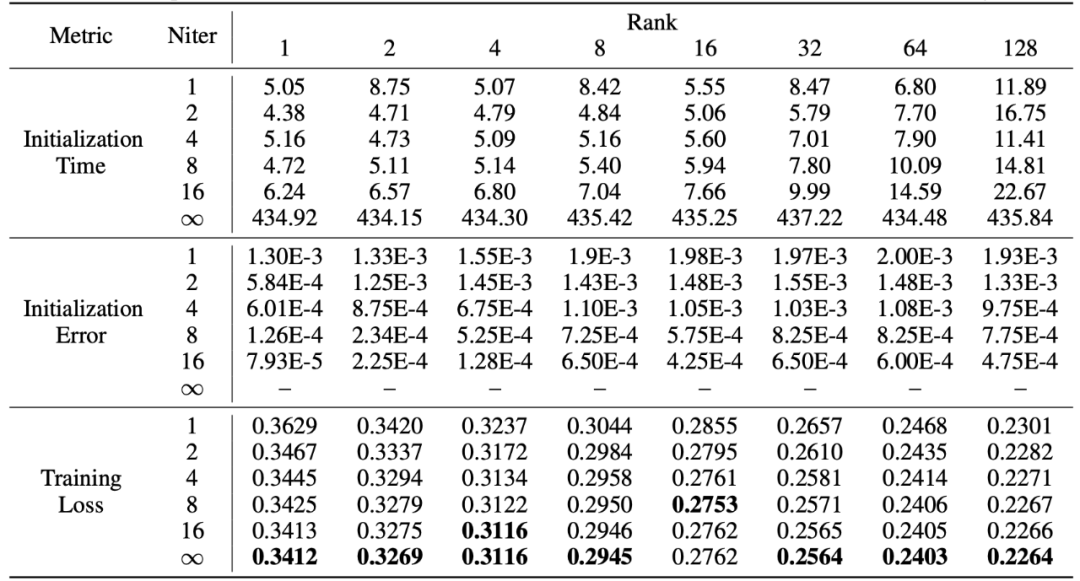
PiSSA mewarisi kelebihan LoRA, mudah digunakan, dan mempunyai kesan yang lebih baik daripada LoRA. Harganya ialah semasa fasa permulaan, model perlu diurai nilai tunggal. Walaupun ia hanya perlu diuraikan sekali semasa permulaan, ia mungkin masih memerlukan beberapa minit atau bahkan berpuluh-puluh minit overhed. Oleh itu, penyelidik menggunakan kaedah penguraian nilai tunggal pantas [6] untuk menggantikan penguraian SVD standard Seperti yang dapat dilihat daripada eksperimen dalam jadual di bawah, ia hanya mengambil masa beberapa saat untuk menganggarkan kesan pemasangan set latihan SVD standard. penguraian. Niter mewakili bilangan lelaran Semakin besar Niter, semakin lama masa tetapi semakin kecil ralat. Niter = ∞ mewakili SVD standard. Ralat purata dalam jadual mewakili purata jarak L_1 antara A dan B yang diperolehi oleh penguraian nilai tunggal cepat dan SVD standard.
Ringkasan dan Tinjauan
Kerja ini melakukan penguraian nilai tunggal pada pemberat model pra-latihan Dengan menggunakan parameter paling penting untuk memulakan penyesuai bernama PiSSA, penalaan halus penyesuai ini menghampiri penalaan halus. model yang lengkap. Percubaan menunjukkan bahawa PiSSA menumpu lebih cepat daripada LoRA dan mempunyai hasil akhir yang lebih baik Satu-satunya kos ialah proses pemulaan SVD yang mengambil masa beberapa saat.
Jadi, untuk hasil latihan yang lebih baik, adakah anda sanggup meluangkan beberapa saat lagi dan menukar permulaan LoRA kepada PiSSA dengan satu klik? LoRA: Adaptasi Peringkat Rendah Model Bahasa Besar
[3] QLoRA: Penalaan Efisien bagi LLM Terkuantiti
[4] AdaLoRA: Peruntukan Belanjawan Suai Suai untuk Penalaan Halus Cekap Parameter
: Fine Delta-Loning High[5] Delta-Tuning High[5] Parameter dengan Delta Matriks Peringkat Rendah
[6] Mencari struktur dengan rawak: Algoritma kebarangkalian untuk membina penguraian matriks anggaran
Atas ialah kandungan terperinci Menukar kaedah permulaan LoRA, kaedah baharu Universiti Peking PiSSA dengan ketara meningkatkan kesan penalaan halus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!