
Rumah >Peranti teknologi >AI >Terlalu lengkap! Kajian semula pembelajaran mendalam multimodal!
Terlalu lengkap! Kajian semula pembelajaran mendalam multimodal!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-08 09:10:02979semak imbas
1. Pengenalan
Pengalaman kita di dunia adalah multimodal - kita melihat objek, mendengar bunyi, merasakan tekstur, bau dan rasa. Modaliti merujuk kepada cara keadaan tertentu berlaku atau dialami, dan apabila soalan penyelidikan mengandungi pelbagai modaliti, ia dicirikan sebagai multimodal. Untuk AI membuat kemajuan dalam memahami dunia di sekeliling kita, ia perlu dapat mentafsir isyarat multimodal ini secara serentak.
Sebagai contoh, imej sering dikaitkan dengan tag dan penjelasan teks, dan teks mengandungi imej untuk menyatakan idea utama artikel dengan lebih jelas. Modaliti yang berbeza mempunyai sifat statistik yang sangat berbeza. Data ini dipanggil data besar multimodal dan mengandungi maklumat multimodal dan cross-modal yang kaya, yang menimbulkan cabaran besar kepada kaedah gabungan data tradisional.
Dalam semakan ini, kami akan memperkenalkan beberapa model pembelajaran mendalam yang inovatif untuk menggabungkan data besar pelbagai mod ini. Memandangkan data besar multimodal semakin diterokai, masih terdapat beberapa cabaran yang perlu ditangani. Oleh itu, artikel ini menyediakan ulasan tentang pembelajaran mendalam untuk gabungan data multimodal, yang bertujuan untuk menyediakan pembaca (tanpa mengira komuniti asal mereka) dengan prinsip asas kaedah gabungan pembelajaran mendalam multimodal dan memberi inspirasi kepada jenis data multimodal baharu untuk teknologi Fusion pembelajaran mendalam.
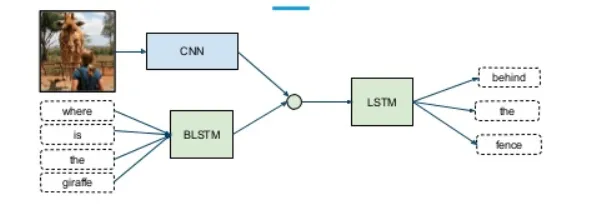
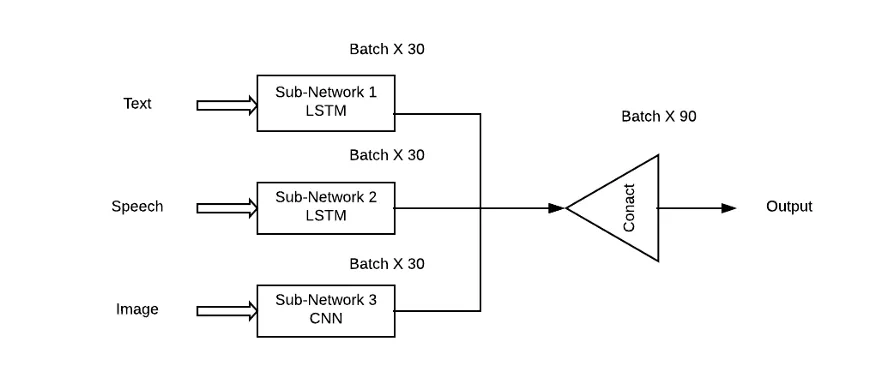
Masalah dengan pendekatan ini ialah ia akan memberikan kepentingan yang sama kepada semua sub-rangkaian/corak, yang sangat tidak mungkin dalam situasi dunia sebenar. Gabungan wajaran sub-rangkaian perlu digunakan di sini supaya setiap modaliti input boleh mempunyai sumbangan pembelajaran (Theta) kepada ramalan output. 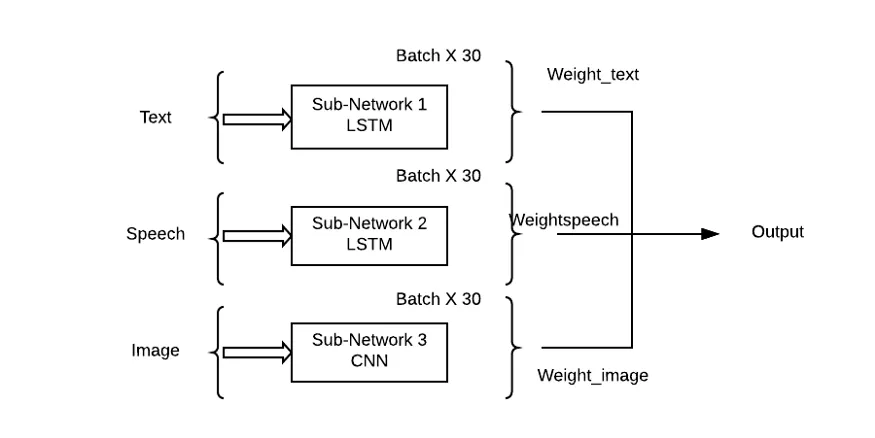
2. Seni bina pembelajaran mendalam perwakilan
Dalam bahagian ini, kami akan memperkenalkan seni bina pembelajaran mendalam yang mewakili model pembelajaran mendalam gabungan data pelbagai mod. Secara khusus, takrifan seni bina dalam, pengiraan suapan hadapan dan pengiraan perambatan belakang, serta variasi tipikal diberikan. Model perwakilan diringkaskan.
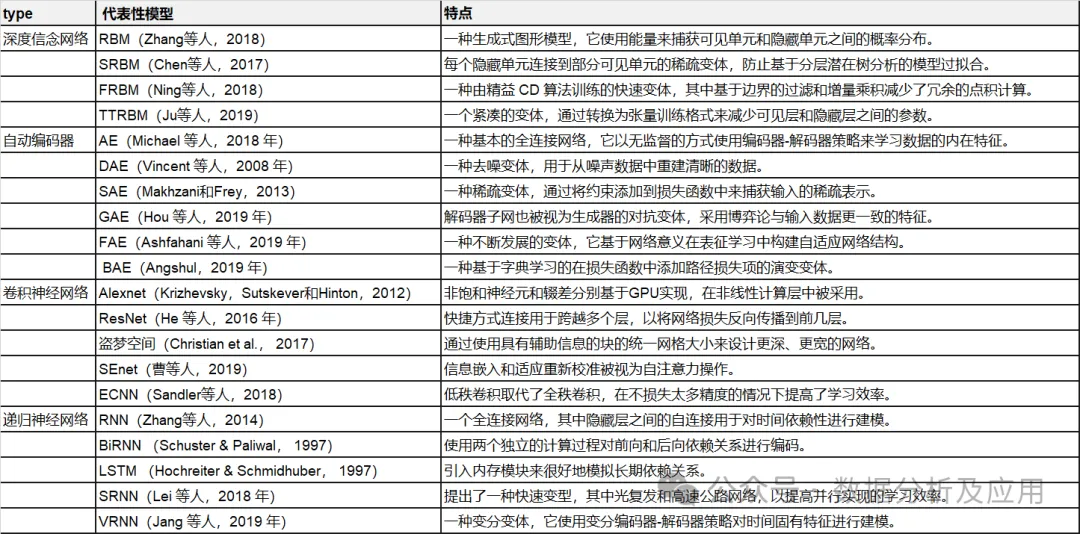
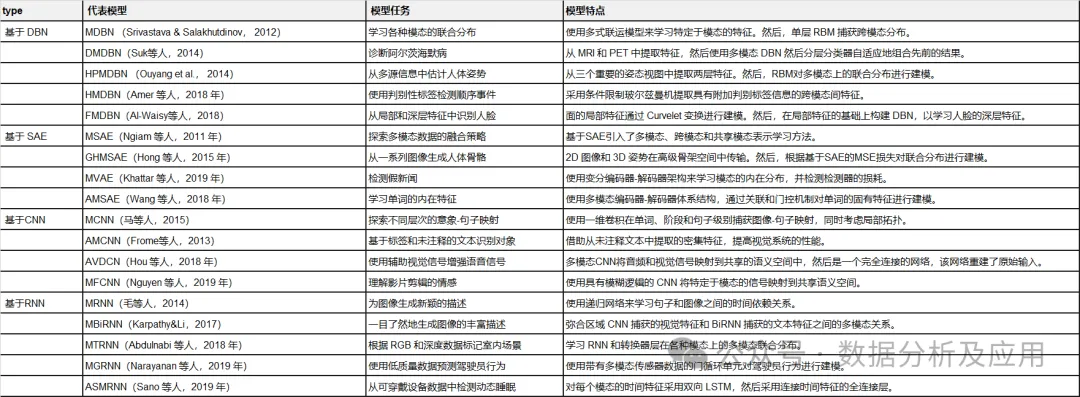
Jadual 1: Ringkasan model pembelajaran mendalam yang mewakili.
2.1 Deep Belief Network (DBN)
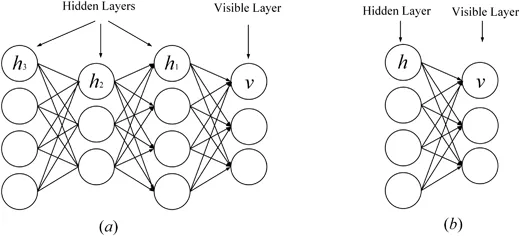
Restricted Boltzmann Machine (RBM) ialah blok asas rangkaian kepercayaan mendalam (Zhang, Ding, Zhang, & Xue, 2018; Bengio, 2009). RBM ialah varian khas mesin Boltzmann (lihat Rajah 1), yang terdiri daripada lapisan kelihatan dan lapisan tersembunyi terdapat sambungan penuh antara lapisan kelihatan dan lapisan tersembunyi, tetapi tiada sambungan antara unit dalam yang sama; lapisan. RBM juga merupakan model generatif yang menggunakan fungsi tenaga untuk menangkap taburan kebarangkalian antara unit kelihatan dan tersembunyi. Dengan menggunakan derivatif fungsi tenaga, taburan kebarangkalian unit antara unit yang kelihatan dan tersembunyi boleh dikira. RBM boleh menangkap taburan kebarangkalian antara elemen individu dan unit tersembunyi. Tiada sambungan antara unit dalam RBM, kecuali tiada sambungan antara unit dalam lapisan yang sama, dan semua unit disambungkan melalui sambungan penuh. RBM juga menggunakan fungsi tenaga untuk mengira taburan kebarangkalian antara unit kelihatan dan tersembunyi. Menggunakan fungsi kebarangkalian RBM, taburan kebarangkalian antara unit boleh ditangkap.
Baru-baru ini, beberapa RBM canggih telah dicadangkan untuk meningkatkan prestasi. Sebagai contoh, untuk mengelakkan lampiran rangkaian, Chen, Zhang, Yeung, dan Chen (2017) mereka bentuk mesin Boltzmann yang jarang yang mempelajari struktur rangkaian berdasarkan pokok pendam hierarki. Ning, Pittman, dan Shen (2018) memperkenalkan algoritma divergensi kontrastif pantas ke dalam RBM, di mana penapisan berasaskan sempadan dan produk delta digunakan untuk mengurangkan pengiraan produk titik berlebihan dalam pengiraan. Untuk melindungi struktur dalaman data multidimensi, Ju et al (2019) mencadangkan tensor RBM untuk mempelajari taburan peringkat tinggi yang tersembunyi dalam data multidimensi, di mana penguraian tensor digunakan untuk mengelakkan kutukan dimensi.
DBM ialah seni bina dalam yang tipikal, yang disusun oleh berbilang RBM (Hinton & Salakhutdinov, 2006). Ia adalah model generatif berdasarkan strategi latihan pra-latihan dan penalaan halus yang boleh memanfaatkan tenaga untuk menangkap pengedaran sambungan antara objek yang boleh dilihat dan label yang sepadan. Dalam pra-latihan, setiap lapisan tersembunyi dimodelkan secara rakus sebagai RBM yang dilatih dalam dasar tanpa pengawasan. Selepas itu, setiap lapisan tersembunyi dilatih lagi melalui maklumat diskriminasi label latihan dalam strategi yang diselia. DBN telah digunakan untuk menyelesaikan masalah dalam banyak bidang, seperti pengurangan dimensi data, pembelajaran perwakilan dan pencincangan semantik. DBM wakil ditunjukkan dalam Rajah 1. Rajah 1 18; , Lu, Tan, dan Zhou, 2016). Ia boleh menangkap ciri ringkas input dengan mengubah input asal menjadi perwakilan perantaraan dengan cara yang tidak diawasi. SAE telah digunakan secara meluas dalam banyak bidang, termasuk pengurangan dimensi (Wang, Yao, & Zhao, 2016), pengecaman imej (Jia, Shao, Li, Zhao, & Fu, 2018) dan pengelasan teks (Chen & Zaki, 2017). Rajah 2 menunjukkan wakil SAE.
Rajah 2:
2.3 Convolutional Neural Network (CNN)
DBN dan SAE ialah rangkaian neural yang disambungkan sepenuhnya. Dalam kedua-dua rangkaian, setiap neuron dalam lapisan tersembunyi disambungkan kepada setiap neuron dalam lapisan sebelumnya, dan topologi ini mencipta sejumlah besar sambungan. Untuk melatih berat sambungan ini, rangkaian saraf yang disambungkan sepenuhnya memerlukan sejumlah besar objek latihan untuk mengelakkan pemasangan berlebihan dan kekurangan, yang memerlukan pengiraan intensif. Di samping itu, topologi bersambung sepenuhnya tidak mengambil kira maklumat kedudukan ciri-ciri yang terkandung di antara neuron. Oleh itu, rangkaian saraf dalam yang disambungkan sepenuhnya (DBN, SAE dan variannya) tidak dapat mengendalikan data berdimensi tinggi, terutamanya imej besar dan data audio yang besar.
Rangkaian saraf konvolusi ialah rangkaian dalam khas yang mengambil kira topologi setempat data (Li, Xia, Du, Lin, & Samat, 2017; Sze, Chen, Yang, & Emer, 2017). Rangkaian saraf konvolusi termasuk rangkaian bersambung sepenuhnya dan rangkaian terhad yang mengandungi lapisan konvolusi dan lapisan gabungan. Rangkaian terkekang menggunakan operasi lilitan dan pengumpulan untuk mencapai medan penerimaan tempatan dan pengurangan parameter. Seperti DBN dan SAE, rangkaian saraf konvolusi dilatih melalui algoritma penurunan kecerunan stokastik. Ia telah membuat kemajuan besar dalam pengecaman imej perubatan (Maggiori, Tarabalka, Charpiat, & Alliez, 2017) dan analisis semantik (Hu, Lu, Li, & Chen, 2014). Wakil CNN ditunjukkan dalam Rajah 3. Rajah 3 dan Hinton, 2011). Tidak seperti seni bina ke hadapan dalam (iaitu, DBN, SAE, dan CNN), ia bukan sahaja memetakan corak input kepada hasil output, tetapi juga memindahkan keadaan tersembunyi kepada output dengan memanfaatkan sambungan antara unit tersembunyi (Graves & Schmidhuber, 2008). Dengan menggunakan sambungan tersembunyi ini, RNN memodelkan kebergantungan temporal, dengan itu berkongsi parameter antara objek dalam dimensi temporal. Ia telah diaplikasikan dalam pelbagai bidang seperti analisis pertuturan (Mulder, Bethard, & Moens, 2015), kapsyen imej (Xu et al., 2015), dan terjemahan bahasa (Graves & Jaitly, 2014), mencapai prestasi cemerlang. Sama seperti seni bina ke hadapan dalam, pengiraannya juga termasuk peringkat hantaran ke hadapan dan perambatan belakang. Dalam pengiraan hantaran hadapan, RNN memperoleh input dan keadaan tersembunyi secara serentak. Dalam pengiraan perambatan belakang, ia menggunakan algoritma perambatan belakang temporal untuk merambat belakang kehilangan langkah masa. Rajah 4 menunjukkan wakil RNN. . model pembelajaran mendalam gabungan data berbilang modal. Mereka dibahagikan kepada empat kategori berdasarkan seni bina pembelajaran mendalam yang digunakan. Jadual 2 meringkaskan model pembelajaran mendalam multimodal perwakilan.
 Jadual 2:
Jadual 2:
Ringkasan model pembelajaran mendalam pelbagai mod yang mewakili.
3.1 Percantuman data multi-modal kepercayaan mendalam berasaskan rangkaian
3.1.1 Contoh 1
Srivastava dan Salakhutdinov (2012) mencadangkan model pembelajaran model mendalam Boltz fusion berasaskan pelbagai model generasi mempelajari perwakilan multimodal dengan menyesuaikan pengedaran bersama data multimodal merentas pelbagai modaliti (seperti imej, teks dan audio).
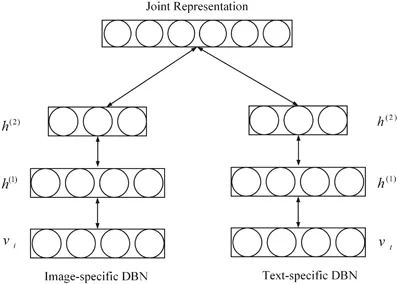
Setiap modul DBN berbilang modal yang dicadangkan dimulakan dalam cara lapisan demi lapisan tanpa pengawasan, dan kaedah penghampiran berasaskan MCMC digunakan untuk latihan model.
Untuk menilai perwakilan multi-modal yang dipelajari, sejumlah besar tugas dilakukan, seperti menjana tugasan modal yang hilang, membuat kesimpulan tugas perwakilan bersama dan tugas diskriminasi. Eksperimen mengesahkan sama ada perwakilan multimodal yang dipelajari memenuhi sifat yang diperlukan. . dalam data berbilang modal. Khususnya, untuk menangani batasan yang disebabkan oleh kaedah pembelajaran ciri cetek, DBN digunakan untuk mempelajari perwakilan mendalam bagi setiap modaliti dengan memindahkan perwakilan khusus domain kepada perwakilan abstrak hierarki. Kemudian, RBM satu lapisan dibina pada vektor bercantum, yang merupakan gabungan linear bagi perwakilan abstrak hierarki daripada setiap modaliti. Ia digunakan untuk mempelajari perwakilan multimodal dengan membina taburan bersama ciri multimodal yang berbeza. Akhir sekali, model yang dicadangkan dinilai secara meluas pada set data ADNI berdasarkan tiga diagnosis biasa, mencapai ketepatan diagnostik terkini. . Ketahui perwakilan berbilang modal daripada jenis campuran, skor penampilan dan modaliti cacat. Dalam model dalam pelbagai sumber pose manusia, tiga modaliti yang digunakan secara meluas diekstrak daripada model struktur imej yang menggabungkan pelbagai bahagian badan berdasarkan teori medan rawak bersyarat. Untuk mendapatkan data multimodal, model struktur grafik dilatih melalui mesin vektor sokongan linear. Setiap satu daripada tiga ciri kemudian dimasukkan ke dalam model Boltzmann terhad dua lapisan untuk menangkap perwakilan abstrak ruang pose tertib tinggi daripada perwakilan khusus ciri. Melalui pemulaan tanpa pengawasan, setiap model Boltzmann terhad khusus modaliti menangkap gambaran intrinsik ruang global. Kemudian, RBM digunakan untuk mempelajari lebih lanjut perwakilan pose manusia berdasarkan vektor gabungan jenis pengadunan peringkat tinggi, skor penampilan dan perwakilan ubah bentuk. Untuk melatih model pembelajaran mendalam berbilang sumber yang dicadangkan, fungsi objektif khusus tugas yang mengambil kira kedudukan badan dan pengesanan manusia direka bentuk. Model yang dicadangkan disahkan pada LSP, PARSE dan UIUC dan menghasilkan peningkatan sehingga 8.6%.
Baru-baru ini, beberapa model pembelajaran ciri pelbagai mod berasaskan DBN baharu telah dicadangkan. Contohnya, Amer, Shields, Siddiquie, dan Tamrakar (2018) mencadangkan pendekatan hibrid untuk pengesanan acara berjujukan, di mana RBM bersyarat digunakan untuk mengekstrak ciri modal dan rentas mod dengan maklumat label diskriminatif tambahan. Al-Waisy, Qahwaji, Ipson, dan Al-Fahdawi (2018) memperkenalkan pendekatan multimodal untuk pengenalan wajah. Dalam pendekatan ini, model berasaskan DBN digunakan untuk memodelkan pengedaran multimodal ciri buatan tangan tempatan yang ditangkap oleh transformasi Curvelet, yang boleh menggabungkan kelebihan ciri tempatan dan ciri mendalam (Al-Waisy et al., 2018).
3.1.4 Ringkasan
Model multimodal berasaskan DBN ini menggunakan rangkaian graf probabilistik untuk menukar perwakilan khusus modaliti kepada ciri semantik dalam ruang kongsi. Kemudian, pengagihan bersama ke atas modaliti dimodelkan berdasarkan ciri-ciri ruang kongsi. Model multimodal berasaskan DBN ini lebih fleksibel dan teguh dalam strategi pembelajaran tanpa penyeliaan, separa penyeliaan dan penyeliaan. Ia sesuai untuk menangkap ciri bermaklumat data input. Walau bagaimanapun, mereka mengabaikan topologi spatial dan temporal data multimodal.
. model untuk gabungan data berbilang modal. Model pembelajaran mendalam ini bertujuan untuk menyelesaikan dua masalah gabungan data: pembelajaran perwakilan mod silang dan perkongsian mod. Yang pertama bertujuan untuk memanfaatkan pengetahuan daripada modaliti lain untuk menangkap perwakilan modal tunggal yang lebih baik, manakala yang kedua mempelajari korelasi yang kompleks antara modaliti di peringkat pertengahan. Untuk mencapai matlamat ini, tiga senario pembelajaran—pembelajaran multimodal, cross-modal dan shared-modal—direka bentuk, seperti yang ditunjukkan dalam Jadual 3 dan Rajah 6.Rajah 6:
Seni bina untuk pembelajaran mod berbilang modal, silang modal dan perkongsian.
Jadual 3: Tetapan untuk pembelajaran pelbagai mod.
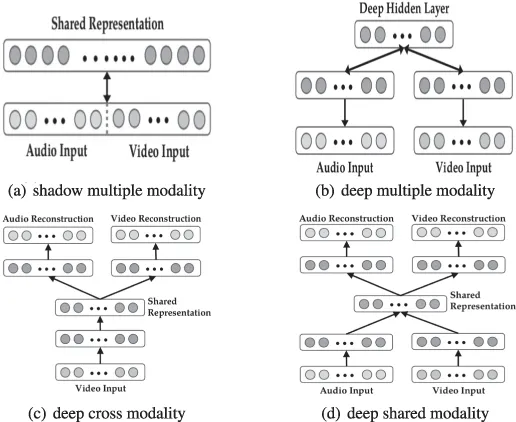 Dalam senario pembelajaran pelbagai mod, spektrogram audio dan bingkai video disambungkan ke dalam vektor secara linear. Vektor bercantum dimasukkan ke dalam Mesin Boltzmann Terhad Jarang (SRBM) untuk mempelajari korelasi antara audio dan video. Model ini hanya boleh mempelajari perwakilan gabungan bayangan bagi pelbagai modaliti kerana korelasi itu tersirat dalam perwakilan dimensi tinggi tahap asal dan SRBM satu lapisan tidak boleh memodelkannya. Diilhamkan oleh ini, vektor gabungan perwakilan peringkat pertengahan dimasukkan ke dalam SRBM untuk memodelkan korelasi pelbagai modaliti, dengan itu menunjukkan prestasi yang lebih baik.
Dalam senario pembelajaran pelbagai mod, spektrogram audio dan bingkai video disambungkan ke dalam vektor secara linear. Vektor bercantum dimasukkan ke dalam Mesin Boltzmann Terhad Jarang (SRBM) untuk mempelajari korelasi antara audio dan video. Model ini hanya boleh mempelajari perwakilan gabungan bayangan bagi pelbagai modaliti kerana korelasi itu tersirat dalam perwakilan dimensi tinggi tahap asal dan SRBM satu lapisan tidak boleh memodelkannya. Diilhamkan oleh ini, vektor gabungan perwakilan peringkat pertengahan dimasukkan ke dalam SRBM untuk memodelkan korelasi pelbagai modaliti, dengan itu menunjukkan prestasi yang lebih baik.
Dalam senario pembelajaran merentas mod, pengekod auto berbilang mod bertindan dalam dicadangkan untuk mempelajari secara eksplisit perkaitan antara modaliti. Secara khusus, kedua-dua audio dan video dibentangkan sebagai input dalam pembelajaran ciri, dan hanya satu daripadanya menjadi input kepada model dalam latihan dan ujian yang diselia. Model ini dimulakan dalam cara pembelajaran pelbagai mod dan boleh mensimulasikan hubungan silang mod dengan baik.
Akhir sekali, percubaan terperinci dijalankan pada set data CUAVE dan AVLetters untuk menilai prestasi pembelajaran mendalam berbilang mod dalam pembelajaran ciri khusus tugas. . menangkap hubungan gabungan antara imej dan pose. Khususnya, pengekod auto dalam pelbagai mod yang dicadangkan dilatih melalui strategi tiga peringkat untuk membina pemetaan tak linear antara imej 2D dan pose 3D. Dalam peringkat gabungan ciri, perwakilan peringkat rendah hipergraf berbilang paparan dieksploitasi untuk membina perwakilan 2D dalaman daripada siri ciri imej (seperti histogram kecerunan berorientasikan dan konteks bentuk) berdasarkan pembelajaran manifold. Pada peringkat kedua, pengekod auto satu lapisan dilatih untuk mempelajari perwakilan abstrak yang digunakan untuk memulihkan pose 3D dengan membina semula ciri antara imej 2D. Sementara itu, pengekod automatik satu lapisan dilatih dengan cara yang sama untuk mempelajari perwakilan abstrak pose 3D. Selepas memperoleh perwakilan abstrak setiap modaliti tunggal, rangkaian saraf digunakan untuk mempelajari korelasi multimodal antara imej 2D dan pose 3D dengan meminimumkan jarak Euclidean kuasa dua antara dua perwakilan bersama modal. Pembelajaran pengekod auto dalam pelbagai mod yang dicadangkan terdiri daripada peringkat permulaan dan penalaan halus. Dalam pemulaan, parameter setiap sub-bahagian autoenkoder dalam berbilang mod disalin daripada pengekod auto dan rangkaian saraf yang sepadan. Kemudian, parameter keseluruhan model diperhalusi lagi melalui algoritma penurunan kecerunan stokastik untuk membina pose tiga dimensi daripada imej dua dimensi yang sepadan. . Oleh kerana ia berdasarkan SAE, yang merupakan model yang disambungkan sepenuhnya, banyak parameter perlu dilatih. Tambahan pula, mereka mengabaikan topologi spatial dan temporal dalam data multimodal.
Untuk mensimulasikan taburan pemetaan semantik antara imej dan ayat, Ma, Lu, Shang, dan Li) (2015 dan Li) dicadangkan Rangkaian neural convolutional multi-modal. Untuk menangkap perkaitan semantik sepenuhnya, strategi gabungan tiga peringkat—peringkat perkataan, peringkat peringkat dan peringkat ayat—direka bentuk dalam seni bina hujung ke hujung. Seni bina terdiri daripada subnet pengimejan, subnet yang sepadan dan subnet multimodal. Subnet imej ialah rangkaian neural konvolusi dalam yang mewakili seperti Alexnet dan Inception, yang cekap mengekod input imej ke dalam perwakilan ringkas. Subrangkaian yang sepadan memodelkan perwakilan bersama yang mengaitkan kandungan imej dengan serpihan perkataan ayat dalam ruang semantik. . rangkaian. Rangkaian terdiri daripada submodel bahasa dan submodel visual. Submodel bahasa adalah berdasarkan model langkau-gram, yang boleh memindahkan maklumat teks ke dalam perwakilan padat ruang semantik. Submodel penglihatan ialah rangkaian saraf konvolusional yang mewakili seperti Alexnet, yang telah dilatih terlebih dahulu pada set data ImageNet 1000 kelas untuk menangkap ciri visual. Untuk memodelkan hubungan semantik antara imej dan teks, bahasa dan submodel visual digabungkan melalui lapisan unjuran linear. Setiap submodel dimulakan dengan parameter untuk setiap modaliti. Selepas itu, untuk melatih model multi-modal visual-semantik ini, fungsi kehilangan baharu dicadangkan yang boleh memberikan skor persamaan yang tinggi untuk pasangan imej dan label yang betul dengan menggabungkan persamaan produk titik dan kehilangan kedudukan engsel. Model ini menghasilkan prestasi terkini pada dataset ImageNet, mengelakkan hasil yang tidak munasabah secara semantik. Model multimodal berdasarkan CNN boleh mempelajari ciri multimodal tempatan antara modaliti melalui medan tempatan dan operasi pengumpulan. Mereka secara eksplisit memodelkan topologi spatial data multimodal. Dan mereka bukan model yang disambungkan sepenuhnya dengan bilangan parameter yang jauh berkurangan. 3.4.1 Contoh 8 Dalam RNN berbilang modal, model lanjutan yang lebih berkesan berdasarkan kandungan teks dan input imej dicadangkan. Model multimodal terdiri daripada rangkaian saraf konvolusi yang mengekod input imej dan RNN yang mengekod ciri dan ayat imej. Model ini juga dilatih melalui algoritma penurunan kecerunan stokastik. Kedua-dua model multimodal dinilai secara meluas pada set data Flickr dan Mscoco dan mencapai prestasi terkini. Model berbilang modal berdasarkan RNN boleh menganalisis pergantungan masa yang tersembunyi dalam data berbilang modal dengan bantuan pemindahan keadaan eksplisit dalam pengiraan unit tersembunyi. Mereka menggunakan algoritma perambatan belakang temporal untuk melatih parameter. Memandangkan pengiraan dilakukan dalam pemindahan keadaan tersembunyi, sukar untuk disejajarkan pada peranti berprestasi tinggi. Kami meringkaskan model kepada empat kumpulan model pembelajaran mendalam data berbilang modal berdasarkan DBN, SAE, CNN dan RNN. Beberapa kemajuan telah dicapai dengan model perintis ini. Walau bagaimanapun, model ini masih dalam peringkat awal, jadi cabaran masih ada. Pertama sekali, terdapat sejumlah besar pemberat bebas dalam model pembelajaran mendalam gabungan data berbilang mod, terutamanya parameter berlebihan yang mempunyai sedikit kesan pada tugas sasaran. Untuk melatih parameter ini yang menangkap struktur ciri data, sejumlah besar data dimasukkan ke dalam model pembelajaran mendalam gabungan data berbilang modal berdasarkan algoritma perambatan belakang, yang intensif secara pengiraan dan memakan masa. Oleh itu, cara mereka bentuk kaedah pemampatan pembelajaran mendalam pelbagai mod baharu berdasarkan strategi pemampatan sedia ada juga merupakan hala tuju penyelidikan yang berpotensi. 3.3 Gabungan data berbilang modal berdasarkan rangkaian neural konvolusi
3.3.1 Contoh 6
3.3.3 Ringkasan
3.4 Gabungan data berbilang modal berdasarkan rangkaian saraf berulang
Untuk menjana kapsyen imej, Mao et al. Rangkaian saraf berulang berbilang mod ini boleh merapatkan korelasi kebarangkalian antara imej dan ayat. Ia menangani had karya terdahulu yang tidak boleh menjana kapsyen imej baharu kerana ia mendapatkan kapsyen yang sepadan dalam pangkalan data ayat berdasarkan pemetaan teks imej yang dipelajari. Tidak seperti kerja sebelumnya, model saraf berulang multimodal (MRNN) mempelajari pengedaran bersama ke atas ruang semantik yang diberikan perkataan dan imej. Apabila imej dipersembahkan, ia menjana ayat verbatim berdasarkan taburan bersama yang ditangkap. Secara khusus, rangkaian saraf berulang multimodal terdiri daripada subnet bahasa, subnet visual dan subnet multimodal, seperti yang ditunjukkan dalam Rajah 7. Subrangkaian bahasa terdiri daripada bahagian pembenaman perkataan dua lapisan yang menangkap perwakilan khusus tugasan yang cekap dan bahagian saraf berulang satu lapisan yang memodelkan pergantungan temporal ayat. Subnet penglihatan pada asasnya ialah rangkaian saraf konvolusi yang mendalam, seperti Alexnet, Resnet, atau Inception, yang mengekod imej berdimensi tinggi kepada perwakilan padat. Akhir sekali, subrangkaian multimodal ialah rangkaian tersembunyi yang memodelkan pengedaran semantik bersama bahasa yang dipelajari dan perwakilan visual. . merapatkan model antara data visual dan tekstual Hubungan antara keadaan, model penjajaran pelbagai modal dicadangkan (Karpathy & Li, 2017). Untuk mencapai matlamat ini, satu skim dwi telah dicadangkan. Pertama, model pembenaman semantik visual direka untuk menjana set data latihan berbilang modal. RNN multimodal kemudiannya dilatih pada set data ini untuk menjana perihalan imej yang kaya.
Dalam model pembenaman semantik visual, rangkaian neural convolutional serantau digunakan untuk mendapatkan perwakilan imej yang kaya yang mengandungi maklumat yang mencukupi untuk kandungan yang sepadan dengan ayat. RNN dwiarah kemudiannya digunakan untuk mengekod setiap ayat ke dalam vektor padat dengan dimensi yang sama seperti perwakilan imej. Tambahan pula, fungsi pemarkahan multimodal dipersembahkan untuk mengukur persamaan semantik antara imej dan ayat. Akhir sekali, kaedah medan rawak Markov digunakan untuk menjana set data multimodal.
3.4.3 Ringkasan
4 Ringkasan dan Tinjauan
Atas ialah kandungan terperinci Terlalu lengkap! Kajian semula pembelajaran mendalam multimodal!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Pembelajaran mesin kecil menjanjikan untuk membenamkan pembelajaran mendalam ke dalam mikropemproses
- Cara yang betul untuk bermain pembelajaran mendalam blok binaan! Universiti Nasional Singapura mengeluarkan DeRy, paradigma pembelajaran pemindahan baharu yang menukar pemindahan pengetahuan kepada percetakan jenis alih
- cara membaiki lsp
- Apakah subnet mask?