

 Peranti teknologiAI1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Peranti teknologiAI1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT


Alamat kertas: https://arxiv.org/abs/2307.09283
Alamat kod: https://github.com/THU-MIG/RepViT
ViT
-
MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。 - 在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
RepViT超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。
好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
方法
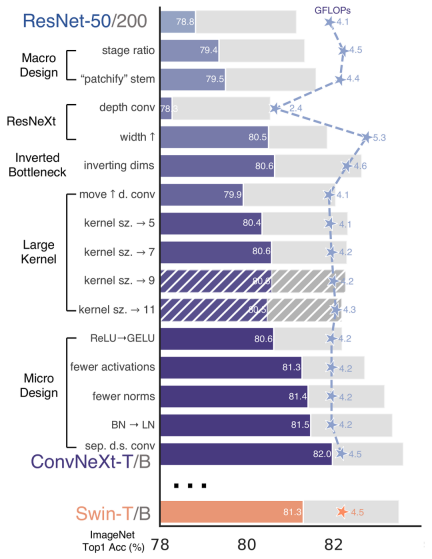
再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-LAdalah disebut dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala mereka (🎜Hasil eksperimen menunjukkan bahawa <code style=" background-color: rgb padding: jejari sempadan: limpahan-balut: pecah-perkataan: paparan: sebaris-blok kecekapan ke atas vit ringan tercanggih sedia ada pada pelbagai tugas penglihatan termasuk klasifikasi imagenet pengesanan objek coco-2017 dan pembahagian contoh segmentasi semantik ade20k khususnya dalam warna latar belakang: break-word text-indent: inline-block>RepViT kod> dalam <code style="background-color: rgb(231, 243, 237); padding: 1px 3px; border-radius: 4px; overflow-wrap: break-word; text-indent: 0px; display: inline- block;">iPhone 12 mencapai kependaman hampir 1ms dan lebih 80% ketepatan Top-1, yang merupakan penemuan pertama untuk model ringan. 🎜Baiklah, perkara yang perlu dibimbangkan oleh semua orang seterusnya ialah "Bagaimana untuk mereka bentuk model dengan kependaman yang rendah tetapi ketepatan yang tinggi"? 🎜
Kaedah
🎜🎜🎜sekali lagi Swin-Transformerseni bina rangkaian neural convolutional tulen. Begitu juga, RepViT juga terutamanya dengan menyepadukan secara beransur-ansur reka bentuk seni bina ViT ringan ke dalam CNN ringan standard, iaitu, MobileNetV3-L untuk melaksanakan transformasi yang disasarkan (pengubahsuaian ajaib) Dalam proses ini, pengarang mempertimbangkan elemen reka bentuk pada tahap butiran yang berbeza dan mencapai matlamat pengoptimuman melalui satu siri langkah. 🎜
Penjajaran resipi latihan
Dalam kertas kerja, metrik baharu diperkenalkan untuk mengukur kependaman pada peranti mudah alih dan memastikan strategi latihan konsisten dengan ViT ringan yang popular pada masa ini. Tujuan inisiatif ini adalah untuk memastikan ketekalan latihan model, yang melibatkan dua konsep utama iaitu pengukuran kelewatan dan pelarasan strategi latihan.
Metrik Kependaman
Untuk mengukur prestasi model dengan lebih tepat pada peranti mudah alih sebenar, penulis memilih untuk mengukur terus kependaman sebenar model pada peranti sebagai metrik garis dasar. Kaedah pengukuran ini berbeza daripada kajian terdahulu, yang kebanyakannya menggunakan FLOPs atau saiz model mengoptimumkan kelajuan inferens model dan metrik ini tidak selalu mencerminkan kependaman sebenar dalam aplikasi mudah alih dengan baik. FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器【ViTs 模型必备的优化器】,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
块设计的优化
接下来,基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。
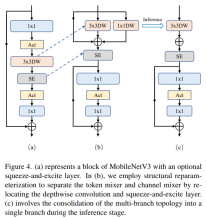
分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-LPenjajaran strategi latihan
Di sini, strategi latihan MobileNetV3-L dilaraskan untuk diselaraskan dengan model ViT ringan yang lain. Ini termasuk menggunakan AdamW pengoptimum [pengoptimum penting untuk model ViTs], melakukan 5 zaman latihan memanaskan badan dan menggunakan penjadualan kadar pembelajaran penyepuhlindapan kosinus untuk 300 zaman latihan. Walaupun pelarasan ini mengakibatkan sedikit penurunan dalam ketepatan model, keadilan terjamin.
Pengadun Token berasingan dan pengadun saluran
Sekeping ini terutamanya untukStruktur blok MobileNetV3-L telah dipertingkatkan untuk memisahkan pengadun token dan pengadun saluran. Struktur blok MobileNetV3 asal terdiri daripada lilitan diluaskan 1x1, diikuti oleh lilitan mendalam dan lapisan unjuran 1x1, dan kemudian menyambungkan input dan output melalui sambungan baki. Atas dasar ini, RepViT memajukan konvolusi kedalaman supaya pengadun saluran dan pengadun token boleh dipisahkan. Untuk meningkatkan prestasi, pengparameteran semula struktur juga diperkenalkan untuk memperkenalkan topologi berbilang cawangan untuk penapis dalam semasa latihan. Akhirnya, penulis berjaya mengasingkan pengadun token dan pengadun saluran dalam blok MobileNetV3 dan menamakan blok tersebut sebagai blok RepViT.
juga diperkenalkan untuk memperkenalkan topologi berbilang cawangan untuk penapis dalam semasa latihan. Akhirnya, penulis berjaya mengasingkan pengadun token dan pengadun saluran dalam blok MobileNetV3 dan menamakan blok tersebut sebagai blok RepViT.
ViT biasanya menggunakan operasi "patchify" yang membahagikan imej input kepada tompok tidak bertindih sebagai batang. Walau bagaimanapun, pendekatan ini mempunyai masalah dengan pengoptimuman latihan dan kepekaan terhadap resipi latihan. Oleh itu, pengarang menggunakan konvolusi awal sebaliknya, pendekatan yang telah diterima pakai oleh banyak ViT ringan. Sebaliknya, MobileNetV3-L menggunakan batang yang lebih kompleks untuk pensampelan turun 4x. Dengan cara ini, walaupun bilangan awal penapis dinaikkan kepada 24, jumlah kependaman dikurangkan kepada 0.86ms, manakala ketepatan 1 teratas meningkat kepada 73.9%.
Lapisan Pensampelan Turun Lebih Dalam
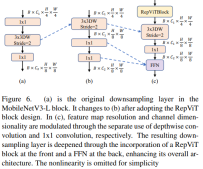
Dalam ViT, pensampelan spatial biasanya dilaksanakan melalui lapisan penggabungan tampalan yang berasingan. Jadi di sini kita boleh menggunakan lapisan pensampelan yang berasingan dan lebih mendalam untuk meningkatkan kedalaman rangkaian dan mengurangkan kehilangan maklumat akibat pengurangan resolusi. Khususnya, pengarang mula-mula menggunakan lilitan 1x1 untuk melaraskan dimensi saluran, dan kemudian menyambungkan input dan output dua lilitan 1x1 melalui baki untuk membentuk rangkaian suapan hadapan. Selain itu, mereka menambah blok RepViT di hadapan untuk memperdalam lagi lapisan pensampelan bawah, satu langkah yang meningkatkan ketepatan 1 teratas kepada 75.4% dengan kependaman 0.96ms.
Pengkelas yang lebih mudah
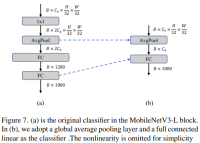
Dalam ViT ringan, pengelas biasanya terdiri daripada lapisan pengumpulan purata global diikuti oleh lapisan linear. Sebaliknya, MobileNetV3-L menggunakan pengelas yang lebih kompleks. Oleh kerana peringkat akhir kini mempunyai lebih banyak saluran, pengarang menggantikannya dengan pengelas mudah, lapisan pengumpulan purata global dan lapisan linear Langkah ini mengurangkan kependaman kepada 0.77ms manakala kadarnya ialah 74.8%.
Nisbah peringkat keseluruhan
Nisbah peringkat mewakili nisbah bilangan blok dalam peringkat yang berbeza, sekali gus menunjukkan pengagihan pengiraan dalam setiap peringkat. Kertas itu memilih nisbah peringkat yang lebih optimum iaitu 1:1:7:1, dan kemudian meningkatkan kedalaman rangkaian kepada 2:2:14:2, dengan itu mencapai reka letak yang lebih mendalam. Langkah ini meningkatkan ketepatan top-1 kepada 76.9% dengan kependaman 1.02 ms.
Pelarasan reka bentuk mikro
Seterusnya, RepViT melaraskan CNN ringan melalui reka bentuk mikro lapisan demi lapisan, yang termasuk memilih saiz kernel lilitan yang sesuai dan mengoptimumkan kedudukan lapisan squeeze-and-excitation (SE). Kedua-dua kaedah meningkatkan prestasi model dengan ketara.
Pemilihan saiz kernel lilitan
Adalah diketahui bahawa prestasi dan kependaman CNN biasanya dipengaruhi oleh saiz kernel lilitan. Contohnya, untuk memodelkan kebergantungan konteks jarak jauh seperti MHSA, ConvNeXt menggunakan kernel konvolusi yang besar, menghasilkan peningkatan prestasi yang ketara. Walau bagaimanapun, kernel lilitan besar tidak mesra mudah alih kerana kerumitan pengiraan dan kos akses memorinya. MobileNetV3-L terutamanya menggunakan lilitan 3x3, dan lilitan 5x5 digunakan dalam beberapa blok. Pengarang menggantikannya dengan lilitan 3x3, yang mengakibatkan kependaman dikurangkan kepada 1.00ms sambil mengekalkan ketepatan 1 teratas sebanyak 76.9%.
Kedudukan lapisan SE
Satu kelebihan modul perhatian kendiri berbanding konvolusi ialah keupayaan untuk melaraskan pemberat berdasarkan input, yang dipanggil sifat terdorong data. Sebagai modul perhatian saluran, lapisan SE boleh menampung had lilitan dalam kekurangan sifat terdorong data, dengan itu membawa kepada prestasi yang lebih baik. MobileNetV3-L menambah lapisan SE dalam beberapa blok, terutamanya memfokuskan pada dua peringkat terakhir. Walau bagaimanapun, peringkat resolusi rendah memperoleh keuntungan ketepatan yang lebih kecil daripada operasi pengumpulan purata global yang disediakan oleh SE berbanding peringkat resolusi lebih tinggi. Pengarang mereka strategi untuk menggunakan lapisan SE secara merentas blok pada semua peringkat untuk memaksimumkan peningkatan ketepatan dengan kenaikan kelewatan terkecil Langkah ini meningkatkan ketepatan 1 teratas kepada 77.4% sambil melambatkan dikurangkan kepada 0.87ms. [Malah, Baidu telah pun melakukan eksperimen dan perbandingan mengenai perkara ini dan mencapai kesimpulan ini sejak dahulu lagi Lapisan SE lebih berkesan apabila diletakkan dekat dengan lapisan dalam]
Seni Bina Rangkaian
Akhir sekali, dengan menyepadukan strategi penambahbaikan di atas, kami mendapat modelRepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3. Begitu juga, varian yang berbeza terutamanya dibezakan oleh bilangan saluran dan blok setiap peringkat.
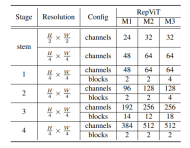
Experiments
Image Classification

Detection and Segmentation

Summary
ini kertas mengkaji semula reka bentuk yang cekap CNNs ringan dengan memperkenalkan pilihan seni bina VIT ringan. Ini membawa kepada kemunculan RepViT, sebuah keluarga baharu CNN ringan yang direka untuk peranti mudah alih yang terhad sumber. RepViT mengatasi prestasi ViT dan CNN ringan terkini yang sedia ada dalam pelbagai tugas penglihatan, menunjukkan prestasi dan kependaman yang unggul. Ini menyerlahkan potensi CNN ringan semata-mata untuk peranti mudah alih.
Atas ialah kandungan terperinci 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AM
Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AMMemanfaatkan kuasa AI di peranti: Membina CLI Chatbot Peribadi Pada masa lalu, konsep pembantu AI peribadi kelihatan seperti fiksyen sains. Bayangkan Alex, seorang peminat teknologi, bermimpi seorang sahabat AI yang pintar, yang tidak bergantung
 AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AM
AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AMPelancaran AI4MH mereka berlaku pada 15 April, 2025, dan Luminary Dr. Tom Insel, M.D., pakar psikiatri yang terkenal dan pakar neurosains, berkhidmat sebagai penceramah kick-off. Dr. Insel terkenal dengan kerja cemerlangnya dalam penyelidikan kesihatan mental dan techno
 Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM
Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM"Kami mahu memastikan bahawa WNBA kekal sebagai ruang di mana semua orang, pemain, peminat dan rakan kongsi korporat, berasa selamat, dihargai dan diberi kuasa," kata Engelbert, menangani apa yang telah menjadi salah satu cabaran sukan wanita yang paling merosakkan. Anno
 Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AMPengenalan Python cemerlang sebagai bahasa pengaturcaraan, terutamanya dalam sains data dan AI generatif. Manipulasi data yang cekap (penyimpanan, pengurusan, dan akses) adalah penting apabila berurusan dengan dataset yang besar. Kami pernah meliputi nombor dan st
 Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AM
Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AMSebelum menyelam, kaveat penting: Prestasi AI adalah spesifik yang tidak ditentukan dan sangat digunakan. Dalam istilah yang lebih mudah, perbatuan anda mungkin berbeza -beza. Jangan ambil artikel ini (atau lain -lain) sebagai perkataan akhir -sebaliknya, uji model ini pada senario anda sendiri
 AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AM
AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AMMembina portfolio AI/ML yang menonjol: Panduan untuk Pemula dan Profesional Mewujudkan portfolio yang menarik adalah penting untuk mendapatkan peranan dalam kecerdasan buatan (AI) dan pembelajaran mesin (ML). Panduan ini memberi nasihat untuk membina portfolio
 AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AM
AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AMHasilnya? Pembakaran, ketidakcekapan, dan jurang yang melebar antara pengesanan dan tindakan. Tak satu pun dari ini harus datang sebagai kejutan kepada sesiapa yang bekerja dalam keselamatan siber. Janji Agentic AI telah muncul sebagai titik perubahan yang berpotensi. Kelas baru ini
 Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AM
Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AMImpak segera berbanding perkongsian jangka panjang? Dua minggu yang lalu Openai melangkah ke hadapan dengan tawaran jangka pendek yang kuat, memberikan akses kepada pelajar A.S. dan Kanada.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

