
Rumah >Peranti teknologi >AI >Algoritma pemprofilan pengguna: sejarah, situasi semasa dan masa depan
Algoritma pemprofilan pengguna: sejarah, situasi semasa dan masa depan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-11 13:40:181083semak imbas
1. Pengenalan kepada potret pengguna
Potret ialah penerangan berstruktur tentang pengguna yang boleh difahami manusia, boleh dibaca mesin dan boleh ditulis. Ia bukan sahaja menyediakan perkhidmatan yang diperibadikan, tetapi juga memainkan peranan penting dalam membuat keputusan strategik dan analisis perniagaan syarikat.
1. Klasifikasi potret
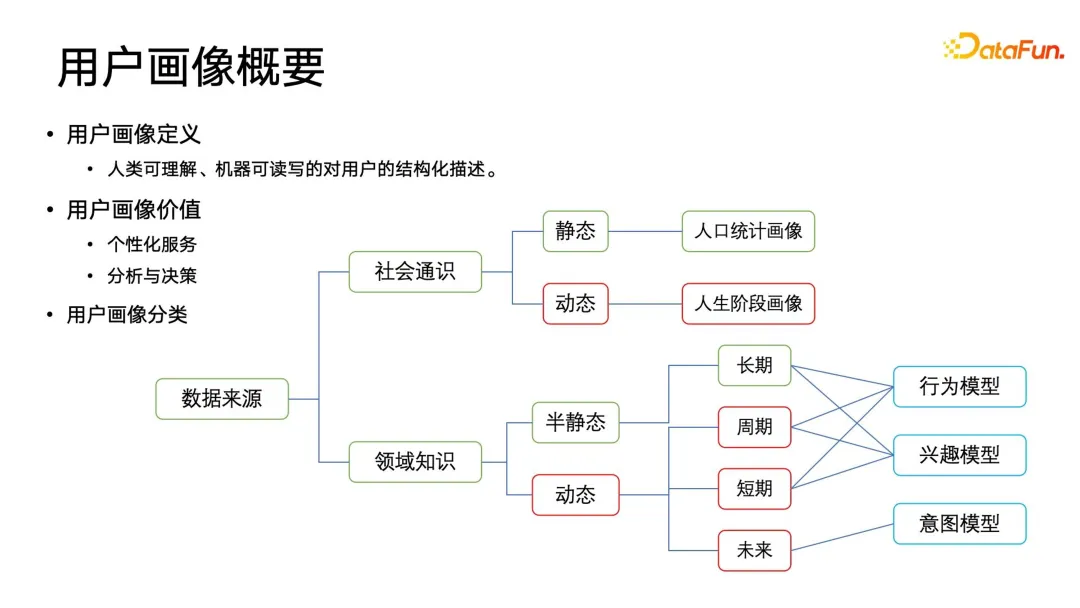
Mengikut sumber data, ia dibahagikan kepada kategori pengetahuan am sosial dan kategori pengetahuan domain. Potret sosial am boleh dibahagikan kepada kategori statik dan dinamik mengikut dimensi masa Potret sosial umum statik yang paling biasa termasuk ciri demografi, seperti jantina, pendaftaran isi rumah, sekolah tamat pengajian, dll. Kandungan ini dipaparkan dalam tempoh yang agak lama. masa. Tingkap agak statik Selain menggunakannya dalam gambar, ia juga sering digunakan dalam demografi, demografi, sosiologi, dll. Potret umum sosial dinamik adalah lebih penting, juga dikenali sebagai potret peringkat kehidupan Sebagai contoh, e-dagang, pendapatan rakyat akan terus berubah dengan perkembangan kerjaya, dan kecenderungan membeli-belah mereka juga akan berubah, jadi potret peringkat kehidupan ini sangat praktikal. nilai.
Selain potret umum di atas, syarikat mungkin membina lebih banyak potret pengetahuan domain dalam syarikat. Potret pengetahuan domain boleh dibahagikan kepada separa statik dan dinamik dari dimensi masa, dan boleh dibahagikan lagi kepada potret atribut jangka panjang, kitaran, jangka pendek dan masa hadapan. Potret dimensi masa ini terikat dengan medan konsep, yang merangkumi model tingkah laku, model minat dan model niat.
Model gelagat terutamanya menjejaki gelagat kitaran pengguna, seperti perkara yang pengguna lakukan semasa berulang-alik setiap pagi, perkara yang mereka lakukan selepas keluar kerja pada waktu petang, perkara yang mereka lakukan sepanjang minggu, perkara yang mereka lakukan pada hujung minggu dan tingkah laku kitaran lain. Model minat melakukan pemodelan bersama dan pengisihan teg dalam pengetahuan domain Sebagai contoh, pengguna boleh mendapatkan beberapa log operasi selepas berinteraksi dengan produk platform seperti APP boleh dikaitkan dan dihuraikan untuk mengekstrak beberapa data berstruktur dan berlabel Mereka boleh dibahagikan kepada kategori, diberi berat tertentu, dan akhirnya diisih untuk membentuk profil minat tertentu. Perlu diingatkan bahawa model niat adalah lebih kepada masa hadapan dan merupakan ramalan niat masa depan pengguna. Tetapi bagaimana untuk meramalkan kemungkinan niat pengguna baharu sebelum mereka berinteraksi? Masalah ini lebih berat sebelah ke arah potret masa nyata dan masa depan, dan juga mempunyai keperluan yang lebih tinggi untuk struktur infrastruktur keseluruhan data potret.
2. Seni bina aplikasi asas potret pengguna
Setelah memahami konsep dan klasifikasi umum imej, mari kita perkenalkan secara ringkas rangka kerja aplikasi asas potret pengguna. Keseluruhan rangka kerja boleh dibahagikan kepada empat peringkat Pertama ialah pengumpulan data, yang kedua ialah prapemprosesan data, yang ketiga ialah pembinaan dan kemas kini potret berdasarkan data yang diproses ini, dan akhirnya lapisan aplikasi A ditakrifkan dalam lapisan aplikasi untuk membolehkan pengguna hiliran ke Pelbagai aplikasi boleh menggunakan imej dengan lebih mudah, cepat dan cekap.
Kita dapati daripada rangka kerja ini bahawa aplikasi pemprofilan pengguna dan algoritma pemprofilan pengguna perlu memahami konotasi yang sangat luas dan kompleks, kerana apa yang kita hadapi bukan sahaja mudah, berlabel, data berasaskan teks, Terdapat juga pelbagai multi- data modal, yang mungkin audio, video atau grafik Pelbagai kaedah pra-pemprosesan diperlukan untuk mendapatkan data berkualiti tinggi dan kemudian membina potret yang lebih yakin. Ini akan melibatkan pelbagai aspek seperti perlombongan data, pembelajaran mesin, graf pengetahuan dan pembelajaran statistik. Perbezaan antara potret pengguna dan algoritma pengesyoran carian tradisional ialah kami perlu bekerjasama rapat dengan pakar domain untuk membina potret berkualiti tinggi secara berterusan dalam lelaran dan kitaran.

2. Potret pengguna tradisional berdasarkan ontologi
Potret pengguna ialah konsep yang diwujudkan melalui analisis maklumat dan data yang mendalam Dengan memahami minat, pilihan dan corak tingkah laku pengguna, kami boleh memberikan pengguna perkhidmatan dan pengalaman yang diperibadikan dengan lebih baik.
Pada zaman awal, potret pengguna terutamanya bergantung pada graf pengetahuan, yang berasal daripada konsep ontologi. Ontologi pula tergolong dalam kategori falsafah. Pertama sekali, definisi ontologi hampir sama dengan definisi potret Ia adalah sistem konsep yang boleh difahami oleh manusia dan boleh dibaca dan ditulis oleh mesin. Sudah tentu, kerumitan sistem konsep ini sendiri boleh menjadi sangat tinggi Ia terdiri daripada entiti, atribut, hubungan dan aksiom. Kelebihan potret pengguna berdasarkan Ontologi ialah ia mudah untuk mengklasifikasikan pengguna dan kandungan, dan ia adalah mudah untuk menghasilkan laporan data yang boleh difahami secara intuitif oleh manusia, dan kemudian membuat keputusan berdasarkan kesimpulan yang berkaitan dengan laporan mengapa kaedah ini dipilih dalam era pembelajaran yang tidak mendalam.
Seterusnya, kami akan memperkenalkan beberapa konsep asas dalam Ontologi. Untuk membina Ontologi, anda mesti terlebih dahulu mengkonseptualisasikan pengetahuan domain, iaitu, membina entiti, atribut, perhubungan dan aksiom, dan memprosesnya ke dalam format yang boleh dibaca mesin, seperti RDF dan OWL. Sudah tentu, anda juga boleh menggunakan beberapa format data yang lebih mudah, atau bahkan merosot Ontologi menjadi pangkalan data hubungan atau pangkalan data graf yang boleh menyimpan, membaca, menulis dan menganalisis data. Cara untuk mendapatkan potret jenis ini biasanya dengan membinanya melalui pakar domain, atau memperkaya dan memperhalusinya berdasarkan beberapa piawaian industri sedia ada. Sebagai contoh, sistem pelabelan produk yang diguna pakai oleh Taobao sebenarnya menggunakan piawaian awam negara untuk pelbagai industri komoditi pembuatan, dan memperkaya dan melelang atas dasar ini.

Gambar di bawah adalah contoh ontologi yang sangat mudah, yang mengandungi 3 nod. Filem mempunyai ID unik, dan setiap filem mempunyai atributnya sendiri, seperti tajuk dan peranan dibintangi Entiti ini juga tergolong dalam siri jenayah, dan siri jenayah tergolong dalam subkategori filem aksi. Kami menulis dokumen teks RDF di sebelah kanan rajah di bawah berdasarkan gambar rajah visual ini Dalam dokumen ini, sebagai tambahan kepada hubungan atribut entiti yang boleh kami fahami secara intuitif, beberapa aksiom juga ditakrifkan, seperti kekangan yang "mempunyai. title" hanya boleh bertindak pada Untuk domain konseptual asas filem, jika terdapat domain konseptual lain, seperti menggunakan pengarah filem sebagai entiti untuk membinanya ke dalam Ontologi, pengarah filem tidak boleh mempunyai atribut "mempunyai tajuk" . Di atas adalah pengenalan ringkas kepada ontologi.

Pada hari-hari awal pemprofilan pengguna berdasarkan ontologi, kaedah yang serupa dengan TF-IDF telah digunakan untuk mengira berat teg berstruktur yang dibina. TF-IDF digunakan terutamanya dalam medan carian atau medan subjek teks pada masa lalu Ia terutamanya mengira berat istilah carian atau perkataan subjek tertentu Apabila digunakan pada potret pengguna, ia hanya perlu dihadkan sedikit dan berubah bentuk, seperti dalam contoh sebelumnya TF adalah untuk mengira bilangan filem atau video pendek yang ditonton oleh pengguna di bawah kategori teg ini adalah untuk mengira bilangan filem atau video pendek yang ditonton pengguna di bawah setiap kategori teg dan jumlah bilangan semua pandangan sejarah, dan kemudian mengiranya mengikut formula dalam rajah IDF dan TF *IDF. Kaedah pengiraan TF-IDF adalah sangat mudah dan stabil, dan ia juga boleh ditafsir dan mudah digunakan.
Tetapi kelemahannya juga jelas: TF-IDF sangat sensitif terhadap butiran tag, tetapi tidak sensitif terhadap struktur Ontologi itu sendiri Ia mungkin terlalu menekankan minat yang tidak popular dan membawa kepada penyelesaian remeh, seperti pengguna Jika anda hanya menonton sekali-sekala. video di bawah teg tertentu, TF akan menjadi sangat kecil dan IDF akan menjadi sangat besar TF-IDF mungkin menjadi nilai yang hampir dengan minat popularnya. Lebih penting lagi, kami perlu mengemas kini dan melaraskan potret pengguna dari semasa ke semasa, dan kaedah TF-IDF tradisional tidak sesuai untuk situasi ini. Oleh itu, penyelidik telah mencadangkan kaedah baharu untuk membina potret pengguna berwajaran secara langsung berdasarkan ekspresi berstruktur ontologi untuk memenuhi keperluan kemas kini dinamik.

Algoritma ini bermula dari kategori daun Ontologi, menggunakan gelagat penggunaan media pengguna di bawah tag yang sepadan untuk mengemas kini berat Berat dimulakan kepada 0, dan kemudian dikemas kini mengikut fungsi f gelagat yang ditakrifkan oleh gelagat pengguna. . Fungsi fkelakuan akan memberikan isyarat maklum balas tersirat yang berbeza berdasarkan tahap penggunaan pengguna yang berbeza, seperti klik, pembelian dan pesanan tambahan dalam medan e-dagang, atau main semula dan penyiapan dalam medan video. Pada masa yang sama, kami juga akan memberikan isyarat maklum balas tentang kekuatan yang berbeza kepada gelagat pengguna yang berbeza Contohnya, dalam tingkah laku penggunaan e-dagang, pesanan > pembelian > klik dalam penggunaan video, penyiapan main semula yang lebih tinggi, tempoh main balik yang lebih tinggi, dsb nilai fkelakuan yang lebih kukuh juga akan ditetapkan.
Selepas berat tandatangan sasaran kelas daun dikemas kini, berat kelas induk perlu dikemas kini Perlu diingat bahawa apabila mengemas kini kelas induk, pekali pereputan kurang daripada 1 perlu ditakrifkan. Kerana, seperti yang ditunjukkan dalam rajah, pengguna mungkin berminat dengan subkategori "Perang Dunia II" dalam "Perang", tetapi mungkin tidak berminat dengan tema perang lain. Pekali pengecilan ini boleh disesuaikan sebagai hiperparameter Takrifan ini menekankan kesamaan sumbangan kepentingan setiap subkategori kepada kategori induk Timbal balik bilangan label subkategori juga boleh digunakan sebagai pekali pengecilan, supaya lebih diberi penekanan. pada minat khusus, sebagai contoh, beberapa nod kategori induk yang besar mengandungi tema subkategori yang luas dan tidak berkait rapat. dan kelajuan pereputan boleh ditetapkan dengan sewajarnya untuk menjadi lebih cepat , dan label subkategori yang lebih kecil mungkin mempunyai minat khusus dan tidak terdapat banyak karya Hubungan antara topik subkategori akan menjadi agak rapat, dan kelajuan pengecilan boleh ditetapkan dengan sewajarnya menjadi lebih kecil. Ringkasnya, kita boleh menetapkan pekali pengecilan berdasarkan atribut pengetahuan domain ini yang ditakrifkan dalam Ontologi.
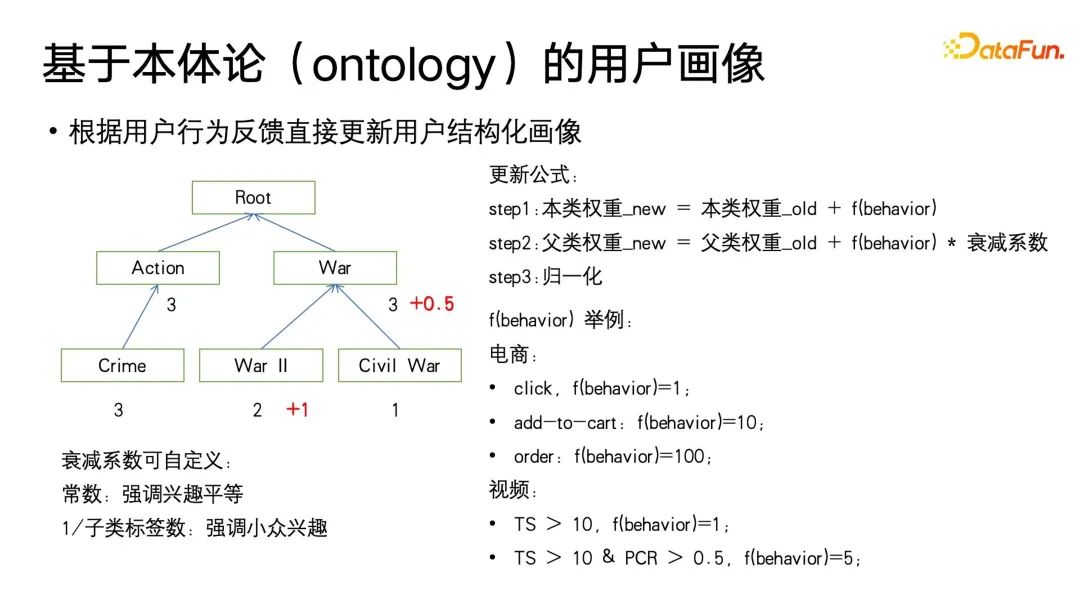
Kaedah di atas boleh mencapai kesan kemas kini tag berstruktur, dan pada dasarnya ia boleh menyamai atau bahkan mengatasi kesan TF-IDF Walau bagaimanapun, ia tidak mempunyai atribut skala masa, iaitu, cara membina masa skala yang lebih sensitif potret.
Kami mula-mula berfikir bahawa kami boleh melaraskan lagi kemas kini berat itu sendiri. Apabila anda perlu membezakan potret pengguna jangka panjang dan jangka pendek, anda boleh menambah tetingkap gelongsor pada berat dan menentukan pekali pereputan masa a (antara 0-1 Fungsi tetingkap gelongsor adalah untuk memfokuskan kepada pengguna sahaja). tingkah laku dalam tempoh tetingkap, dan tidak memberi tumpuan kepada tingkah laku pengguna sebelum tetingkap Sebabnya ialah minat jangka panjang pengguna juga akan berubah secara perlahan dengan perubahan peringkat kehidupan Sebagai contoh, pengguna mungkin menyukai jenis tertentu filem selama satu atau dua tahun, dan kemudian tidak lagi menyukainya.
Selain itu, anda juga mungkin melihat bahawa formula ini adalah serupa dengan kaedah kemas kini kecerunan Adam dengan momentum Kami melaraskan saiz a untuk menjadikan kemas kini berat lebih fokus pada sejarah atau masa kini pada tahap tertentu. Khususnya, apabila diberi a yang lebih kecil, ia akan lebih memfokuskan pada masa kini, dan kemudian pengumpulan sejarah akan mempunyai pengecilan yang lebih besar.
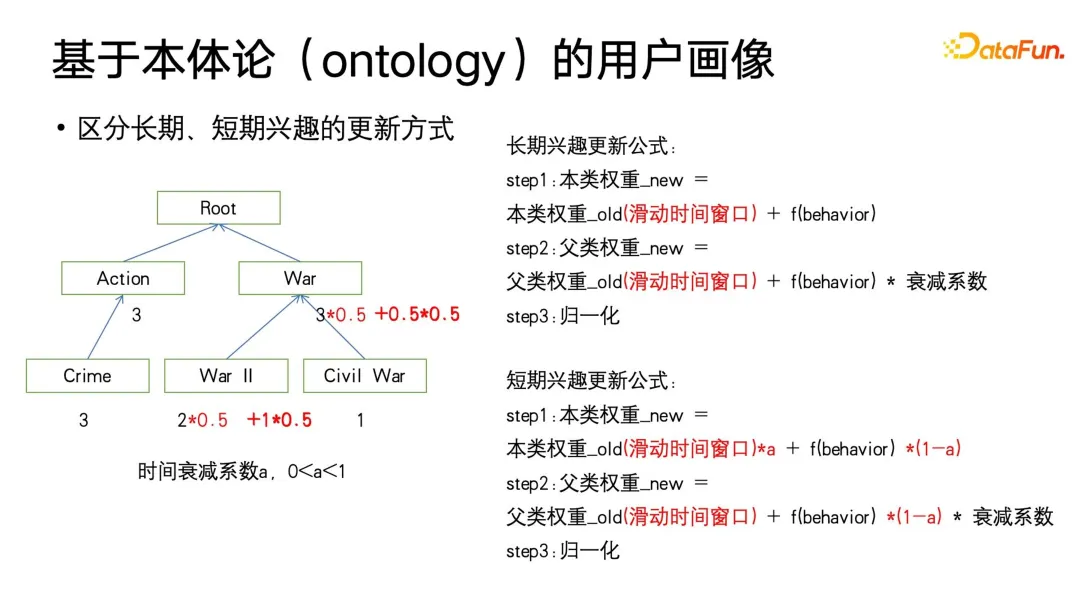
Metodologi di atas adalah terhad kepada maklumat yang telah diterima oleh pengguna, tetapi kami biasanya juga menghadapi sejumlah besar teg yang hilang, serta permulaan sejuk pengguna atau apabila pengguna mungkin tidak terdedah kepada ini kandungan tetapi ia tidak bermakna pengguna tidak menyukainya. Dalam kes ini, penyiapan faedah dan inferens faedah diperlukan.
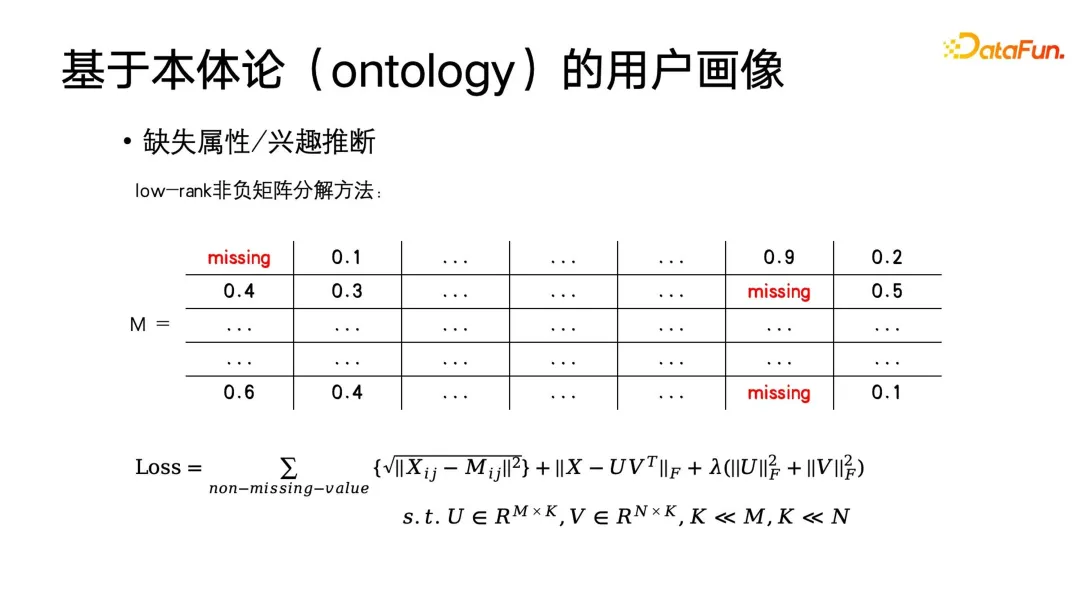
Kaedah yang paling asas ialah menggunakan penapisan kolaboratif dalam sistem pengesyoran untuk melengkapkan potret. Katakan terdapat matriks label Paksi mendatar ialah setiap label adalah respons pengguna terhadap label ini Minat, elemen ini boleh menjadi 0 atau 1, atau berat faedah. Sudah tentu, matriks ini juga boleh diubah untuk menyesuaikan diri dengan profil demografi Sebagai contoh, label boleh dinyatakan sebagai sama ada ia seorang pelajar, atau sama ada ia adalah seorang profesional, atau jenis pekerjaan, dll. Anda juga boleh menggunakan. kaedah pengekodan untuk membina matriks ini Anda juga boleh menggunakan penguraian matriks untuk mendapatkan penguraian matriks, dan kemudian melengkapkan nilai eigen yang hilang Pada masa ini, matlamat pengoptimuman adalah seperti yang ditunjukkan dalam rajah di bawah.
Seperti yang anda lihat dari formula ini, matriks asal ialah M, matriks penyiapan adalah matriks peringkat rendah, kerana kami mengandaikan bahawa kepentingan sebilangan besar pengguna adalah serupa di bawah andaian pengguna yang serupa, matriks label mestilah berpangkat rendah Akhirnya, penyelarasan dilakukan pada matriks ini untuk mencapai matlamat penguraian matriks bukan negatif. Kaedah ini sebenarnya boleh diselesaikan menggunakan kaedah penurunan kecerunan stokastik yang paling kita kenali.
Sudah tentu, selain membuat kesimpulan atribut atau minat yang hilang melalui penguraian matriks, kaedah pembelajaran mesin tradisional juga boleh digunakan. Ia masih diandaikan bahawa pengguna yang serupa akan mempunyai minat yang sama Pada masa ini, klasifikasi atau regresi KNN boleh digunakan untuk membuat kesimpulan minat Kaedah khusus adalah untuk mewujudkan peta perhubungan jiran terdekat pengguna, dan kemudian menambah tag atau tag dengan yang terbesar bilangan jiran antara k jiran terdekat pengguna Purata wajaran diberikan kepada atribut pengguna yang hilang. Graf perhubungan jiran boleh dibina sendiri atau ia boleh menjadi struktur graf jiran sedia, seperti potret pengguna rangkaian sosial, atau potret perniagaan sebelah B - peta perusahaan.

Di atas adalah pengenalan kepada pembinaan potret tradisional Ontologi. Nilai algoritma pembinaan potret tradisional ialah ia sangat mudah, langsung, mudah difahami, dan mudah dilaksanakan Pada masa yang sama, kesannya adalah baik, jadi ia tidak akan digantikan sepenuhnya oleh algoritma peringkat tinggi, terutamanya apabila kita perlu menyahpepijat potret Satu kelas algoritma tradisional akan mempunyai kemudahan yang lebih besar. . dengan menggabungkan algoritma pembelajaran mendalam Kesan algoritma pemprofilan. Apakah nilai pembelajaran mendalam kepada algoritma pemprofilan?
Pertama sekali, mesti ada keupayaan perwakilan pengguna yang lebih berkuasa Dalam bidang pembelajaran mendalam dan pembelajaran mesin, terdapat kategori khas - pembelajaran perwakilan, atau kaedah pembelajaran ini boleh membantu kita membina pembelajaran yang sangat berkuasa Perwakilan pengguna. Yang kedua ialah proses pemodelan yang lebih mudah Kita boleh menggunakan pendekatan pembelajaran mendalam dari hujung ke hujung untuk memudahkan proses pemodelan Dalam banyak kes, kita hanya perlu membina ciri, melakukan beberapa kejuruteraan ciri, dan kemudian menganggap rangkaian saraf sebagai kotak hitam ciri adalah input dan label atau maklumat penyeliaan lain ditakrifkan pada output tanpa memberi perhatian kepada butiran.
Sekali lagi, berdasarkan keupayaan ekspresi hebat pembelajaran mendalam, kami juga telah mencapai ketepatan yang lebih tinggi dalam banyak tugasan. Kemudian, pembelajaran mendalam juga boleh memodelkan data berbilang modal secara seragam. Dalam era algoritma tradisional, kita perlu menghabiskan banyak tenaga untuk prapemprosesan data Contohnya, pengekstrakan teg jenis video yang disebutkan di atas memerlukan prapemprosesan yang sangat kompleks Mula-mula potong video, kemudian ekstrak subjek, dan kemudian kenal pasti wajah di dalamnya satu demi satu Tambahkan tag yang sepadan, dan akhirnya bina potret. Dengan pembelajaran mendalam, apabila anda mahukan ekspresi pengguna atau item yang bersatu, anda boleh memproses data berbilang modal secara langsung dari hujung ke hujung.Akhir sekali, kami berharap dapat mengurangkan kos sebanyak mungkin semasa lelaran. Seperti yang dinyatakan dalam artikel sebelum ini, perbezaan antara lelaran algoritma pemprofilan dan lelaran jenis algoritma lain seperti promosi carian ialah ia memerlukan banyak penyertaan manual. Kadangkala data yang paling boleh dipercayai adalah data yang dianotasi oleh orang, atau dikumpul melalui soal selidik dan kaedah lain Kos untuk mendapatkan data ini agak tinggi, jadi bagaimana untuk mendapatkan data dengan nilai anotasi yang lebih pada kos yang lebih rendah? Masalah ini juga mempunyai lebih banyak idea dan penyelesaian dalam era pembelajaran mendalam.
2. Ramalan label berstruktur berdasarkan pembelajaran mendalam
C-HMCNN ialah kaedah pembelajaran mendalam klasik untuk meramalkan label berstruktur ontologi. Ia bukan rangka kerja rangkaian yang mewah, tetapi definisi yang sesuai untuk label, terutamanya untuk pengelasan atau ramalan label berstruktur.
Intinya adalah untuk meratakan teg berstruktur hierarki dan kemudian meramalkannya Seperti yang ditunjukkan di sebelah kanan rajah di bawah, rangkaian secara langsung memberikan kebarangkalian ramalan bagi tiga teg ABC tanpa mengambil kira tahap dan kedalaman struktur. Reka bentuk formula Kehilangannya juga boleh menghukum hasil yang melanggar teg berstruktur sebanyak mungkin Formula pertama menggunakan Kehilangan silang entropi klasik untuk kategori daun B dan C, dan maks(y
BpB untuk kategori induk , y.
Cp C
C
B, pC
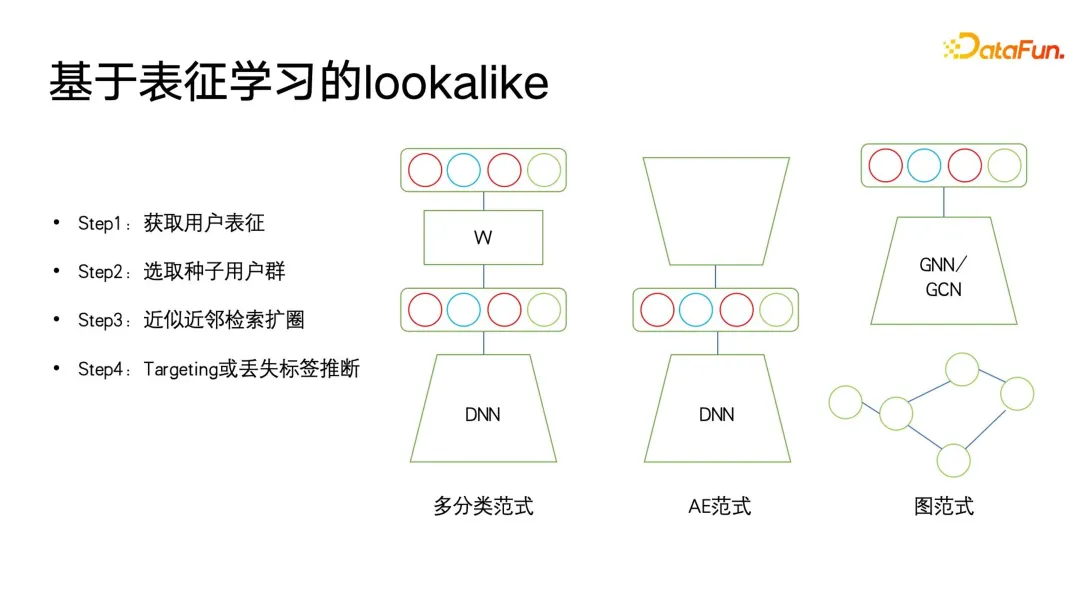
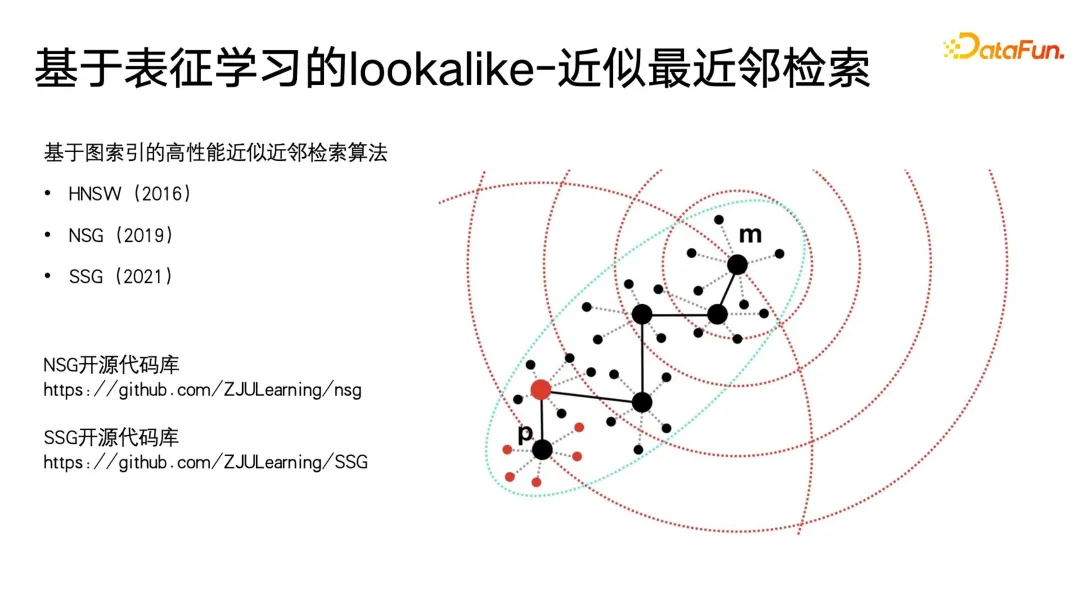
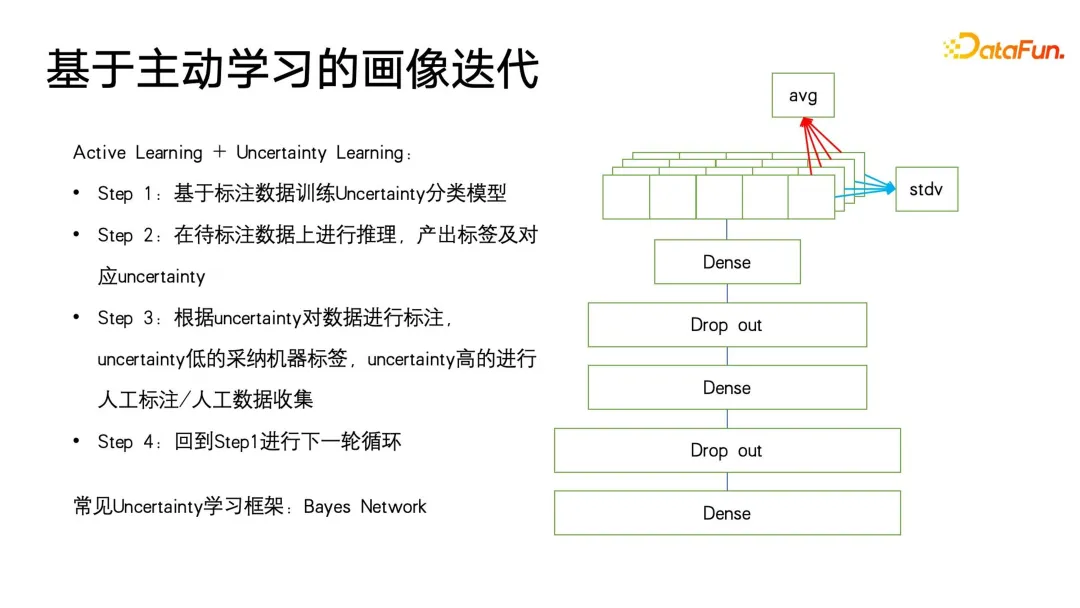
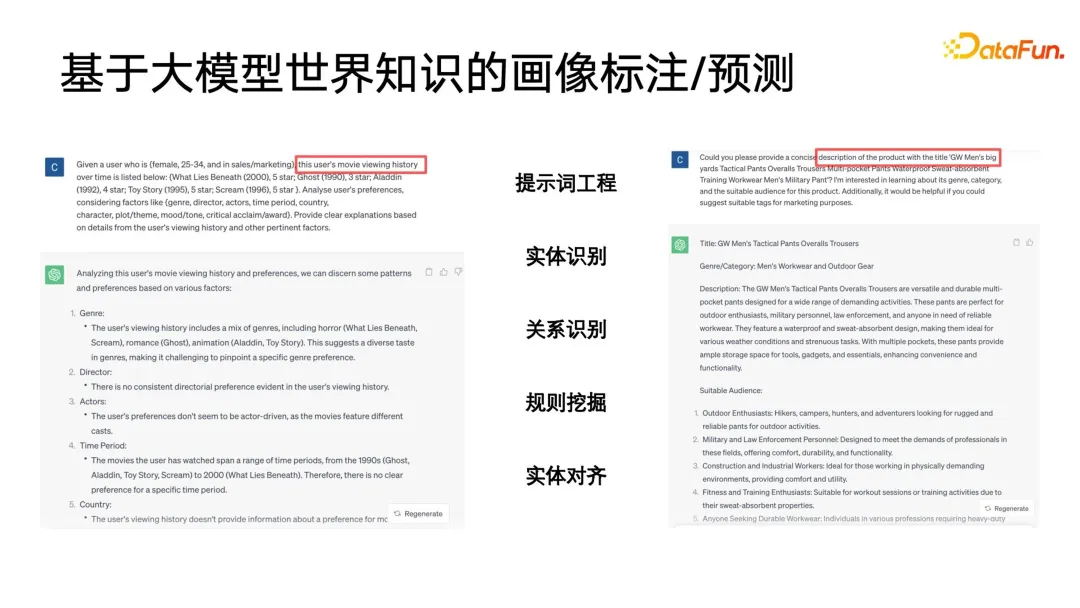
) Untuk menyatakan, apabila label sasaran kelas induk adalah palsu, ramalan kategori subkelas terpaksa sehampir 0 yang mungkin, dengan itu mencapai kekangan pada label berstruktur. Kelebihan pemodelan ini ialah pengiraan Kerugian adalah sangat mudah Ia meramalkan semua label secara sama rata dan hampir boleh mengabaikan maklumat kedalaman pepohon label.Perkara terakhir yang perlu dinyatakan ialah kaedah ini memerlukan setiap label adalah 0 atau 1. Contohnya, PB hanya mewakili sama ada pengguna suka atau tidak suka, dan tidak boleh ditetapkan kepada berbilang kategori, kerana RUGI kekangan berbilang kategori akan menjadi lebih Ia adalah sukar untuk ditubuhkan, jadi apabila memodelkan model ini, ia adalah bersamaan dengan meratakan semua label, dan kemudian membuat ramalan 0 dan 1. Satu masalah yang mungkin timbul daripada perataan ialah apabila label induk dalam struktur pokok label mempunyai sejumlah besar sub-label, ia akan menghadapi masalah klasifikasi berbilang label berskala besar Cara umum untuk menanganinya adalah dengan gunakan beberapa cara untuk menapis lebih awal pengguna mungkin tidak menyedarinya. Dalam aplikasi potret pengguna, idea serupa sering digunakan. Dalam aplikasi hiliran potret, lookalike boleh digunakan untuk menyasarkan kumpulan pengguna berpotensi untuk iklan juga boleh digunakan untuk mencari beberapa pengguna yang kehilangan atribut sasaran berdasarkan pengguna benih, dan kemudian atribut hilang yang sepadan bagi pengguna ini boleh digantikan atau dinyatakan. dengan pengguna benih. Apa yang paling diperlukan oleh aplikasi Lookalike ialah pelajar perwakilan yang berkuasa Seperti yang ditunjukkan dalam rajah di bawah, terdapat tiga jenis kaedah pemodelan perwakilan yang paling biasa digunakan. Yang pertama ialah kaedah berbilang klasifikasi Jika kita mempunyai data potret label klasifikasi berbilang, kita boleh mempelajari lebih banyak perwakilan disasarkan dengan isyarat yang diselia untuk jenis label tertentu yang ingin kita ramalkan berharga untuk label yang disasarkan tiada ramalan. Paradigma AE (auto encoder) Struktur model adalah dalam bentuk jam pasir, sebaliknya, anda hanya perlu mencari mod pengekodan , dan kemudian di tengah pinggang nipis Paradigma memampatkan maklumat dan mendapatkan perwakilan ini lebih dipercayai apabila tidak ada data penyeliaan yang mencukupi. Yang ketiga ialah paradigma graf Pada masa ini, rangkaian graf seperti GNN dan GCN digunakan dalam lebih banyak bidang, termasuk dalam potret Selain itu, GNN boleh dilatih tanpa pengawasan berdasarkan kaedah kemungkinan maksimum, atau ia boleh Latihan yang diselia dengan maklumat label dan mengatasi paradigma pelbagai klasifikasi. Kerana selain menyatakan maklumat label, struktur graf juga boleh membenamkan lebih banyak maklumat struktur graf. Apabila tiada struktur graf yang dipaparkan, terdapat banyak cara untuk membina graf Contohnya, swing i2i, algoritma pengesyoran yang terkenal dalam medan e-dagang, membina graf dwipartit berdasarkan pembelian bersama pengguna atau rekod tontonan bersama. . Struktur graf sedemikian juga sangat kaya Maklumat semantik boleh membantu kami mempelajari perwakilan pengguna yang lebih baik. Selepas kami mempunyai perwakilan yang kaya, kami boleh memilih beberapa pengguna benih untuk menggunakan carian jiran terdekat untuk mengembangkan kalangan, dan kemudian menggunakan pengguna yang dikembangkan untuk membuat kesimpulan teg atau sasaran yang hilang. Sangat mudah untuk melakukan pencarian jiran terdekat pada aplikasi berskala kecil, tetapi pada data berskala yang sangat besar, seperti platform besar dengan ratusan juta pengguna aktif bulanan, ia adalah masalah untuk melaksanakan KNN pengambilan semula pada pengguna ini sangat memakan masa, jadi kaedah yang paling biasa digunakan pada masa ini adalah anggaran pengambilan jiran terdekat, yang dicirikan dengan menukar ketepatan untuk kecekapan Ia memastikan ketepatan hampir 99% sambil memampatkan masa perolehan kepada 1/. 1000, 1/1 daripada pengambilan semula ganas yang asal, atau 1/100000. Pada masa ini, kaedah yang berkesan untuk mendapatkan semula jiran terdekat adalah algoritma mendapatkan semula vektor berdasarkan indeks graf Kaedah ini telah ditolak ke klimaks dalam era model besar semasa, yang merupakan konsep paling popular dalam beberapa model besar. masa lalu. -- RAG (Retrieval Enhancement Generation). Dua yang terakhir Kod sumber terbuka asal dan pautan pelaksanaan juga diletakkan dalam rajah di bawah. Dalam proses lelaran potret, masih terdapat beberapa titik buta yang tidak boleh ditutup Contohnya, beberapa potret pengguna dengan tingkah laku penggunaan rendah masih tidak sangat baik. Pada akhirnya, banyak kaedah masih akan kembali kepada kaedah pengumpulan manual. Walau bagaimanapun, kami mempunyai begitu ramai pengguna aktiviti rendah Jika kami hanya boleh memilih pengguna yang lebih berharga dan mewakili untuk pelabelan, kami boleh mengumpul data yang lebih berharga Oleh itu, kami telah memperkenalkan rangka kerja pembelajaran yang aktif . Pertama, berdasarkan data beranotasi sedia ada, latih model klasifikasi dengan ramalan ketidakpastian Kaedah yang digunakan ialah kaedah klasik dalam bidang pembelajaran probabilistik - rangkaian Bayesian. Ciri-ciri rangkaian Bayesian ialah apabila meramal, ia bukan sahaja dapat memberikan kebarangkalian, tetapi juga meramalkan ketidakpastian hasil ramalan. Rangkaian Bayesian sangat mudah untuk dilaksanakan, seperti yang ditunjukkan di sebelah kanan rajah di bawah Hanya tambahkan beberapa lapisan khas pada struktur rangkaian asal Kami menambah beberapa lapisan tercicir di tengah rangkaian ini untuk menggugurkan secara rawak rangkaian suapan hadapan. Rangkaian Bayesian mengandungi berbilang sub-rangkaian, yang setiap satunya mempunyai parameter rangkaian yang sama Namun, disebabkan oleh ciri-ciri lapisan tercicir, kebarangkalian setiap parameter rangkaian digugurkan secara rawak adalah berbeza apabila digugurkan secara rawak dilatih untuk inferens juga dikekalkan apabila menggunakan keciciran, yang berbeza daripada cara keciciran digunakan dalam bidang lain. Dalam bidang lain, keciciran hanya dilakukan semasa latihan, dan semua parameter digunakan semasa inferens Hanya apabila nilai logit dan kebarangkalian akhirnya dikira, penggandaan skala bagi nilai ramalan yang disebabkan oleh keciciran dipulihkan. Perbezaan antara rangkaian Bayesian ialah semua kes rawak yang tercicir mesti dikekalkan semasa inferens suapan hadapan, supaya setiap rangkaian akan memberikan kebarangkalian yang berbeza bagi label ini, dan kemudian mengira set kebarangkalian ini Min sebenarnya adalah hasil daripada undian dan nilai kebarangkalian yang ingin kita ramalkan Pada masa yang sama, pengiraan varians dilakukan pada set nilai kebarangkalian ini untuk menyatakan ketidakpastian ramalan. Apabila sampel mengalami ekspresi parameter keciciran yang berbeza, nilai kebarangkalian akhir yang diperoleh adalah berbeza Semakin besar varians nilai kebarangkalian, semakin kecil kepastian kebarangkalian dalam proses pembelajaran. Akhir sekali, sampel ramalan label dengan ketidakpastian yang tinggi boleh dilabel secara manual, dan untuk label dengan kepastian tinggi, hasil pelabelan mesin boleh diterima pakai secara langsung. Kemudian teruskan kembali ke langkah pertama kerangka pembelajaran aktif untuk kitaran di atas adalah kerangka asas pembelajaran aktif. Dalam era model besar, pengetahuan dunia tentang model besar juga boleh diperkenalkan untuk anotasi potret. Rajah berikut memberikan dua contoh mudah Di sebelah kiri, model besar digunakan untuk menganotasi potret pengguna, dan sejarah tontonan pengguna disusun dalam urutan tertentu untuk membentuk gesaan. Anda akan melihat bahawa model besar boleh memberikan yang sangat terperinci analisis, seperti Apakah genre, pengarah, pelakon, dsb. yang mungkin disukai pengguna. Di sebelah kanan ialah model besar yang menganalisis tajuk produk dan memberikan tajuk produk untuk model besar meneka kategori mana ia tergolong. Pada ketika ini kami telah mendapati bahawa masalah besar ialah output model besar tidak berstruktur, ungkapan teks yang agak primitif dan memerlukan beberapa pemprosesan pasca. Sebagai contoh, adalah perlu untuk melaksanakan pengiktirafan entiti, pengiktirafan perhubungan, perlombongan peraturan, penjajaran entiti, dll. pada output model besar, dan pemprosesan pasca ini tergolong dalam peraturan aplikasi asas dalam kategori graf pengetahuan atau ontologi. Mengapa menggunakan pengetahuan dunia tentang model besar untuk anotasi imej mempunyai hasil yang lebih baik, malah boleh menggantikan sebahagian daripada kerja? Oleh kerana model besar dilatih pada rangkaian luas pengetahuan rangkaian terbuka, manakala sistem pengesyoran, enjin carian, dsb. hanya mempunyai beberapa data interaksi sejarah antara pengguna dan pustaka produk dalam platform tertutup mereka sendiri Data ini sebenarnya berasaskan ID , yang kebanyakannya saling berkaitan, sukar untuk ditafsir melalui pengetahuan tertutup dalam platform sedia ada, tetapi pengetahuan dunia model besar boleh membantu kami mengisi pengetahuan yang hilang dalam sistem tertutup, dengan itu membantu kami melukis yang lebih baik. pelabelan potret atau ramalan. Model besar bahkan boleh difahami sebagai gambaran abstrak berkualiti tinggi bagi sistem konsep dunia itu sendiri. Sistem konsep ini sangat sesuai untuk sistem potret dan label.
Akhir sekali, mari kita ringkaskan secara ringkas hala tuju pembangunan dan had masa hadapan pengguna. Soalan pertama ialah bagaimana untuk meningkatkan lagi ketepatan imej sedia ada. Faktor yang menghalang peningkatan ketepatan termasuk aspek berikut Yang pertama ialah penyatuan daripada ID maya kepada orang asli Pada hakikatnya, pengguna mempunyai berbilang peranti untuk log masuk ke akaun yang sama, dan mungkin juga mempunyai berbilang port dan saluran log masuk. Contohnya, pengguna Log masuk ke APP yang berbeza, tetapi APP ini tergolong dalam kumpulan yang sama Bolehkah kita menghubungkan orang asli dalam kumpulan, memetakan semua ID maya kepada orang yang sama, dan kemudian mengenal pastinya? Yang kedua ialah isu pengenalan subjek untuk akaun kongsi keluarga. Masalah ini sangat biasa dalam bidang video, terutamanya dalam bidang video panjang Kami sering menghadapi beberapa kes yang buruk keluarga berkongsi akaun Kepentingan peribadi adalah berbeza. Sebagai tindak balas kepada situasi ini, bolehkah kita menggunakan beberapa cara untuk mengenal pasti masa semasa dan corak tingkah laku, untuk mengemas kini potret dengan cepat dan dalam masa nyata, kemudian menentukan siapa subjek semasa, dan kemudian menyediakan perkhidmatan diperibadikan yang disasarkan. Yang ketiga ialah ramalan niat masa nyata bagi kaitan pelbagai senario. Kami mendapati bahawa apabila platform telah berkembang ke peringkat tertentu, carian dan imej promosinya masih agak berpecah-belah Contohnya, kadangkala pengguna baru sahaja melangkah ke adegan yang disyorkan dan kini bersedia untuk mencari yang lebih baik pada niat masa nyata adegan yang disyorkan sebentar tadi Jika anda mencari perkataan yang disyorkan, atau baru sahaja mencari sesuatu, bolehkah anda menggunakan niat ini untuk menyebarkan dan meramalkan beberapa kategori perkara lain yang mungkin ingin dilihat oleh pengguna dan buat ramalan niat. Peralihan daripada ontologi tertutup kepada ontologi terbuka juga merupakan isu yang perlu diselesaikan segera dalam bidang pengimejan. Untuk masa yang lama, beberapa piawaian industri yang agak kukuh digunakan untuk mentakrifkan ontologi, tetapi kini ontologi banyak sistem terbuka sepenuhnya kepada kemas kini tambahan, seperti platform video pendek, dan pelbagai teg video pendek itu sendiri tumbuh dan meletup secara spontan di bawah ciptaan bersama Terdapat banyak perkataan panas dan tag panas yang terus muncul seiring dengan berlalunya masa. Cara meningkatkan ketepatan masa imej pada Ontologi terbuka, mengalih keluar hingar, dan kemudian meneroka lebih banyak lagi dan menggunakan beberapa kaedah untuk membantu kami meningkatkan ketepatan imej juga merupakan persoalan yang patut dikaji. Akhir sekali, dalam era pembelajaran mendalam, cara meningkatkan kebolehtafsiran dalam algoritma pemprofilan, terutamanya algoritma pemprofilan yang menggunakan pembelajaran mendalam, dan cara untuk melaksanakan model besar dalam algoritma pemprofilan dengan lebih baik, ini akan menjadi Arah untuk penyelidikan masa depan. Di atas adalah kandungan yang dikongsikan kali ini, terima kasih semua! A1: Pautan aplikasi untuk potret sememangnya agak panjang. Jika potret anda menggunakan algoritma terutamanya, maka memang terdapat jurang kehilangan ketepatan daripada ketepatan potret kepada model hiliran. Sebenarnya, saya tidak mengesyorkan melakukan ujian potret AB, saya rasa kaedah aplikasi yang lebih baik ialah pergi ke kakitangan operasi, dan menggunakannya dalam pemilihan pengguna dan pengiklanan pelaburan tetap dan senario aplikasi lain yang lebih beroperasi, seperti kupon untuk. jualan besar. Menjalankan Ujian AB dalam senario seperti penghantaran yang disasarkan. Oleh kerana kesannya adalah berdasarkan potret anda secara langsung, anda boleh mempertimbangkan ujian AB dalam talian kolaboratif sebelah aplikasi ini dengan pautan yang agak pendek. Di samping itu, saya mungkin mencadangkan bahawa sebagai tambahan kepada ujian AB, kami juga mempertimbangkan kaedah ujian lain - pengesahan silang, untuk mengesyorkan kepada pengguna hasil pengisihan berdasarkan imej sebelum dan selepas pengoptimuman, dan kemudian biarkan pengguna menilai yang mana satu lebih baik. Sebagai contoh, kini kita boleh melihat bahawa sesetengah pengeluar model besar akan membenarkan model mengeluarkan dua hasil, dan kemudian membenarkan pengguna memutuskan model besar yang mana menghasilkan teks yang lebih baik. Malah, saya fikir semak silang seperti ini mungkin lebih berkesan, dan ia berkaitan secara langsung dengan potret itu sendiri. A2: Ia tidak bermakna terdapat keciciran pada set ujian, tetapi ia bermakna apabila menguji inferens, kita masih akan mengekalkan ciri rawak keciciran dalam rangkaian untuk inferens rawak. A3: Terus terang, pada masa ini tiada penyelesaian yang sangat baik dalam industri. Tetapi mungkin terdapat dua cara iaitu dengan mempertimbangkan pihak ketiga yang saling dipercayai untuk melakukan penempatan inferens bagi model besar setempat. Satu lagi, dan juga baru-baru ini, konsep baru dipanggil rangkaian bersekutu, yang bukan pembelajaran bersekutu Anda boleh melihat beberapa kemungkinan yang terkandung dalam rangkaian bersekutu. A4: Sebagai tambahan kepada anotasi, terdapat juga beberapa analisis dan penaakulan daripada pengguna. Berdasarkan potret sedia ada, kami boleh menyimpulkan niat pengguna seterusnya, atau kami boleh mengumpul sejumlah besar data pengguna dan menggunakan model besar untuk menganalisis beberapa corak pengguna serantau atau lain di bawah kekangan. Malah, terdapat beberapa demo sumber terbuka untuk ini, anda boleh meneroka arah ini. 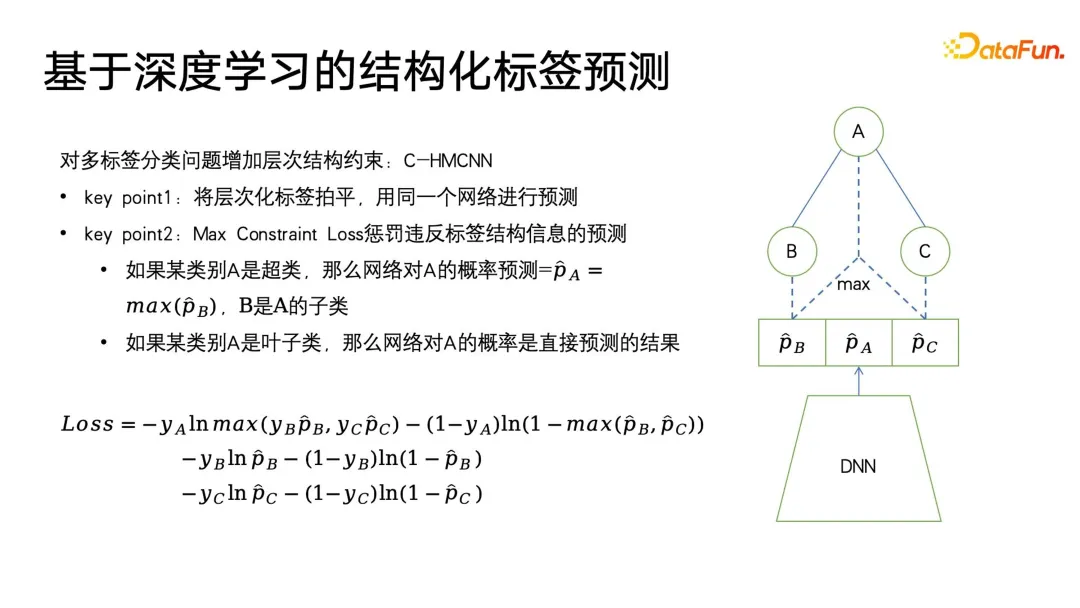
3. Serupa berdasarkan pembelajaran perwakilan
4. Lelaran potret berdasarkan pembelajaran aktif
5. Anotasi potret/ramalan berdasarkan pengetahuan dunia model besar
4. Ringkasan dan Pandangan

5. Soal Jawab
S1: Pautan antara pemprosesan potret dan aplikasi praktikal adalah sangat panjang. Mungkin terdapat banyak masalah dengan kesan penerimaan menggunakan ujian AB dalam perniagaan sebenar pada ujian AB potret Adakah anda mempunyai pengalaman untuk dikongsi?
S2: Adakah terdapat keciciran pada set ujian rangkaian Bayesian?
S3: Mempertimbangkan isu privasi dan keselamatan, cara menggunakan hasil model besar apabila data pelanggan tidak boleh dieksport.
S4: Selain pelabelan, adakah kombinasi lain yang boleh anda nyatakan apabila digabungkan dengan model besar?
Atas ialah kandungan terperinci Algoritma pemprofilan pengguna: sejarah, situasi semasa dan masa depan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!