
Rumah >Peranti teknologi >AI >Apakah AI generatif? Apakah jenis ciri yang ada
Apakah AI generatif? Apakah jenis ciri yang ada

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-03 17:58:212006semak imbas
Generative AI ialah teknologi kecerdasan buatan manusia yang boleh menjana pelbagai jenis kandungan, termasuk teks, imej, audio dan data sintetik. Jadi apakah kecerdasan buatan? Apakah perbezaan antara kecerdasan buatan dan pembelajaran mesin? Apakah ciri teknikal?
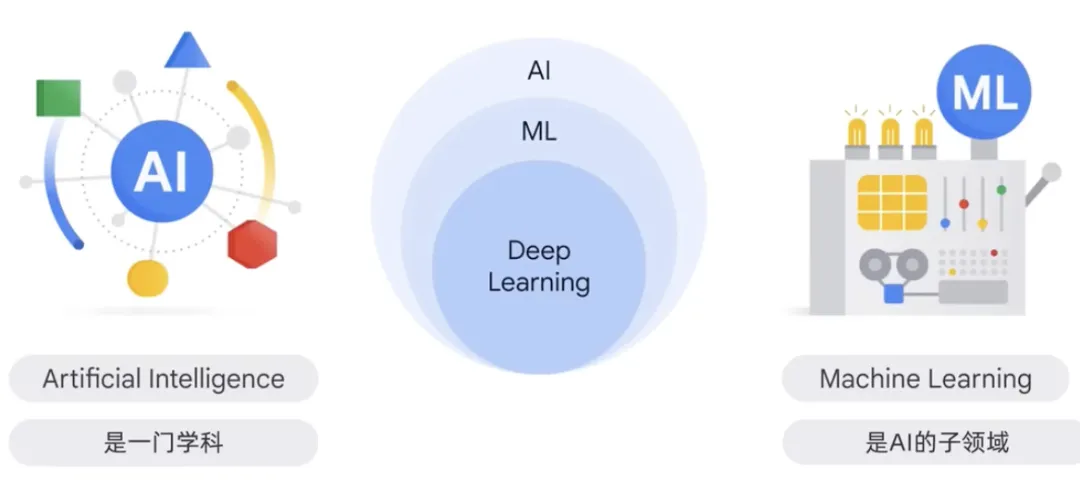
Kecerdasan buatan ialah satu disiplin, satu cabang sains komputer yang mengkaji penciptaan agen pintar. Ini adalah sistem di mana ejen pintar boleh menaakul, belajar dan bertindak secara autonomi. Kajian tentang agen pintar ialah kajian tentang sistem yang boleh menaakul, belajar, dan bertindak secara autonomi.
Kecerdasan Buatan berkenaan dengan teori dan kaedah membina mesin yang berfikir dan bertindak seperti manusia. Dalam disiplin ini, pembelajaran mesin ialah bidang kecerdasan buatan. Ia adalah program atau sistem yang melatih model berdasarkan data input Model terlatih boleh membuat ramalan berguna daripada data baharu atau tidak kelihatan, yang boleh diperoleh daripada data bersatu yang model itu dilatih. Dengan melatih model pada data bersatu daripada model latihannya sendiri, data ini boleh digunakan untuk meramalkan data yang tidak dilihat oleh model. Data ini datang daripada data bersatu yang digunakan untuk melatih model itu sendiri, membolehkan ramalan berguna dibuat. Kaedah ini digunakan secara meluas dalam masalah dalam imej, pengecaman pertuturan, pemprosesan bahasa semula jadi dan bidang lain.
Pembelajaran mesin memberi komputer keupayaan untuk belajar tanpa pengaturcaraan eksplisit. Dua jenis model pembelajaran mesin yang paling biasa ialah model pembelajaran tanpa pengawasan dan model ML yang diselia. Perbezaan utama antara kedua-duanya ialah untuk model diselia kami mempunyai label, data berlabel ialah data dengan label seperti nama, jenis atau nombor dan data tanpa seliaan ialah data tanpa label.
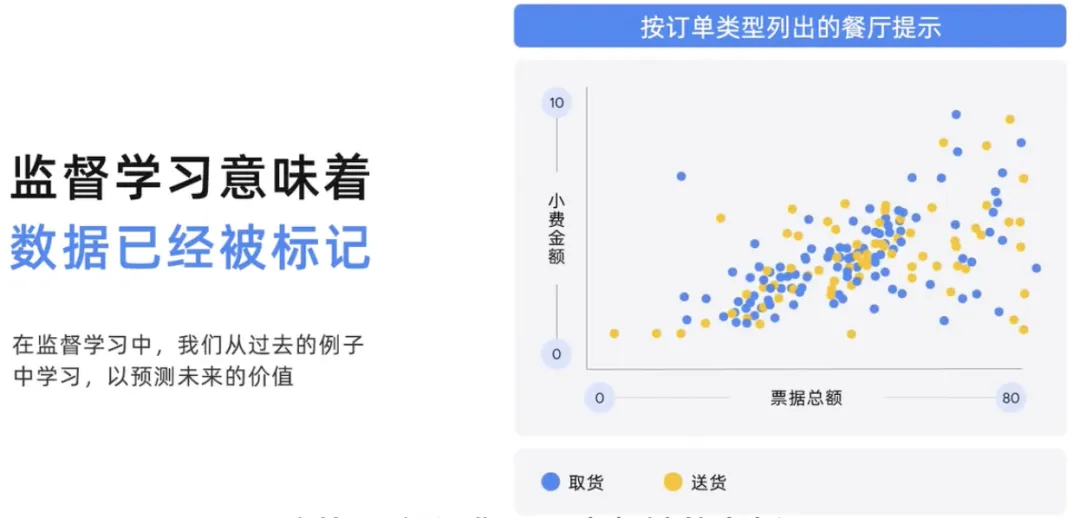
Angka ini ialah contoh masalah yang mungkin cuba diselesaikan oleh model yang diselia.
Andaikan anda pemilik restoran dan anda mempunyai data sejarah amaun bil, berapa banyak petua yang diberikan kepada orang yang berbeza berdasarkan jenis pesanan, bilangan orang yang berbeza diberi petua berdasarkan jenis pesanan sama ada pengambilan atau penghantaran . Dalam pembelajaran diselia, model belajar daripada data lepas dan meramalkan nilai masa hadapan. Jadi dalam model ini, bergantung pada jenis pesanan, jumlah bil digunakan untuk meramalkan sama ada pembelian masa hadapan mungkin untuk pengambilan atau penghantaran dan jumlah petua yang mungkin. Ramalan berdasarkan model lepas dijangka dapat meramalkan jumlah penggunaan akan datang dengan tepat. Oleh itu, model di sini menggunakan jumlah bil untuk meramalkan perbelanjaan dan petua masa hadapan berdasarkan jenis pesanan.
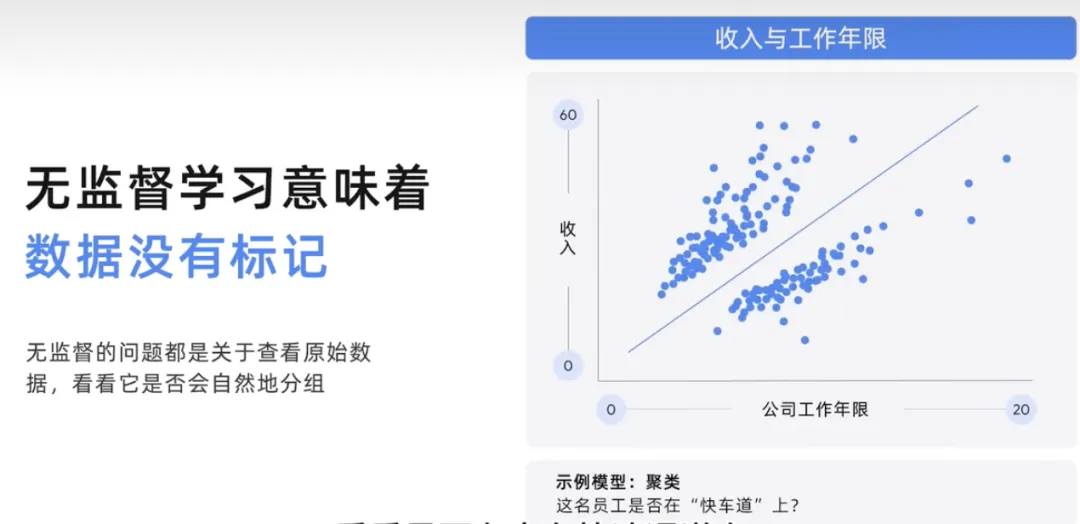
Model tanpa pengawasan ini mungkin membantu dalam contoh masalah di mana seseorang itu perlu melihat tempoh perkhidmatan dan pendapatan dan kemudian kumpulan pekerja untuk mendapatkan kohort untuk melihat sama ada sesiapa berada di landasan pantas. Masalah yang tidak diselia adalah mengenai melihat data mentah dan melihat sama ada ia berkumpul secara semula jadi, mari kita mendalami sedikit dan tunjukkan ini secara grafik.
Konsep di atas adalah asas untuk memahami AI generatif.

Dalam pembelajaran diselia, nilai data ujian dimasukkan ke dalam model, model mengeluarkan ramalan, dan ramalan itu dibandingkan dengan data latihan yang digunakan untuk melatih model.
Jika nilai data ujian yang diramalkan dan nilai data latihan sebenar adalah berjauhan, ia dipanggil ralat, dan model cuba mengurangkan ralat ini sehingga nilai ramalan dan nilai sebenar lebih dekat.
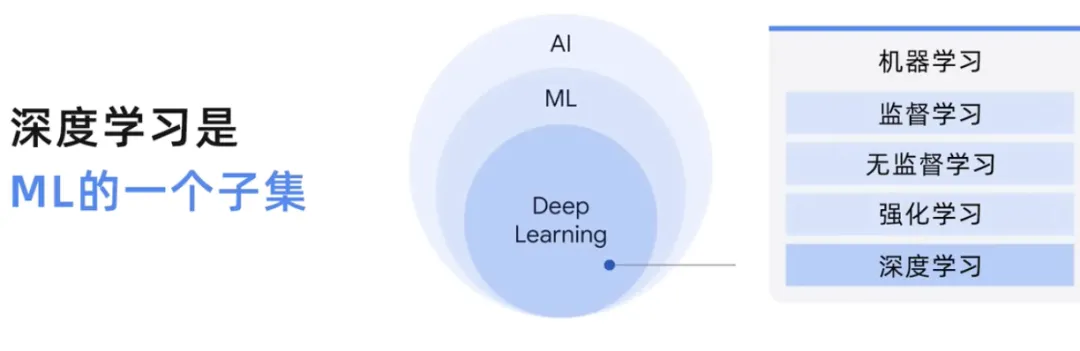
Kami telah membincangkan perbezaan antara Kepintaran Buatan dan Pembelajaran Mesin, Pembelajaran Terselia dan Pembelajaran Tanpa Selia. Jadi, mari kita meneroka secara ringkas pembelajaran mendalam.
Walaupun pembelajaran mesin merupakan bidang yang luas yang merangkumi pelbagai teknik, pembelajaran mendalam ialah sejenis pembelajaran mesin yang menggunakan rangkaian saraf tiruan, membolehkan mereka memproses corak yang lebih kompleks daripada pembelajaran mesin.
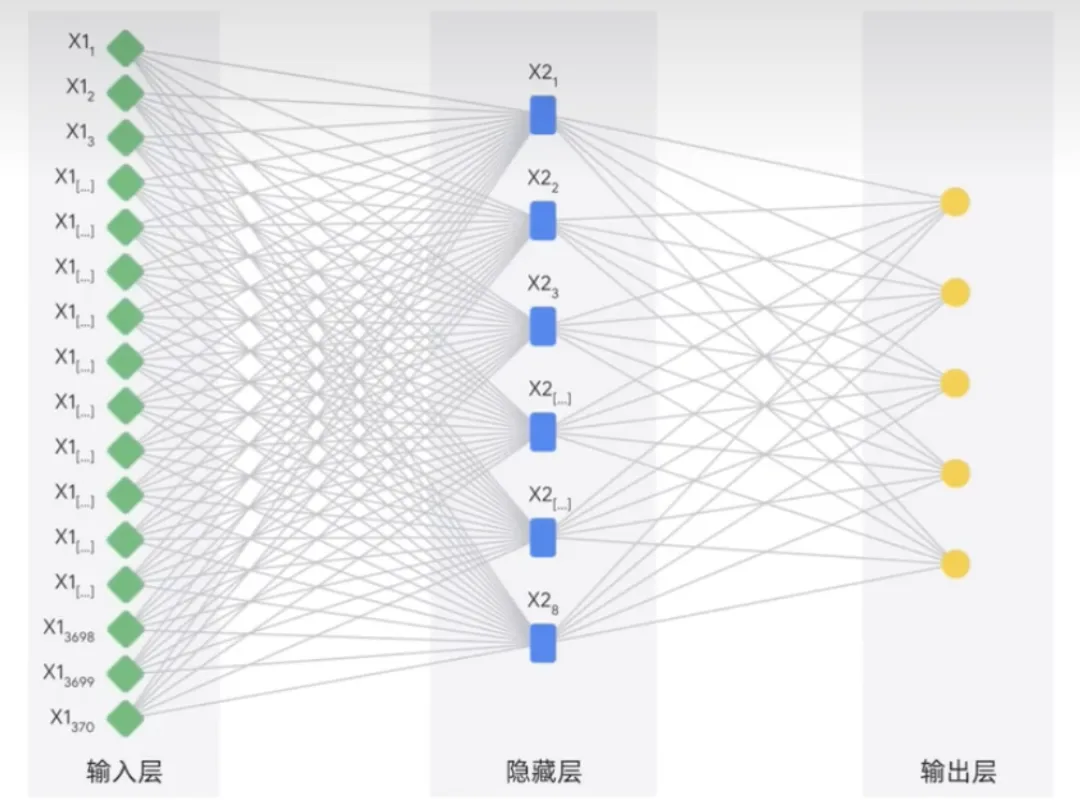
Rangkaian saraf tiruan diilhamkan oleh otak manusia Ia terdiri daripada banyak nod atau neuron yang saling berkaitan yang boleh belajar melaksanakan tugas dengan memproses data dan membuat ramalan.
Model pembelajaran mendalam biasanya mempunyai berbilang lapisan neuron. Ini membolehkan mereka mempelajari corak yang lebih kompleks daripada model pembelajaran mesin tradisional. Rangkaian saraf boleh berfungsi dengan kedua-dua data berlabel dan tidak berlabel, yang dipanggil pembelajaran separa diselia. Dalam pembelajaran separa penyeliaan, rangkaian saraf dilatih pada sejumlah kecil data berlabel dan sejumlah besar data tidak berlabel. Data berlabel membantu rangkaian saraf mempelajari konsep asas tugas. Dan data tidak berlabel membantu rangkaian saraf membuat generalisasi kepada contoh baharu. Kedudukan
dalam disiplin kecerdasan buatan ini, yang bermaksud menggunakan rangkaian saraf tiruan, data berlabel dan tidak berlabel boleh diproses dalam kaedah yang diselia, tidak diselia dan separa diselia. Model bahasa besar juga merupakan subset pembelajaran mendalam, model pembelajaran mendalam atau model pembelajaran mesin secara umum.
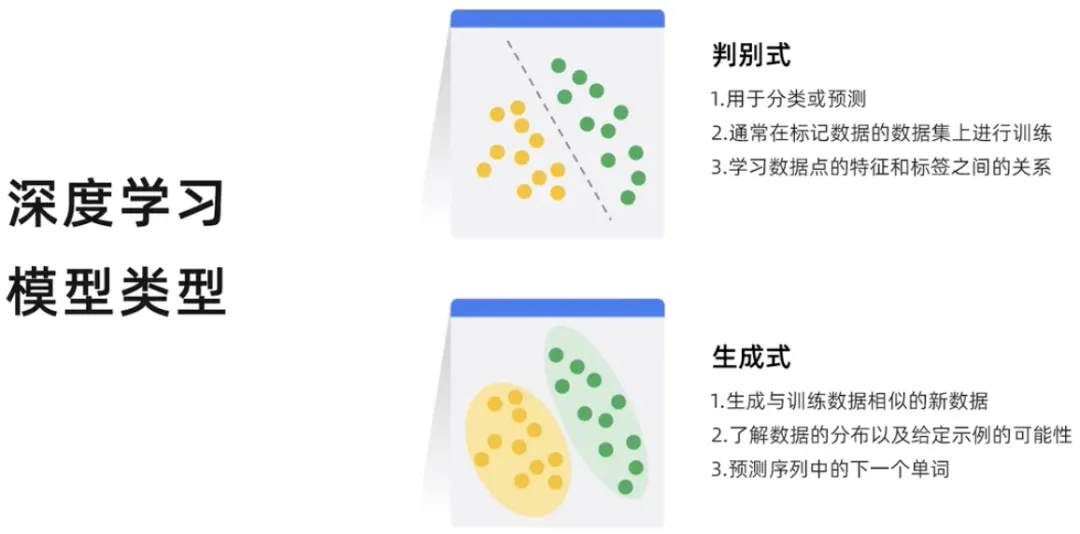
Pembelajaran mendalam boleh dibahagikan kepada dua jenis: diskriminatif dan generatif. Model diskriminatif ialah model yang digunakan untuk mengklasifikasikan atau meramalkan label titik data. Model diskriminatif biasanya dilatih pada set data titik data berlabel. Mereka mempelajari hubungan antara ciri dan label titik data, dan setelah model diskriminatif dilatih, ia boleh digunakan untuk meramalkan label titik data baharu. Model generatif menjana kejadian data baharu berdasarkan taburan kebarangkalian yang dipelajari bagi data sedia ada, jadi model generatif menghasilkan kandungan baharu.
Model generatif boleh mengeluarkan tika data baharu, manakala model diskriminatif boleh membezakan jenis tika data yang berbeza.
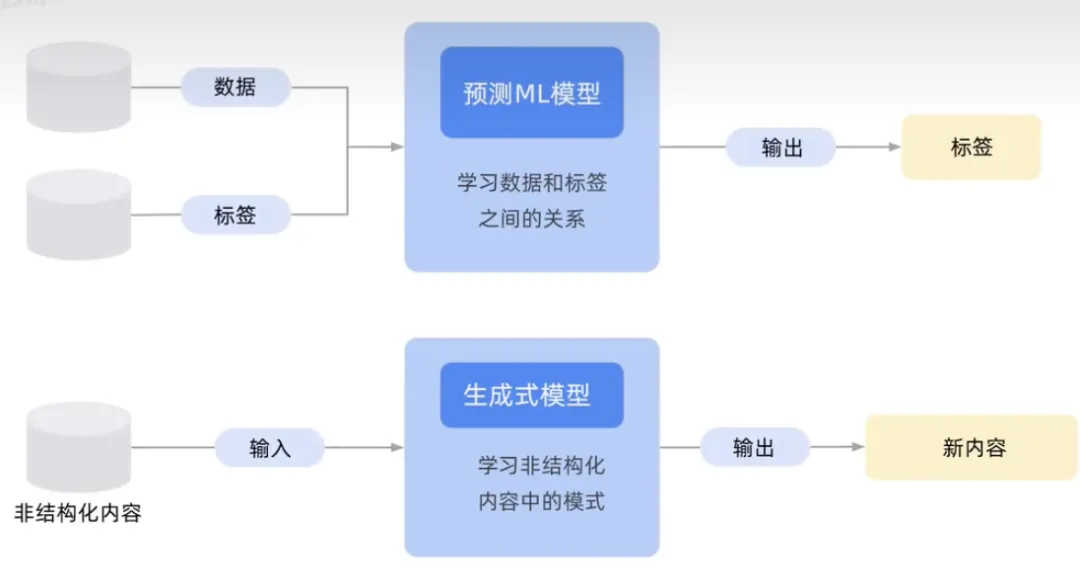
Rajah ini menunjukkan model pembelajaran mesin tradisional, perbezaannya ialah hubungan antara data dan label, atau perkara yang anda ingin ramalkan. Imej bawah menunjukkan model AI generatif yang cuba mempelajari corak kandungan untuk menjana dan mengeluarkan kandungan baharu.
Apabila label luar output ialah nombor atau kebarangkalian, ia adalah AI bukan generatif, seperti spam atau bukan spam. Apabila output adalah bahasa semula jadi, ia adalah AI generatif, seperti pertuturan, teks, imej dan video.
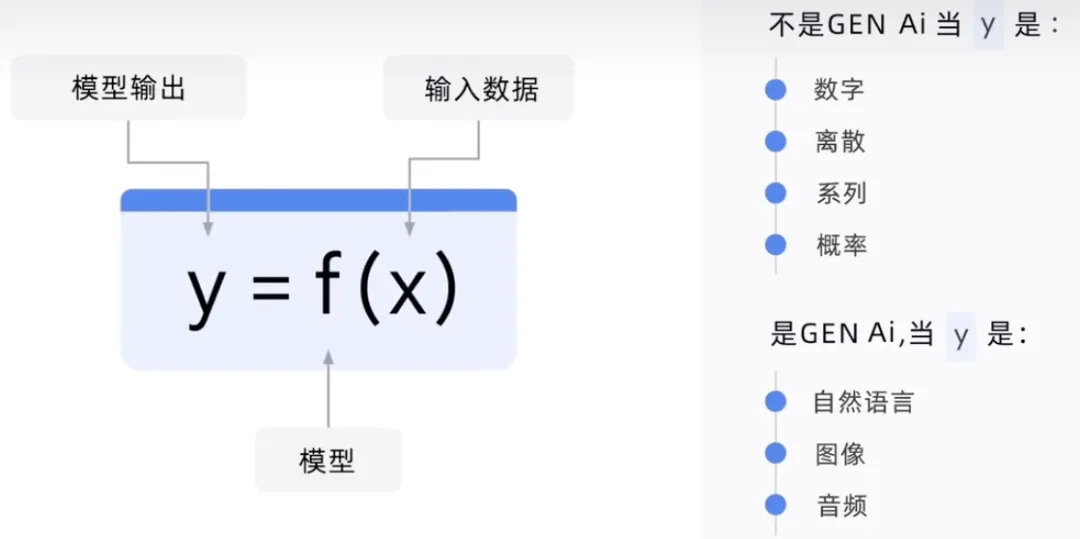
Output model adalah fungsi semua input, jika Y ialah nombor, seperti jualan yang diramalkan, maka ia bukan GenAI. Jika Y adalah ayat, ia seperti mentakrifkan jualan. Ia adalah generatif dalam soalan yang menimbulkan tindak balas teks. Tanggapan beliau akan berdasarkan semua jumlah besar data besar yang model telah dilatih.
Ringkasnya, proses pembelajaran tradisional, klasik diselia dan tidak diselia menggunakan kod latihan dan data berlabel untuk membina model. Bergantung pada kes penggunaan atau masalah, model boleh memberi anda ramalan, ia boleh mengelaskan atau mengelompokkan sesuatu, menggunakan daya ini untuk menunjukkan betapa teguhnya proses yang menjananya.
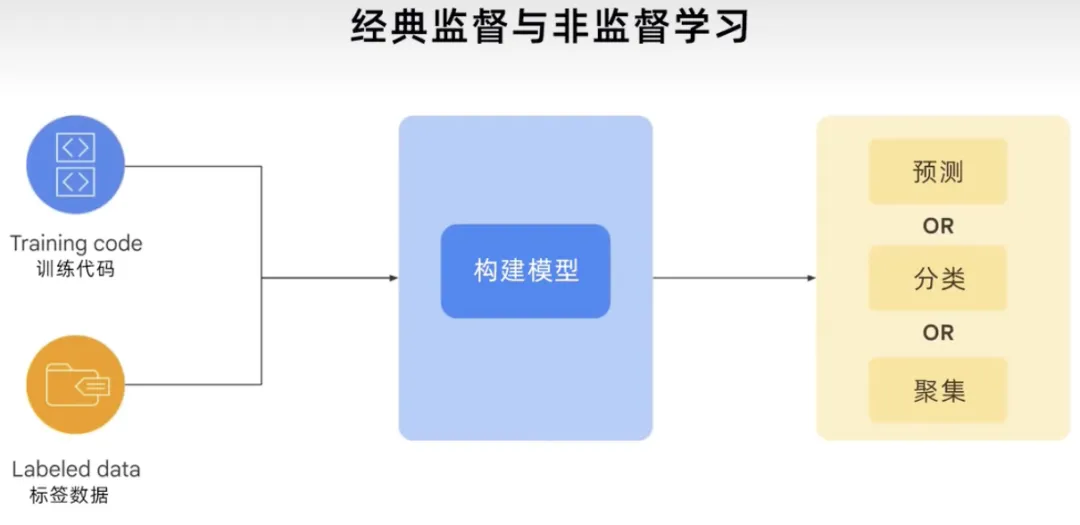
Proses GenAI boleh mendapatkan kod latihan, data berlabel dan data tidak berlabel semua jenis data, membina model asas, dan kemudian model asas boleh menjana kandungan baharu. Seperti teks, kod, imej, audio, video, dsb.
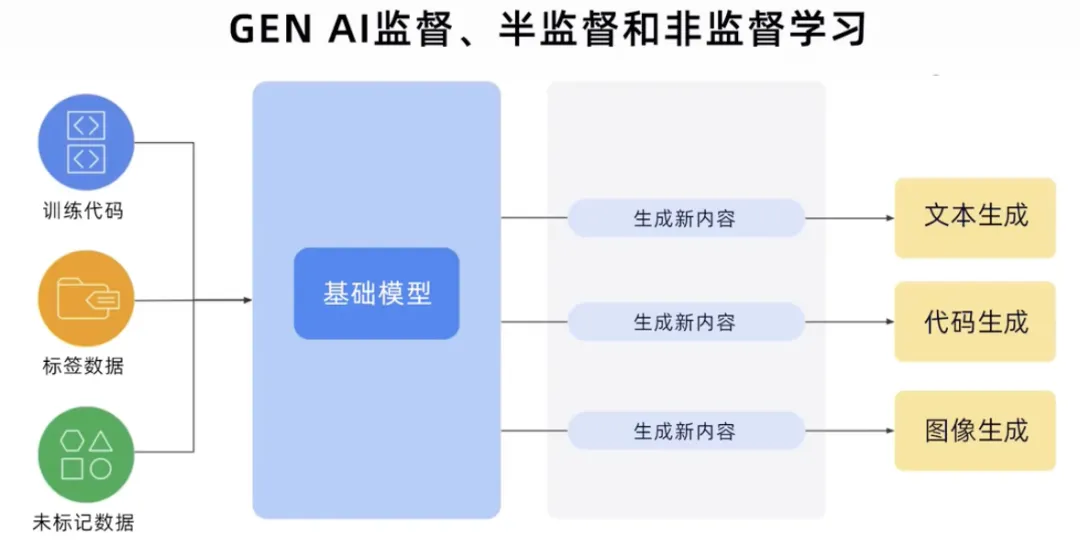
Daripada pengaturcaraan tradisional kepada rangkaian saraf kepada model generatif, kami telah melangkah jauh. Dalam pengaturcaraan tradisional, kita perlu mengekodkan peraturan untuk membezakan kucing. Jenisnya ialah haiwan, dengan 4 kaki, 2 telinga, bulu, dll.
Dalam gelombang rangkaian saraf, kita boleh memberi makan gambar rangkaian kucing dan anjing. dan bertanya sama ada ia kucing. Dia akan meramalkan seekor kucing. Dalam gelombang AI generatif, kami, sebagai pengguna, boleh menjana kandungan kami sendiri.

Sama ada teks, imej, audio, video, dll., seperti model bahasa Python atau model bahasa aplikasi perbualan dan model lain. Dapatkan data yang sangat besar daripada pelbagai sumber di internet. Bina model bahasa asas yang boleh digunakan hanya dengan bertanya soalan. Jadi, apabila anda bertanya kepadanya apa itu kucing, dia boleh memberitahu anda semua yang dia tahu tentang kucing.
GenAI Generative AI ialah teknologi kecerdasan buatan yang mencipta kandungan baharu berdasarkan pengetahuan yang dipelajari daripada kandungan sedia ada Proses pembelajaran daripada kandungan sedia ada dipanggil latihan. Dan buat model statistik apabila gesaan diberikan, gunakan model itu untuk meramalkan tindak balas yang dijangkakan dan jana kandungan baharu.
Pada asasnya, ia mempelajari kandungan struktur asas data dan kemudian boleh menjana sampel baharu yang serupa dengan data latihan. Seperti yang dinyatakan sebelum ini, model bahasa generatif boleh mengambil apa yang telah dipelajari daripada contoh yang ditunjukkan dan mencipta sesuatu yang benar-benar baharu berdasarkan maklumat tersebut.
Model bahasa berskala besar ialah sejenis kecerdasan buatan generatif kerana ia menghasilkan gabungan teks baharu dalam bentuk bahasa yang berbunyi semula jadi, menjana model imej, mengambil imej sebagai input dan boleh mengeluarkan teks, imej lain atau sebuah video. Contohnya, di bawah Teks Output anda boleh mendapatkan jawapan soalan visual, manakala di bawah Imej Output menjana penyiapan imej, dan di bawah Video Output menjana animasi.
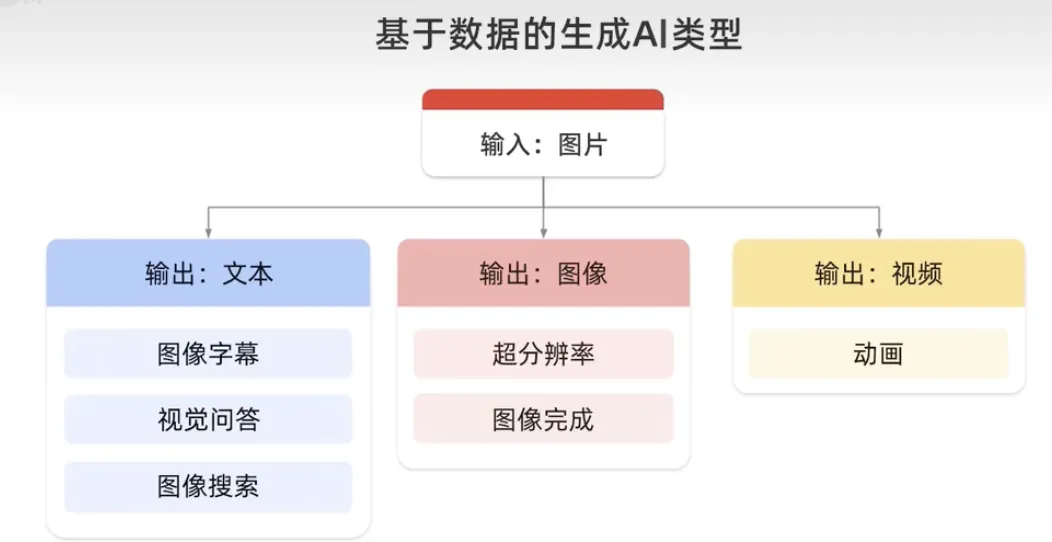
Jana model bahasa yang mengambil teks sebagai input dan boleh mengeluarkan lebih banyak teks, imej, audio atau keputusan. Sebagai contoh, hasilkan soalan dan jawapan di bawah teks output dan video di bawah imej output.

Kami telah mengatakan bahawa model bahasa generatif belajar tentang corak dan bahasa melalui data latihan, dan kemudian diberi beberapa teks, mereka meramalkan perkara yang akan berlaku seterusnya.
Model bahasa generatif ialah sistem padanan corak, mereka mempelajari corak berdasarkan data yang anda berikan kepada mereka. Berdasarkan apa yang dia pelajari daripada data latihan, dia memberikan ramalan bagaimana untuk melengkapkan ayat tersebut. Ia dilatih mengenai sejumlah besar data teks dan dapat berkomunikasi sebagai tindak balas kepada pelbagai gesaan dan soalan serta menjana teks seperti manusia.
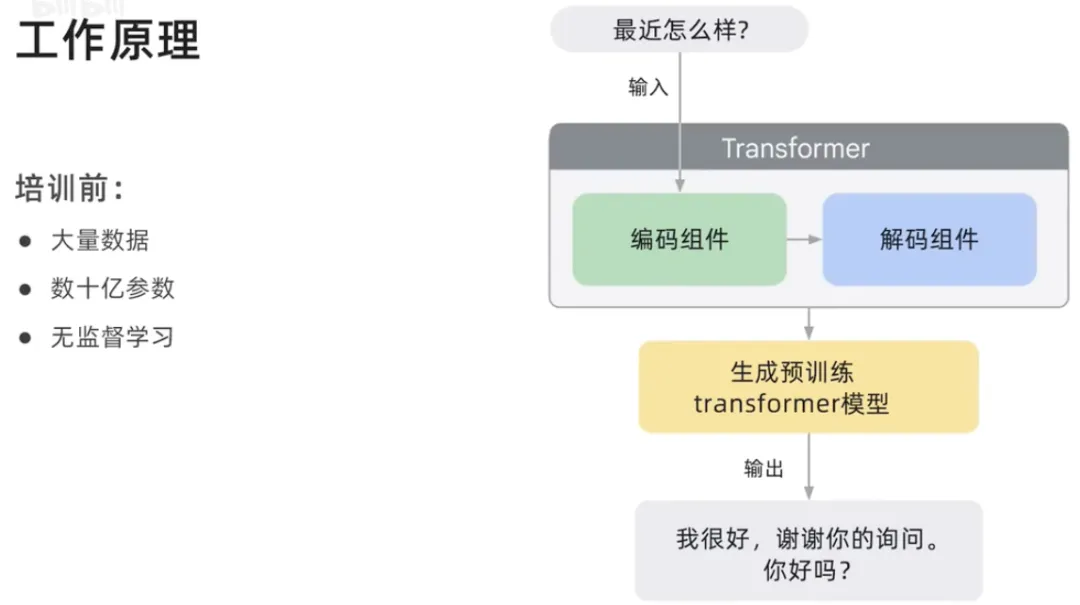
Dalam transformer, halusin ialah perkataan atau frasa yang dijana oleh model, yang biasanya karut atau tidak betul dari segi tatabahasa. Halusinasi boleh disebabkan oleh pelbagai faktor, termasuk model tidak dilatih mengenai data yang mencukupi, atau model dilatih mengenai data yang bising atau kotor, atau tidak memberikan model yang cukup konteks, atau tidak memberikan model yang cukup kekangan.

Mereka juga boleh menjadikan model lebih berkemungkinan menghasilkan maklumat yang tidak betul atau mengelirukan, seperti Pelbagai TPT3.5 yang kadangkala mungkin menjana maklumat yang tidak semestinya betul. Kata gesaan ialah kepingan kecil teks yang diberikan sebagai input kepada model bahasa yang besar. Dan ia boleh digunakan untuk mengawal output model dalam pelbagai cara.
Reka bentuk petunjuk ialah proses mencipta pembayang yang akan menghasilkan kandungan output yang diingini daripada model bahasa yang besar. Seperti yang dinyatakan sebelum ini, LLM sangat bergantung pada data latihan yang anda masukkan. Ia belajar dengan menganalisis corak dan struktur data input. Tetapi dengan mengakses gesaan berasaskan pelayar, pengguna boleh menjana kandungan mereka sendiri.

Kami telah menunjukkan peta jalan untuk jenis input berasaskan data, di bawah ialah jenis model yang berkaitan.
Model teks ke teks. Mengambil input bahasa semula jadi dan menjana output teks. Model ini dilatih untuk mempelajari pemetaan antara teks. Contohnya, terjemahan dari satu bahasa ke bahasa yang lain.
Teks ke model imej. Kerana model teks-ke-imej dilatih pada sejumlah besar imej. Setiap imej disertakan dengan penerangan teks pendek. Penyebaran adalah satu kaedah yang digunakan untuk mencapai ini.

Teks ke Video dan Teks ke 3D. Model teks-ke-video menjana kandungan video daripada input teks sahaja, yang boleh terdiri daripada satu ayat kepada skrip yang lengkap. Output ialah teks seperti video yang sepadan dengan teks input kepada model 3D yang menghasilkan objek tiga dimensi yang sepadan dengan penerangan teks pengguna. Ini boleh digunakan untuk permainan atau dunia 3D lain, contohnya.
Model teks-ke-tugas. Setelah dilatih, ia boleh melaksanakan tugas atau tindakan yang ditentukan berdasarkan input teks. Tugas ini boleh menjadi luas. Contohnya, menjawab soalan, melakukan carian, membuat ramalan atau mengambil beberapa tindakan Model Teks ke tugas juga boleh dilatih untuk membimbing pertanyaan atau membuat perubahan pada dokumen.
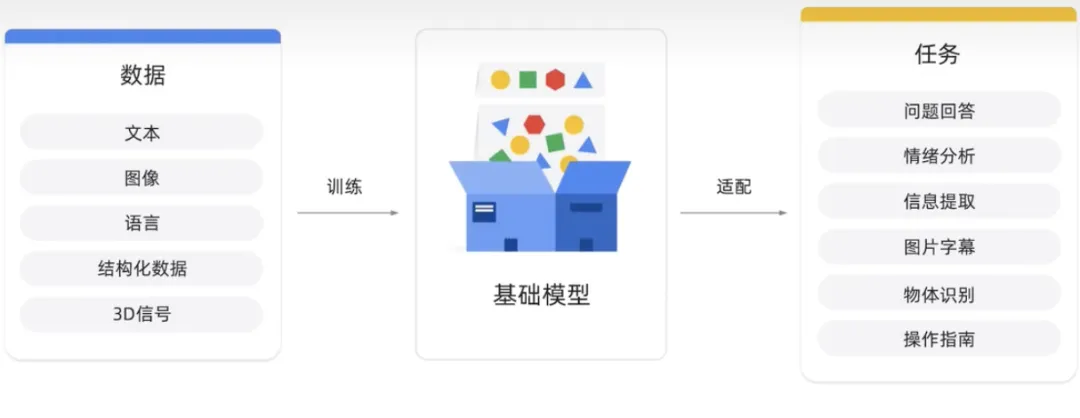
Model asas ialah model AI besar yang dipralatih pada sejumlah besar data. Matlamatnya adalah untuk menyesuaikan atau memperhalusi pelbagai tugas hiliran seperti analisis sentimen, imej, kapsyen dan pengecaman objek.
Model asas mempunyai potensi untuk merevolusikan banyak industri, termasuk penjagaan kesihatan, kewangan dan perkhidmatan pelanggan, di mana ia boleh digunakan untuk mengesan ramalan dan menyediakan sokongan pelanggan yang diperibadikan. OpenAI menyediakan bahasa sumber model asas, termasuk bahasa untuk sembang dan teks.

Model penglihatan asas termasuk resapan yang stabil, yang boleh menjana imej kualiti pakej dengan berkesan daripada penerangan teks. Katakan anda mempunyai kes di mana anda perlu mengumpulkan maklumat tentang perasaan pelanggan tentang produk atau perkhidmatan anda.

Generative AI Studio, dari perspektif pembangun, membolehkan anda mereka bentuk dan membina aplikasi dengan mudah tanpa menulis sebarang kod. Ia mempunyai editor visual yang memudahkan untuk membuat dan mengedit kandungan aplikasi. Terdapat juga enjin carian terbina dalam yang membolehkan pengguna mencari maklumat dalam aplikasi.
Terdapat juga enjin kecerdasan buatan perbualan yang membantu pengguna berinteraksi dengan aplikasi menggunakan bahasa semula jadi. Anda boleh membuat pembantu digital anda sendiri, enjin carian tersuai, pangkalan pengetahuan, apl latihan dan banyak lagi.

Alat pengerahan model membantu pembangun menggunakan model ke dalam persekitaran pengeluaran menggunakan beberapa pilihan penggunaan yang berbeza. Dan alat pemantauan model membantu pembangun memantau prestasi model ML dalam pengeluaran menggunakan papan pemuka dan banyak metrik yang berbeza.
Jika anda menganggap pembangunan aplikasi AI generatif sebagai pemasangan teka-teki yang kompleks, setiap keupayaan teknikal yang diperlukannya, seperti sains data, pembelajaran mesin dan pengaturcaraan, adalah setara dengan setiap bahagian teka-teki itu.
Adalah sukar bagi perusahaan tanpa pengumpulan teknikal untuk memahami kepingan teka-teki ini, dan menyusunnya menjadi satu tugas yang lebih sukar. Tetapi jika terdapat perkhidmatan yang boleh menyediakan perusahaan tradisional ini dengan keupayaan teknikal yang lemah dengan beberapa kepingan teka-teki yang telah dipasang sebelumnya, perusahaan tradisional ini boleh menyelesaikan keseluruhan teka-teki dengan lebih mudah dan cepat.
Berdasarkan situasi sebenar dalam pasaran domestik, pembangunan AI generatif tidaklah begitu optimistik seperti yang diramalkan oleh pengamal yang mengejar trend, mahupun pesimis seperti yang diterangkan oleh penentang.
Pengguna perusahaan mengejar keteguhan, ekonomi, keselamatan dan kebolehgunaan aplikasi, yang merupakan laluan yang sama sekali berbeza daripada AI generatif seperti model bahasa besar yang menghabiskan kos kuasa pengkomputeran yang tinggi semasa proses latihan untuk mencapai keupayaan yang lebih tinggi.
Isu teras di sebalik ini ialah dalam bidang AI generatif peringkat perusahaan dengan imaginasi yang lebih besar, perkara yang paling penting bukanlah betapa berkuasa model besar itu, tetapi bagaimana ia boleh berkembang daripada model asas kepada aplikasi khusus dalam pelbagai bidang .
Atas ialah kandungan terperinci Apakah AI generatif? Apakah jenis ciri yang ada. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!