
Rumah >Peranti teknologi >AI >ICLR 2024 Spotlight |
ICLR 2024 Spotlight |

- PHPzke hadapan
- 2024-03-07 16:16:16882semak imbas
Kuantasi model ialah teknologi utama dalam pemampatan dan pecutan model Ia mengkuantiskan berat model dan nilai pengaktifan kepada bit yang rendah, membolehkan model menduduki lebih sedikit overhed memori dan mempercepatkan inferens. Untuk model bahasa besar dengan parameter besar, kuantifikasi model adalah lebih penting. Sebagai contoh, parameter 175B model GPT-3 menggunakan 350GB memori apabila dimuatkan menggunakan format FP16, memerlukan sekurang-kurangnya lima 80GB A100 GPU.
Tetapi jika berat model GPT-3 boleh dimampatkan kepada 3bit, maka satu A100-80GB boleh digunakan untuk memuatkan semua berat model.
Pada masa ini, terdapat cabaran yang jelas dalam algoritma pengkuantitian pasca latihan model bahasa berskala besar sedia ada, iaitu ia bergantung pada tetapan manual parameter pengkuantitian dan tidak mempunyai proses pengoptimuman yang sepadan. Ini menyebabkan kaedah sedia ada sering mengalami kemerosotan prestasi apabila melakukan pengkuantitian bit rendah. Walaupun latihan sedar kuantisasi berkesan dalam menentukan konfigurasi kuantisasi optimum, ia memerlukan kos latihan tambahan dan sokongan data. Terutamanya dalam model bahasa berskala besar, jumlah pengiraan itu sendiri sudah besar, yang menjadikan penerapan latihan sedar kuantisasi dalam kuantisasi model bahasa berskala besar lebih sukar.
Ini menimbulkan persoalan: bolehkah kita mencapai prestasi latihan sedar kuantisasi sambil mengekalkan kecekapan masa dan data kuantisasi selepas latihan?
Untuk menangani masalah pengoptimuman parameter kuantisasi semasa latihan selepas model bahasa besar, sekumpulan penyelidik dari Makmal Kepintaran Buatan Shanghai, Universiti Hong Kong dan Universiti China Hong Kong mencadangkan "OmniQuant: Omnidirectionally Kuantiti Ditentukur untuk Model Bahasa Besar". Algoritma ini bukan sahaja menyokong pengkuantitian pemberat dan pengaktifan dalam model bahasa besar, tetapi juga boleh menyesuaikan diri dengan pelbagai tetapan bit pengkuantitian yang berbeza.

alamat kertas arXiv: https://arxiv.org/abs/2308.13137
Alamat kertas Semakan Terbuka: https://openreview.net/forum?id=8Wuvhh0LYW
Alamat kod: https://openreview.net/forum?id=8Wuvhh0LYW
: https://github. com. Selain itu, sambil mencapai model pengkuantitian berprestasi tinggi, ia mengekalkan kecekapan masa latihan dan kecekapan data pengkuantitian selepas latihan. Contohnya, OmniQuant boleh mengemas kini parameter pengkuantitian model LLaMA-7B ~ LLaMA70B dalam masa 1-16 jam pada satu kad A100-40GB. Untuk mencapai matlamat ini, OmniQuant menggunakan rangka kerja pengecilan ralat pengkuantitian bijak Blok. Pada masa yang sama, OmniQuant telah merangka dua strategi baharu untuk meningkatkan parameter pengkuantitian boleh dipelajari, termasuk pemotongan berat boleh dipelajari (LWC) untuk meringankan kesukaran pengkuantitian pemberat, dan transformasi setara yang boleh dipelajari (Transformasi Setara Boleh Dipelajari, LET), mengalihkan lagi cabaran pengkuantitian daripada nilai pengaktifan kepada pemberat.

Pengurangan ralat pengkuantitian dari segi blok
OmniQuant mencadangkan proses pengoptimuman baharu yang menggunakan pengecilan ralat pengkuantitian bijak Blok dan mengoptimumkan parameter pengkuantitian tambahan dalam cara yang boleh dibezakan. Antaranya, objektif pengoptimuman dirumuskan seperti berikut:di mana F mewakili fungsi pemetaan blok pengubah dalam LLM, W dan merupakan parameter pengkuantitian dalam keratan berat boleh dipelajari (LWC) dan transformasi setara boleh dipelajari (LET) masing-masing. . OmniQuant memasang pengkuantitian mengikut Blok untuk mengkuantumkan parameter secara berurutan dalam satu Blok Transformer sebelum beralih ke yang seterusnya.
Keratan Berat Boleh Belajar (LWC)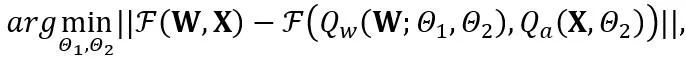
Transformasi setara melakukan pemindahan magnitud antara berat model dan nilai pengaktifan. Transformasi setara yang boleh dipelajari yang diterima pakai oleh OmniQuant menyebabkan pengagihan berat model berubah secara berterusan dengan latihan semasa proses pengoptimuman parameter. Kaedah sebelumnya untuk mempelajari ambang pemotongan berat secara langsung [1,2] hanya sesuai apabila taburan berat tidak berubah secara drastik, jika tidak, ia akan menjadi sukar untuk menumpu. Berdasarkan masalah ini, tidak seperti kaedah sebelumnya yang secara langsung mempelajari ambang keratan berat, LWC mengoptimumkan keamatan keratan dengan cara berikut:
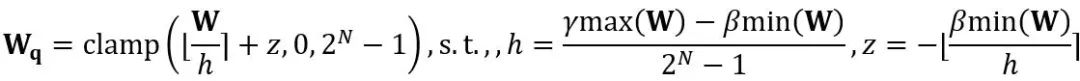
di mana ⌊⋅⌉ mewakili operasi pembundaran. N ialah bilangan digit sasaran. 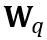 dan W masing-masing mewakili berat terkuantisasi dan ketepatan penuh. h ialah faktor normalisasi pemberat dan z ialah nilai titik sifar. Operasi pengapit mengehadkan nilai terkuantasi kepada julat integer N-bit, iaitu,
dan W masing-masing mewakili berat terkuantisasi dan ketepatan penuh. h ialah faktor normalisasi pemberat dan z ialah nilai titik sifar. Operasi pengapit mengehadkan nilai terkuantasi kepada julat integer N-bit, iaitu, 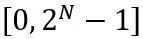 . Dalam formula di atas,
. Dalam formula di atas, 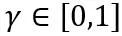 dan
dan 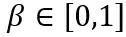 ialah kekuatan keratan yang boleh dipelajari bagi sempadan atas dan bawah berat masing-masing. Oleh itu, dalam fungsi objektif pengoptimuman
ialah kekuatan keratan yang boleh dipelajari bagi sempadan atas dan bawah berat masing-masing. Oleh itu, dalam fungsi objektif pengoptimuman 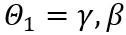 .
.
Learnable Equivalent Transformation (LET)
Selain mengoptimumkan ambang keratan untuk mencapai LWC dengan pemberat yang lebih sesuai untuk kuantisasi, OmniQuant mengurangkan lagi kesukaran mengkuantifikasi nilai pengaktifan melalui LET. Memandangkan outlier dalam nilai pengaktifan LLM wujud dalam saluran tertentu, kaedah sebelumnya seperti SmoothQuant [3], Outlier Supression+[4] memindahkan kesukaran kuantifikasi daripada nilai pengaktifan kepada pemberat melalui transformasi yang setara secara matematik.
Walau bagaimanapun, parameter transformasi setara yang diperoleh melalui pemilihan manual atau carian tamak akan mengehadkan prestasi model terkuantiti. Terima kasih kepada pengenalan peminimakan ralat pengkuantitian Blok, LET OmniQuant boleh menentukan parameter transformasi setara yang optimum dengan cara yang boleh dibezakan. Diilhamkan oleh Outlier Suppression+~citep {outlier-plus}, penskalaan peringkat saluran dan peralihan peringkat saluran digunakan untuk memanipulasi pengagihan pengaktifan, memberikan penyelesaian yang berkesan kepada masalah terpencil dalam nilai pengaktifan. Secara khusus, OmniQuant meneroka transformasi yang setara dalam lapisan linear dan operasi perhatian.
Transformasi setara dalam lapisan linear: Lapisan linear menerima urutan input token 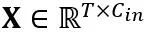 , dengan T ialah panjang token dan merupakan hasil darab matriks berat
, dengan T ialah panjang token dan merupakan hasil darab matriks berat 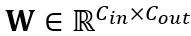 dan vektor pincang
dan vektor pincang 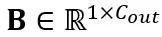 . Ungkapan lapisan linear yang setara secara matematik ialah:
. Ungkapan lapisan linear yang setara secara matematik ialah:
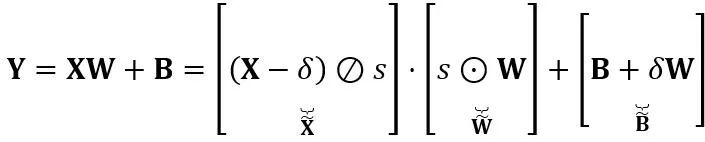
di mana Y mewakili output, 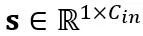 dan
dan 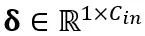 ialah penskalaan dan parameter peralihan peringkat saluran masing-masing,
ialah penskalaan dan parameter peralihan peringkat saluran masing-masing, 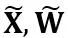 dan
dan 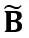 masing-masing adalah pengaktifan, berat dan pincang yang setara, ⊘ dan ⊙ mewakili pembahagian dan pendaraban peringkat unsur. Melalui penukaran yang setara dengan formula di atas, nilai pengaktifan ditukar kepada bentuk yang lebih mudah untuk diukur, dengan mengorbankan peningkatan kesukaran untuk mengukur berat. Dalam pengertian ini, LWC boleh meningkatkan prestasi pengkuantitian model yang dicapai oleh LET kerana ia menjadikan pemberat lebih mudah untuk diukur. Akhir sekali, OmniQuant mengkuantifikasikan pengaktifan dan pemberat yang diubah seperti berikut
masing-masing adalah pengaktifan, berat dan pincang yang setara, ⊘ dan ⊙ mewakili pembahagian dan pendaraban peringkat unsur. Melalui penukaran yang setara dengan formula di atas, nilai pengaktifan ditukar kepada bentuk yang lebih mudah untuk diukur, dengan mengorbankan peningkatan kesukaran untuk mengukur berat. Dalam pengertian ini, LWC boleh meningkatkan prestasi pengkuantitian model yang dicapai oleh LET kerana ia menjadikan pemberat lebih mudah untuk diukur. Akhir sekali, OmniQuant mengkuantifikasikan pengaktifan dan pemberat yang diubah seperti berikut

di mana Q_a ialah pengkuantiti MinMax biasa dan Q_w ialah pengkuantiti MinMax dengan pemotongan berat yang boleh dipelajari (iaitu LWC yang dicadangkan).
Transformasi setara dalam operasi perhatian: Selain lapisan linear, operasi perhatian juga menduduki kebanyakan pengiraan LLM. Tambahan pula, mod inferens autoregresif LLM memerlukan cache nilai kunci (KV) untuk setiap token, yang menghasilkan keperluan memori yang besar untuk jujukan yang panjang. Oleh itu, OmniQuant juga mempertimbangkan pengkuantitian matriks Q/K/V dalam pengiraan daya autonomi kepada bit rendah. Secara khusus, transformasi setara yang boleh dipelajari dalam matriks perhatian kendiri boleh ditulis sebagai:

di mana 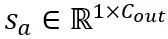 faktor penskalaan. Pengiraan kuantitatif dalam pengiraan perhatian kendiri dinyatakan sebagai
faktor penskalaan. Pengiraan kuantitatif dalam pengiraan perhatian kendiri dinyatakan sebagai 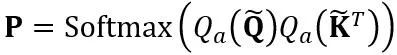 . Di sini OmniQuant juga menggunakan skema pengkuantitian MinMax sebagai
. Di sini OmniQuant juga menggunakan skema pengkuantitian MinMax sebagai 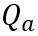 untuk mengukur
untuk mengukur 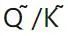 matriks. Oleh itu,
matriks. Oleh itu, 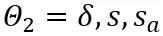 dalam fungsi objektif akhirnya dioptimumkan.
dalam fungsi objektif akhirnya dioptimumkan.
Pseudocode

Algoritma pseudo OmniQuant ditunjukkan dalam rajah di atas. Ambil perhatian bahawa parameter tambahan yang diperkenalkan oleh LWC dan LET boleh dihapuskan selepas model dikuantisasi, iaitu, OmniQuant tidak memperkenalkan apa-apa overhed tambahan kepada model terkuantisasi, jadi ia boleh disesuaikan secara langsung kepada alatan penggunaan kuantisasi sedia ada. . Seperti yang dapat dilihat, OmniQuant secara konsisten mengatasi model sebelumnya dalam pelbagai model LLM (OPT, LLaMA-1, LLaMA-2) dan konfigurasi pengkuantitian pelbagai (termasuk W2A16, W2A16g128, W2A16g64, W3A16, W3A16g16g128 dan W48A kaedah kuantifikasi sahaja. Pada masa yang sama, eksperimen ini menunjukkan kepelbagaian OmniQuant dan keupayaannya untuk menyesuaikan diri dengan pelbagai konfigurasi kuantifikasi. Sebagai contoh, sementara AWQ [5] amat berkesan pada pengkuantitian kumpulan, OmniQuant menunjukkan prestasi yang unggul dalam kedua-dua kuantisasi peringkat saluran dan peringkat kumpulan. Selain itu, apabila bilangan bit pengkuantitian berkurangan, kelebihan prestasi OmniQuant menjadi lebih jelas.
Dalam tetapan di mana kedua-dua pemberat dan pengaktifan dikuantisasi, fokus utama eksperimen adalah pada pengkuantitian W6A6 dan W4A4. Pengkuantitian W8A8 dikecualikan daripada persediaan percubaan kerana SmoothQuant sebelumnya mencapai pengkuantitian model W8A8 yang hampir tanpa kerugian berbanding model ketepatan penuh. Angka di atas menunjukkan keputusan percubaan kuantifikasi OmniQuant bagi nilai pengaktifan berat pada model LLaMA. Terutama sekali, OmniQuant meningkatkan ketepatan purata dengan ketara merentas model kuantifikasi W4A4 yang berbeza, dengan peningkatan antara +4.99% hingga +11.80%. Terutamanya dalam model LLaMA-7B, OmniQuant malah mengatasi kaedah latihan sedar pengkuantitian terkini LLM-QAT [6] dengan jurang yang ketara sebanyak +6.22%. Peningkatan ini menunjukkan keberkesanan memperkenalkan parameter tambahan yang boleh dipelajari, yang lebih berfaedah daripada pelarasan berat global yang digunakan dalam latihan sedar pengkuantitian.

Pada masa yang sama, model yang dikuantisasi menggunakan OmniQuant boleh digunakan dengan lancar pada MLC-LLM [7]. Rajah di atas menunjukkan keperluan memori dan kelajuan inferens model pengkuantitian siri LLaMA pada NVIDIA A100-80G.
Weights Memory (WM) mewakili storan berat terkuantisasi, manakala Running Memory (RM) mewakili memori semasa inferens, yang terakhir adalah lebih tinggi kerana nilai pengaktifan tertentu dikekalkan. Kelajuan inferens diukur dengan menghasilkan 512 token. Jelas sekali bahawa model terkuantisasi mengurangkan penggunaan memori dengan ketara berbanding model ketepatan penuh 16-bit. Tambahan pula, pengkuantitian W4A16g128 dan W2A16g128 hampir menggandakan kelajuan inferens.
Perlu diingat bahawa MLC-LLM [7] turut menyokong penggunaan model kuantifikasi OmniQuant pada platform lain, termasuk telefon Android dan telefon IOS. Seperti yang ditunjukkan dalam rajah di atas, aplikasi LLM Persendirian baru-baru ini menggunakan algoritma OmniQuant untuk melengkapkan penggunaan LLM yang cekap memori pada berbilang platform seperti iPhone, iPad, macOS, dsb.
Ringkasan
OmniQuant ialah algoritma pengkuantitian model bahasa besar termaju yang memajukan pengkuantitian kepada format bit rendah. Prinsip teras OmniQuant adalah untuk mengekalkan berat ketepatan penuh asal sambil menambah parameter pengkuantitian yang boleh dipelajari. Ia menggunakan sambungan berat yang boleh dipelajari dan transformasi yang setara untuk mengoptimumkan keserasian pengkuantitian berat dan nilai pengaktifan. Semasa menggabungkan kemas kini kecerunan, OmniQuant mengekalkan kecekapan masa latihan dan kecekapan data setanding dengan kaedah PTQ sedia ada. Selain itu, OmniQuant memastikan keserasian perkakasan kerana parameter boleh dilatih tambahannya boleh dimasukkan ke dalam model asal tanpa sebarang overhed tambahan.
Rujukan
[1] Pakatan: Pengaktifan kliping berparameter untuk rangkaian neural terkuantasi.
[2] LSQ: Kuantiti saiz langkah yang dipelajari.🜎 kadar dan jawatan yang cekap -kuantisasi latihan untuk model bahasa besar.
[4] Penindasan outlier+: Pengkuantitian tepat model bahasa besar dengan peralihan dan penskalaan yang setara dan optimum.
[5] Awq: Pengkuantitian berat yang sedar pengaktifan dan pengkuantitian pecutan.
[6] Llm-qat: Latihan sedar kuantisasi tanpa data untuk model bahasa besar.
[7] MLC-LLM: https://github.com/mlc-ai/mlc-llm
Atas ialah kandungan terperinci ICLR 2024 Spotlight |. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!