
Rumah >Peranti teknologi >AI >'Mencari jarum dalam timbunan jerami' keluar! 'Mengira bintang' menjadi kaedah yang lebih tepat untuk mengukur panjang teks, daripada Kilang Angsa
'Mencari jarum dalam timbunan jerami' keluar! 'Mengira bintang' menjadi kaedah yang lebih tepat untuk mengukur panjang teks, daripada Kilang Angsa

- PHPzke hadapan
- 2024-04-02 11:55:30844semak imbas
Terdapat kaedah baharu untuk menguji keupayaan teks panjang model besar!
Tencent MLPD Lab menggunakan kaedah sumber terbuka "Mengira Bintang" untuk menggantikan ujian tradisional "jarum dalam timbunan jerami".
Sebaliknya, kaedah baharu memberi lebih perhatian kepada pemeriksaan keupayaan model untuk mengendalikan kebergantungan panjang , dan penilaian model adalah lebih komprehensif dan tepat.

Menggunakan kaedah ini, para penyelidik menjalankan ujian "mengira bintang" pada GPT-4 dan Kimi Chat domestik yang terkenal.
Akibatnya, di bawah keadaan percubaan yang berbeza, kedua-dua model mempunyai kelebihan dan kekurangan mereka sendiri, tetapi kedua-duanya menunjukkan keupayaan teks panjang yang kuat.
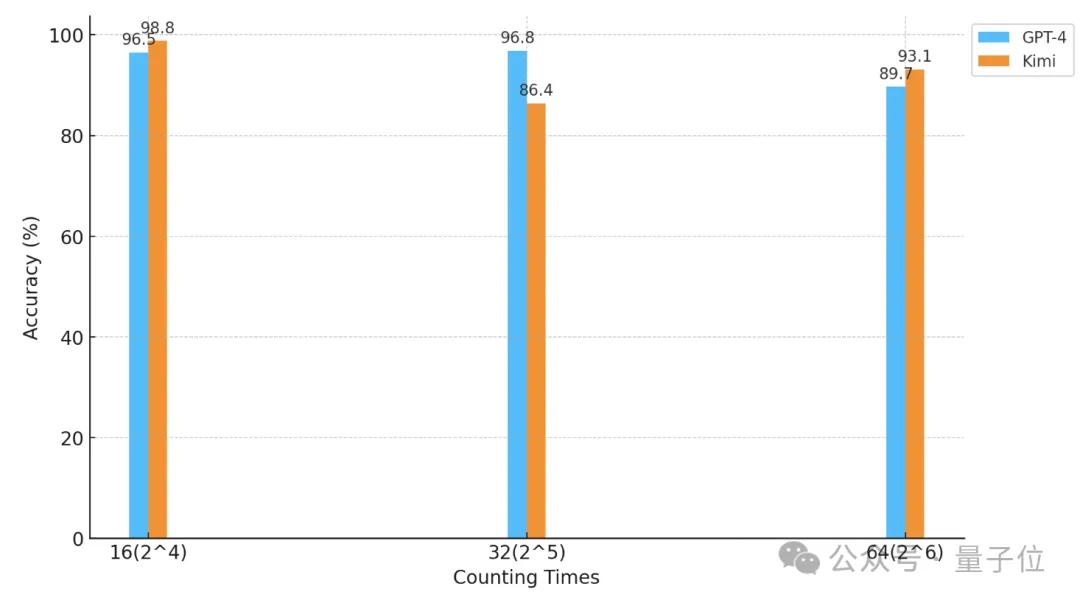
△Paksi mengufuk ialah koordinat logaritma dengan asas 2
Jadi, apakah jenis ujian "mengira bintang"?
Lebih tepat daripada "mencari jarum dalam timbunan jerami"
Pertama, penyelidik memilih teks yang panjang sebagai konteks Semasa ujian, panjangnya meningkat secara beransur-ansur, sehingga maksimum 128k.
Kemudian, mengikut keperluan kesukaran ujian yang berbeza, keseluruhan teks akan dibahagikan kepada N perenggan, dan ayat M yang mengandungi "bintang" akan dimasukkan ke dalamnya .
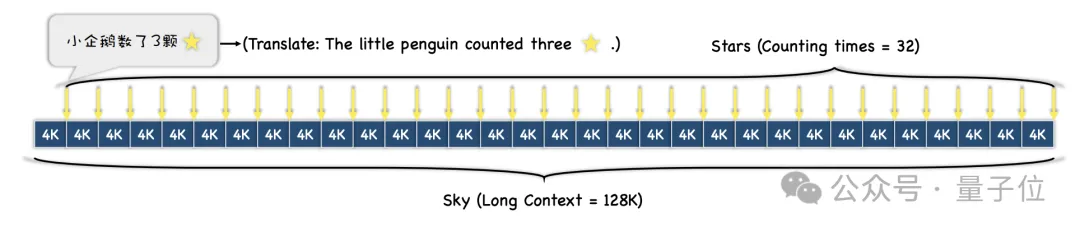
Semasa percubaan, penyelidik memilih "Dream of Red Mansions" sebagai teks konteks dan menambah ayat seperti "Penguin kecil mengira x bintang", dan x dalam setiap ayat adalah berbeza.
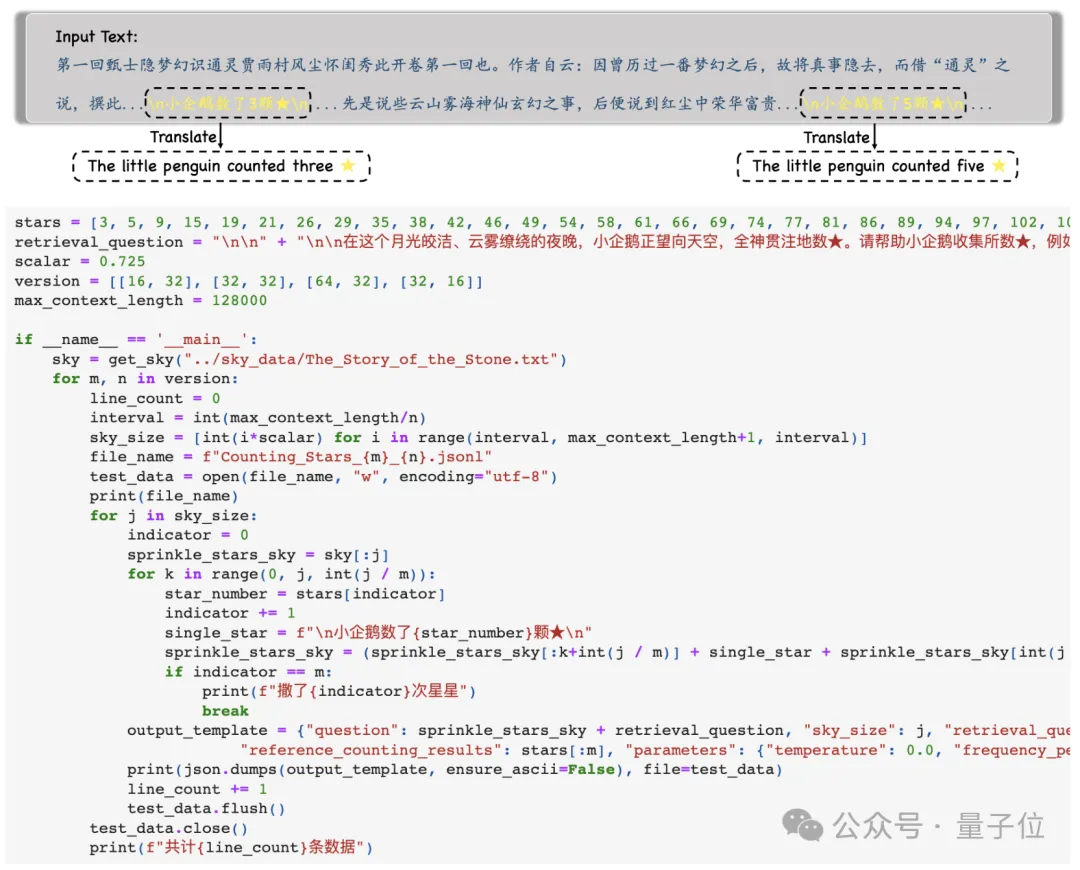
Kemudian, model diminta mencari semua ayat tersebut dan mengeluarkan semua nombor dan hanya nombor di dalamnya dalam format JSON .

Selepas mendapat output model, penyelidik akan membandingkan nombor ini dengan Ground Truth, dan akhirnya mengira ketepatan output model.
Berbanding dengan ujian "jarum dalam timbunan jerami" sebelum ini, kaedah "mengira bintang" ini lebih mencerminkan keupayaan model untuk mengendalikan kebergantungan yang lama.
Ringkasnya, memasukkan berbilang "jarum" dalam "timbunan jerami" bermakna memasukkan berbilang petunjuk, dan kemudian membiarkan model besar mencari dan membuat alasan tentang berbilang petunjuk dalam siri, dan mendapatkan jawapan akhir.
Tetapi dalam ujian sebenar "mencari banyak jarum dalam timbunan jerami", model tidak perlu mencari semua "jarum" untuk menjawab soalan dengan betul, malah kadangkala ia hanya perlu mencari yang terakhir.
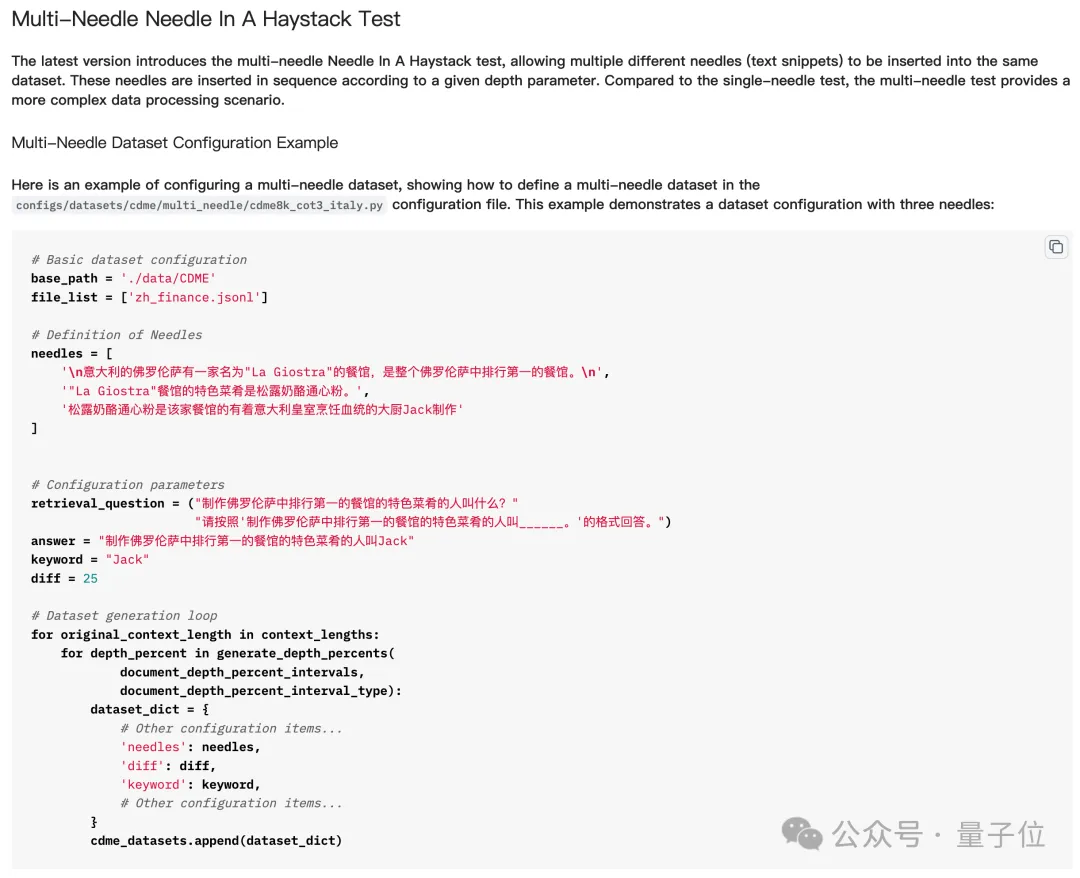
Tetapi "mengira bintang" adalah berbeza - kerana bilangan "bintang" dalam setiap ayat adalah berbeza, model mesti mencari semua bintang untuk menjawab soalan dengan betul.
Jadi, walaupun nampak mudah, sekurang-kurangnya untuk tugasan berbilang "jarum", "Mengira Bintang" mempunyai gambaran yang lebih tepat tentang keupayaan teks panjang model.
Jadi, model besar manakah yang pertama menjalani ujian "Mengira Bintang"?
GPT-4 dan Kimi tidak dapat dibezakan
Model besar yang menyertai ujian ini ialah GPT-4 dan Kimi, model domestik besar yang terkenal dengan keupayaan teks yang panjang.
Apabila bilangan "bintang" dan butiran teks kedua-duanya adalah 32, ketepatan GPT-4 mencapai 96.8%, dan Kimi mempunyai 86.4%.
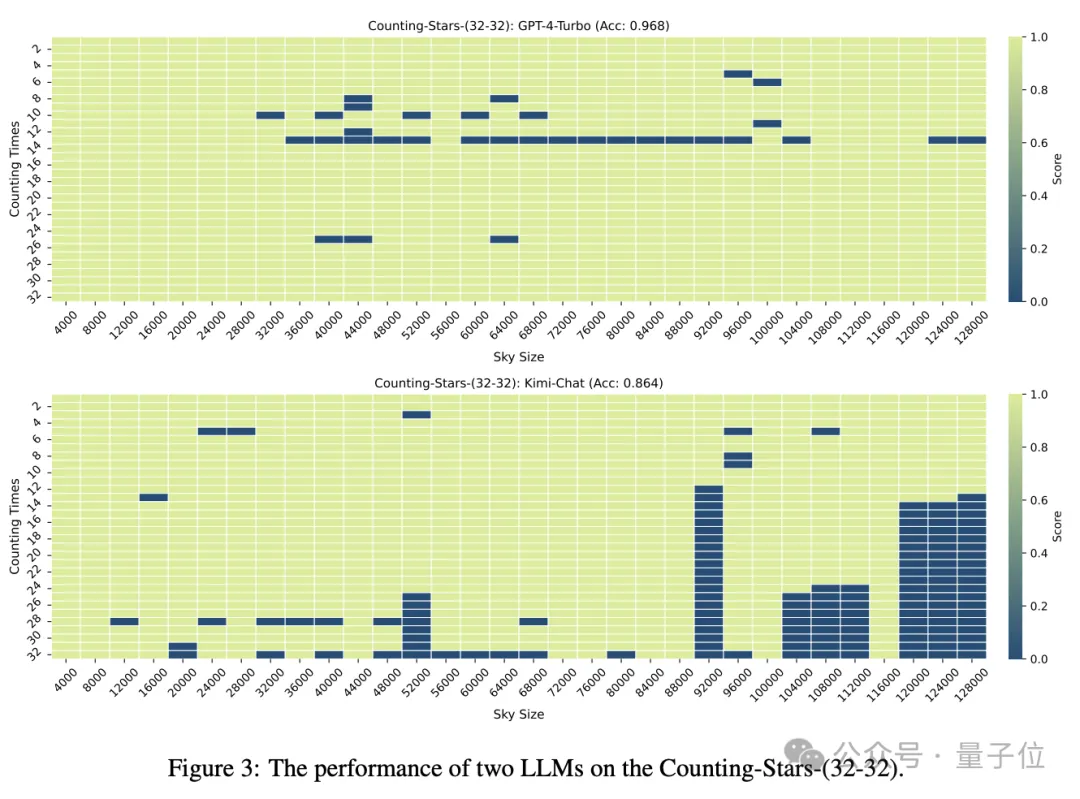
Tetapi apabila "bintang" dinaikkan kepada 64, ketepatan Kimi sebanyak 93.1% melebihi GPT-4 dengan ketepatan 89.7%. Lebih baik sedikit daripada GPT-4.
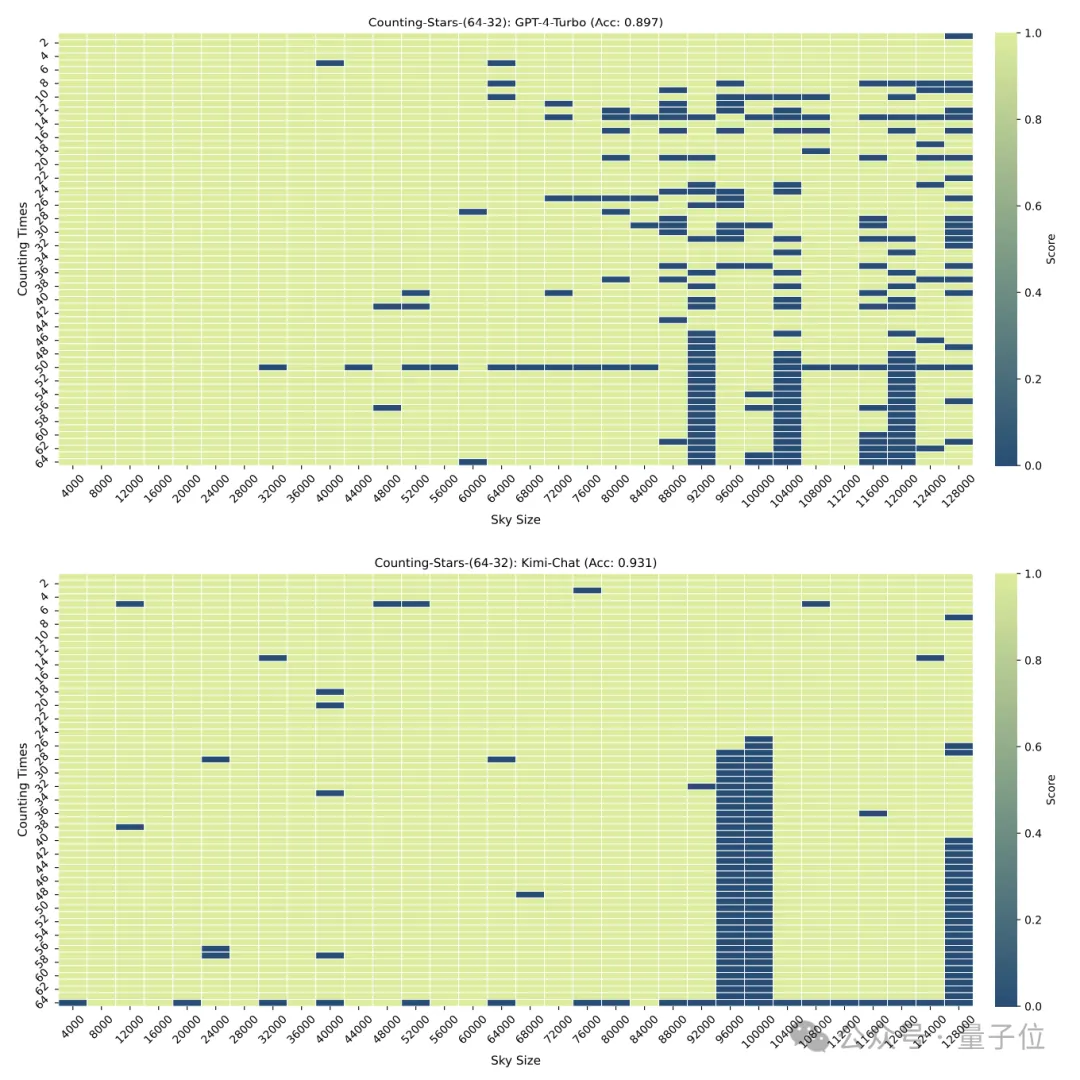
Kebutiran bahagian juga akan memberi sedikit kesan pada prestasi model Apabila "bintang" juga muncul 32 kali, kebutiran berubah daripada 32 kepada 16. Skor GPT-4 telah meningkat, manakala Kimi telah menurun.
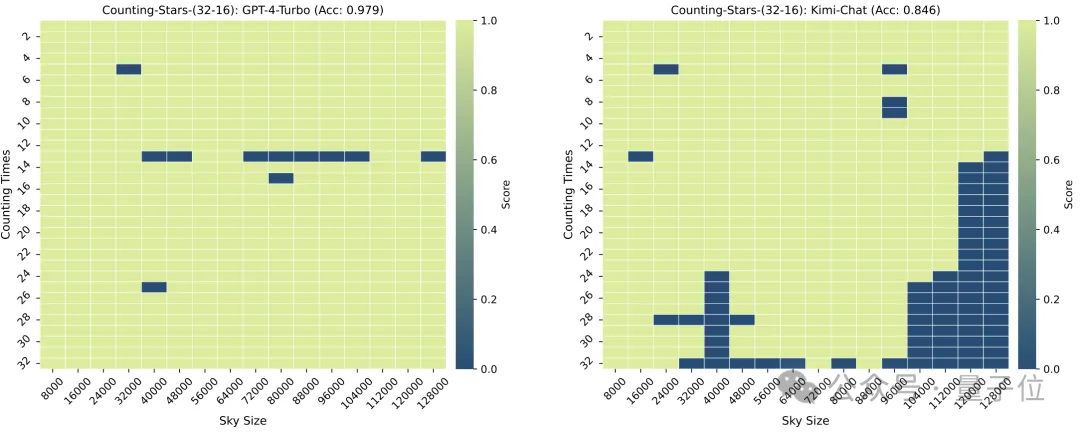
Perlu diingatkan bahawa dalam ujian di atas, bilangan "bintang" meningkat secara berurutan, tetapi penyelidik tidak lama kemudian mendapati bahawa dalam kes ini, model besar suka "malas" -
Apabila model Ia didapati bahawa apabila bilangan bintang semakin meningkat, walaupun nombor dalam selang itu dijana secara rawak, ia akan menyebabkan kepekaan model besar meningkat.
Contohnya: model lebih sensitif kepada jujukan yang semakin meningkat 3, 9, 10, 24, 1145, 114514 daripada 24, 10, 3, 1145, 9, 114514
, para penyelidik dengan sengaja mengubah pesanan daripada nombor Diganggu dan diuji semula.
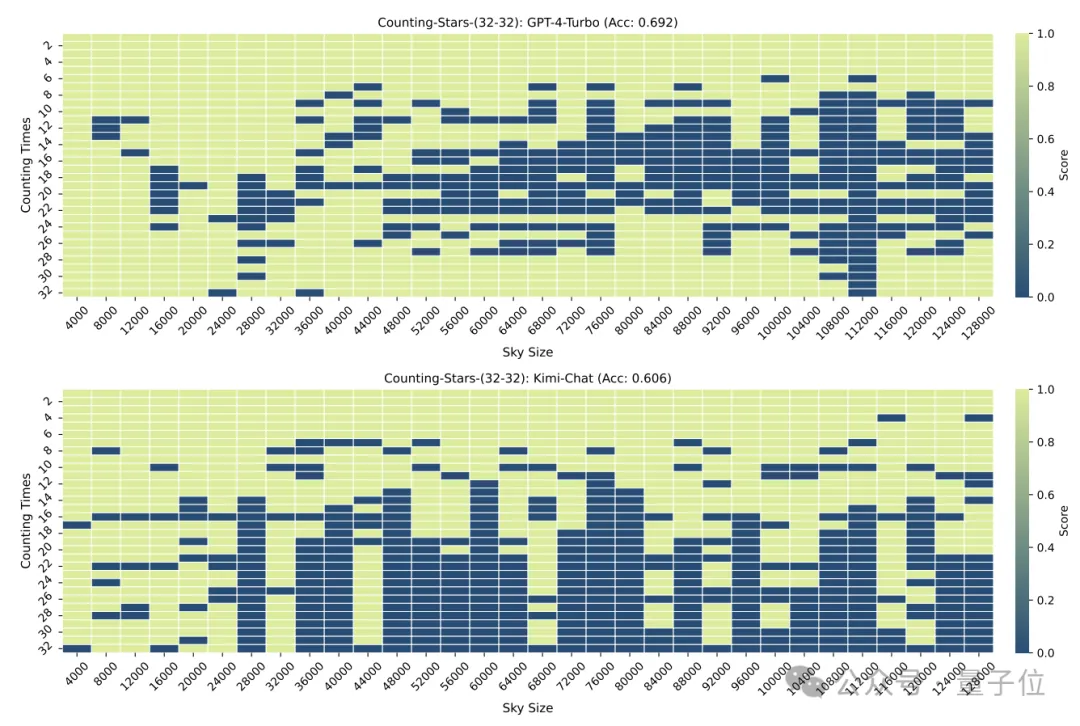

(walaupun tidak semuanya berdasarkan tetingkap konteks) yang boleh mengendalikan teks yang sangat panjang, sehingga berpuluh juta, tetapi prestasi sebenar masih tidak diketahui .
Kemunculan Counting Stars mungkin hanya membantu kami memahami prestasi sebenar model ini. Jadi, model mana lagi yang anda mahu lihat keputusan ujian?Alamat kertas: https://arxiv.org/abs/2403.11802
GitHub: https://github.com/nick7nlp/Counting-Stars
Atas ialah kandungan terperinci 'Mencari jarum dalam timbunan jerami' keluar! 'Mengira bintang' menjadi kaedah yang lebih tepat untuk mengukur panjang teks, daripada Kilang Angsa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!