
Rumah >Peranti teknologi >AI >Meningkatkan keupayaan pembelajaran sifar pukulan generatif, kaedah prototaip semantik dinamik yang dipertingkatkan secara visual telah dipilih untuk CVPR 2024
Meningkatkan keupayaan pembelajaran sifar pukulan generatif, kaedah prototaip semantik dinamik yang dipertingkatkan secara visual telah dipilih untuk CVPR 2024

- 王林ke hadapan
- 2024-03-16 09:20:021059semak imbas
Walaupun saya tidak pernah bertemu dengan anda, saya mungkin "mengenali" anda - ini adalah keadaan yang diharapkan orang ramai untuk mencapai kecerdasan buatan selepas "pandangan pertama".
Untuk mencapai matlamat ini, dalam tugas pengecaman imej tradisional, orang ramai melatih model algoritma pada sejumlah besar sampel imej dengan label kategori yang berbeza, supaya model boleh memperoleh keupayaan untuk mengenali imej ini. Dalam tugas pembelajaran sifar pukulan (ZSL), orang ramai berharap model itu boleh membuat inferens dan mengenal pasti kategori yang belum melihat sampel imej dalam peringkat latihan.
Pembelajaran sifar pukulan generatif (GZSL) dianggap kaedah yang berkesan untuk pembelajaran pukulan sifar. Dalam GZSL, langkah pertama ialah melatih penjana untuk mensintesis ciri visual bagi kategori yang tidak kelihatan. Proses penjanaan ini didorong dengan memanfaatkan penerangan semantik seperti label atribut sebagai syarat. Setelah ciri visual maya ini dijana, anda boleh mula melatih model klasifikasi yang boleh mengecam kelas yang tidak kelihatan seperti yang anda lakukan pada pengelas tradisional.
Latihan penjana adalah penting untuk algoritma pembelajaran sifar pukulan generatif. Sebaik-baiknya, sampel ciri visual kategori ghaib yang dijana oleh penjana berdasarkan penerangan semantik harus mempunyai taburan yang sama seperti ciri visual sampel sebenar kategori tersebut. Ini bermakna bahawa penjana perlu dapat menangkap dengan tepat hubungan dan corak antara ciri visual untuk menghasilkan sampel dengan tahap ketekalan dan kredibiliti yang tinggi. Dengan melatih penjana, ia boleh mempelajari secara berkesan perbezaan ciri visual antara kategori yang berbeza, dan
Dalam kaedah pembelajaran sifar pukulan generatif sedia ada, apabila penjana dilatih dan digunakan, ia adalah bunyi Gaussian dan penerangan semantik keseluruhan bagi kategori adalah bersyarat, yang mengehadkan penjana untuk hanya mengoptimumkan untuk keseluruhan kategori dan bukannya menerangkan setiap contoh sampel, jadi sukar untuk menggambarkan dengan tepat taburan ciri visual sampel sebenar, mengakibatkan prestasi generalisasi yang lemah bagi model Lemah. Di samping itu, maklumat visual set data yang dikongsi oleh kelas dilihat dan kelas ghaib, iaitu pengetahuan domain, tidak digunakan sepenuhnya dalam proses latihan penjana, yang mengehadkan pemindahan pengetahuan daripada kelas yang dilihat kepada kelas yang tidak kelihatan.
Untuk menyelesaikan masalah ini, pelajar siswazah dari Universiti Sains dan Teknologi Huazhong dan pakar teknikal dari Intime Business Group, anak syarikat Alibaba, mencadangkan kaedah yang dipanggil Visually Enhanced Dynamic Semantic Prototyping (VADS). Pendekatan ini memperkenalkan ciri visual kelas yang dilihat dengan lebih lengkap ke dalam keadaan semantik, membolehkan penjana tolak mempelajari pemetaan semantik-visual yang tepat. Kertas penyelidikan "Prototaip Semantik Dinamik Pertambahan Visual untuk Pembelajaran Sifar Tangkapan Generatif" ini telah diterima oleh CVPR 2024, persidangan akademik antarabangsa teratas dalam bidang penglihatan komputer.
Secara khusus, penyelidikan di atas membentangkan tiga perkara inovatif:
Dalam pembelajaran sifar pukulan, ciri visual digunakan untuk meningkatkan penjana bagi menjana ciri visual yang boleh dipercayai, yang merupakan kaedah inovatif .
Penyelidikan ini juga memperkenalkan dua komponen, VDKL dan VOSU Dengan bantuan komponen ini, visual sebelum set data diperoleh dengan berkesan, dan dengan mengemas kini ciri visual imej secara dinamik, penerangan semantik kategori yang telah ditetapkan adalah. dikemas kini. Kaedah ini menggunakan ciri visual dengan berkesan.
Hasil eksperimen menunjukkan bahawa kesan penggunaan ciri visual untuk meningkatkan penjana dalam kajian ini adalah sangat ketara. Bukan sahaja pendekatan plug-and-play ini sangat serba boleh, ia juga cemerlang dalam meningkatkan prestasi penjana.
Butiran penyelidikan
VADS terdiri daripada dua modul: (1) Modul pembelajaran pengetahuan domain persepsi visual (VDKL) mempelajari kecenderungan tempatan dan keutamaan global ciri visual, iaitu, pengetahuan visual domain, yang menggantikan hingar Gaussian tulen menyediakan maklumat hingar terdahulu yang lebih kaya; (2) Modul kemas kini semantik berorientasikan penglihatan (VOSU) mempelajari cara mengemas kini prototaip semantiknya mengikut perwakilan visual sampel, dan prototaip pasca-semantik yang dikemas kini juga mengandungi pengetahuan visual domain.
Akhir sekali, pasukan penyelidik menggabungkan output kedua-dua modul ke dalam vektor prototaip semantik dinamik sebagai keadaan penjana. Sebilangan besar percubaan menunjukkan bahawa kaedah VADS mencapai prestasi yang jauh lebih baik daripada kaedah sedia ada pada set data pembelajaran pukulan sifar yang biasa digunakan, dan boleh digabungkan dengan kaedah pembelajaran pukulan sifar generatif yang lain untuk mendapatkan peningkatan umum dalam ketepatan.
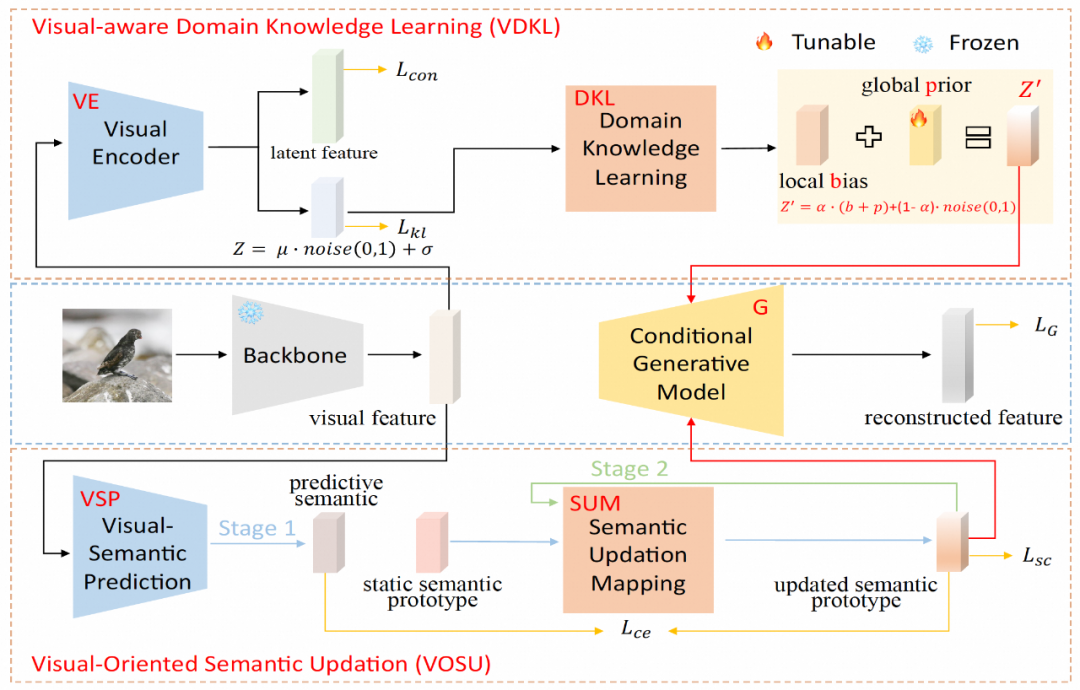
Dalam modul pembelajaran pengetahuan domain persepsi visual (VDKL), pasukan penyelidik mereka bentuk pengekod visual (VE) dan rangkaian pembelajaran pengetahuan domain (DKL). Antaranya, VE mengodkan ciri visual kepada ciri terpendam dan pengekodan terpendam. Dengan menggunakan kehilangan kontrastif untuk melatih VE menggunakan sampel imej kelas yang dilihat semasa peringkat latihan penjana, VE boleh meningkatkan kebolehpisahan kelas ciri visual.
Apabila melatih pengelas ZSL, ciri visual ghaib yang dijana oleh penjana juga dimasukkan ke dalam VE, dan ciri terpendam yang diperoleh disambungkan dengan ciri visual yang dijana sebagai sampel ciri visual akhir. Keluaran VE yang lain, iaitu pengekodan terpendam, membentuk sisihan tempatan b selepas transformasi DKL Bersama-sama dengan p sebelumnya global yang boleh dipelajari dan hingar Gaussian rawak, ia digabungkan menjadi hingar terdahulu visual berkaitan domain untuk menggantikan sampel sifar generatif yang lain. . Bunyi Gaussian Tulen yang biasa digunakan dalam pembelajaran sebagai sebahagian daripada keadaan penjanaan penjana.
Dalam Modul Kemas Kini Semantik Berorientasikan Visi (VOSU), pasukan penyelidik mereka bentuk VSP peramal semantik visual dan rangkaian pemetaan kemas kini semantik SUM. Dalam fasa latihan VOSU, VSP mengambil ciri visual imej sebagai input untuk menjana vektor semantik yang diramalkan yang boleh menangkap corak visual imej sasaran Pada masa yang sama, SUM mengambil prototaip semantik kategori sebagai input, mengemas kininya dan memperolehnya prototaip semantik yang dikemas kini, dan kemudian VSP dan SUM dilatih dengan meminimumkan kehilangan entropi silang antara vektor semantik yang diramalkan dan prototaip semantik yang dikemas kini. Modul VOSU boleh melaraskan prototaip semantik secara dinamik berdasarkan ciri visual, membolehkan penjana bergantung pada maklumat semantik peringkat contoh yang lebih tepat apabila mensintesis ciri kategori baharu.
Dalam bahagian eksperimen, penyelidikan di atas menggunakan tiga set data ZSL yang biasa digunakan dalam akademik: Haiwan dengan Atribut 2 (AWA2), Atribut SUN (SUN) dan Caltech-USCD Birds-200-2011 (CUB), untuk tradisional Penunjuk utama pembelajaran sifar pukulan dan pembelajaran sifar pukulan umum adalah secara komprehensif dibandingkan dengan kaedah perwakilan terkini yang lain.
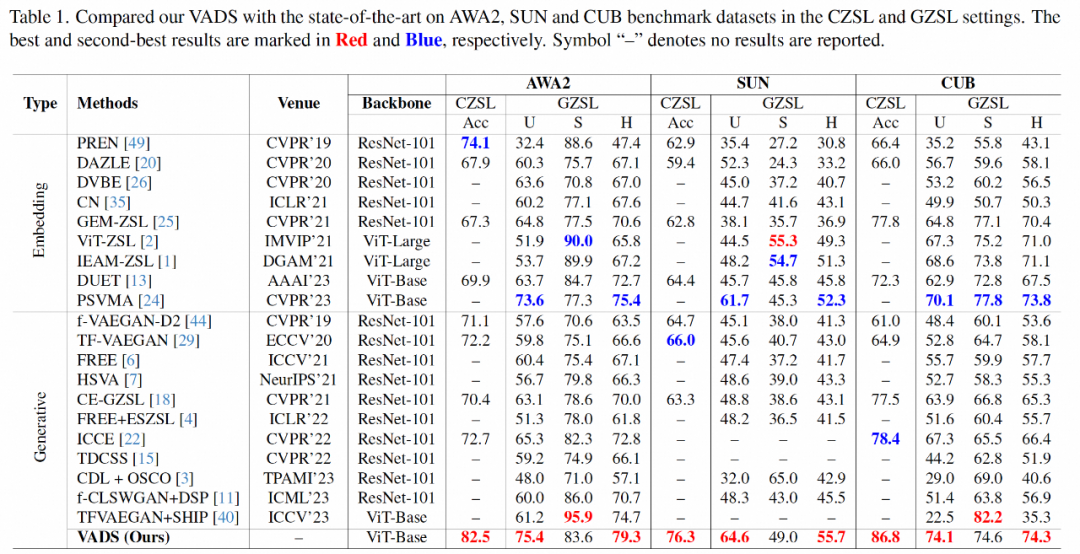
Dari segi penunjuk Acc pembelajaran sifar pukulan tradisional, kaedah kajian ini telah mencapai peningkatan ketepatan yang ketara berbanding dengan kaedah sedia ada, masing-masing mendahului 8.4%, 10.3% dan 8.4 pada tiga set data. %. Dalam senario pembelajaran sifar pukulan umum, kaedah penyelidikan di atas juga berada di kedudukan utama dalam indeks min harmonik H kelas ghaib dan ketepatan kelas dilihat.
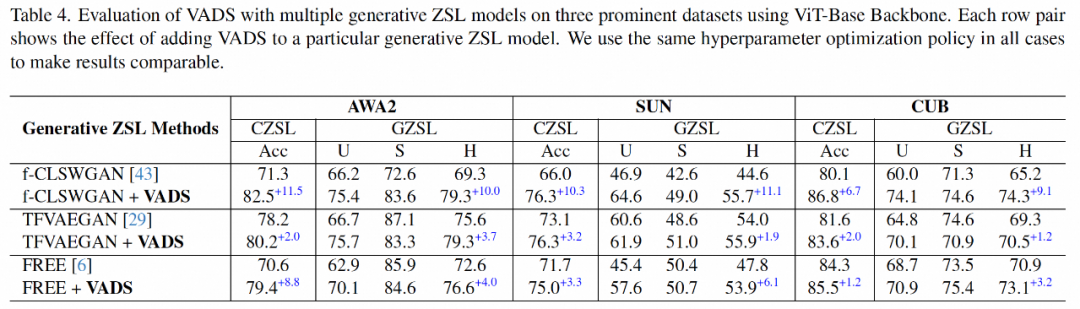
Kaedah VADS juga boleh digabungkan dengan kaedah pembelajaran sifar pukulan generatif yang lain. Sebagai contoh, selepas digabungkan dengan tiga kaedah CLSWGAN, TF-VAEGAN dan PERCUMA, penunjuk Acc dan H pada tiga set data bertambah baik dengan ketara, dan purata peningkatan bagi tiga set data ialah 7.4%/5.9%, 5.6% /6.4% dan 3.3%/4.2%.
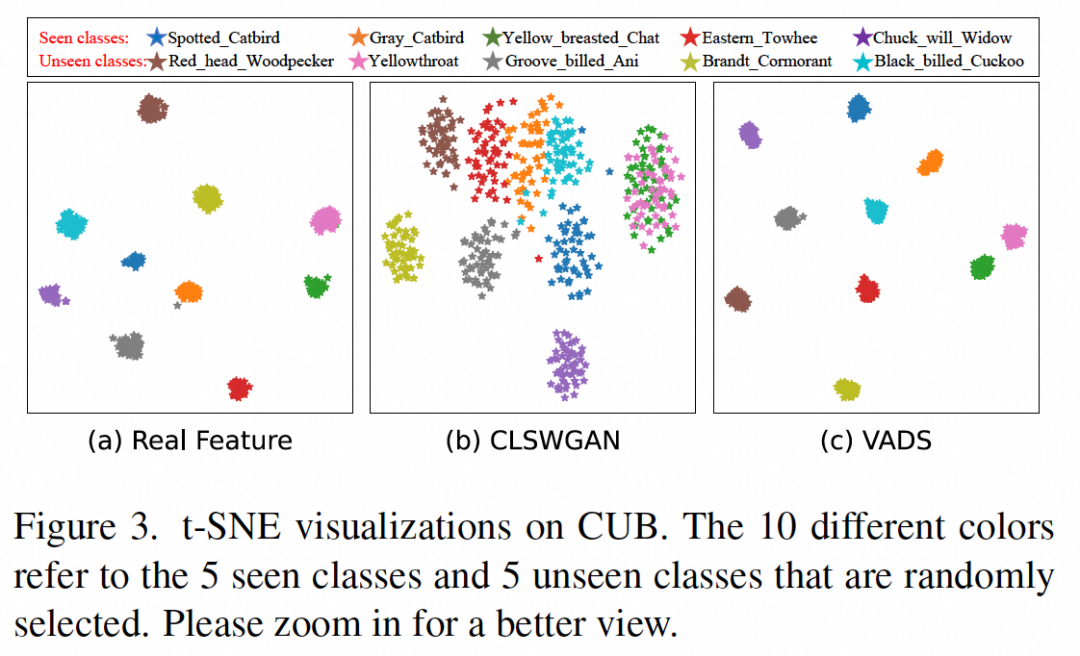
Dengan memvisualisasikan ciri visual yang dihasilkan oleh penjana, dapat dilihat bahawa ciri beberapa kategori pada asalnya dikelirukan bersama, seperti kelas yang dilihat "Sembang dada kuning" dan kelas ghaib yang ditunjukkan dalam (b ) di bawah. Kedua-dua jenis ciri "Yellowthroat" boleh dipisahkan dengan jelas kepada dua kelompok dalam Rajah (c) selepas menggunakan kaedah VADS, dengan itu mengelakkan kekeliruan semasa latihan pengelas.
Boleh diperluaskan kepada bidang keselamatan pintar dan model besar
Machine Heart memahami bahawa pembelajaran sifar pukulan yang difokuskan oleh pasukan penyelidik yang dinyatakan di atas bertujuan untuk membolehkan model mengenali yang tidak mempunyai sampel imej dalam peringkat latihan , yang mempunyai potensi nilai dalam bidang keselamatan pintar.
Pertama, hadapi risiko yang muncul dalam senario keselamatan Memandangkan jenis ancaman baharu atau corak tingkah laku luar biasa akan terus muncul dalam senario keselamatan, ia mungkin tidak muncul dalam data latihan sebelumnya. Pembelajaran sifar pukulan membolehkan sistem keselamatan mengenal pasti dan bertindak balas dengan cepat kepada jenis risiko baharu, dengan itu meningkatkan keselamatan.
Kedua, kurangkan pergantungan pada data sampel: Mendapatkan data beranotasi yang mencukupi untuk melatih sistem keselamatan yang berkesan adalah mahal dan memakan masa pembelajaran Zero-shot mengurangkan pergantungan sistem pada sejumlah besar sampel imej, dengan itu menjimatkan kos R&D. .
Ketiga, tingkatkan kestabilan dalam persekitaran dinamik: pembelajaran sifar menggunakan penerangan semantik untuk mengenali corak kelas yang tidak kelihatan Berbanding dengan kaedah tradisional yang bergantung sepenuhnya pada ciri imej, ia secara semula jadi lebih tahan terhadap perubahan dalam persekitaran visual.
Sebagai teknologi asas untuk menyelesaikan masalah pengelasan imej, teknologi ini juga boleh dilaksanakan dalam senario yang bergantung pada teknologi pengelasan visual, seperti pengecaman atribut orang, barangan, kenderaan dan objek, pengecaman tingkah laku, dsb. Terutamanya dalam senario di mana kategori baharu yang ingin dikenal pasti perlu ditambah dengan cepat dan tiada masa untuk mengumpul sampel latihan, atau sukar untuk mengumpul sejumlah besar sampel (seperti pengenalpastian risiko), teknologi pembelajaran sifar pukulan mempunyai kelebihan yang besar berbanding kaedah tradisional.
Adakah teknologi penyelidikan ini mempunyai sebarang rujukan untuk pembangunan model besar semasa?
Penyelidik percaya bahawa idea teras pembelajaran sifar pukulan generatif adalah untuk menyelaraskan ruang semantik dan ruang ciri visual, yang konsisten dengan matlamat penyelidikan model bahasa visual (seperti CLIP) dalam pelbagai masa kini. model besar modal.
Perbezaan terbesar antara mereka ialah pembelajaran sifar pukulan generatif dilatih dan digunakan pada kategori set data terhad yang telah ditetapkan, manakala model besar bahasa visual adalah serba boleh melalui pembelajaran data besar dan keupayaan perwakilan visual tidak terhad kepada kategori terhad Sebagai model asas, mereka mempunyai rangkaian aplikasi yang lebih luas.
Jika senario aplikasi teknologi adalah bidang tertentu, anda boleh memilih untuk menyesuaikan dan memperhalusi model besar kepada bidang ini, dalam proses ini, bekerja dalam arah penyelidikan yang sama atau serupa seperti yang boleh dibawa oleh artikel ini secara teori sedikit inspirasi yang berguna.
Pengenalan kepada pengarang
Hou Wenjin, pelajar sarjana di Universiti Sains dan Teknologi Huazhong Minat penyelidikannya termasuk penglihatan komputer, pemodelan generatif, pembelajaran beberapa pukulan, dan lain-lain. Beliau menyelesaikan tesis ini semasa latihan amalinya. di Alibaba-Intime Business .
Wang Yan, Pengarah Teknologi Komersial Alibaba-Intime, Ketua Algoritma Pasukan Pintar Shenzhen Xiang.
Feng Xuetao, pakar algoritma kanan di Alibaba-Intime Business, tertumpu terutamanya pada aplikasi algoritma visual dan berbilang modal dalam runcit luar talian dan industri lain.
Atas ialah kandungan terperinci Meningkatkan keupayaan pembelajaran sifar pukulan generatif, kaedah prototaip semantik dinamik yang dipertingkatkan secara visual telah dipilih untuk CVPR 2024. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Ai、Ae、Ps分别是什么软件?
- ai属性栏怎么调出来
- ai技术是什么技术
- Pengumuman rasmi Pusat Pengkomputeran Super Haimo: model besar dengan 100 bilion parameter, skala data 1 juta klip dan pengurangan 200 kali ganda dalam kos latihan
- Musk mengisytiharkan dia akan menyaman Microsoft kerana menggunakan data Twitter untuk melatih sistem kecerdasan buatan