Saya tidak tahu sama ada Gemini 1.5 Pro menggunakan teknologi ini.
Google telah membuat satu lagi langkah besar dan mengeluarkan model Transformer generasi seterusnya Infini-Transformer.
Infini-Transformer memperkenalkan cara yang cekap untuk menskalakan model bahasa besar (LLM) berasaskan Transformer kepada input yang tidak terhingga panjang tanpa meningkatkan keperluan memori dan pengiraan. Menggunakan teknologi ini, para penyelidik berjaya meningkatkan panjang konteks model 1B kepada 1 juta yang digunakan pada model 8B, model itu boleh mengendalikan tugas ringkasan buku 500K. Seni bina Transformer telah mendominasi bidang kecerdasan buatan generatif sejak penerbitan kertas penyelidikan terobosan "Perhatian Adalah Semua yang Anda Perlukan" pada 2017. Reka bentuk Transformer yang dioptimumkan oleh Google agak kerap berlaku baru-baru ini, mereka mengemas kini seni bina Transformer dan mengeluarkan Mixture-of-Depths (MoD), yang mengubah model pengkomputeran Transformer sebelumnya. Dalam masa beberapa hari, Google mengeluarkan kajian baharu ini. Para penyelidik yang memfokuskan pada bidang AI semuanya memahami kepentingan ingatan Ia adalah asas kecerdasan dan boleh menyediakan pengkomputeran yang cekap untuk LLM. Walau bagaimanapun, LLM berasaskan Transformer dan Transformer mempamerkan kerumitan kuadratik dalam kedua-dua penggunaan memori dan masa pengiraan disebabkan oleh ciri-ciri wujud mekanisme perhatian, iaitu, mekanisme perhatian dalam Transformer. Contohnya, untuk model 500B dengan saiz kelompok 512 dan panjang konteks 2048, jejak memori keadaan nilai kunci perhatian (KV) ialah 3TB. Tetapi sebenarnya, seni bina Transformer standard kadangkala perlu memanjangkan LLM kepada jujukan yang lebih panjang (seperti 1 juta token), yang membawa overhed memori yang besar, dan apabila panjang konteks meningkat, kos penggunaan juga meningkat. Berdasarkan ini, Google telah memperkenalkan pendekatan yang berkesan, komponen utamanya ialah teknologi perhatian baharu yang dipanggil Infini-attention. Tidak seperti Transformers tradisional, yang menggunakan perhatian tempatan untuk membuang serpihan lama dan mengosongkan ruang memori untuk serpihan baharu. Infini-attention menambah memori mampatan, yang boleh menyimpan serpihan lama terpakai ke dalam memori termampat Apabila output, maklumat konteks semasa dan maklumat dalam memori termampat akan diagregatkan, jadi model boleh mendapatkan semula sejarah konteks yang lengkap. Kaedah ini membolehkan Transformer LLM menskalakan kepada konteks yang tidak terhingga panjang dengan memori terhad dan memproses input yang sangat panjang untuk pengiraan secara penstriman. Percubaan menunjukkan bahawa kaedah itu mengatasi garis dasar pada penanda aras pemodelan bahasa konteks panjang sambil mengurangkan parameter memori lebih daripada 100 kali ganda. Model ini mencapai kebingungan yang lebih baik apabila dilatih dengan panjang jujukan 100K. Di samping itu, kajian mendapati bahawa model 1B telah diperhalusi pada contoh utama panjang jujukan 5K, menyelesaikan masalah panjang 1M. Akhir sekali, kertas kerja menunjukkan bahawa model 8B dengan Infini-attention mencapai keputusan SOTA baharu pada tugasan ringkasan buku sepanjang 500K selepas latihan pra-latihan berterusan dan penalaan halus tugas. Sumbangan artikel ini diringkaskan seperti berikut:
- Memperkenalkan mekanisme perhatian yang praktikal dan berkuasa Infini-attention - dengan ingatan termampat jangka panjang dan perhatian kausal setempat, yang boleh digunakan secara berkesan. model kebergantungan konteks jangka panjang dan jangka pendek;
- Infini-perhatian membuat perubahan minimum kepada perhatian produk titik berskala standard dan direka bentuk untuk menyokong pra-latihan berterusan dan pembelajaran kendiri konteks panjang. Penyesuaian;
- Kaedah ini membolehkan Transformer LLM memproses input yang sangat panjang melalui aliran, menskalakan kepada konteks yang tidak terhingga dengan memori dan sumber pengkomputeran yang terhad. Pautan Kertas H: https://arxiv.org/pdf/2404.07143.pdf
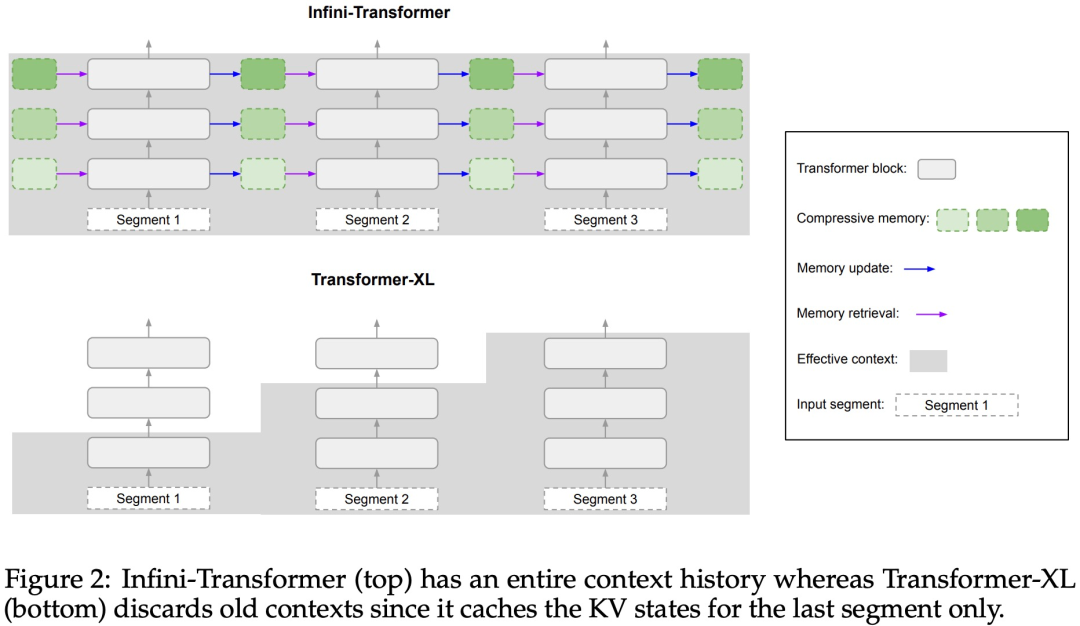
Tajuk Tesis: Jangan Tinggalkan Konteks Di Belakang: Transformers Konteks Infinite yang Cekap dengan Infini-Wention Perhatian infini membolehkan Transformer LLM mengendalikan input panjang tak terhingga dengan cekap dengan jejak memori dan pengiraan terhad. Seperti yang ditunjukkan dalam Rajah 1 di bawah, Infini-attention menggabungkan memori termampat ke dalam mekanisme perhatian biasa, dan membina perhatian tempatan bertopeng dan mekanisme perhatian linear jangka panjang dalam satu blok Transformer.
Perhatian infini membolehkan Transformer LLM mengendalikan input panjang tak terhingga dengan cekap dengan jejak memori dan pengiraan terhad. Seperti yang ditunjukkan dalam Rajah 1 di bawah, Infini-attention menggabungkan memori termampat ke dalam mekanisme perhatian biasa, dan membina perhatian tempatan bertopeng dan mekanisme perhatian linear jangka panjang dalam satu blok Transformer.
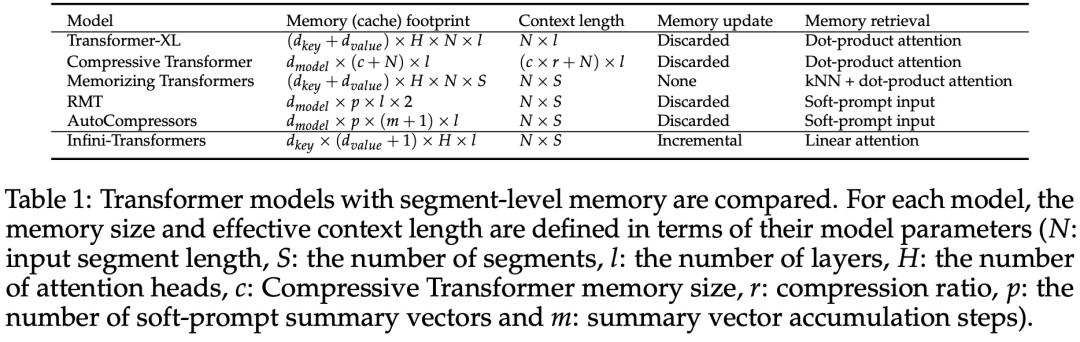
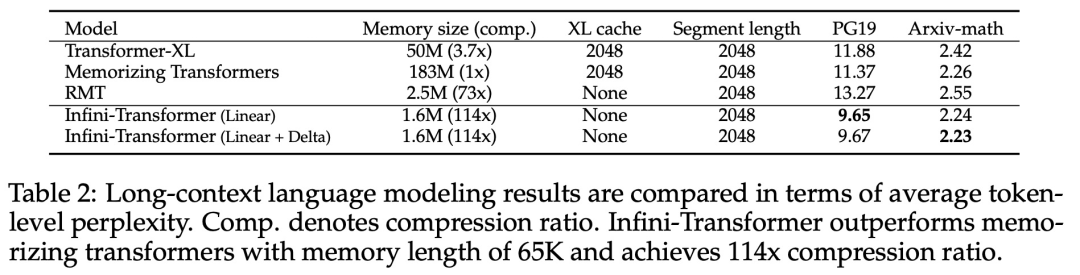
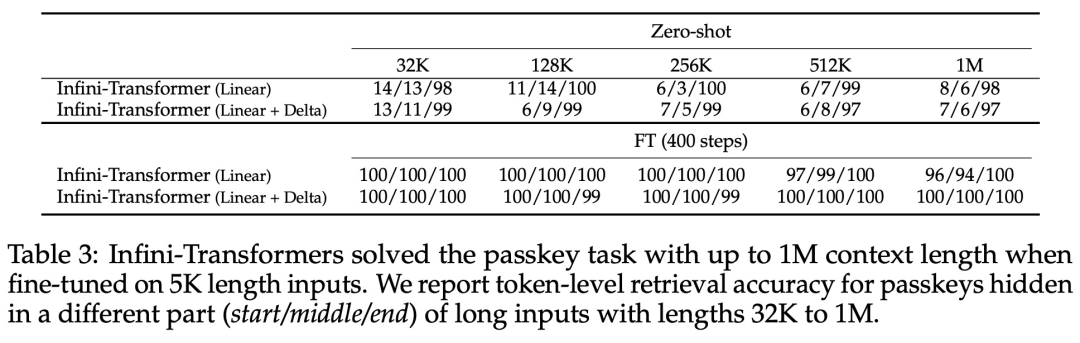
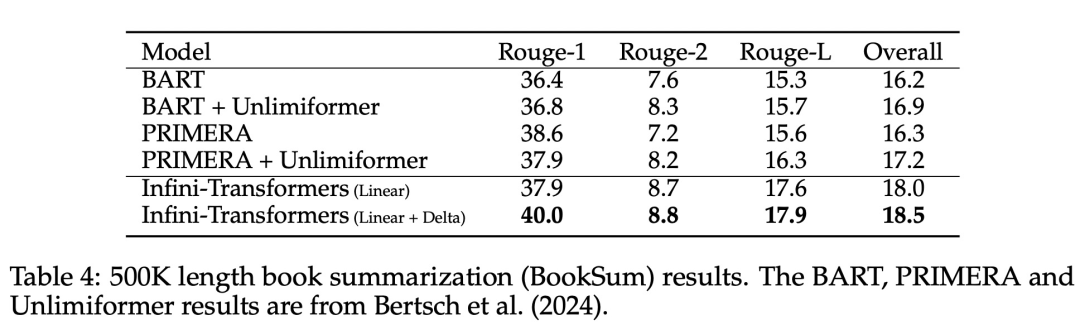
Pengubahsuaian halus tetapi kritikal pada lapisan perhatian Transformer ini boleh memanjangkan tetingkap konteks LLM sedia ada kepada panjang yang tidak terhingga melalui pra-latihan dan penalaan halus yang berterusan. Infini-perhatian mengambil semua kunci, nilai dan keadaan pertanyaan pengiraan perhatian standard untuk penyatuan dan perolehan ingatan jangka panjang, dan menyimpan keadaan perhatian KV lama dalam memori termampat sebaliknya Buangnya seperti mekanisme perhatian standard.Apabila memproses urutan berikutnya, Infini-attention menggunakan keadaan pertanyaan perhatian untuk mendapatkan semula nilai daripada ingatan. Untuk mengira output konteks akhir, Infini-attention mengagregatkan nilai perolehan memori jangka panjang dan konteks perhatian setempat. Seperti yang ditunjukkan dalam Rajah 2 di bawah, pasukan penyelidik membandingkan Infini-Transformer dan Transformer-XL berdasarkan Infini-attention. Sama seperti Transformer-XL, Infini-Transformer beroperasi pada jujukan segmen dan mengira konteks perhatian produk titik penyebab standard dalam setiap segmen. Oleh itu, pengiraan perhatian produk titik adalah setempat dalam beberapa segi. Walau bagaimanapun, perhatian tempatan membuang keadaan perhatian segmen sebelumnya apabila memproses segmen seterusnya, tetapi Infini-Transformer menggunakan semula keadaan perhatian KV lama untuk mengekalkan keseluruhan sejarah konteks melalui storan termampat. Oleh itu, setiap lapisan perhatian Infini-Transformer mempunyai keadaan mampat global dan keadaan berbutir halus tempatan. Serupa dengan multi-head attention (MHA), selain perhatian produk titik, Infini-attention juga mengekalkan H ingatan mampat selari untuk setiap lapisan perhatian (H ialah bilangan kepala perhatian). Jadual 1 di bawah menyenaraikan jejak memori konteks dan panjang konteks berkesan yang ditakrifkan oleh beberapa model berdasarkan parameter model dan panjang segmen input. Infini-Transformer menyokong tetingkap konteks tak terhingga dengan jejak memori terhad. Kajian ini menilai model Infini-Transformer pada pemodelan bahasa konteks panjang, pengambilan blok konteks kunci panjang 1M dan 500K panjang buku ringkasan input panjang, yang mempunyai urutan input panjang tugasan yang sangat tinggi Untuk pemodelan bahasa, penyelidik memilih untuk melatih model dari awal, manakala untuk tugasan ringkasan utama dan buku, penyelidik menggunakan pra-latihan berterusan LLM untuk membuktikan kebolehsuaian konteks panjang plug-and-play Infini-attention. Pemodelan bahasa konteks panjang. Keputusan Jadual 2 menunjukkan bahawa Infini-Transformer mengatasi garis dasar Transformer-XL dan Memorizing Transformers dan menyimpan 114x lebih sedikit parameter berbanding model Memorizing Transformer. Misi Utama. Jadual 3 menunjukkan Infini-Transformer, diperhalusi pada input panjang 5K, menyelesaikan tugas utama sehingga 1M panjang konteks. Token input dalam percubaan berjulat dari 32K hingga 1M Untuk setiap subset ujian, penyelidik mengawal kedudukan kunci supaya ia terletak berhampiran permulaan, tengah atau akhir jujukan input. Eksperimen melaporkan ketepatan tangkapan sifar dan ketepatan penalaan halus. Selepas 400 langkah penalaan halus pada input panjang 5K, Infini-Transformer menyelesaikan tugasan sehingga 1M panjang konteks. Tugasan ringkasan. Jadual 4 membandingkan Infini-Transformer dengan model penyahkod pengekod yang dibina khusus untuk tugasan ringkasan. Keputusan menunjukkan bahawa Infini-Transformer mengatasi keputusan terbaik sebelumnya dan mencapai SOTA baharu pada BookSum dengan memproses keseluruhan teks buku. Para penyelidik juga memplot skor keseluruhan Rouge bagi pembahagian pengesahan data BookSum dalam Rajah 4. Aliran polyline menunjukkan bahawa Infini-Transformers meningkatkan metrik prestasi ringkasan apabila panjang input meningkat.
Atas ialah kandungan terperinci Berkembang terus kepada panjang tak terhingga, Google Infini-Transformer menamatkan perbahasan panjang konteks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



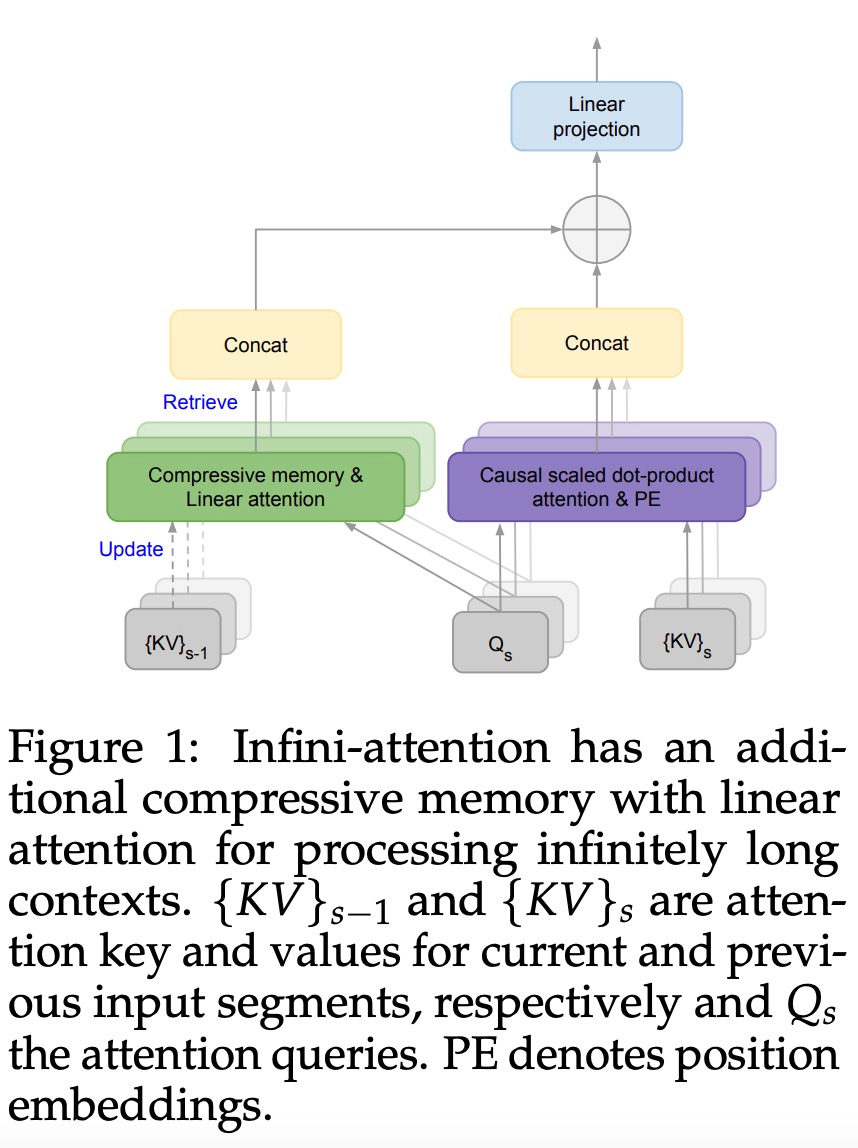 Infini-perhatian mengambil semua kunci, nilai dan keadaan pertanyaan pengiraan perhatian standard untuk penyatuan dan perolehan ingatan jangka panjang, dan menyimpan keadaan perhatian KV lama dalam memori termampat sebaliknya Buangnya seperti mekanisme perhatian standard.Apabila memproses urutan berikutnya, Infini-attention menggunakan keadaan pertanyaan perhatian untuk mendapatkan semula nilai daripada ingatan. Untuk mengira output konteks akhir, Infini-attention mengagregatkan nilai perolehan memori jangka panjang dan konteks perhatian setempat.
Infini-perhatian mengambil semua kunci, nilai dan keadaan pertanyaan pengiraan perhatian standard untuk penyatuan dan perolehan ingatan jangka panjang, dan menyimpan keadaan perhatian KV lama dalam memori termampat sebaliknya Buangnya seperti mekanisme perhatian standard.Apabila memproses urutan berikutnya, Infini-attention menggunakan keadaan pertanyaan perhatian untuk mendapatkan semula nilai daripada ingatan. Untuk mengira output konteks akhir, Infini-attention mengagregatkan nilai perolehan memori jangka panjang dan konteks perhatian setempat.