
Rumah >Peranti teknologi >AI >Melebihi ViT, Meituan, Universiti Zhejiang, dsb. VisionLLAMA yang dicadangkan secara menyeluruh, seni bina bersatu untuk tugas visual
Melebihi ViT, Meituan, Universiti Zhejiang, dsb. VisionLLAMA yang dicadangkan secara menyeluruh, seni bina bersatu untuk tugas visual

- PHPzke hadapan
- 2024-03-07 15:37:02901semak imbas
Selama lebih setengah tahun, seni bina LLaMA sumber terbuka Meta telah bertahan dalam ujian dalam LLM dan mencapai kejayaan yang hebat (latihan yang stabil dan penskalaan mudah).
Mengikuti idea penyelidikan ViT, bolehkah kita benar-benar mencapai penyatuan seni bina bahasa dan imej dengan bantuan seni bina LLaMA yang inovatif?
Mengenai cadangan ini, kajian terbaru VisionLLaMA telah membuat kemajuan. VisionLLaMA telah bertambah baik dengan ketara berbanding kaedah ViT asal dalam banyak tugas arus perdana seperti penjanaan imej (termasuk DIT asas yang Sora bergantung pada) dan pemahaman (pengkelasan, segmentasi, pengesanan, penyeliaan diri).

- Tajuk kertas: VisionLLaMA: Antara Muka LLaMA Disatukan untuk Tugasan Visi
- Alamat kertas: https://absp.
- Alamat kod : https://github.com/Meituan-AutoML/VisionLLaMA
Kejayaan seni bina LLaMA menyebabkan pengarang artikel ini mencadangkan idea yang mudah dan menarik: Bolehkah seni bina ini berjaya dalam modaliti visual yang sama? Jika jawapannya ya, maka kedua-dua model visual dan bahasa boleh menggunakan seni bina bersatu yang sama dan mendapat manfaat daripada pelbagai teknik penggunaan dinamik yang direka untuk LLaMA. Walau bagaimanapun, ini adalah isu yang kompleks kerana terdapat beberapa perbezaan yang jelas antara kedua-dua modaliti.

Tujuan kertas ini adalah untuk menangani cabaran ini dan mengecilkan jurang seni bina antara modaliti yang berbeza, mencadangkan seni bina LLaMA yang disesuaikan dengan tugas penglihatan. Dengan seni bina ini, isu yang berkaitan dengan perbezaan ragam boleh diselesaikan dan data visual dan linguistik boleh diproses secara seragam, yang membawa kepada hasil yang lebih baik.
Sumbangan utama artikel ini adalah seperti berikut:1 Artikel ini mencadangkan VisionLLaMA, seni bina pengubah visual yang serupa dengan LLaMA, untuk mengurangkan perbezaan seni bina antara bahasa dan penglihatan.
2 Kertas kerja ini menyiasat cara untuk menyesuaikan VisionLLaMA kepada tugas penglihatan biasa, termasuk pemahaman imej dan penciptaan (Rajah 1). Kertas kerja ini menyiasat dua skema seni bina visual yang terkenal (struktur biasa dan struktur piramid) dan menilai prestasi mereka dalam senario pembelajaran yang diselia dan diselia sendiri. Selain itu, kertas kerja ini mencadangkan AS2DRoPE (iaitu, Autoscaling 2D RoPE), yang memanjangkan pengekodan kedudukan putaran daripada 1D ke 2D dan menggunakan penskalaan interpolasi untuk menampung resolusi sewenang-wenangnya.
3 Di bawah penilaian yang tepat, VisionLLaMA dengan ketara mengatasi pengubah penglihatan arus perdana dan diperhalusi dengan tepat dalam banyak tugas perwakilan seperti penjanaan imej, pengelasan, pembahagian semantik dan pengesanan objek. Eksperimen yang meluas menunjukkan bahawa VisionLLaMA mempunyai kelajuan penumpuan yang lebih pantas dan prestasi yang lebih baik daripada pengubah penglihatan sedia ada.
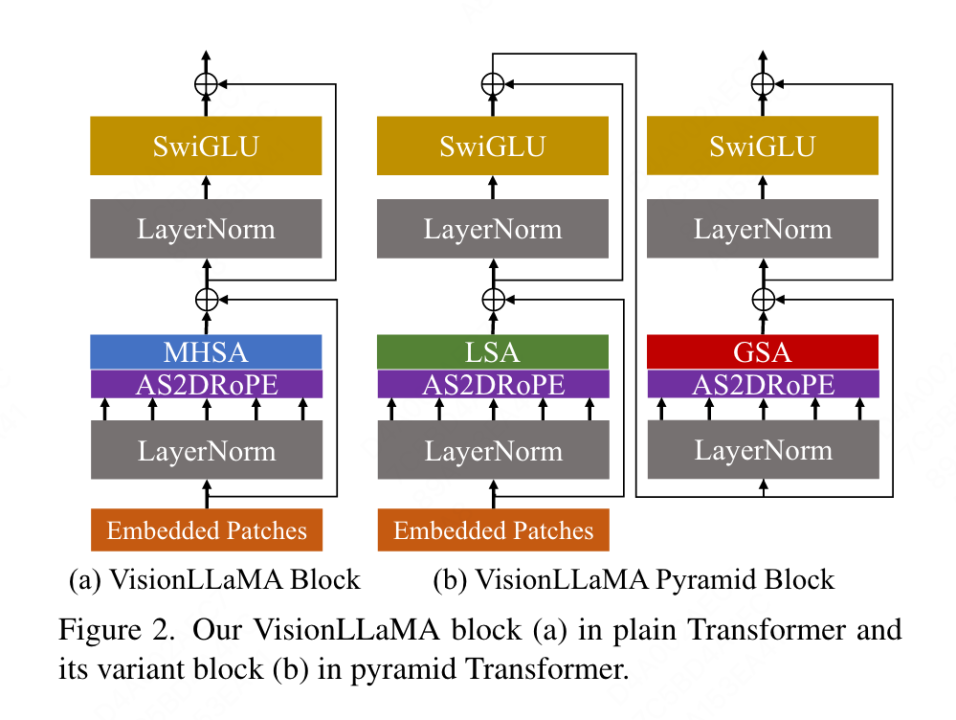
Conventional Transformer VisionLLaMA konvensional mengikut kemungkinan reka bentuk VisionLLaMA yang mungkin dalam artikel ini. Untuk imej, ia mula-mula diubah dan diratakan menjadi jujukan, kemudian token kategori ditambah pada permulaan jujukan, dan keseluruhan jujukan diproses melalui blok L VisionLLaMA. Tidak seperti ViT, VisionLLaMA tidak menambah pengekodan kedudukan pada urutan input kerana blok VisionLLaMA mengandungi pengekodan kedudukan. Khususnya, blok ini berbeza daripada blok ViT standard dalam dua cara: perhatian diri dengan pengekodan kedudukan (RoPE) dan pengaktifan SwiGLU. Artikel ini masih menggunakan LayerNorm dan bukannya RMSNorm kerana artikel ini secara eksperimen mendapati bahawa artikel terdahulu menunjukkan prestasi yang lebih baik (lihat Jadual 11g). Struktur bongkah ditunjukkan dalam Rajah 2(a). Kertas kerja ini mendapati bahawa penggunaan RoPE 1D secara langsung dalam tugas penglihatan tidak digeneralisasikan dengan baik kepada resolusi yang berbeza, jadi ia dilanjutkan kepada bentuk 2D: Pyramid Structure Transformer sangat mudah
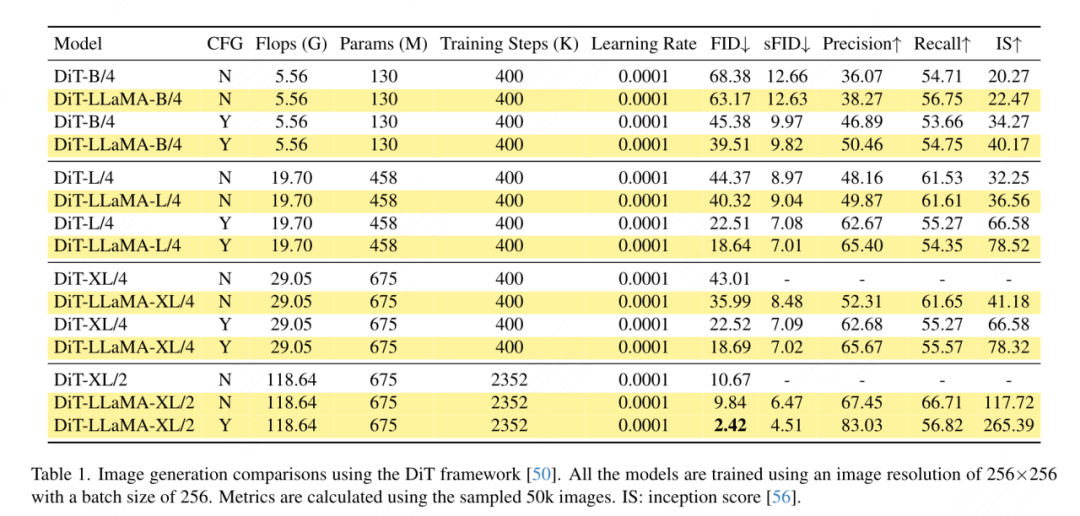
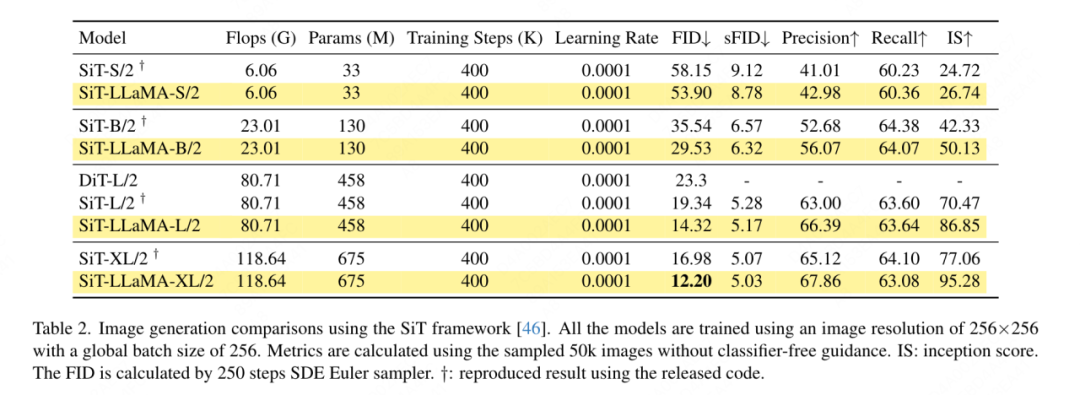
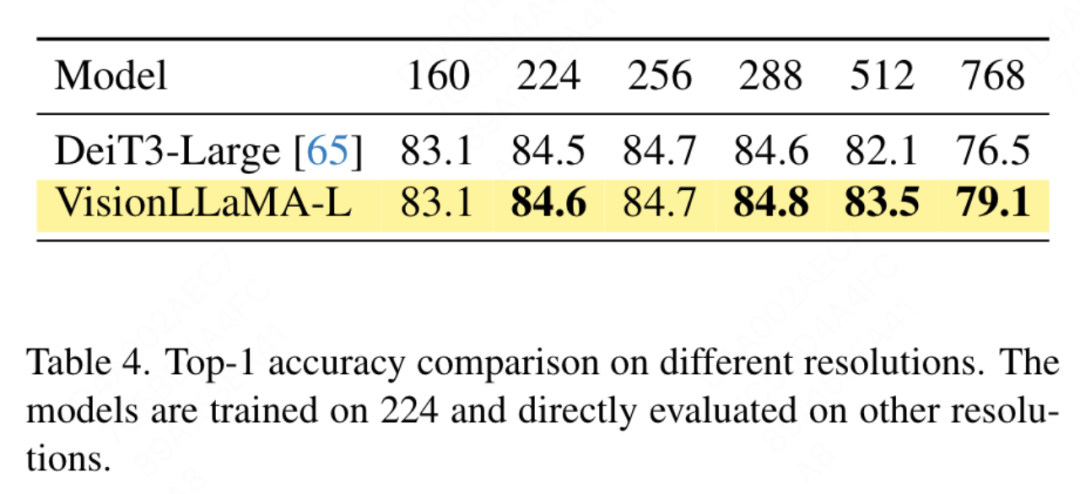
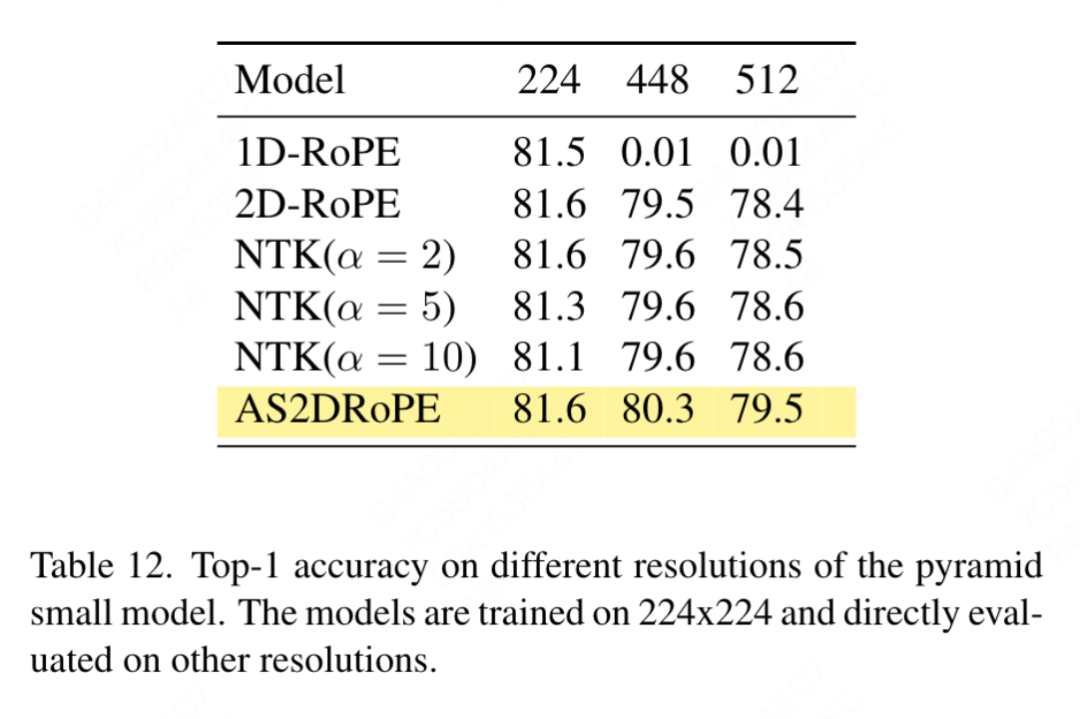
Matlamat artikel ini bukan untuk mencipta transformer penglihatan berstruktur piramid baharu, tetapi bagaimana untuk menyesuaikan reka bentuk asas VisionLLaMA berdasarkan reka bentuk sedia ada Oleh itu, artikel ini mengikut prinsip pengubahsuaian minimum kepada seni bina dan hiperparameter. Mengikut kaedah penamaan ViT, dua blok berturut-turut boleh ditulis sebagai: di mana LSA ialah operasi perhatian kendiri tempatan dalam kumpulan, dan GSA dilakukan dengan berinteraksi dengan nilai utama yang mewakili dalam setiap sub-tingkap Pensubsampelan global perhatian. Artikel ini mengalih keluar pengekodan kedudukan bersyarat dalam struktur piramid VisionLLaMA kerana maklumat kedudukan sudah disertakan dalam AS2DRoPE. Selain itu, token kategori dialih keluar dan GAP (pengumpulan purata global) digunakan sebelum kepala pengelasan Struktur blok di bawah tetapan ini ditunjukkan dalam Rajah 2 (b). Latihan atau inferens melebihi had panjang jujukan Interpolasi kedudukan membantu RoPE 2D untuk digeneralisasikan dengan lebih baik: Diilhamkan oleh beberapa kerja menggunakan interpolasi untuk melanjutkan tetingkap konteks LLaMA, dengan penyertaan resolusi yang lebih tinggi, VisionLLaMA menggunakan pendekatan yang sama untuk melanjutkan tetingkap konteks 2D . Tidak seperti tugas bahasa dengan panjang konteks tetap yang diperbesarkan, tugas visual seperti pengesanan objek sering mengendalikan resolusi pensampelan yang berbeza dalam lelaran yang berbeza. Artikel ini menggunakan resolusi input 224×224 untuk melatih model kecil dan menilai prestasi resolusi yang lebih besar tanpa melatih semula, membimbing artikel ini untuk menggunakan strategi interpolasi atau heterodina dengan lebih baik. Selepas percubaan, artikel ini memilih untuk menggunakan interpolasi penskalaan automatik (AS2DRoPE) berdasarkan "resolusi utama". Kaedah pengiraan untuk memproses imej segi empat sama H × H dan resolusi titik anchor B × B adalah seperti berikut: Disebabkan keperluan untuk menambah maklumat lokasi pada nilai utama yang diringkaskan, artikel ini melaksanakan pemprosesan khas untuk GSA di bawah tetapan struktur piramid. Kekunci subsampel ini dijana melalui pengabstrakan pada peta ciri. Kertas ini menggunakan lilitan dengan saiz kernel k×k dan langkah k. Seperti yang ditunjukkan dalam Rajah 3, koordinat nilai kunci yang dijana boleh dinyatakan sebagai purata ciri sampel. Kertas ini menilai secara menyeluruh keberkesanan VisionLLaMA terhadap tugas seperti penjanaan imej, pengelasan, segmentasi dan pengesanan. Secara lalai, semua model dalam artikel ini dilatih pada 8 GPU NVIDIA Tesla A100. Penjanaan imej Penjanaan imej berdasarkan rangka kerja DiT: Artikel ini memilih untuk menggunakan VisionLLaMA di bawah rangka kerja DiT kerana DiT ialah kerja perwakilan pada penjanaan imej menggunakan Transformer visual dan DD. Artikel ini menggantikan pengubah penglihatan asal DiT dengan VisionLLaMA, sambil mengekalkan komponen dan hiperparameter lain tidak berubah. Percubaan ini menunjukkan kepelbagaian VisionLLaMA pada tugas penjanaan imej. Sama seperti DiT, artikel ini menetapkan langkah sampel DDPM kepada 250, dan keputusan eksperimen ditunjukkan dalam Jadual 1. Selaras dengan kebanyakan metodologi, FID dianggap sebagai metrik utama dan dinilai pada metrik sekunder lain seperti sFID, Precision/Recall, Inception Score. Keputusan menunjukkan bahawa VisionLLaMA dengan ketara mengatasi prestasi DiT dalam pelbagai saiz model. Artikel ini juga memanjangkan bilangan langkah latihan model XL kepada 2352k untuk menilai sama ada model kami mempunyai kelebihan penumpuan yang lebih pantas atau masih berprestasi lebih baik di bawah tetapan tempoh latihan yang lebih lama. FID DiT-LLaMA-XL/2 adalah 0.83 lebih rendah daripada DiT-XL/2, menunjukkan bahawa VisionLLaMA bukan sahaja mempunyai kecekapan pengiraan yang lebih baik tetapi juga mempunyai prestasi yang lebih tinggi daripada DiT. Beberapa contoh yang dijana menggunakan model XL ditunjukkan dalam Rajah 1. Penjanaan imej berdasarkan rangka kerja SiT: Rangka kerja SiT meningkatkan prestasi penjanaan imej menggunakan pengubah visual dengan ketara. Artikel ini menggantikan pengubah penglihatan dalam SiT dengan VisionLLaMA untuk menilai faedah seni bina model yang lebih baik, yang artikel ini memanggil SiT-LLaMA. Eksperimen mengekalkan semua tetapan dan hiperparameter yang tinggal dalam SiT, semua model telah dilatih menggunakan bilangan langkah yang sama, dan model interpolan dan halaju linear digunakan dalam semua eksperimen. Untuk perbandingan yang adil, kami juga menjalankan semula kod yang diterbitkan dan mengambil sampel 50k 256×256 imej menggunakan pensampel SDE (Euler) dengan 250 langkah, dan hasilnya ditunjukkan dalam Jadual 2. SiT-LLaMA mengatasi prestasi SiT dalam model pada pelbagai tahap kapasiti. Berbanding dengan SiT-L/2, SiT-LLaMA-L/2 menurunkan 5.0 FID, yang lebih besar daripada peningkatan yang dibawa oleh rangka kerja baharu (4.0 FID). Kertas ini juga menunjukkan pensampel ODE (dopri5) yang lebih cekap dalam Jadual 13, dan jurang prestasi dengan kaedah kami masih wujud. Kesimpulan yang sama boleh dibuat seperti dalam kertas SiT: SDE mempunyai prestasi yang lebih baik daripada rakan ODE mereka. . tidak termasuk set data lain Atau pengaruh kemahiran penyulingan, semua model telah dilatih menggunakan set latihan ImageNet-1K, dan keputusan ketepatan pada set pengesahan ditunjukkan dalam Jadual 3. Perbandingan pengubah penglihatan konvensional: DeiT3 ialah pengubah penglihatan konvensional tercanggih semasa yang mencadangkan penambahan data khas dan melakukan carian hiperparameter yang meluas untuk meningkatkan prestasi. DeiT3 sensitif kepada hiperparameter dan terdedah kepada overfitting Menggantikan token kategori dengan GAP (pengumpulan purata global) akan menyebabkan ketepatan model DeiT3-Large menurun sebanyak 0.7% selepas 800 zaman latihan. Oleh itu, artikel ini menggunakan token kategori dan bukannya GAP dalam transformer biasa. Keputusan ditunjukkan dalam Jadual 3, di mana VisionLLaMA mencapai ketepatan 1 teratas setanding dengan DeiT3. Ketepatan pada resolusi tunggal tidak memberikan perbandingan yang komprehensif Kertas ini juga menilai prestasi pada resolusi imej yang berbeza, dan hasilnya ditunjukkan dalam Jadual 4. Untuk DeiT3, kami menggunakan interpolasi bikubik untuk pengekodan kedudukan yang boleh dipelajari. Walaupun kedua-dua model mempunyai prestasi yang setanding pada resolusi 224 × 224, jurang melebar apabila resolusi meningkat, yang bermaksud bahawa kaedah kami mempunyai keupayaan generalisasi yang lebih baik pada resolusi berbeza, yang baik untuk pengesanan sasaran dan banyak tugas hiliran lain. Perbandingan pengubah visual bagi struktur piramid: Artikel ini menggunakan seni bina yang sama seperti Twins-SVT, dan konfigurasi terperinci disenaraikan dalam Jadual 17. Artikel ini mengalih keluar pengekodan kedudukan bersyarat kerana VisionLLaMA sudah mengandungi pengekodan kedudukan putaran. Oleh itu, VisionLLaMA ialah seni bina bebas konvolusi. Artikel ini mengikut semua tetapan termasuk hiperparameter dalam Twins-SVT, yang konsisten dengan Twins-SVT Artikel ini tidak menggunakan token kategori, tetapi menggunakan GAP. Keputusan ditunjukkan dalam Jadual 3. Kaedah kami mencapai prestasi yang setanding dengan Twins pada semua peringkat model dan sentiasa lebih baik daripada Swin. . penyulingan, dsb. Komponen yang boleh meningkatkan prestasi, pelaksanaan artikel ini adalah berdasarkan rangka kerja MMPretrain, menggunakan rangka kerja MAE dan menggunakan VisionLLaMA untuk menggantikan pengekod, sambil mengekalkan komponen lain tidak berubah. Eksperimen kawalan ini boleh menilai keberkesanan kaedah ini. Tambahan pula, kami menggunakan tetapan hiperparameter yang sama seperti kaedah yang dibandingkan, di mana kami masih mencapai peningkatan prestasi yang ketara berbanding garis dasar yang berkuasa. . Pelaksanaan artikel ini adalah berdasarkan MMSegmentasi, dan hasilnya ditunjukkan dalam Jadual 7. Untuk set pra-latihan 800 zaman, VisionLLaMA-B telah meningkatkan ViT-Base dengan ketara sebanyak 2.8% mIoU. Kaedah kami juga jauh lebih baik daripada penambahbaikan lain, seperti memperkenalkan objektif atau ciri latihan tambahan, yang akan membawa overhed tambahan kepada proses latihan dan mengurangkan kelajuan latihan. Sebaliknya, VisionLLaMA hanya melibatkan penggantian model asas dan mempunyai kelajuan latihan yang pantas. Kertas kerja ini menilai lagi prestasi 1600 zaman pra-latihan yang lebih lama, dan VisionLLaMA-B mencapai 50.2% mIoU pada set pengesahan ADE20K, yang meningkatkan prestasi ViT-B sebanyak 2.1% mIoU. Pengesanan objek pada dataset COCO tugas pengesanan objek pada set data COCO . Kertas kerja ini menggunakan rangka kerja Mask RCNN dan menggantikan rangkaian tulang belakang dengan VisionLLaMA berstruktur piramid yang dipralatih pada dataset ImageNet-1K selama 300 zaman, serupa dengan persediaan Swin. Oleh itu, model kami mempunyai bilangan parameter dan FLOP yang sama seperti Twins. Percubaan ini boleh digunakan untuk mengesahkan keberkesanan kaedah ini pada tugas pengesanan sasaran. Pelaksanaan artikel ini adalah berdasarkan rangka kerja MMDetection Jadual 8 menunjukkan keputusan kitaran latihan 36 zaman standard (3×). Khususnya, VisionLLaMA-B mengatasi Swin-S dengan 1.5% peta kotak dan 1.0% peta topeng. Berbanding dengan garis dasar Twins-B yang lebih kuat, kaedah kami mempunyai kelebihan 1.1% lebih tinggi kotak mAP dan 0.8% lebih tinggi topeng mAP. . Kertas ini menggunakan pengesan Mask RCNN dan menggantikan rangkaian tulang belakang vit-Base dengan model VisionLLaMA-Base, yang dipralatih dengan MAE selama 800 zaman. ViTDet asal menumpu secara perlahan dan memerlukan strategi latihan khusus, seperti tempoh latihan yang lebih lama, untuk mencapai prestasi optimum. Semasa proses latihan, kertas kerja ini mendapati bahawa VisionLLaMA mencapai prestasi yang sama selepas 30 zaman Oleh itu, kertas kerja ini secara langsung menggunakan strategi latihan 3x standard. Kos latihan kaedah kami hanya 36% daripada garis dasar. Tidak seperti kaedah yang dibandingkan, kaedah kami tidak melakukan carian hiperparameter optimum. Keputusan ditunjukkan dalam Jadual 9. VisionLLaMA mengatasi ViT-B sebanyak 0.6% pada peta kotak dan 0.8% pada peta topeng. . berjalan Varians adalah kecil. Pengekodan kedudukan separa: Kertas ini menggunakan RoPE untuk melaraskan nisbah semua saluran Keputusan ditunjukkan dalam Jadual 11b Keputusan menunjukkan bahawa menetapkan nisbah pada ambang yang kecil boleh mencapai prestasi yang baik, dan tiada perbezaan yang ketara diperhatikan antara yang berbeza tetapan prestasi. Oleh itu, artikel ini mengekalkan tetapan lalai dalam LLaMA. Kekerapan asas: Kertas ini menukar dan membandingkan kekerapan asas, dan keputusan ditunjukkan dalam Jadual 11c Keputusan menunjukkan bahawa prestasi adalah teguh kepada julat frekuensi yang luas. Oleh itu, artikel ini mengekalkan nilai lalai dalam LLaMA untuk mengelakkan pengendalian khas tambahan pada masa penggunaan. Pengekodan kedudukan dikongsi antara setiap kepala perhatian: Kertas kerja ini mendapati bahawa berkongsi PE yang sama antara kepala yang berbeza (frekuensi dalam setiap kepala berbeza dari 1 hingga 10000) adalah lebih baik daripada PE bebas (kekerapan dalam semua saluran berbeza dari 1 hingga 10000 perubahan ), keputusan ditunjukkan dalam Jadual 11d. Strategi abstraksi ciri: Kertas kerja ini membandingkan dua strategi pengekstrakan ciri biasa pada model skala parameter besar (-L): token kategori dan GAP Hasilnya ditunjukkan dalam Jadual 11e, yang lebih baik daripada GAP adalah berbeza daripada kesimpulan yang diperolehi dalam PEG [13]. Walau bagaimanapun, tetapan latihan untuk kedua-dua kaedah agak berbeza. Kertas kerja ini juga menjalankan eksperimen tambahan menggunakan DeiT3-L dan mencapai kesimpulan yang sama. Artikel ini menilai lagi prestasi model "kecil" (-S) dan "asas" (-B). Menariknya, kesimpulan yang bertentangan diperhatikan dalam model kecil, dan terdapat sebab untuk mengesyaki bahawa kadar laluan jatuh yang lebih tinggi yang digunakan dalam DeiT3 menjadikan kaedah abstraksi bebas parameter seperti GAP sukar dicapai. Strategi pengekodan kedudukan: Kertas kerja ini juga menilai strategi pengekodan kedudukan mutlak lain, seperti pengekodan kedudukan yang boleh dipelajari dan PEG, pada struktur piramid VisionLLaMA-S. Disebabkan kewujudan garis dasar yang kukuh, kertas ini menggunakan model "kecil", dan hasilnya ditunjukkan dalam Jadual 11f: PE yang boleh dipelajari tidak meningkatkan prestasi, PEG meningkatkan sedikit garis dasar daripada 81.6% kepada 81.8%. Artikel ini tidak memasukkan PEG sebagai komponen penting kerana tiga sebab. Pertama, kertas kerja ini cuba membuat pengubahsuaian minimum kepada LLaMA. Kedua, matlamat kertas ini adalah untuk mencadangkan pendekatan umum untuk pelbagai tugas seperti ViT. Untuk rangka kerja imej bertopeng seperti MAE, PEG meningkatkan kos latihan dan mungkin menjejaskan prestasi pada tugas hiliran. Pada dasarnya, PEG jarang boleh digunakan di bawah rangka kerja MAE, tetapi pengendali yang tidak mesra penempatan akan diperkenalkan. Sama ada lilitan jarang mengandungi maklumat kedudukan sebanyak versi padatnya masih menjadi persoalan terbuka. Ketiga, reka bentuk bebas modaliti membuka jalan untuk penyelidikan lanjut meliputi modaliti lain di luar teks dan visual. Sensitiviti kepada saiz input: Tanpa latihan, artikel ini membandingkan lagi prestasi resolusi yang dipertingkatkan dan resolusi biasa, dan hasilnya ditunjukkan dalam Jadual 12. Pengubah struktur piramid digunakan di sini kerana ia lebih popular untuk tugas hiliran daripada versi bukan hierarki yang sepadan. Tidak menghairankan bahawa prestasi 1D-RoPE terjejas teruk oleh perubahan resolusi. Interpolasi NTK-Aware dengan α = 2 mencapai prestasi yang serupa dengan 2D-RoPE, yang sebenarnya ialah NTKAware (α = 1). AS2DRoPE menunjukkan prestasi terbaik pada resolusi yang lebih besar. . Memandangkan SDE jauh lebih perlahan daripada ODE, kami memilih untuk menggunakan pensampel ODE dalam artikel ini. Keputusan dalam Jadual 10 menunjukkan bahawa VisionLLaMA menumpu lebih cepat daripada ViT pada semua model. SiT-LLaMA dengan 300,000 lelaran latihan malah mengatasi model garis dasar dengan 400,000 lelaran latihan.
VisionLLaMA reka bentuk seni bina keseluruhan

 untuk digunakan pada transformer berasaskan tingkap seperti Swin, jadi artikel ini memilih untuk meneroka cara membina pengubah struktur piramid yang berkuasa pada Twins garis dasar yang lebih kukuh. Seni bina asal Twins memanfaatkan pengekodan kedudukan bersyarat, pertukaran maklumat tempatan-global berjalin dalam bentuk perhatian tempatan-global. Komponen ini adalah biasa merentasi transformer, yang bermaksud tidak sukar untuk menggunakan VisionLLaMA pada pelbagai variasi transformer.
untuk digunakan pada transformer berasaskan tingkap seperti Swin, jadi artikel ini memilih untuk meneroka cara membina pengubah struktur piramid yang berkuasa pada Twins garis dasar yang lebih kukuh. Seni bina asal Twins memanfaatkan pengekodan kedudukan bersyarat, pertukaran maklumat tempatan-global berjalin dalam bentuk perhatian tempatan-global. Komponen ini adalah biasa merentasi transformer, yang bermaksud tidak sukar untuk menggunakan VisionLLaMA pada pelbagai variasi transformer.
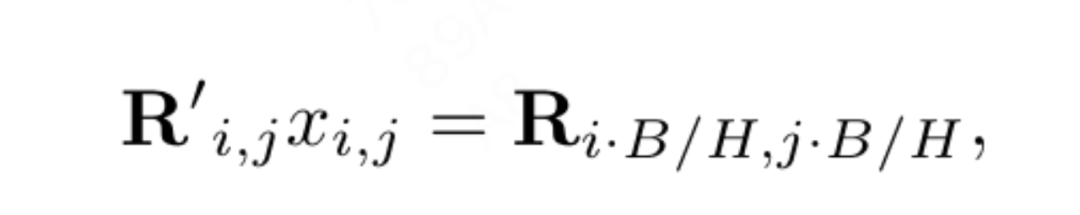 Melanjutkan RoPE satu dimensi kepada dua dimensi: Memproses resolusi input yang berbeza adalah keperluan biasa dalam tugas penglihatan. Rangkaian saraf konvolusi menggunakan mekanisme tetingkap gelongsor untuk mengendalikan panjang berubah-ubah. Sebaliknya, kebanyakan transformer visual menggunakan operasi tetingkap tempatan atau interpolasi, mis. Kertas kerja ini menilai prestasi RoPE 1D dan mendapati bahawa ia mempunyai ketepatan tertinggi pada resolusi 224×224 Namun, apabila resolusi meningkat kepada 448×448, ketepatan menurun dengan mendadak malah mencapai 0. Oleh itu, kertas ini memanjangkan RoPE satu dimensi kepada dua dimensi. Untuk mekanisme perhatian diri berbilang kepala, RoPE 2D dikongsi antara kepala yang berbeza.
Melanjutkan RoPE satu dimensi kepada dua dimensi: Memproses resolusi input yang berbeza adalah keperluan biasa dalam tugas penglihatan. Rangkaian saraf konvolusi menggunakan mekanisme tetingkap gelongsor untuk mengendalikan panjang berubah-ubah. Sebaliknya, kebanyakan transformer visual menggunakan operasi tetingkap tempatan atau interpolasi, mis. Kertas kerja ini menilai prestasi RoPE 1D dan mendapati bahawa ia mempunyai ketepatan tertinggi pada resolusi 224×224 Namun, apabila resolusi meningkat kepada 448×448, ketepatan menurun dengan mendadak malah mencapai 0. Oleh itu, kertas ini memanjangkan RoPE satu dimensi kepada dua dimensi. Untuk mekanisme perhatian diri berbilang kepala, RoPE 2D dikongsi antara kepala yang berbeza. 
Hasil eksperimen
Penyiasatan linear: Kerja terbaru menganggap metrik probing linear sebagai penilaian pembelajaran perwakilan yang lebih dipercayai. Dalam persediaan semasa, model dimulakan dengan pemberat pralatihan daripada peringkat SSL. Kemudian, semasa latihan, keseluruhan rangkaian tulang belakang dibekukan kecuali kepala pengelas. Keputusan ditunjukkan dalam Jadual 5: pada kos latihan 800 zaman, VisionLLaMA-Base mengatasi ViTBase-MAE sebanyak 4.6%. Ia juga mengatasi prestasi ViT-Base-MAE yang dilatih selama 1600 zaman. Apabila VisionLLaMA dilatih selama 1600 zaman, VisionLLaMA-Base mencapai ketepatan top1 sebanyak 71.7%. Kaedah ini juga diperluaskan kepada VisionLLaMA-Large, yang bertambah baik sebanyak 3.6% berbanding ViT-Large. Segmentasi Semantik pada Dataset ADE20K Latihan yang diawasi oleh Pengawasan ke tetapan Swin, artikel ini menggunakan segmentasi semantik pada dataset ADE20K untuk menilai kaedah ini keberkesanan. Untuk perbandingan yang saksama, kertas kerja ini mengehadkan model garis dasar untuk hanya menggunakan ImageNet-1K untuk pra-latihan. Artikel ini menggunakan rangka kerja UpperNet dan menggantikan rangkaian tulang belakang dengan struktur piramid VisionLLaMA. Pelaksanaan artikel ini adalah berdasarkan rangka kerja MMSegmentation. Bilangan langkah latihan model ditetapkan kepada 160k, dan saiz kelompok global ialah 16. Keputusan ditunjukkan dalam Jadual 6. Pada FLOP yang serupa, kaedah kami mengatasi Swin dan Twins dengan lebih daripada 1.2% mIoU. 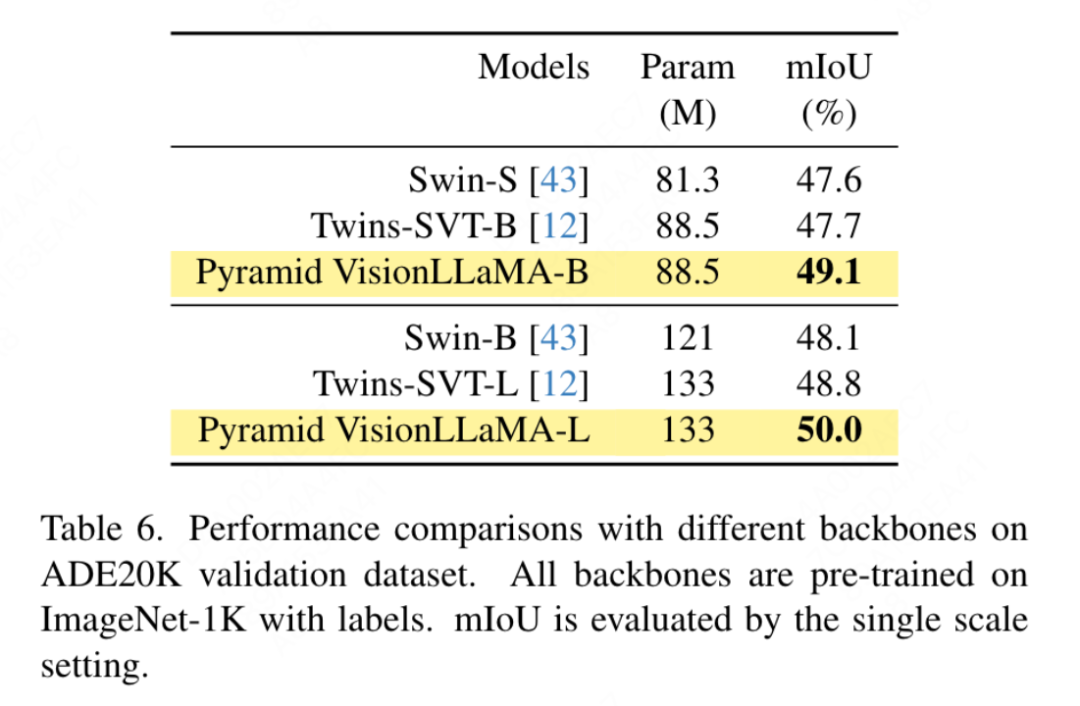
Ablasi FFN dan SwiGLU: Kertas ini menggantikan FFN dengan SwiGLU, dan hasilnya ditunjukkan dalam Jadual 11a. Disebabkan oleh jurang prestasi yang jelas, makalah ini memilih untuk menggunakan SwiGLU untuk mengelak daripada memperkenalkan pengubahsuaian tambahan kepada seni bina LLaMA.
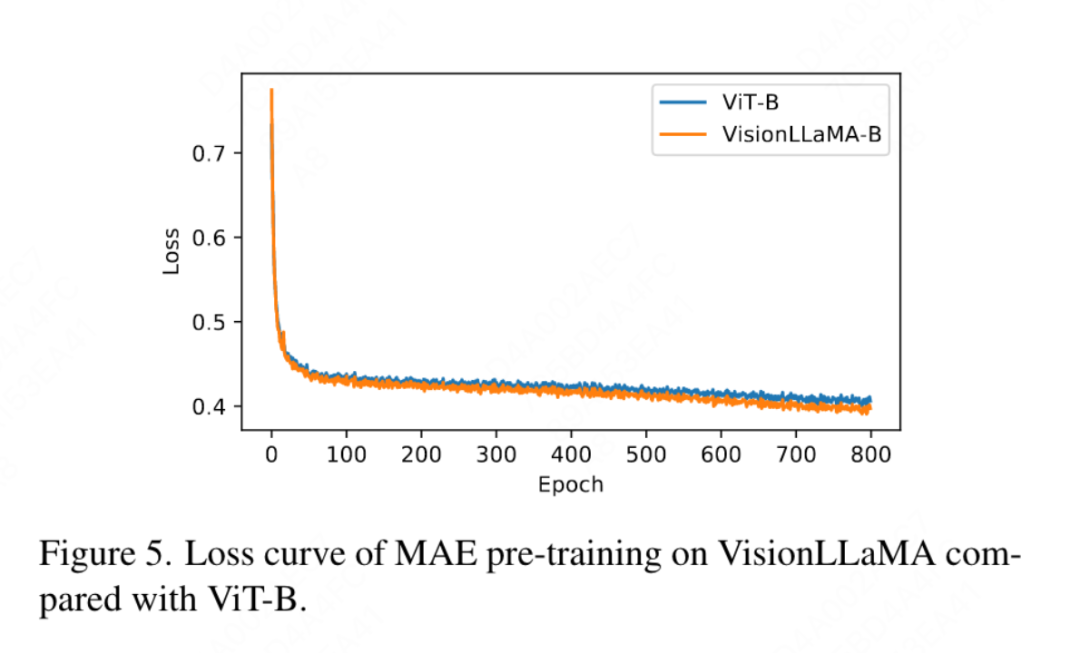
Kertas kerja ini juga membandingkan dengan ketepatan teratas 800 zaman latihan diselia sepenuhnya pada ImageNet menggunakan DeiT3-Large dalam Rajah 4, menunjukkan bahawa VisionLLaMA menumpu lebih cepat daripada DeiT3-L. Kertas kerja ini membandingkan lagi kehilangan latihan selama 800 zaman model ViT-Base di bawah rangka kerja MAE, dan digambarkan dalam Rajah 5. VisionLLaMA mempunyai kehilangan latihan yang lebih rendah pada permulaan dan mengekalkan trend ini sehingga akhir.
Atas ialah kandungan terperinci Melebihi ViT, Meituan, Universiti Zhejiang, dsb. VisionLLAMA yang dicadangkan secara menyeluruh, seni bina bersatu untuk tugas visual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- java软件系统功能设计实战训练视频教程
- python ipo模型是指什么
- Pada lapisan model osi manakah fungsi pemilihan laluan selesai?
- Melatih BERT dan ResNet pada telefon pintar buat kali pertama, mengurangkan penggunaan tenaga sebanyak 35%
- Pengaturcara berada dalam bahaya! Dikatakan bahawa OpenAI merekrut tentera penyumberan luar secara global dan melatih petani kod ChatGPT langkah demi langkah