

 Peranti teknologiAICLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Peranti teknologiAICLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjangCLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang

Ditulis di hadapan & pemahaman peribadi penulis
Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Kenderaan autonomi yang memandu di jalan raya hanya boleh mendapatkan maklumat yang tepat melalui modul persepsi Hanya selepas penderiaan hasilnya boleh modul pengawalan dan kawalan hiliran dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat.
Algoritma persepsi BEV berdasarkan penglihatan tulen telah mendapat perhatian meluas daripada industri dan akademia kerana kos perkakasannya yang rendah dan penggunaan yang mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran. Dalam beberapa tahun kebelakangan ini, banyak algoritma persepsi visual berdasarkan ruang BEV telah muncul satu demi satu dan telah menunjukkan prestasi persepsi yang sangat baik pada set data awam.
Pada masa ini, algoritma persepsi berdasarkan ruang BEV boleh dibahagikan secara kasar kepada dua jenis model algoritma berdasarkan cara membina ciri BEV:
- Satu jenis ialah kaedah pembinaan ciri BEV hadapan yang diwakili oleh algoritma LSS jenis ini model algoritma persepsi adalah pertama Rangkaian anggaran kedalaman dalam model persepsi digunakan untuk meramalkan maklumat ciri semantik dan taburan kebarangkalian kedalaman diskret bagi setiap piksel peta ciri, dan kemudian maklumat ciri semantik yang diperolehi dan kebarangkalian kedalaman diskret digunakan untuk membina ciri frustum semantik menggunakan operasi produk luar dan kaedah lain digunakan untuk akhirnya menyelesaikan proses pembinaan ciri ruang BEV.
- Jenis lain ialah kaedah pembinaan ciri BEV terbalik yang diwakili oleh algoritma BEVFormer jenis model algoritma persepsi ini mula-mula secara eksplisit menjana titik koordinat voxel 3D dalam ruang BEV yang dirasakan, dan kemudian menggunakan parameter dalaman dan luaran kamera untuk menukar. 3D Titik koordinat voxel diunjurkan kembali ke sistem koordinat imej, dan ciri piksel pada kedudukan ciri yang sepadan diekstrak dan diagregatkan untuk membina ciri BEV dalam ruang BEV.
Walaupun kedua-dua algoritma boleh menjana ciri dengan tepat dalam ruang BEV dan mencapai hasil persepsi 3D, terdapat dua masalah berikut dalam algoritma persepsi sasaran 3D semasa berdasarkan ruang BEV, seperti algoritma BEVFormer:
- Masalah 1 : Sejak rangka kerja keseluruhan model algoritma persepsi BEVFormer menggunakan struktur rangkaian Pengekod-Penyahkod, idea utama adalah menggunakan modul Pengekod untuk mendapatkan ciri dalam ruang BEV, dan kemudian menggunakan modul Penyahkod untuk meramalkan hasil persepsi akhir, dan membandingkan hasil persepsi output dengan Proses pengiraan kerugian untuk mencapai ciri ruang BEV yang diramalkan oleh model. Walau bagaimanapun, kaedah kemas kini parameter model rangkaian ini akan terlalu bergantung pada prestasi persepsi modul Penyahkod, yang mungkin membawa kepada masalah bahawa ciri BEV output oleh model tidak sejajar dengan ciri BEV nilai sebenar, dengan itu mengehadkan lagi prestasi akhir model persepsi.
- Soalan 2: Memandangkan modul Penyahkod model algoritma persepsi BEVFormer masih menggunakan langkah-langkah modul perhatian kendiri ->modul perhatian silang->rangkaian neural suapan ke hadapan dalam Transformer untuk melengkapkan pembinaan ciri Pertanyaan dan keluarkan hasil pengesanan akhir Keseluruhan proses masih merupakan model kotak hitam, tidak mempunyai kebolehtafsiran yang baik. Pada masa yang sama, terdapat juga ketidakpastian yang besar dalam proses pemadanan satu dengan satu antara Object Query dan sasaran nilai sebenar semasa proses latihan model.
Untuk menyelesaikan masalah model algoritma persepsi BEVFormer, kami menambah baiknya dan mencadangkan model algoritma pengesanan 3D CLIP-BEVFormer berdasarkan imej sekeliling. Dengan memperkenalkan kaedah pembelajaran kontrastif, kami meningkatkan keupayaan model untuk membina ciri BEV dan mencapai prestasi persepsi peringkat terkemuka pada set data nuScenes.
Pautan artikel: https://arxiv.org/pdf/2403.08919.pdf
Keseluruhan seni bina & butiran model rangkaian
Sebelum memperkenalkan butiran CLIP-BEVFormer persepsi algoritma, model yang dicadangkan dalam artikel ini rajah berikut menunjukkan Struktur rangkaian keseluruhan algoritma CLIP-BEVFormer diperkenalkan.
 Carta alir keseluruhan model algoritma persepsi CLIP-BEVFormer yang dicadangkan dalam artikel ini
Carta alir keseluruhan model algoritma persepsi CLIP-BEVFormer yang dicadangkan dalam artikel ini
Dapat dilihat daripada carta alir keseluruhan algoritma bahawa model algoritma CLIP-BEVFormer yang dicadangkan dalam artikel ini ditambah baik berdasarkan model algoritma BEVFormer Berikut adalah ulasan ringkas proses pelaksanaan model algoritma persepsi BEVFormer . Pertama, model algoritma BEVFormer memasukkan data imej sekeliling yang dikumpul oleh penderia kamera dan menggunakan rangkaian pengekstrakan ciri imej 2D untuk mengekstrak maklumat ciri semantik berbilang skala bagi imej sekeliling input. Kedua, modul Pengekod yang mengandungi perhatian kendiri sementara dan perhatian silang ruang digunakan untuk melengkapkan proses penukaran ciri imej 2D kepada ciri spatial BEV. Kemudian, satu set Pertanyaan Objek dijana dalam bentuk taburan normal dalam ruang persepsi 3D dan dihantar ke modul Penyahkod untuk melengkapkan penggunaan interaktif ciri spatial dengan keluaran ciri ruang BEV oleh modul Pengekod. Akhir sekali, rangkaian neural suapan digunakan untuk meramalkan ciri semantik yang ditanya oleh Object Query, dan hasil klasifikasi dan regresi akhir model rangkaian adalah output. Pada masa yang sama, semasa proses latihan model algoritma BEVFormer, strategi padanan Hungaria satu dengan satu digunakan untuk melengkapkan proses pengedaran sampel positif dan negatif, dan klasifikasi dan kerugian regresi digunakan untuk melengkapkan proses kemas kini bagi parameter model rangkaian keseluruhan. Proses pengesanan keseluruhan model algoritma BEVFormer boleh dinyatakan dengan formula matematik berikut:
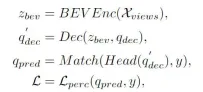
di mana, dalam formula mewakili modul pengekstrakan ciri Pengekod dalam algoritma BEVFormer, mewakili modul penyahkod Penyahkod dalam algoritma BEVFormer, dan mewakili nilai sebenar dalam set data Label sasaran Nilai, mewakili output hasil persepsi 3D oleh model algoritma BEVFormer semasa.
Penjanaan nilai sebenar BEV
Seperti yang dinyatakan di atas, kebanyakan algoritma pengesanan sasaran 3D sedia ada berdasarkan ruang BEV tidak menyelia secara eksplisit ciri ruang BEV yang dijana, menyebabkan ciri BEV penjanaan model mungkin tidak konsisten dengan ciri BEV sebenar Perbezaan dalam pengedaran ciri spatial BEV ini akan menyekat prestasi persepsi akhir model. Berdasarkan pertimbangan ini, kami mencadangkan modul Ground Truth BEV Idea teras kami dalam mereka bentuk modul ini adalah untuk membolehkan ciri BEV yang dihasilkan oleh model diselaraskan dengan ciri BEV nilai sebenar semasa, dengan itu meningkatkan prestasi model.
Secara khusus, seperti yang ditunjukkan dalam rajah rangka kerja keseluruhan rangkaian, kami menggunakan pengekod kebenaran tanah () untuk mengekod label kategori dan maklumat kedudukan kotak sempadan ruang bagi sebarang contoh kebenaran tanah pada peta ciri BEV :
Dimensi ciri dalam formula mempunyai saiz yang sama dengan peta ciri BEV yang dijana, mewakili maklumat ciri yang dikodkan bagi sasaran nilai sebenar. Semasa proses pengekodan, kami menggunakan dua bentuk, satu ialah model bahasa besar (LLM), dan satu lagi ialah perceptron berbilang lapisan (MLP) Melalui keputusan eksperimen, kami mendapati bahawa kedua-dua kaedah pada asasnya mencapai prestasi yang sama.
Selain itu, untuk meningkatkan lagi maklumat sempadan sasaran sebenar pada peta ciri BEV, kami memangkas sasaran sebenar pada peta ciri BEV mengikut kedudukan spatialnya, dan menggunakan pengumpulan pada operasi pemangkasan ciri untuk membina perwakilan maklumat ciri yang sepadan Proses ini boleh dinyatakan dalam bentuk berikut:
Akhir sekali, untuk menyelaraskan lagi ciri BEV yang dihasilkan oleh model dengan ciri BEV nilai sebenar, kami menggunakan kaedah pembelajaran kontrastif untuk mengoptimumkan kedua-dua kategori Hubungan elemen dan jarak antara ciri BEV, proses pengoptimuman boleh dinyatakan dalam bentuk berikut:
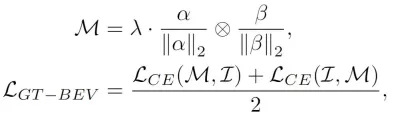
di mana jumlah dalam formula masing-masing mewakili matriks persamaan antara ciri BEV yang dihasilkan dan ciri BEV nilai sebenar, mewakili perbandingan Faktor skala logik dalam pembelajaran mewakili operasi pendaraban antara matriks dan mewakili fungsi kehilangan entropi silang. Melalui kaedah pembelajaran kontrastif di atas, kaedah yang kami cadangkan dapat memberikan panduan ciri yang lebih jelas untuk ciri BEV yang dihasilkan dan meningkatkan keupayaan persepsi model.
Interaksi pertanyaan sasaran nilai sebenar
Bahagian ini juga disebut dalam artikel sebelumnya, Pertanyaan Objek dalam model algoritma persepsi BEVFormer berinteraksi dengan ciri BEV yang dihasilkan melalui modul Penyahkod untuk mendapatkan ciri pertanyaan sasaran yang sepadan. keseluruhan proses Ia masih merupakan proses kotak hitam, kurang pemahaman proses yang lengkap. Untuk menangani masalah ini, kami memperkenalkan modul interaksi pertanyaan nilai kebenaran, yang menggunakan sasaran nilai kebenaran untuk melaksanakan interaksi ciri BEV modul Dekoder untuk merangsang proses pembelajaran parameter model. Khususnya, kami memperkenalkan output maklumat pengekodan sasaran kebenaran oleh modul pengekod kebenaran () ke dalam Pertanyaan Objek untuk mengambil bahagian dalam proses penyahkodan modul Penyahkod Seperti Pertanyaan Objek biasa, kami mengambil bahagian dalam modul perhatian diri yang sama, modul perhatian silang dan Rangkaian saraf suapan ke hadapan mengeluarkan hasil persepsi akhir. Walau bagaimanapun, perlu diingat bahawa semasa proses penyahkodan, semua Object Query menggunakan pengkomputeran selari untuk mengelakkan kebocoran maklumat sasaran nilai sebenar. Keseluruhan proses interaksi pertanyaan sasaran nilai kebenaran boleh dinyatakan secara abstrak dalam bentuk berikut:
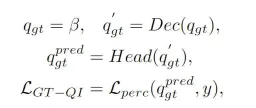
Antaranya, dalam formula mewakili Pertanyaan Objek yang dimulakan, dan mewakili hasil output Pertanyaan Objek nilai sebenar melalui modul Dekoder dan kepala pengesanan penderiaan masing-masing. Dengan memperkenalkan proses interaksi sasaran nilai sebenar dalam proses latihan model, modul interaksi pertanyaan sasaran nilai kebenaran yang kami cadangkan boleh merealisasikan interaksi antara pertanyaan sasaran nilai sebenar dan ciri BEV nilai sebenar, dengan itu membantu proses kemas kini parameter bagi modul Penyahkod model.
Hasil eksperimen & penunjuk penilaian
Bahagian analisis kuantitatif
Untuk mengesahkan keberkesanan model algoritma CLIP-BEVFormer yang kami cadangkan, kami melakukan pada set data kesan nuScenes dan panjang persepsi daripada 3D kategori sasaran dalam set data. Eksperimen yang berkaitan telah dijalankan dari perspektif taburan ekor dan keteguhan Jadual berikut menunjukkan perbandingan ketepatan antara model algoritma yang kami cadangkan dan model algoritma persepsi 3D yang lain pada set data nuScenes.
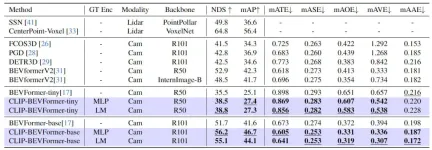
Hasil perbandingan antara kaedah yang dicadangkan dalam artikel ini dan model algoritma persepsi lain
Dalam bahagian percubaan ini, kami menilai prestasi persepsi di bawah konfigurasi model yang berbeza Secara khusus, kami menggunakan model algoritma CLIP-BEVFormer Dalam varian kecil dan asas BEVFormer. Selain itu, kami juga meneroka kesan penggunaan model CLIP terlatih atau lapisan MLP sebagai pengekod sasaran kebenaran tanah pada prestasi persepsi model. Ia boleh dilihat daripada keputusan eksperimen bahawa sama ada ia adalah varian kecil atau asas asal, selepas menggunakan algoritma CLIP-BEVFormer yang kami cadangkan, penunjuk NDS dan mAP mempunyai peningkatan prestasi yang stabil. Di samping itu, melalui keputusan percubaan, kita boleh mendapati bahawa model algoritma yang kami cadangkan tidak sensitif sama ada lapisan MLP atau model bahasa dipilih untuk pengekod sasaran kebenaran tanah Kefleksibelan ini boleh menjadikan algoritma CLIP-BEVFormer yang kami cadangkan lebih banyak cekap. Boleh disesuaikan dan mudah dipasang pada kenderaan. Ringkasnya, penunjuk prestasi pelbagai varian model algoritma kami yang dicadangkan secara konsisten menunjukkan bahawa model algoritma CLIP-BEVFormer yang dicadangkan mempunyai keteguhan persepsi yang baik dan boleh mencapai prestasi pengesanan yang cemerlang di bawah kerumitan model dan jumlah parameter yang berbeza.
Selain mengesahkan prestasi cadangan CLIP-BEVFormer kami pada tugas persepsi 3D, kami juga menjalankan eksperimen pengedaran ekor panjang untuk menilai keteguhan dan generalisasi algoritma kami dalam menghadapi kehadiran pengedaran ekor panjang dalam data set. keupayaan isasi, keputusan eksperimen diringkaskan dalam jadual di bawah
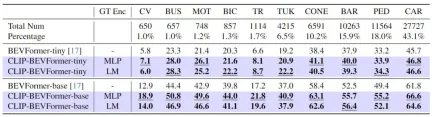
Prestasi model algoritma CLIP-BEVFormer yang dicadangkan pada masalah ekor panjang
Ia boleh dilihat daripada keputusan eksperimen dalam jadual di atas bahawa Set data nuScenes menunjukkan sejumlah besar kategori Masalah ketidakseimbangan kuantiti ialah beberapa kategori seperti (kenderaan pembinaan, bas, motosikal, basikal, dll.) mempunyai bahagian yang sangat rendah, tetapi bahagian kereta adalah sangat tinggi. Kami menilai prestasi persepsi model algoritma CLIP-BEVFormer yang dicadangkan pada kategori ciri dengan menjalankan eksperimen yang berkaitan dengan pengedaran ekor panjang, dengan itu mengesahkan keupayaan pemprosesannya untuk menyelesaikan kategori yang kurang biasa. Ia boleh dilihat daripada data percubaan di atas bahawa model algoritma CLIP-BEVFormer yang dicadangkan telah mencapai peningkatan prestasi dalam semua kategori, dan dalam kategori yang menyumbang bahagian yang sangat kecil, model algoritma CLIP-BEVFormer telah menunjukkan peningkatan prestasi substantif yang jelas.
Memandangkan sistem pemanduan autonomi dalam persekitaran sebenar perlu menghadapi masalah seperti kegagalan perkakasan, keadaan cuaca yang teruk atau kegagalan sensor yang mudah disebabkan oleh halangan buatan manusia, kami selanjutnya mengesahkan secara eksperimen kekukuhan model algoritma yang dicadangkan. Khususnya, untuk mensimulasikan masalah kegagalan penderia, kami menyekat kamera kamera secara rawak semasa proses inferens pelaksanaan model, untuk mensimulasikan pemandangan di mana kamera mungkin gagal. Keputusan percubaan yang berkaitan ditunjukkan dalam jadual di bawah
 Hasil percubaan kekukuhan model algoritma CLIP-BEVFormer yang dicadangkan
Hasil percubaan kekukuhan model algoritma CLIP-BEVFormer yang dicadangkan
Dapat dilihat daripada keputusan eksperimen bahawa model algoritma CLIP-BEVFormer yang kami cadangkan sentiasa lebih baik daripada BEVFormer tanpa mengira konfigurasi parameter model kecil atau asas model dengan konfigurasi yang sama mengesahkan prestasi unggul dan keteguhan cemerlang model algoritma kami dalam mensimulasikan keadaan kegagalan sensor.
Bahagian analisis kualitatif
Rajah berikut menunjukkan perbandingan visual hasil persepsi model algoritma CLIP-BEVFormer yang dicadangkan dan model algoritma BEVFormer. Dapat dilihat daripada hasil visual bahawa hasil persepsi model algoritma CLIP-BEVFormer yang kami cadangkan adalah lebih dekat dengan sasaran nilai sebenar, menunjukkan keberkesanan modul penjanaan ciri BEV nilai sebenar dan modul interaksi pertanyaan sasaran nilai sebenar yang kami cadangkan. .

Perbandingan visual hasil persepsi model algoritma CLIP-BEVFormer yang dicadangkan dan model algoritma BEVFormer
Kesimpulan
Dalam artikel ini, algoritma BEVFormer asal memfokuskan kepada kekurangan penyeliaan penjanaan paparan dalam proses penjanaan Peta ciri BEV Serta ketidakpastian pertanyaan interaktif antara Pertanyaan Objek dan ciri BEV dalam modul Penyahkod, kami mencadangkan model algoritma CLIP-BEVFormer dan menjalankan eksperimen dari aspek prestasi persepsi 3D model algoritma, sasaran pengedaran ekor panjang , dan keteguhan kepada kegagalan sensor , Sebilangan besar keputusan percubaan menunjukkan keberkesanan model algoritma CLIP-BEVFormer kami.
Atas ialah kandungan terperinci CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Carta 10 kuasa bi yang paling banyak digunakan - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Carta 10 kuasa bi yang paling banyak digunakan - Analytics VidhyaApr 16, 2025 pm 12:05 PMMemanfaatkan kekuatan visualisasi data dengan carta Microsoft Power BI Dalam dunia yang didorong oleh data hari ini, dengan berkesan menyampaikan maklumat yang rumit kepada penonton bukan teknikal adalah penting. Visualisasi data jambatan jurang ini, mengubah data mentah i
 Sistem Pakar di AIApr 16, 2025 pm 12:00 PM
Sistem Pakar di AIApr 16, 2025 pm 12:00 PMSistem Pakar: menyelam yang mendalam ke dalam kuasa membuat keputusan AI Bayangkan mempunyai akses kepada nasihat pakar mengenai apa -apa, dari diagnosis perubatan kepada perancangan kewangan. Itulah kuasa sistem pakar dalam kecerdasan buatan. Sistem ini meniru pro
 Tiga coder getaran terbaik memecahkan revolusi AI ini dalam kodApr 16, 2025 am 11:58 AM
Tiga coder getaran terbaik memecahkan revolusi AI ini dalam kodApr 16, 2025 am 11:58 AMPertama sekali, jelas bahawa ini berlaku dengan cepat. Pelbagai syarikat bercakap mengenai perkadaran kod mereka yang kini ditulis oleh AI, dan ini semakin meningkat pada klip pesat. Terdapat banyak anjakan pekerjaan
 Runway AI's Gen-4: Bagaimanakah montaj AI boleh melampaui kebodohanApr 16, 2025 am 11:45 AM
Runway AI's Gen-4: Bagaimanakah montaj AI boleh melampaui kebodohanApr 16, 2025 am 11:45 AMIndustri filem, bersama semua sektor kreatif, dari pemasaran digital ke media sosial, berdiri di persimpangan teknologi. Sebagai kecerdasan buatan mula membentuk semula setiap aspek bercerita visual dan mengubah landskap hiburan
 Bagaimana untuk mendaftar selama 5 hari kursus percuma ISRO AI? - Analytics VidhyaApr 16, 2025 am 11:43 AM
Bagaimana untuk mendaftar selama 5 hari kursus percuma ISRO AI? - Analytics VidhyaApr 16, 2025 am 11:43 AMKursus Online AI/ML percuma ISRO: Gerbang ke Inovasi Teknologi Geospatial Pertubuhan Penyelidikan Angkasa India (ISRO), melalui Institut Pengesan Jauh India (IIRS), menawarkan peluang yang hebat untuk pelajar dan profesional
 Algoritma Carian Tempatan di AIApr 16, 2025 am 11:40 AM
Algoritma Carian Tempatan di AIApr 16, 2025 am 11:40 AMAlgoritma Carian Tempatan: Panduan Komprehensif Merancang acara berskala besar memerlukan pengagihan beban kerja yang cekap. Apabila pendekatan tradisional gagal, algoritma carian tempatan menawarkan penyelesaian yang kuat. Artikel ini meneroka pendakian bukit dan simul
 Terbuka beralih fokus dengan GPT-4.1, mengutamakan pengekodan dan kecekapan kosApr 16, 2025 am 11:37 AM
Terbuka beralih fokus dengan GPT-4.1, mengutamakan pengekodan dan kecekapan kosApr 16, 2025 am 11:37 AMPelepasan ini termasuk tiga model yang berbeza, GPT-4.1, GPT-4.1 Mini dan GPT-4.1 Nano, menandakan langkah ke arah pengoptimuman khusus tugas dalam landskap model bahasa yang besar. Model-model ini tidak segera menggantikan antara muka yang dihadapi pengguna seperti
 Prompt: CHATGPT menjana pasport palsuApr 16, 2025 am 11:35 AM
Prompt: CHATGPT menjana pasport palsuApr 16, 2025 am 11:35 AMGergasi Chip Nvidia berkata pada hari Isnin ia akan memulakan pembuatan superkomputer AI - mesin yang boleh memproses sejumlah besar data dan menjalankan algoritma kompleks - sepenuhnya dalam A.S. untuk kali pertama. Pengumuman itu datang selepas Presiden Trump Si


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Dreamweaver CS6
Alat pembangunan web visual

Dreamweaver Mac版
Alat pembangunan web visual

