
Rumah >Peranti teknologi >AI >Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?

- 王林ke hadapan
- 2024-04-08 21:31:111252semak imbas
Jika anda telah memberi perhatian kepada seni bina model bahasa besar, anda mungkin pernah melihat istilah "SwiGLU" dalam model dan kertas penyelidikan terkini. SwiGLU boleh dikatakan sebagai fungsi pengaktifan yang paling biasa digunakan dalam model bahasa besar Kami akan memperkenalkannya secara terperinci dalam artikel ini. SwiGLU sebenarnya adalah fungsi pengaktifan yang dicadangkan oleh Google pada tahun 2020, yang menggabungkan ciri-ciri SWISH dan GLU. Nama penuh Cina SwiGLU ialah "unit linear berpagar dua arah". Ia mengoptimumkan dan menggabungkan dua fungsi pengaktifan, SWISH dan GLU, untuk meningkatkan keupayaan ekspresi tak linear model. SWISH ialah fungsi pengaktifan yang sangat biasa yang digunakan secara meluas dalam model bahasa besar, manakala GLU berfungsi dengan baik dalam tugas pemprosesan bahasa semula jadi. Kelebihan SwiGLU ialah ia boleh memperoleh ciri pelicinan SWISH dan ciri gating GLU pada masa yang sama, sekali gus menjadikan ekspresi tak linear model lebih

Kami akan memperkenalkannya satu persatu:
Swish
Swish ialah fungsi pengaktifan tak linear, ditakrifkan seperti berikut:
Swish(x) = x*sigmoid(ßx)
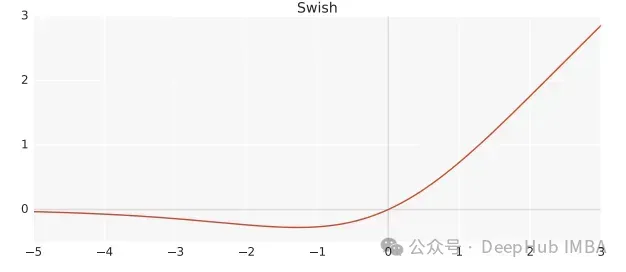
di mana, ß ialah parameter yang boleh dipelajari. Swish boleh menjadi lebih baik daripada fungsi pengaktifan ReLU kerana ia memberikan peralihan yang lebih lancar yang boleh membawa kepada pengoptimuman yang lebih baik.
Unit Linear Berpagar
GLU (Unit Linear Berpagar) ditakrifkan sebagai produk komponen dua transformasi linear, satu daripadanya diaktifkan oleh sigmoid.
GLU(x) = sigmoid(W1x+b)⊗(Vx+c)
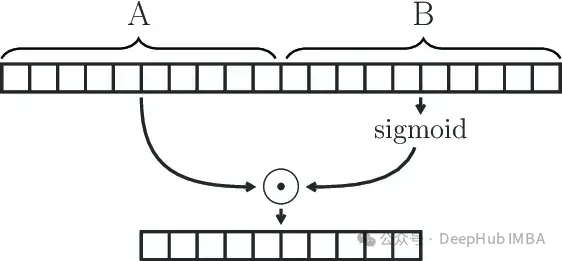
Modul GLU secara berkesan boleh menangkap kebergantungan jarak jauh dalam jujukan sambil mengelakkan beberapa masalah kecerunan yang lenyap yang dikaitkan dengan mekanisme gating lain seperti LSTM dan GRU.
SwiGLU
Kami telah pun mengatakan bahawa SwiGLU adalah gabungan kedua-duanya. Ia adalah GLU, tetapi daripada menggunakan sigmoid sebagai fungsi pengaktifan, kami menggunakan swish dengan ß=1, jadi kami berakhir dengan formula berikut:
SwiGLU(x) = Swish(W1x+b)⊗(Vx+c)
Kami menggunakan fungsi SwiGLU untuk membina rangkaian feedforward
FFNSwiGLU(x) = (Swish1(xW)⊗xV)W2
Pelaksanaan mudah Pytorch
Jika prinsip matematik di atas kelihatan menyusahkan dan membosankan, kami akan menerangkannya terus menggunakan kod di bawah.
class SwiGLU(nn.Module): def __init__(self, w1, w2, w3) -> None:super().__init__()self.w1 = w1self.w2 = w2self.w3 = w3 def forward(self, x):x1 = F.linear(x, self.w1.weight)x2 = F.linear(x, self.w2.weight)hidden = F.silu(x1) * x2return F.linear(hidden, self.w3.weight)
Fungsi F.silu yang digunakan dalam kod kami adalah sama seperti swish apabila ß=1, jadi kami menggunakannya secara langsung.
Anda boleh lihat dari kod tersebut terdapat 3 pemberat dalam fungsi pengaktifan kami yang boleh dilatih iaitu parameter dari formula GLU.
Perbandingan Kesan SwiGLU
Membandingkan SwiGLU dengan varian GLU yang lain, kita dapat melihat bahawa SwiGLU menunjukkan prestasi yang lebih baik semasa kedua-dua tempoh pra-latihan.
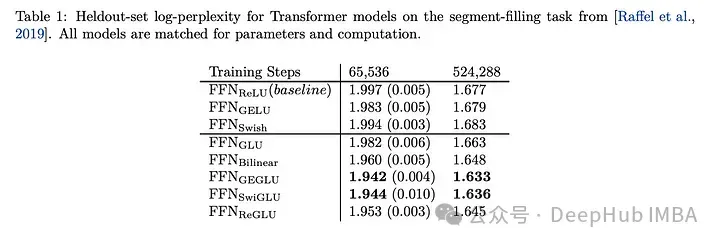
Tugas hiliran
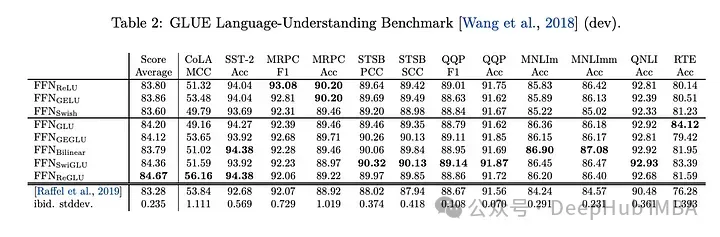
mempunyai prestasi terbaik, jadi sekarang llm, seperti LLAMA, OLMO dan PALM semuanya menggunakan SwiGLU dalam pelaksanaannya. Tetapi mengapa SwiGLU lebih baik daripada yang lain?
Kertas itu hanya memberikan keputusan ujian dan tidak menjelaskan sebab sebaliknya, ia berkata:
Kami tidak memberikan penjelasan mengapa seni bina ini nampaknya berkesan, seperti yang lain. kepada ihsan ilahi.
Penulis berkata bahawa alkimia itu berjaya.
Tetapi sekarang sudah 2024 dan kami boleh menerangkannya dengan tegas:
1 Respons Swish yang agak kecil terhadap nilai negatif mengatasi kekurangan ReLU bahawa output pada sesetengah neuron sentiasa sifar
. Ciri-ciri gating GLU, yang bermaksud bahawa ia boleh memutuskan maklumat mana yang harus diluluskan dan maklumat mana yang harus ditapis berdasarkan situasi input. Mekanisme ini membolehkan rangkaian mempelajari perwakilan berguna dengan lebih berkesan dan membantu meningkatkan keupayaan generalisasi model. Dalam model bahasa yang besar, ini amat berguna untuk memproses jujukan teks yang panjang dengan kebergantungan jarak jauh.3 Parameter W1, W2, W3, b1, b2, b3 dalam SwiGLU boleh dipelajari melalui latihan, supaya model boleh melaraskan parameter ini secara dinamik mengikut tugasan dan set data yang dipertingkatkan.
4. Kecekapan pengiraan adalah lebih tinggi daripada beberapa fungsi pengaktifan yang lebih kompleks (seperti GELU), sambil mengekalkan prestasi yang baik. Ini merupakan pertimbangan penting untuk latihan dan inferens model bahasa berskala besar.
Pilih SwiGLU sebagai fungsi pengaktifan model bahasa besar, terutamanya kerana ia menggabungkan kelebihan keupayaan tak linear, ciri gating, kestabilan kecerunan dan parameter yang boleh dipelajari. SwiGLU diterima pakai secara meluas kerana prestasi cemerlangnya dalam mengendalikan hubungan semantik yang kompleks dan masalah pergantungan yang lama dalam model bahasa, serta mengekalkan kestabilan latihan dan kecekapan pengiraan.
Alamat kertas
Atas ialah kandungan terperinci Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Seruan ICML untuk kertas melarang penggunaan model bahasa besar yang dikemukakan LeCun: Bolehkah model bersaiz kecil dan sederhana digunakan?
- Meta melancarkan model bahasa AI LLaMA, model bahasa berskala besar dengan 65 bilion parameter
- Enam cara untuk membina chatbot AI dan model bahasa yang besar untuk meningkatkan keselamatan siber
- Bina pangkalan pengetahuan AI model bahasa yang besar dalam masa tiga minit sahaja
- Eksekutif Lenovo mendedahkan: Moto razr baharu tahun depan akan mempunyai reka bentuk yang lebih menakjubkan dan interaksi AI, dan perdana siri X akan menambah keupayaan model bahasa yang besar