
Rumah >Peranti teknologi >AI >Merumuskan 374 karya berkaitan, pasukan Tao Dacheng, bersama-sama dengan Universiti Hong Kong dan UMD, mengeluarkan ulasan terbaru tentang penyulingan pengetahuan LLM
Merumuskan 374 karya berkaitan, pasukan Tao Dacheng, bersama-sama dengan Universiti Hong Kong dan UMD, mengeluarkan ulasan terbaru tentang penyulingan pengetahuan LLM

- 王林ke hadapan
- 2024-03-18 19:49:211404semak imbas
Model Bahasa Besar (LLM) telah berkembang pesat dalam tempoh dua tahun yang lalu, dan beberapa model serta produk yang fenomenal telah muncul, seperti GPT-4, Gemini, Claude, dll., tetapi kebanyakannya adalah sumber tertutup. Terdapat jurang yang besar antara kebanyakan LLM sumber terbuka yang kini boleh diakses oleh komuniti penyelidikan dan LLM sumber tertutup Oleh itu, meningkatkan keupayaan LLM sumber terbuka dan model kecil lain untuk mengurangkan jurang antara mereka dan model besar sumber tertutup telah menjadi tempat tumpuan penyelidikan. dalam padang ini.
Keupayaan berkuasa LLM, terutamanya LLM sumber tertutup, membolehkan penyelidik saintifik dan pengamal industri menggunakan output dan pengetahuan model besar ini apabila melatih model mereka sendiri. Proses ini pada asasnya ialah proses penyulingan pengetahuan (KD), iaitu, penyulingan pengetahuan daripada model guru (seperti GPT-4) kepada model yang lebih kecil (seperti Llama), yang meningkatkan keupayaan model kecil dengan ketara. Ia boleh dilihat bahawa teknologi penyulingan pengetahuan model bahasa besar ada di mana-mana dan merupakan kaedah yang kos efektif dan berkesan untuk penyelidik membantu melatih dan menambah baik model mereka sendiri.
Jadi, bagaimanakah kerja semasa menggunakan LLM sumber tertutup untuk penyulingan pengetahuan dan pemerolehan data? Bagaimana untuk melatih pengetahuan ini dengan cekap kepada model kecil? Apakah kemahiran berkuasa yang boleh diperoleh oleh model kecil daripada model guru? Bagaimanakah penyulingan pengetahuan LLM memainkan peranan dalam industri dengan ciri domain? Isu-isu ini patut difikirkan dan dikaji secara mendalam.
Pada tahun 2020, pasukan Tao Dacheng menerbitkan "Penyulingan Pengetahuan: Satu Tinjauan", yang meneroka secara menyeluruh aplikasi penyulingan pengetahuan dalam pembelajaran mendalam. Teknologi ini digunakan terutamanya untuk pemampatan dan pecutan model. Dengan peningkatan model bahasa berskala besar, bidang aplikasi penyulingan pengetahuan telah diperluaskan secara berterusan, yang bukan sahaja dapat meningkatkan prestasi model kecil, tetapi juga mencapai peningkatan diri model.
Pada awal tahun 2024, pasukan Tao Dacheng bekerjasama dengan University of Hong Kong dan University of Maryland untuk menerbitkan ulasan terbaru "A Survey on Knowledge Distillation of Large Language Models", yang meringkaskan 374 karya berkaitan dan membincangkan cara mendapatkan pengetahuan daripada model bahasa yang besar. Melatih model yang lebih kecil, dan peranan penyulingan pengetahuan dalam pemampatan model dan latihan kendiri. Pada masa yang sama, ulasan ini juga meliputi penyulingan kemahiran model bahasa yang besar dan penyulingan medan menegak, membantu penyelidik memahami sepenuhnya cara melatih dan menambah baik model mereka sendiri.

Tajuk kertas: Satu Tinjauan Mengenai Penyulingan Pengetahuan Model Bahasa Besar
Pautan kertas: https://arxiv.org/abs/2402.13116
- pautan https://projek
com. proses penyulingan pengetahuan model bahasa yang besar, ulasan ini menguraikan penyulingan pengetahuan kepada dua langkah: 1.
Elisitasi Pengetahuan: Iaitu, cara mendapatkan pengetahuan daripada model guru. Proses ini terutamanya merangkumi: a) Mula-mula bina arahan untuk mengenal pasti kemahiran atau kecekapan menegak yang perlu disuling daripada model guru.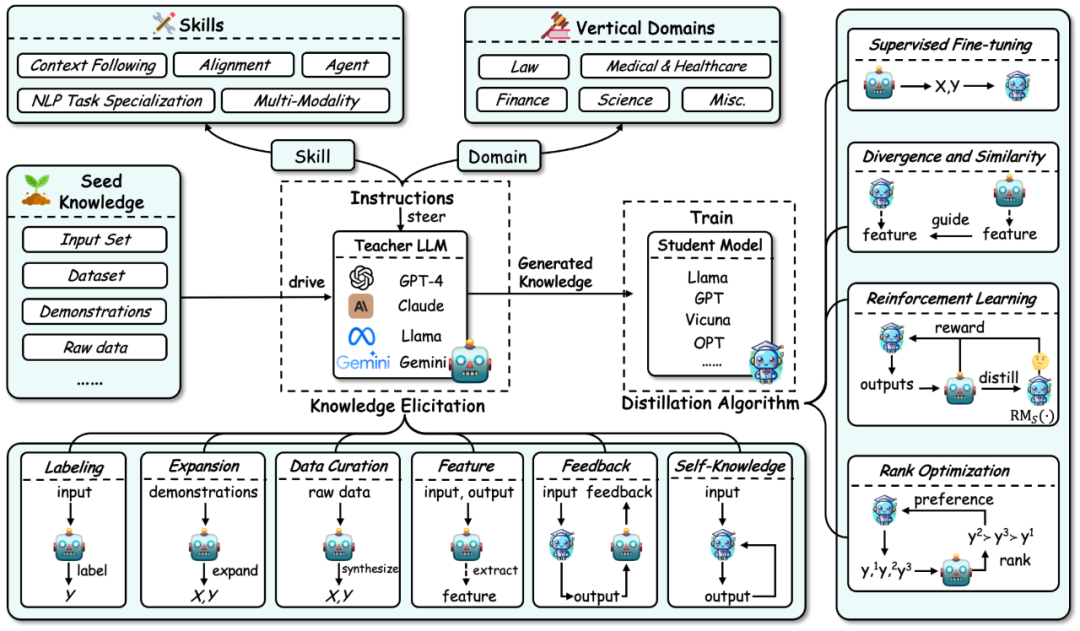 b) Kemudian gunakan pengetahuan benih (seperti set data tertentu) sebagai input untuk memacu model guru dan menjana respons yang sepadan, dengan itu membimbing pengetahuan yang sepadan.
b) Kemudian gunakan pengetahuan benih (seperti set data tertentu) sebagai input untuk memacu model guru dan menjana respons yang sepadan, dengan itu membimbing pengetahuan yang sepadan.
c) Pada masa yang sama, pemerolehan pengetahuan merangkumi beberapa teknologi khusus: anotasi, pengembangan, sintesis, pengekstrakan ciri, maklum balas dan pengetahuan sendiri.
2. Algoritma Penyulingan: Iaitu, cara menyuntik pengetahuan yang diperoleh ke dalam model pelajar. Algoritma khusus dalam bahagian ini termasuk: penalaan halus yang diselia, perbezaan dan persamaan, pembelajaran pengukuhan (iaitu pembelajaran pengukuhan daripada maklum balas AI, RLAIF) dan pengoptimuman kedudukan.
Kaedah klasifikasi ulasan ini meringkaskan kerja berkaitan daripada tiga dimensi berdasarkan proses ini: algoritma penyulingan pengetahuan, penyulingan kemahiran dan penyulingan medan menegak. Dua yang terakhir disuling berdasarkan algoritma penyulingan pengetahuan. Butiran klasifikasi ini dan ringkasan kerja berkaitan yang sepadan ditunjukkan dalam rajah di bawah. Algoritma penyulingan pengetahuan (Ciri), maklum balas (Feedback), pengetahuan yang dihasilkan sendiri (Self-Knowledge). Contoh setiap kaedah ditunjukkan di bawah:
Pelabelan: Pelabelan pengetahuan bermakna LLM guru menggunakan input yang diberikan sebagai pengetahuan benih untuk menjana output yang sepadan berdasarkan arahan atau contoh. Sebagai contoh, pengetahuan benih ialah input set data tertentu, dan model guru melabelkan output rantaian pemikiran.
Pengembangan: Ciri utama teknologi ini ialah menggunakan keupayaan pembelajaran kontekstual LLM untuk menjana data yang serupa dengan contoh berdasarkan contoh benih yang disediakan. Kelebihannya ialah set data yang lebih pelbagai dan meluas boleh dihasilkan melalui contoh. Walau bagaimanapun, apabila data yang dijana terus meningkat, masalah kehomogenan data mungkin timbul.
Penyusunan Data: Ciri tersendiri sintesis data ialah ia mensintesis data dari awal. Ia menggunakan sejumlah besar maklumat meta (seperti topik, dokumen pengetahuan, data asal, dll.) sebagai pengetahuan benih yang pelbagai dan besar untuk mendapatkan set data berskala besar dan berkualiti tinggi daripada LLM guru.
Pemerolehan ciri (Ciri): Kaedah biasa untuk mendapatkan pengetahuan ciri adalah dengan mengeluarkan jujukan input dan output kepada LLM guru, dan kemudian mengekstrak perwakilan dalamannya. Kaedah ini sesuai terutamanya untuk LLM sumber terbuka dan sering digunakan untuk pemampatan model.
Maklum Balas: Pengetahuan maklum balas biasanya memberikan maklum balas kepada model guru tentang output pelajar, seperti menyediakan maklumat keutamaan, penilaian atau pembetulan untuk membimbing pelajar menjana output yang lebih baik.
Ilmu Kendiri: Ilmu juga boleh diperolehi daripada pelajar sendiri, yang dinamakan ilmu yang dijana sendiri. Dalam kes ini, model yang sama bertindak sebagai kedua-dua guru dan pelajar, secara berulang-ulang memperbaiki dirinya dengan teknik penyulingan dan menambah baik output yang dihasilkan sebelumnya. Pendekatan ini berfungsi dengan baik untuk LLM sumber terbuka.
Ringkasan: Pada masa ini, kaedah sambungan masih digunakan secara meluas, dan kaedah sintesis data secara beransur-ansur menjadi arus perdana kerana ia boleh menjana sejumlah besar data berkualiti tinggi. Kaedah maklum balas boleh memberikan pengetahuan yang membantu model pelajar meningkatkan keupayaan penjajaran mereka. Pemerolehan ciri dan kaedah pengetahuan yang dijana sendiri telah menjadi popular kerana penggunaan model besar sumber terbuka sebagai model guru. Kaedah pemerolehan ciri membantu memampatkan model sumber terbuka, manakala kaedah pengetahuan yang dijana sendiri boleh terus menambah baik model bahasa yang besar. Yang penting, kaedah di atas boleh digabungkan dengan berkesan, dan penyelidik boleh meneroka kombinasi yang berbeza untuk mendapatkan pengetahuan yang lebih berkesan.
Algoritma Penyulingan
Selepas memperoleh pengetahuan, ia perlu disuling ke dalam model pelajar. Algoritma penyulingan termasuk: penalaan halus yang diselia, perbezaan dan persamaan, pembelajaran pengukuhan dan pengoptimuman kedudukan. Contoh ditunjukkan dalam rajah di bawah:
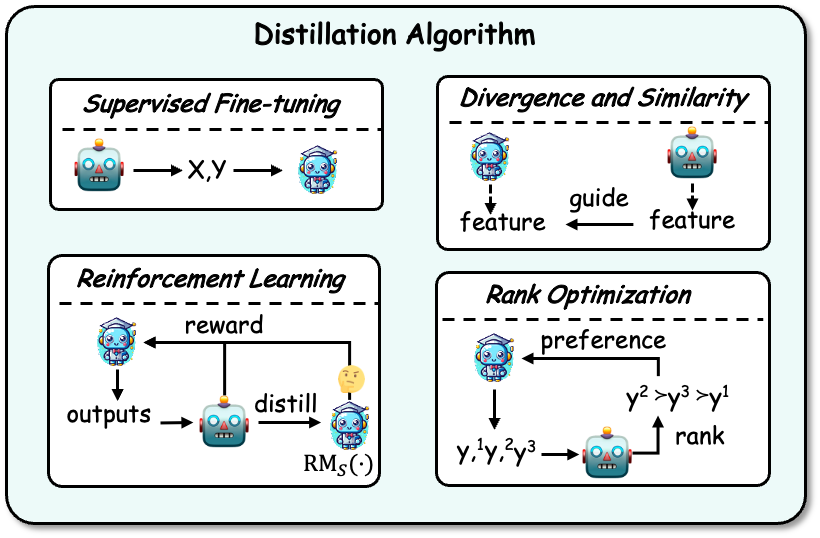
Penalaan halus diselia: Penalaan halus diselia (SFT) memperhalusi model pelajar dengan memaksimumkan kemungkinan urutan yang dihasilkan oleh model guru, membenarkan pelajar model untuk meniru model guru. Pada masa ini, ini merupakan teknik yang paling biasa digunakan dalam penyulingan pengetahuan LLM.
Divergence dan Similarity: Algoritma ini menggunakan pengetahuan parameter dalaman model guru sebagai isyarat penyeliaan untuk latihan model pelajar, dan sesuai untuk model guru sumber terbuka. Kaedah berdasarkan perbezaan dan persamaan masing-masing menjajarkan taburan kebarangkalian dan keadaan tersembunyi.
Pembelajaran Pengukuhan: Algoritma ini sesuai untuk menggunakan pengetahuan maklum balas guru untuk melatih model pelajar, iaitu teknologi RLAIF. Terdapat dua aspek utama: (1) menggunakan data maklum balas yang dijana oleh guru untuk melatih model ganjaran pelajar, (2) mengoptimumkan model pelajar dengan memaksimumkan ganjaran yang diharapkan melalui model ganjaran terlatih. Guru juga boleh berkhidmat secara langsung sebagai model ganjaran.
Pengoptimuman Kedudukan: Pengoptimuman kedudukan juga boleh menyuntik pengetahuan keutamaan ke dalam model pelajar Kelebihannya ialah kestabilan dan kecekapan pengiraan yang tinggi, seperti beberapa algoritma klasik seperti DPO, RRHF, dll.
Penyulingan Kemahiran
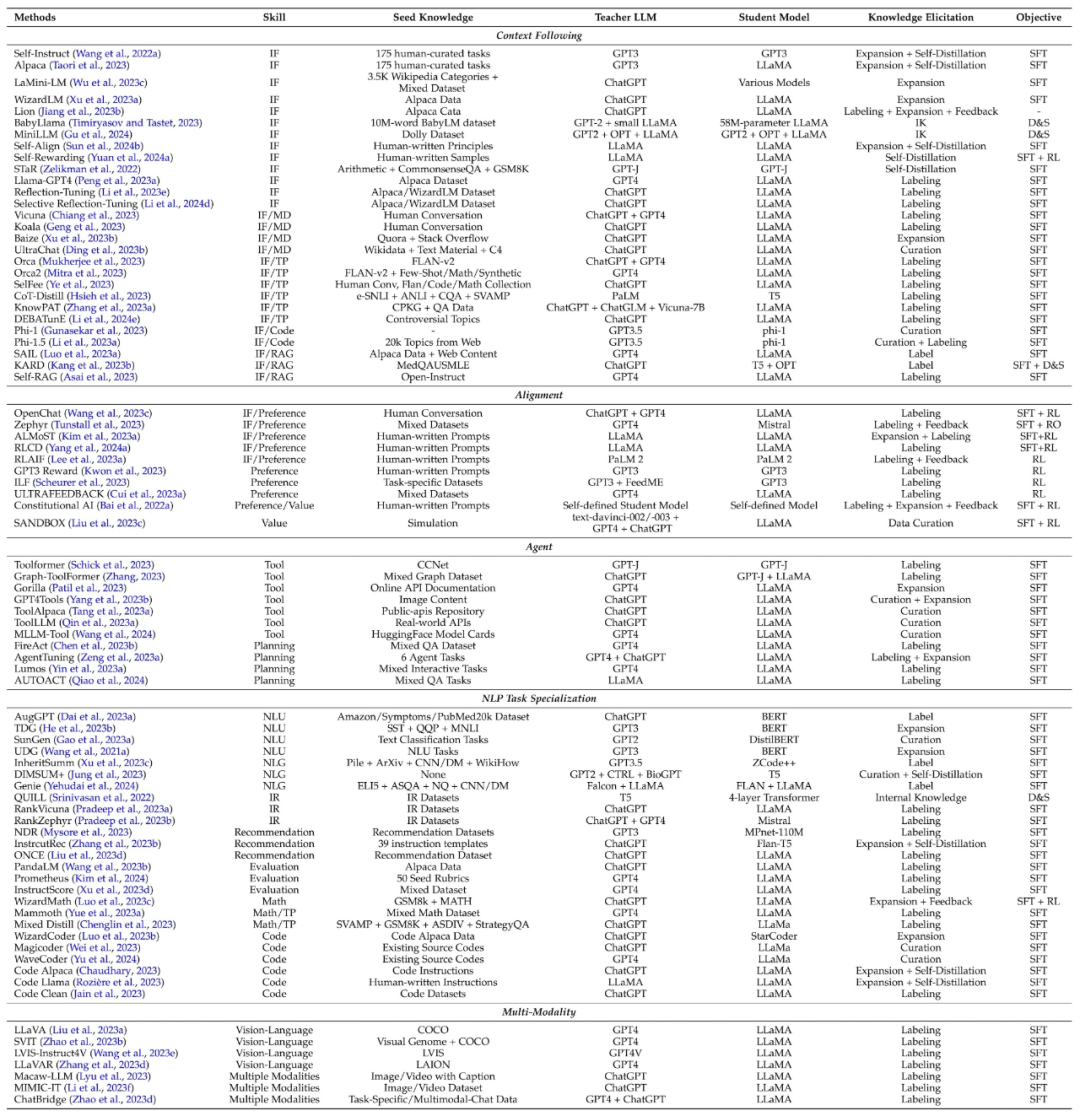
Adalah diketahui umum bahawa model bahasa besar mempunyai banyak keupayaan yang sangat baik. Melalui teknologi penyulingan pengetahuan, arahan disediakan untuk mengawal guru untuk menjana pengetahuan yang mengandungi kemahiran yang sepadan dan melatih model pelajar supaya mereka boleh memperoleh kebolehan ini. Keupayaan ini terutamanya termasuk keupayaan seperti konteks berikut (seperti arahan), penjajaran, ejen, tugas pemprosesan bahasa semula jadi (NLP) dan pelbagai mod.
Jadual berikut meringkaskan kerja klasik penyulingan kemahiran, dan juga meringkaskan kemahiran, pengetahuan benih, model guru, model pelajar, kaedah pemerolehan pengetahuan dan algoritma penyulingan yang terlibat dalam setiap kerja.
Penyulingan medan menegak
Selain model bahasa besar dalam bidang umum, kini terdapat banyak usaha untuk melatih model bahasa besar dalam bidang menegak, yang membantu komuniti penyelidikan dan industri dalam aplikasi dan penggunaan model bahasa besar. Walaupun model bahasa yang besar (seperti GPT-4) mempunyai pengetahuan domain yang terhad dalam medan menegak, model tersebut masih boleh memberikan beberapa pengetahuan dan keupayaan domain atau meningkatkan set data domain sedia ada. Bidang yang terlibat di sini terutamanya termasuk (1) undang-undang, (2) kesihatan perubatan, (3) kewangan, (4) sains, dan beberapa bidang lain. Taksonomi dan kerja berkaitan bahagian ini ditunjukkan dalam rajah di bawah:

Arah Masa Depan
Semakan ini meneroka masalah semasa penyulingan pengetahuan model bahasa besar dan potensi arah penyelidikan masa depan, terutamanya termasuk:
Pemilihan Data: Bagaimana untuk memilih data secara automatik untuk mencapai hasil penyulingan yang lebih baik?
Penyulingan berbilang guru: Terokai penyulingan pengetahuan daripada model guru yang berbeza kepada satu model pelajar.
Pengetahuan yang lebih kaya dalam model guru: Anda boleh meneroka pengetahuan yang lebih kaya dalam model guru, termasuk maklum balas dan pengetahuan ciri, dan meneroka gabungan pelbagai kaedah pemerolehan pengetahuan.
Mengatasi pelupaan bencana semasa penyulingan : Keupayaan untuk mengekalkan model asal dengan berkesan semasa penyulingan atau pemindahan pengetahuan kekal sebagai isu yang mencabar.
Penyulingan Pengetahuan Dipercayai: Pada masa ini, KD memberi tumpuan terutamanya pada penyulingan pelbagai kemahiran, dan memberi sedikit perhatian kepada kredibiliti model besar.
Penyulingan Lemah-ke-Kuat(Penyulingan Lemah-ke-Kuat). OpenAI mencadangkan konsep "pengertian lemah kepada kuat", yang memerlukan penerokaan strategi teknikal yang inovatif supaya model yang lebih lemah boleh membimbing proses pembelajaran model yang lebih kukuh dengan berkesan.
Penjajaran Kendiri (Penyulingan Kendiri). Arahan boleh direka bentuk supaya model pelajar secara autonomi menambah baik dan menyelaraskan kandungan yang dihasilkan dengan menjana maklum balas, kritikan dan penjelasan.
Kesimpulan
Semakan ini menyediakan ringkasan yang komprehensif dan sistematik tentang cara menggunakan pengetahuan model bahasa besar untuk menambah baik model pelajar, seperti model bahasa besar sumber terbuka, dan juga termasuk teknologi penyulingan diri yang popular baru-baru ini . Kajian semula ini membahagikan penyulingan pengetahuan kepada dua langkah: pemerolehan pengetahuan dan algoritma penyulingan, dan juga meringkaskan penyulingan kemahiran dan penyulingan medan menegak. Akhir sekali, semakan ini meneroka hala tuju masa depan penyulingan model bahasa besar, dengan harapan dapat menolak sempadan penyulingan pengetahuan model bahasa besar dan mendapatkan model bahasa besar yang lebih mudah diakses, cekap, berkesan dan boleh dipercayai.
Atas ialah kandungan terperinci Merumuskan 374 karya berkaitan, pasukan Tao Dacheng, bersama-sama dengan Universiti Hong Kong dan UMD, mengeluarkan ulasan terbaru tentang penyulingan pengetahuan LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Penandaarasan Bing Chat: Fungsi 'perbualan' beta awam skala kecil Baidu Search, berdasarkan model bahasa Wenxin Yiyan
- Eksekutif Audi: Kekurangan semikonduktor telah menyebabkan industri automotif Jerman memasuki tempoh kesesakan yang akan berterusan selama beberapa tahun
- Artikel ini akan membawa anda memahami model bahasa besar universal yang dibangunkan secara bebas oleh Tencent - model besar Hunyuan.
- LLMLingua: Sepadukan LlamaIndex, mampatkan petunjuk dan menyediakan perkhidmatan inferens model bahasa besar yang cekap
- Industri robot: medan panas seterusnya dalam era AI, salah satu daripada sembilan industri utama pada masa hadapan!