
Rumah >Peranti teknologi >AI >Video AI boleh dihasilkan daripada hanya satu gambar! Model penyebaran baharu Google menjadikan watak bergerak
Video AI boleh dihasilkan daripada hanya satu gambar! Model penyebaran baharu Google menjadikan watak bergerak

- WBOYke hadapan
- 2024-03-28 15:40:16688semak imbas
Anda hanya memerlukan foto dan sekeping audio untuk terus menjana video watak bercakap!
Baru-baru ini, penyelidik daripada Google mengeluarkan model penyebaran pelbagai mod VLOGGER, membawa kita selangkah lebih dekat dengan manusia digital maya.

Alamat kertas: https://enriccorona.github.io/vlogger/paper.pdf
Vlogger boleh mengumpul satu imej input dan menggunakan teks atau pemacu audio untuk menjana video ucapan manusia, termasuk lisan Bentuk, ekspresi, pergerakan badan dan sebagainya semuanya sangat semula jadi.
let melihat beberapa contoh terlebih dahulu:




Jika anda merasakan bahawa penggunaan suara orang lain dalam video itu agak tidak konsisten, editor akan membantu anda mematikan bunyi:

Ia boleh dilihat bahawa keseluruhan kesan yang dihasilkan adalah sangat elegan dan semula jadi.
VLOGGER membina kejayaan model resapan generatif baru-baru ini, termasuk model yang menterjemah manusia ke dalam gerakan 3D, dan seni bina berasaskan resapan baharu untuk mempertingkatkan imej yang dihasilkan teks dengan kawalan temporal dan ruang.

VLOGGER boleh menjana video berkualiti tinggi dengan panjang berubah-ubah, dan video ini boleh dikawal dengan mudah dengan representasi wajah dan badan yang lebih maju.

Sebagai contoh, kita boleh meminta orang dalam video yang dijana untuk diam:

atau tutup mata mereka:

model yang serupa dengan model sebelumnya
tidak memerlukan Ia dilatih kepada individu, tidak bergantung pada pengesanan muka dan pemangkasan, dan termasuk pergerakan badan, batang tubuh dan latar belakang - membentuk prestasi manusia biasa yang boleh berkomunikasi.



🎜🎜🎜Para penyelidik menilai VLOGGER pada tiga penanda aras berbeza, menunjukkan bahawa model itu mencapai prestasi terkini dari segi kualiti imej, pemeliharaan identiti dan ketekalan temporal. 🎜🎜

VLOGGER
Matlamat VLOGGER adalah untuk menjana video realistik panjang berubah-ubah yang menggambarkan keseluruhan proses orang sasaran bercakap, termasuk pergerakan kepala dan gerak isyarat.

Seperti yang ditunjukkan di atas, diberikan satu imej input yang ditunjukkan dalam lajur 1 dan sampel input audio, satu siri imej komposit ditunjukkan di lajur kanan.
Termasuk menjana pergerakan kepala, pandangan, kerdipan mata, pergerakan bibir dan sesuatu yang model terdahulu tidak boleh lakukan, menghasilkan bahagian atas badan dan gerak isyarat, yang merupakan kemajuan besar dalam sintesis dipacu audio.
VLOGGER menggunakan saluran paip dua peringkat berdasarkan model resapan rawak untuk mensimulasikan pemetaan satu-ke-banyak daripada pertuturan ke video.
Rangkaian pertama mengambil bentuk gelombang audio sebagai input untuk menjana kawalan pergerakan badan yang bertanggungjawab untuk pandangan, ekspresi muka dan gerak isyarat sepanjang video sasaran.
Rangkaian kedua ialah model terjemahan imej-ke-imej temporal yang memanjangkan model penyebaran imej besar untuk menggunakan kawalan badan yang diramalkan untuk menjana bingkai yang sepadan. Untuk menyelaraskan proses ini kepada identiti tertentu, rangkaian memperoleh imej rujukan orang sasaran.
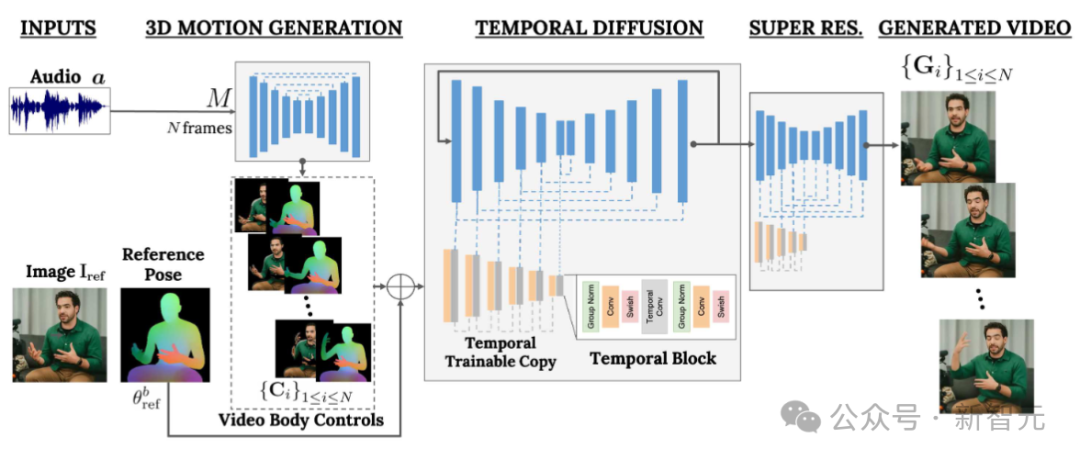
VLOGGER menggunakan model badan 3D berasaskan statistik untuk mengawal selia proses penjanaan video. Memandangkan imej input, parameter bentuk yang diramalkan mengekodkan sifat geometri identiti sasaran.
Pertama, rangkaian M mengambil pertuturan input dan menjana satu siri N bingkai ekspresi muka dan pose badan 3D.
Perwakilan padat badan 3D yang bergerak kemudiannya dipaparkan untuk bertindak sebagai kawalan 2D semasa peringkat penjanaan video. Imej ini, bersama-sama dengan imej input, berfungsi sebagai input kepada model penyebaran temporal dan modul resolusi super.
Penjanaan gerakan dipacu audio
Rangkaian saluran paip pertama direka untuk meramalkan gerakan berdasarkan pertuturan input. Di samping itu, teks input ditukar kepada bentuk gelombang melalui model teks ke pertuturan, dan audio yang dijana diwakili sebagai Mel-Spectrograms standard.
Saluran paip adalah berdasarkan seni bina Transformer dan mempunyai empat lapisan perhatian berbilang kepala dalam dimensi masa. Termasuk pengekodan kedudukan nombor bingkai dan langkah resapan, serta membenamkan MLP untuk audio input dan langkah resapan.
Dalam setiap bingkai, gunakan topeng sebab untuk menjadikan model hanya fokus pada bingkai sebelumnya. Model ini dilatih menggunakan video panjang berubah-ubah (seperti dataset TalkingHead-1KH) untuk menjana jujukan yang sangat panjang.
Para penyelidik menggunakan parameter anggaran berasaskan statistik bagi model badan manusia 3D untuk menjana perwakilan kawalan perantaraan untuk video sintetik.
Model ini mengambil kira ekspresi muka dan pergerakan badan untuk menjana gerak isyarat ekspresif dan dinamik yang lebih baik.
Di samping itu, kerja penjanaan muka sebelum ini biasanya bergantung pada imej yang melencong, tetapi dalam seni bina berasaskan penyebaran, kaedah ini telah diabaikan.
Pengarang mencadangkan menggunakan imej yang herot untuk membimbing proses penjanaan, yang memudahkan tugas rangkaian dan membantu mengekalkan identiti subjek watak.
Menjana manusia yang bercakap dan bergerak
Matlamat seterusnya adalah untuk melakukan pemprosesan gerakan pada imej input seseorang supaya ia mengikuti pergerakan badan dan muka yang diramalkan sebelum ini.
Diinspirasikan oleh ControlNet, para penyelidik membekukan model yang dilatih pada mulanya dan menggunakan kawalan masa input untuk membuat salinan lapisan pengekodan yang dimulakan sifar.
Pengarang menyilangkan lapisan konvolusi satu dimensi dalam domain masa Rangkaian dilatih dengan mendapatkan bingkai dan kawalan N berturut-turut, dan menjana video aksi watak rujukan berdasarkan kawalan input.
Model ini dilatih menggunakan set data MENTOR yang dibina oleh penulis Kerana semasa proses latihan, rangkaian memperoleh satu siri bingkai berturut-turut dan imej rujukan sewenang-wenangnya, jadi secara teori mana-mana bingkai video boleh ditetapkan sebagai rujukan.
Dalam amalan, bagaimanapun, pengarang memilih untuk sampel rujukan lebih jauh daripada klip sasaran, kerana contoh yang lebih dekat menawarkan potensi generalisasi yang kurang.
Rangkaian dilatih dalam dua peringkat, mula-mula mempelajari lapisan kawalan baharu pada bingkai tunggal, dan kemudian berlatih pada video dengan menambahkan komponen temporal. Ini membolehkan penggunaan kumpulan besar pada peringkat pertama dan pembelajaran tugasan ulang kepala yang lebih pantas.
Kadar pembelajaran yang digunakan oleh penulis ialah 5e-5, dan model imej dilatih dengan saiz langkah 400k dan saiz kelompok 128 dalam kedua-dua peringkat.
Kepelbagaian
Rajah di bawah menunjukkan taburan pelbagai video sasaran yang dijana daripada imej input. Lajur paling kanan menunjukkan kepelbagaian piksel yang diperoleh daripada 80 video yang dijana.

Walaupun latar belakang kekal tetap, kepala dan badan orang itu bergerak dengan ketara (merah bermakna kepelbagaian warna piksel yang lebih tinggi), dan, walaupun terdapat kepelbagaian, semua video kelihatan sama Sangat realistik. Salah satu aplikasi
Pengeditan Video

adalah untuk mengedit video sedia ada. Dalam kes ini, VLOGGER mengambil video dan menukar ekspresi subjek dengan menutup mulut atau mata mereka, sebagai contoh.
Secara praktikal, pengarang mengambil kesempatan daripada fleksibiliti model resapan untuk membaiki bahagian imej yang perlu ditukar, menjadikan pengeditan video konsisten dengan piksel asal yang tidak berubah.
Terjemahan Video
Salah satu aplikasi utama model ialah terjemahan video. Dalam kes ini, VLOGGER mengambil video sedia ada dalam bahasa tertentu dan mengedit bibir serta kawasan muka untuk diselaraskan dengan audio baharu (cth. Sepanyol).
Atas ialah kandungan terperinci Video AI boleh dihasilkan daripada hanya satu gambar! Model penyebaran baharu Google menjadikan watak bergerak. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!