
Rumah >Peranti teknologi >AI >Diikat untuk tempat pertama dengan GPT-4, penanda aras LMSYS menunjukkan bahawa model Claude-3 berprestasi baik
Diikat untuk tempat pertama dengan GPT-4, penanda aras LMSYS menunjukkan bahawa model Claude-3 berprestasi baik

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-28 17:26:43603semak imbas

Berita pada 28 Mac, menurut laporan penanda aras terbaharu yang dikeluarkan oleh LMSYS Org, Claude-3 mendapat markah melepasi GPT-4 dan menjadi model bahasa besar "terbaik" di platform.
Tapak web ini mula-mula memperkenalkan LMSYS Org, yang merupakan organisasi penyelidikan yang dicipta bersama oleh University of California, Berkeley, University of California, San Diego, dan Carnegie Mellon University.
Sistem ini melancarkan Chatbot Arena, platform penanda aras untuk model bahasa besar (LLM), yang menggunakan sumber ramai untuk menguji produk model besar secara anonim dan secara rawak berdasarkan sistem pemarkahan Elo yang digunakan secara meluas dalam permainan kompetitif seperti catur.
Melalui keputusan penilaian yang dijana oleh pengundian pengguna, sistem akan secara rawak memilih dua robot model besar yang berbeza untuk bersembang dengan pengguna setiap kali, dan membenarkan pengguna memilih produk model besar yang berprestasi lebih baik secara keseluruhan secara tanpa nama.
Arena Chatbot Sejak dilancarkan tahun lepas, GPT-4 telah berada di kedudukan teratas dan malah menjadi standard emas untuk menilai model besar.
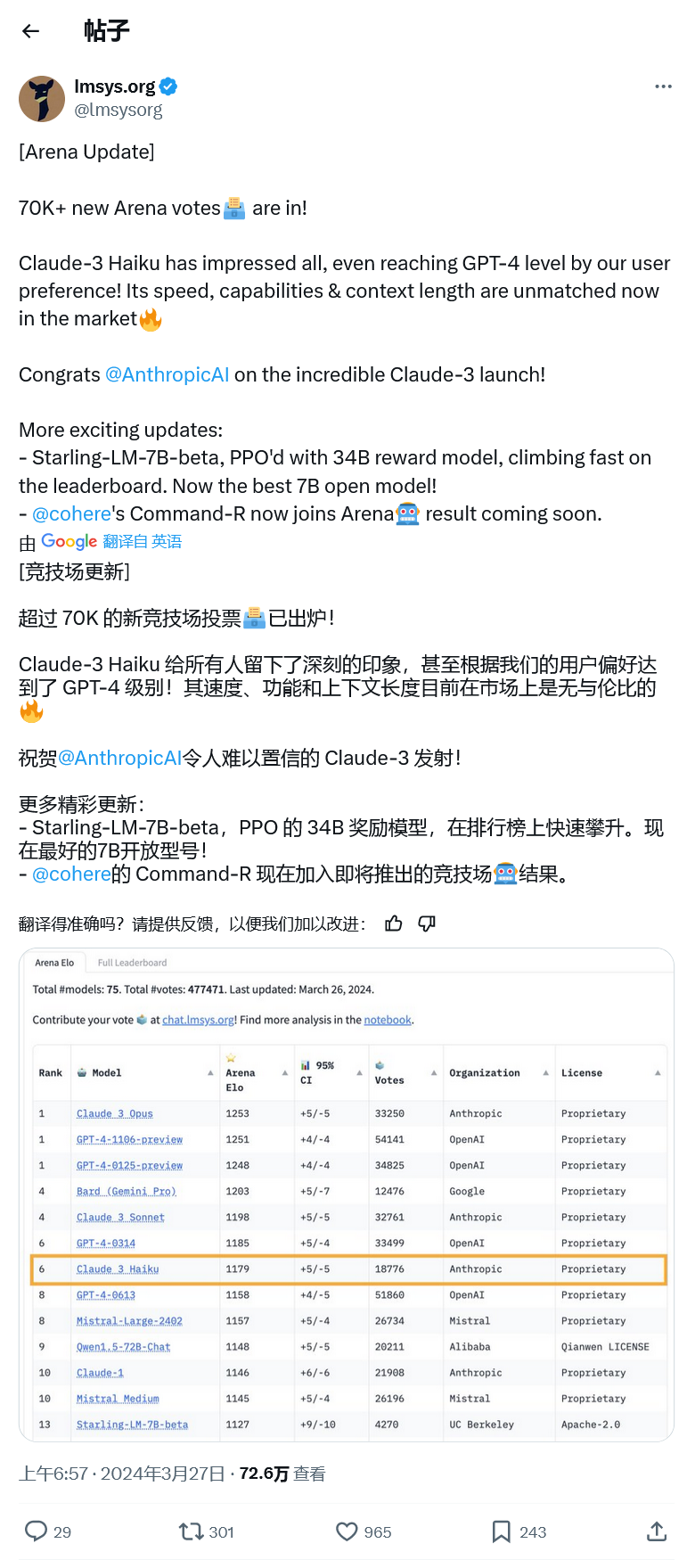
Walau bagaimanapun, semalam Claude 3 Opus Anthropic menewaskan GPT-4 dengan margin kecil 1253 berbanding 1251, dan LLM OpenAI telah ditolak daripada tempat teratas. Oleh kerana skor terlalu hampir, agensi itu membenarkan Claude 3 dan GPT-4 seri di tempat pertama disebabkan pertimbangan kadar ralat, dan versi pratonton GPT-4 yang lain juga terikat di tempat pertama.
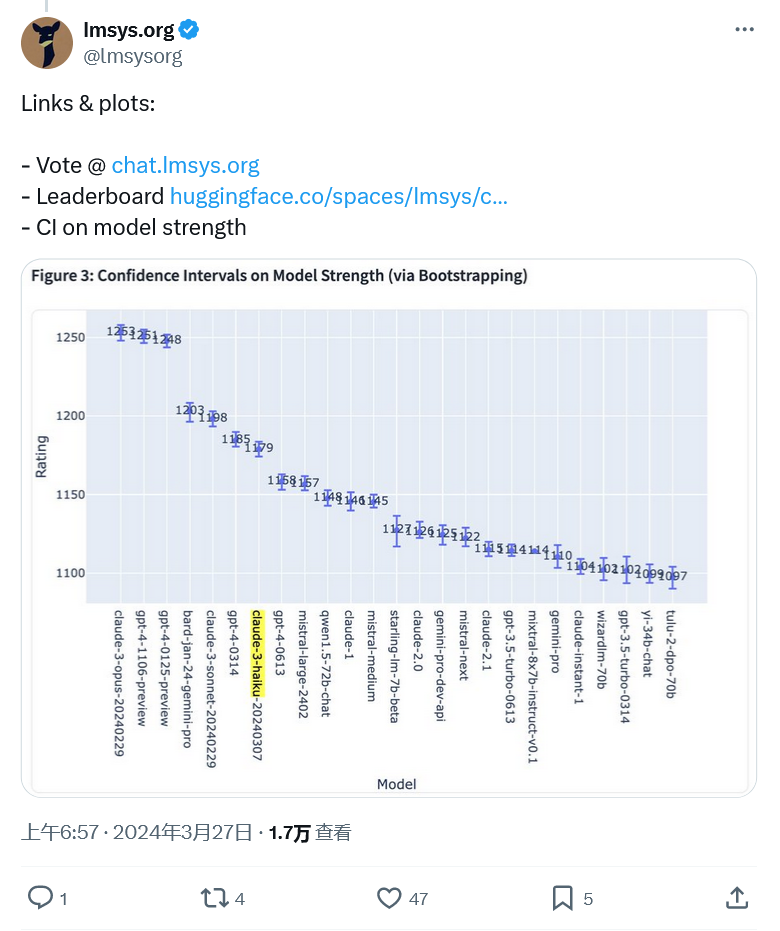
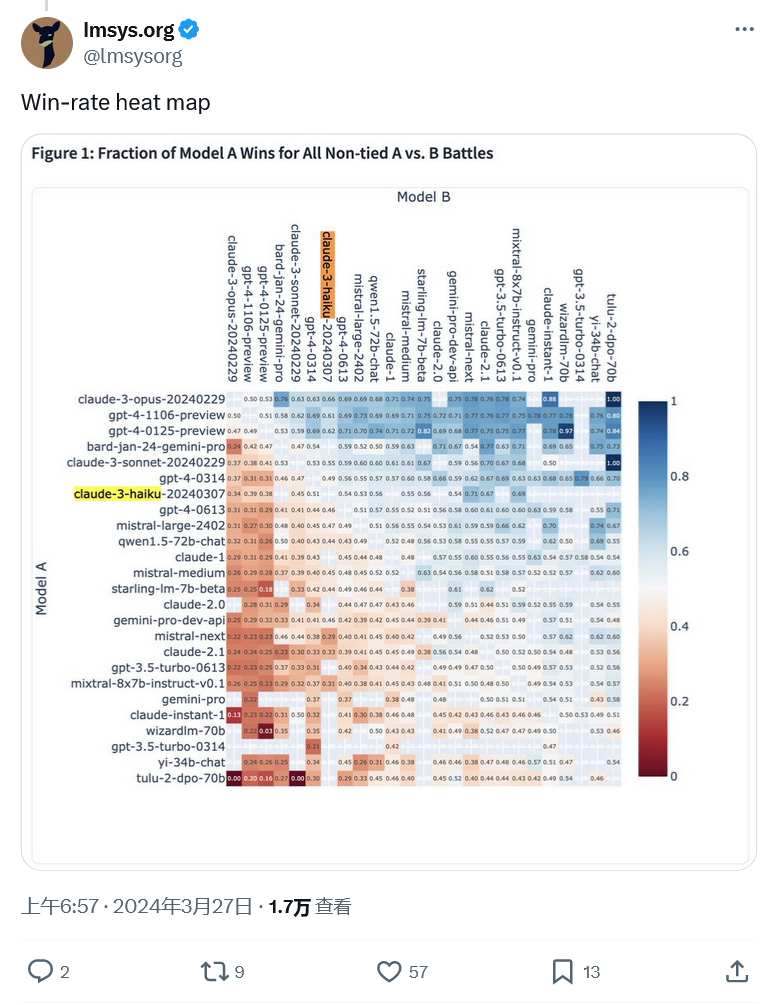
Atas ialah kandungan terperinci Diikat untuk tempat pertama dengan GPT-4, penanda aras LMSYS menunjukkan bahawa model Claude-3 berprestasi baik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!