
Rumah >Peranti teknologi >AI >Mari kita bincangkan tentang kaedah gabungan model model besar
Mari kita bincangkan tentang kaedah gabungan model model besar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-11 13:10:15679semak imbas
Dalam amalan sebelum ini, gabungan model telah digunakan secara meluas, terutamanya dalam model diskriminasi, di mana ia dianggap sebagai kaedah yang boleh meningkatkan prestasi secara berterusan. Walau bagaimanapun, untuk model bahasa generatif, cara ia beroperasi tidak semudah model diskriminatif kerana proses penyahkodan yang terlibat.
Selain itu, disebabkan peningkatan dalam bilangan parameter model besar, dalam senario dengan skala parameter yang lebih besar, kaedah yang boleh dipertimbangkan dengan pembelajaran ensembel mudah adalah lebih terhad daripada pembelajaran mesin berparameter rendah, seperti tindanan klasik, boosting dan kaedah lain, kerana Masalah parameter model bertindan tidak boleh dikembangkan dengan mudah. Oleh itu, pembelajaran ensemble untuk model besar memerlukan pertimbangan yang teliti.
Di bawah ini kami menerangkan lima kaedah integrasi asas, iaitu integrasi model, integrasi probabilistik, pembelajaran cantuman, pengundian sumber ramai, dan KPM.
1. Integrasi model
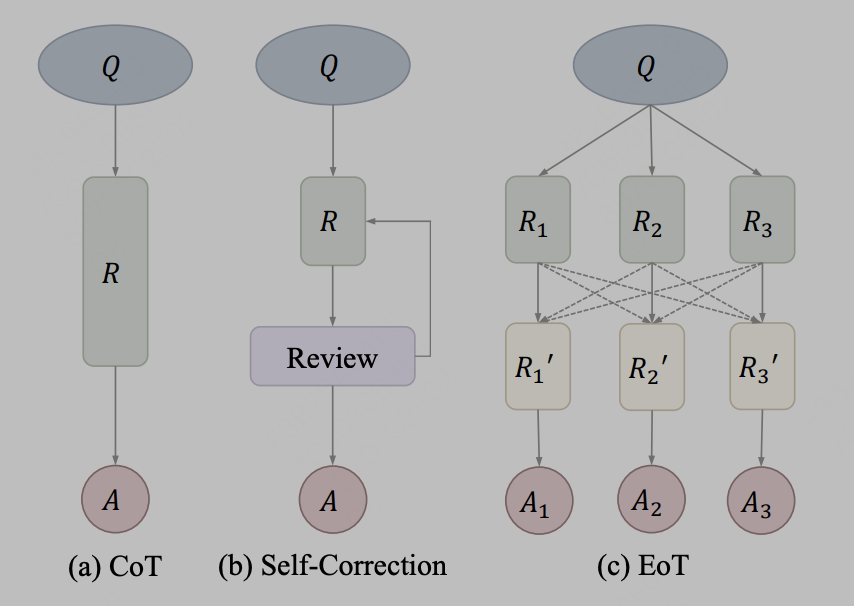
Integrasi model agak mudah, iaitu, model besar disepadukan pada tahap teks keluaran Contohnya, hanya gunakan hasil keluaran tiga model LLama yang berbeza dan masukkannya sebagai gesaan ke dalam model keempat untuk rujukan. Dalam amalan, penghantaran maklumat melalui teks boleh digunakan sebagai kaedah komunikasi Kaedah perwakilan adalah EoT, yang berasal dari artikel "Pertukaran-Pemikiran: Meningkatkan Keupayaan Model Bahasa Besar melalui Komunikasi Cross-Model". Rangka kerja pertukaran pemikiran, dikenali sebagai Exchange-of-Thought, direka bentuk untuk memudahkan komunikasi silang antara model untuk meningkatkan pemahaman kolektif dalam proses penyelesaian masalah. Melalui rangka kerja ini, model boleh menyerap alasan model lain untuk menyelaras dan menambah baik penyelesaian mereka sendiri dengan lebih baik. Diwakili oleh gambar rajah dalam kertas kerja:
 Gambar
Gambar
Selepas pengarang menganggap kaedah CoT dan pembetulan diri sebagai konsep yang sama, EoT menyediakan kaedah baharu yang membolehkan mesej hierarki dihantar antara berbilang model . Dengan berkomunikasi merentas model, model boleh menggunakan penaakulan dan proses pemikiran masing-masing, membantu menyelesaikan masalah dengan lebih berkesan. Pendekatan ini dijangka dapat meningkatkan prestasi dan ketepatan model.
2. Ensemble probabilistik
Ensemble probabilistik mempunyai persamaan dengan kaedah pembelajaran mesin tradisional. Sebagai contoh, kaedah ensemble boleh dibentuk dengan purata keputusan logit yang diramalkan oleh model. Dalam model besar, ensembel kebarangkalian boleh digabungkan pada tahap kebarangkalian keluaran perbendaharaan kata model pengubah. Adalah penting untuk ambil perhatian bahawa operasi ini memerlukan senarai perbendaharaan kata bagi pelbagai model asal yang digabungkan mestilah konsisten. Kaedah penyepaduan sedemikian boleh meningkatkan prestasi dan keteguhan model, menjadikannya lebih sesuai untuk senario aplikasi praktikal.
Di bawah ini kami memberikan pelaksanaan pseudokod yang mudah.
kv_cache = NoneWhile True:input_ids = torch.tensor([[new_token]], dtype=torch.long, device='cuda')kv_cache1, kv_cache2 = kv_cache output1 = models[0](input_ids=input_ids, past_key_values=kv_cache1, use_cache=True)output2 = models[1](input_ids=input_ids, past_key_values=kv_cache2, use_cache=True)kv_cache = [output1.past_key_values, output2.past_key_values]prob = (output1.logits + output2.logits) / 2new_token = torch.argmax(prob, 0).item()
3. Pembelajaran cantuman
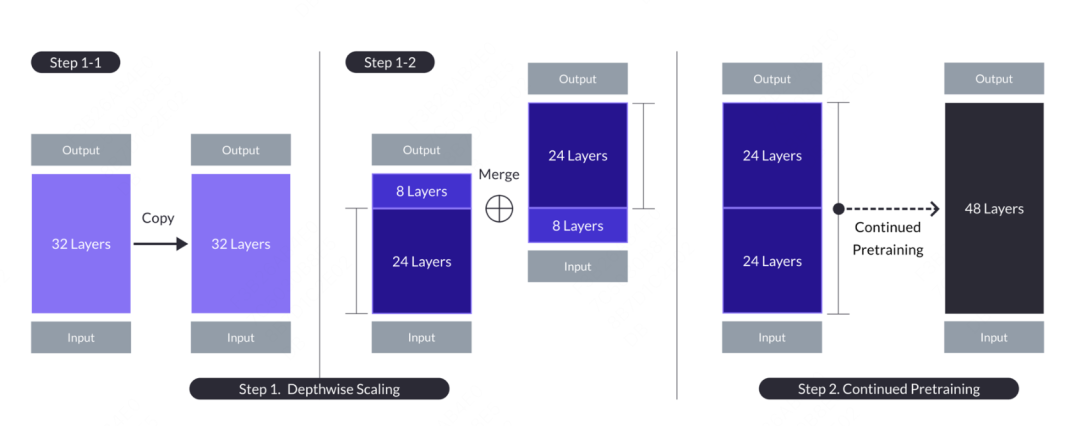
Konsep pembelajaran cantuman berasal dari plantsgo Kaggle Grandmaster domestik, yang berasal dari pertandingan perlombongan data. Ia pada asasnya adalah sejenis pembelajaran pemindahan, yang pada asalnya digunakan untuk menerangkan kaedah menggunakan output satu model pokok sebagai input model pokok lain. Kaedah ini serupa dengan cantuman dalam pembiakan pokok, maka namanya. Dalam model besar, terdapat juga aplikasi pembelajaran cantuman Nama model adalah SOLAR Artikel itu berasal dari "SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling cantuman model Berbeza dengan pembelajaran cantuman dalam pembelajaran mesin, model besar tidak secara langsung menggabungkan hasil kebarangkalian model lain, tetapi mencantumkan sebahagian daripada struktur dan pemberat kepada model gabungan, dan menjalani proses pra-latihan tertentu untuk membuat. ia Parameter model boleh disesuaikan dengan model baharu. Operasi khusus adalah untuk menyalin model asas yang mengandungi n lapisan untuk pengubahsuaian seterusnya. Kemudian, lapisan m terakhir dikeluarkan daripada model asal dan lapisan m pertama dikeluarkan daripada salinannya, menghasilkan dua model lapisan n-m yang berbeza. Akhir sekali, kedua-dua model digabungkan untuk membentuk model berskala dengan lapisan 2*(n-m).
Apabila anda perlu membina model sasaran 48 lapisan, anda boleh mempertimbangkan untuk mengambil 24 lapisan pertama dan 24 lapisan terakhir daripada dua model 32 lapisan dan menyambungkannya untuk membentuk model 48 lapisan baharu. Kemudian, model gabungan dilatih lebih lanjut. Secara umum, meneruskan pra-latihan memerlukan volum data dan sumber pengkomputeran yang lebih sedikit daripada latihan dari awal.
 Gambar
Gambar
Selepas meneruskan pra-latihan, operasi penjajaran perlu dilakukan, yang merangkumi dua proses, iaitu penalaan halus arahan dan DPO. Penalaan halus arahan menggunakan data arahan sumber terbuka dan mengubahnya menjadi data arahan khusus matematik untuk meningkatkan keupayaan matematik model. DPO ialah pengganti RLHF tradisional, yang akhirnya menjadi versi sembang SOLAR.
4. Pengundian Crowdsourcing
Pengundian Crowdsourcing telah digunakan dalam rancangan tempat pertama WSDM CUP tahun ini, dan telah diamalkan dalam pertandingan generasi domestik yang lalu. Idea teras ialah: jika ayat yang dihasilkan oleh model adalah paling serupa dengan hasil semua model, maka ayat ini boleh dianggap sebagai purata semua model. Dengan cara ini, purata dalam erti kata kebarangkalian menjadi purata dalam hasil penjanaan token. Katakan bahawa diberikan sampel ujian, kita mempunyai jawapan calon yang perlu diagregatkan Untuk setiap calon, kita mengira skor korelasi antara ) dan () dan menambahnya bersama-sama sebagai skor kualiti (). Sumbernya boleh membenamkan kesamaan kosinus lapisan (ditandakan sebagai emb_a_s), ROUGE-L peringkat perkataan (ditandakan sebagai word_a_f), dan ROUGE-L peringkat aksara (ditandakan sebagai char_a_f Berikut ialah beberapa penunjuk persamaan yang dibina secara artifisial, termasuk penunjuk literal . dan semantik.
Alamat kod: https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
Kelima, MoE
Akhir sekali, model pakar campuran yang paling penting (Campuran Pakar ( Pendek kata MoE), ini ialah kaedah seni bina model yang menggabungkan berbilang sub-model (iaitu "pakar"). Ia bertujuan untuk meningkatkan kesan ramalan keseluruhan melalui kerja kolaboratif pelbagai pakar model. dan kecekapan operasi Seni bina MoE model besar termasuk mekanisme gating dan rangkaian pakar Mekanisme gating bertanggungjawab untuk memperuntukkan berat setiap pakar berdasarkan data input untuk menentukan sumbangan akhir setiap pakar. . Tahap sumbangan kepada output pada masa yang sama, mekanisme pemilihan pakar akan memilih sebahagian daripada pakar untuk mengambil bahagian dalam pengiraan ramalan sebenar mengikut arahan isyarat gating ini bukan sahaja mengurangkan keperluan pengkomputeran keseluruhan , tetapi juga membolehkan model memilih yang terbaik berdasarkan input yang berbeza
Campuran Pakar (MoE) bukanlah konsep baharu baru-baru ini Konsep Campuran Pakar boleh dikesan kembali kepada kertas "Adaptive Mixture of Pakar Tempatan" diterbitkan pada tahun 1991. Sama seperti pembelajaran ensemble, terasnya adalah untuk mewujudkan mekanisme penyelarasan dan gabungan untuk koleksi rangkaian pakar bebas. Di bawah seni bina sedemikian, setiap rangkaian bebas (iaitu, "pakar") bertanggungjawab untuk memproses sesuatu bahagian tertentu set data, dan fokus pada kawasan data input tertentu ini mungkin berat sebelah terhadap topik tertentu, medan tertentu, klasifikasi masalah tertentu, dsb., dan bukan konsep yang jelas
. menghadapi data input yang berbeza, satu Isu utama ialah bagaimana sistem memutuskan pakar yang akan mengendalikannya The Gating Network berada di sini untuk menyelesaikan masalah ini keseluruhan proses latihan. Rangkaian kawalan akan dilatih secara serentak dan tidak memerlukan manipulasi manual yang jelas
Dalam tempoh dari 2010 hingga 2015, dua hala tuju penyelidikan mempunyai kesan penting ke atas pembangunan Model Pakar Campuran (MoE):
.组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
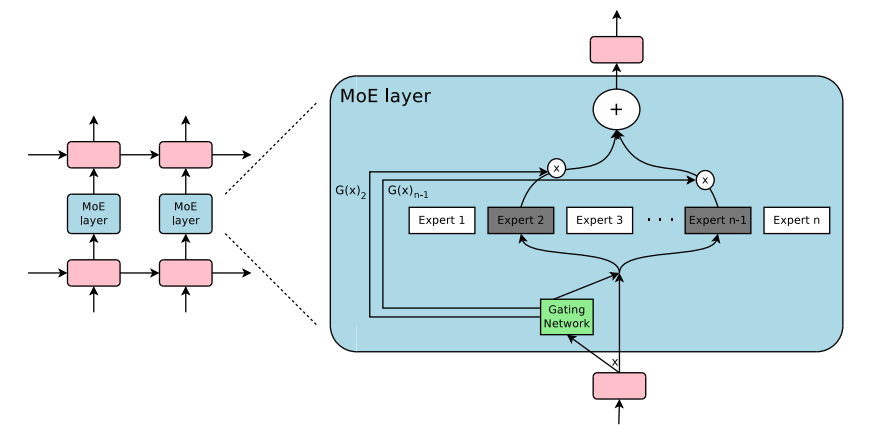
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
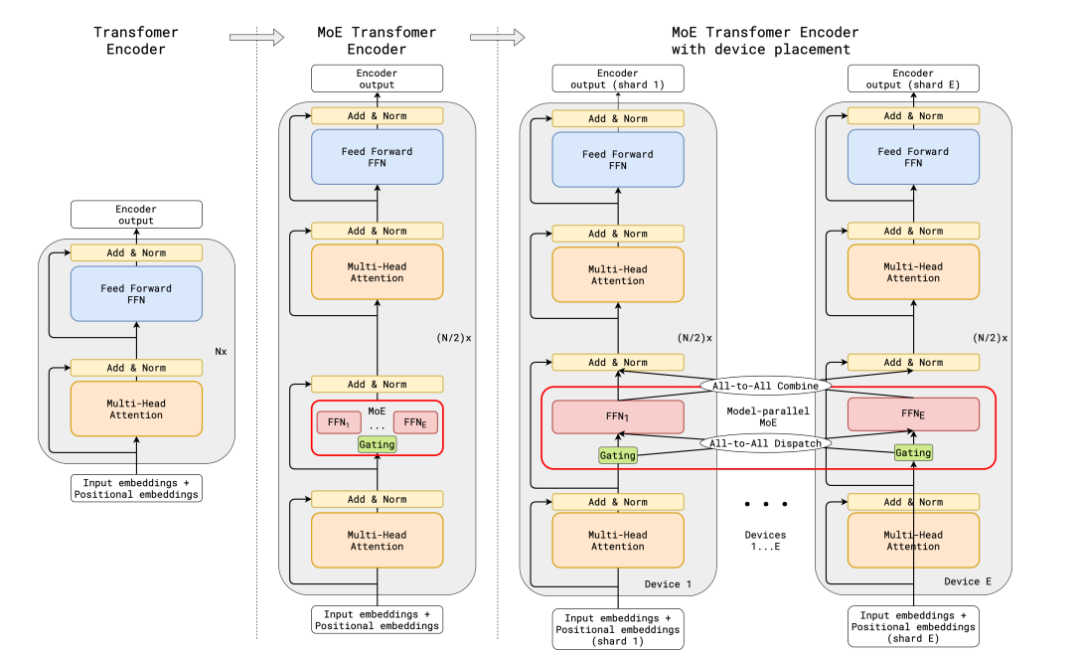
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)Berkenaan penambahbaikan seni bina MoE, Switch Transformers mereka satu lapisan Transformer Suis khas yang boleh memproses dua input bebas (iaitu dua token berbeza) dan dilengkapi dengan empat pakar untuk pemprosesan. Bertentangan dengan idea pakar top2 asal, Switch Transformers menggunakan strategi pakar top1 yang dipermudahkan. Seperti yang ditunjukkan dalam rajah di bawah:
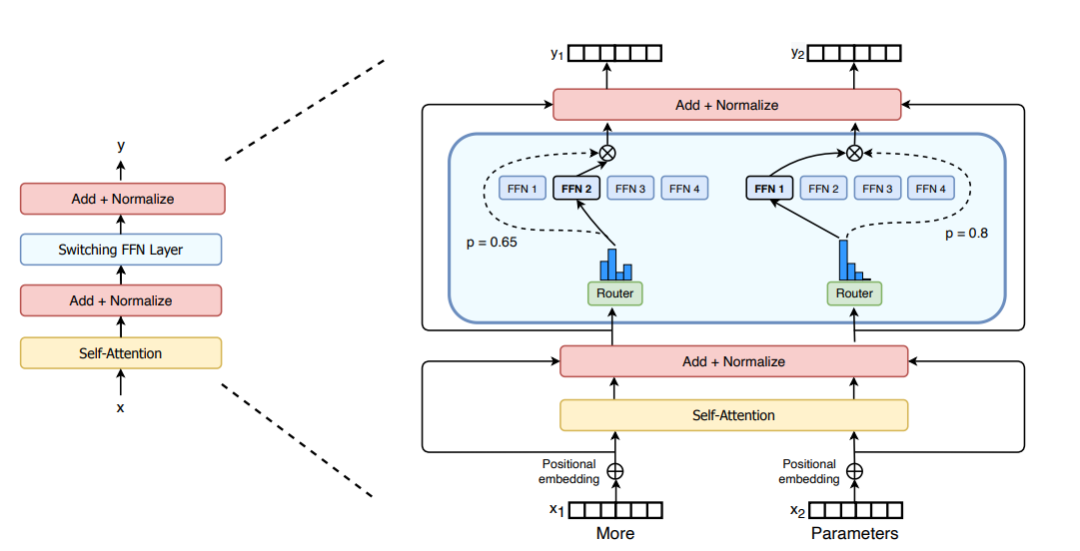 Picture
Picture
Perbezaan, seni bina DeepSeek MoE, model besar domestik yang terkenal, mereka bentuk pakar kongsi yang mengambil bahagian dalam pengaktifan setiap masa Reka bentuknya berdasarkan premis itu pakar tertentu boleh Mahir dalam bidang pengetahuan tertentu. Dengan pembahagian yang terperinci bagi bidang pengetahuan pakar, adalah mungkin untuk menghalang seorang pakar daripada perlu menguasai terlalu banyak pengetahuan, dengan itu mengelakkan kekeliruan pengetahuan. Pada masa yang sama, menubuhkan pakar kongsi memastikan bahawa beberapa pengetahuan yang boleh digunakan secara universal digunakan dalam setiap pengiraan. 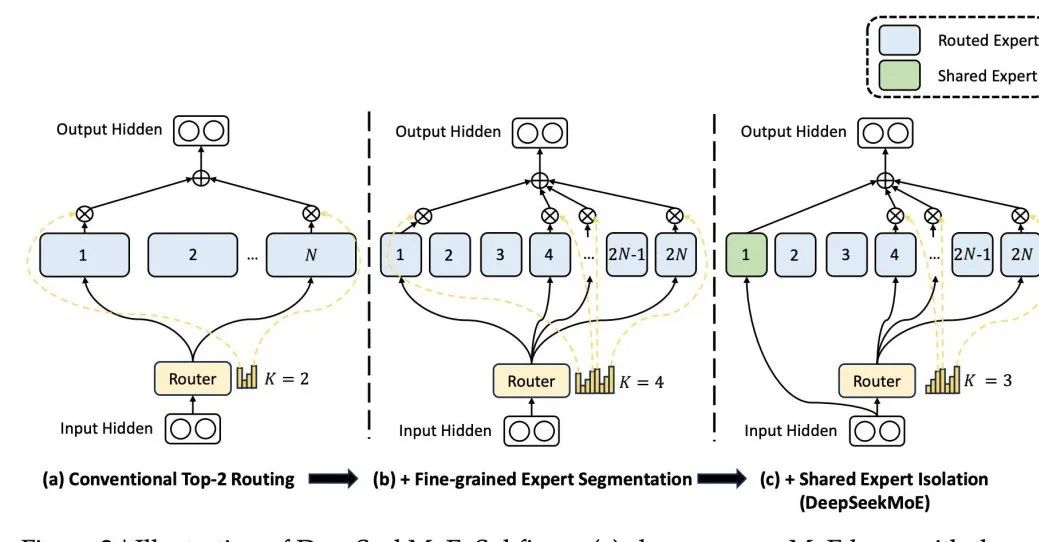 Gambar
Gambar
Atas ialah kandungan terperinci Mari kita bincangkan tentang kaedah gabungan model model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!