
Rumah >Peranti teknologi >AI >Google mengeluarkan AI 'bacaan skrin' terkini! PaLM 2-S menjana data secara automatik, dan pelbagai tugas pemahaman menyegarkan SOTA
Google mengeluarkan AI 'bacaan skrin' terkini! PaLM 2-S menjana data secara automatik, dan pelbagai tugas pemahaman menyegarkan SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-06 18:30:03911semak imbas
Model besar yang diingini semua orang ialah jenis yang benar-benar pintar...
Tidak, pasukan Google telah mencipta AI "bacaan skrin" yang berkuasa.
Para penyelidik memanggilnya ScreenAI, model bahasa visual baharu untuk memahami antara muka pengguna dan maklumat grafik.

Alamat kertas: https://arxiv.org/pdf/2402.04615.pdf Teras ScreenAI ialah kaedah perwakilan teks tangkapan skrin baharu yang boleh mengenal pasti jenis dan kedudukan elemen UI.
Para penyelidik menggunakan model bahasa Google PaLM 2-S untuk menjana data latihan sintetik, yang digunakan untuk melatih model menjawab soalan yang berkaitan dengan maklumat skrin, navigasi skrin dan ringkasan kandungan skrin. Perlu dinyatakan bahawa kaedah ini memberikan idea baharu untuk meningkatkan prestasi model apabila mengendalikan tugas berkaitan skrin.
Sebagai contoh, jika anda membuka halaman APP muzik, anda boleh bertanya "Berapa banyak lagu yang panjangnya kurang daripada 30 saat"? 
ScreenAI memberikan jawapan mudah: 1.
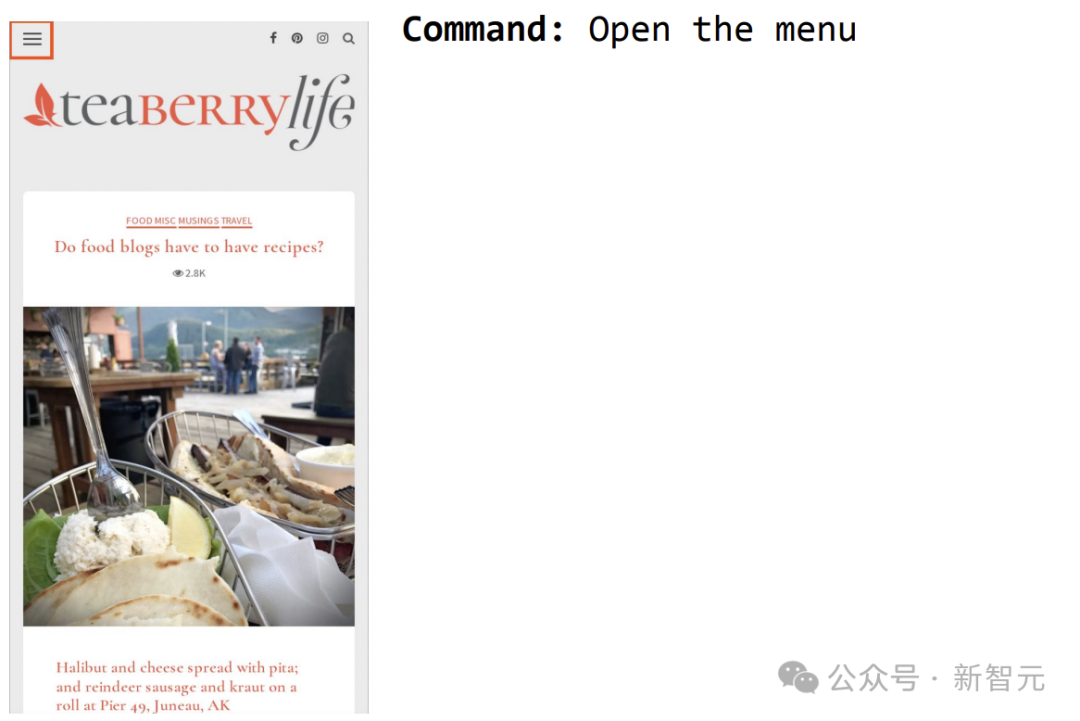
Contoh lain ialah mengarahkan ScreenAI untuk membuka menu dan anda boleh memilihnya. 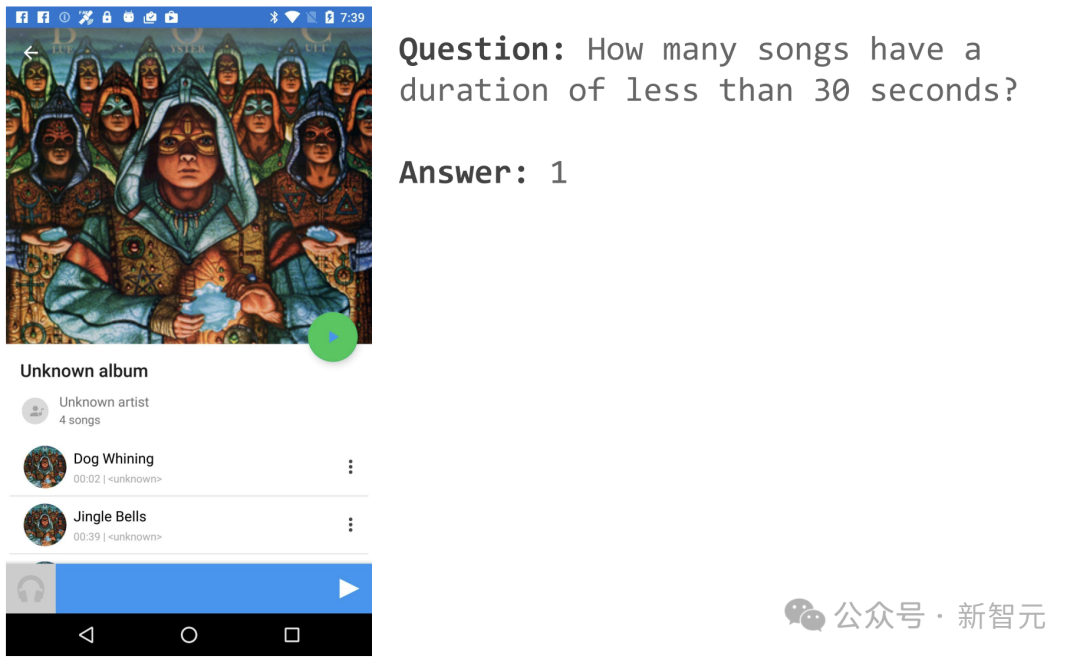
 Sumber inspirasi seni bina - PaLI
Sumber inspirasi seni bina - PaLI
Rajah 1 menunjukkan seni bina model ScreenAI. Para penyelidik telah diilhamkan oleh seni bina keluarga model PaLI, yang terdiri daripada blok pengekod multimodal.
Blok pengekod mengandungi pengekod visual seperti ViT dan pengekod bahasa mT5 yang menggunakan input imej dan teks, diikuti dengan penyahkod autoregresif.
Imej input diubah oleh pengekod visual kepada satu siri pembenaman, yang digabungkan dengan pembenaman teks input dan dimasukkan ke dalam pengekod bahasa mT5.
Output pengekod dihantar ke penyahkod, yang menjana output teks.
Rumusan umum ini boleh menggunakan seni bina model yang sama untuk menyelesaikan pelbagai tugas visual dan pelbagai mod. Tugasan ini boleh dirumuskan semula sebagai masalah teks+imej (input) kepada teks (output).
Berbanding dengan input teks, benam imej membentuk sebahagian besar panjang input kepada pengekod berbilang modal.
Ringkasnya, model ini menggunakan pengekod imej dan pengekod bahasa untuk mengekstrak ciri imej dan teks, menggabungkan kedua-duanya dan kemudian memasukkannya ke dalam penyahkod untuk menghasilkan teks.
Kaedah pembinaan ini boleh digunakan secara meluas untuk tugasan pelbagai modal seperti pemahaman imej.
Di samping itu, para penyelidik melanjutkan lagi seni bina pengekod-penyahkod PaLI untuk menerima pelbagai mod penyekatan imej. 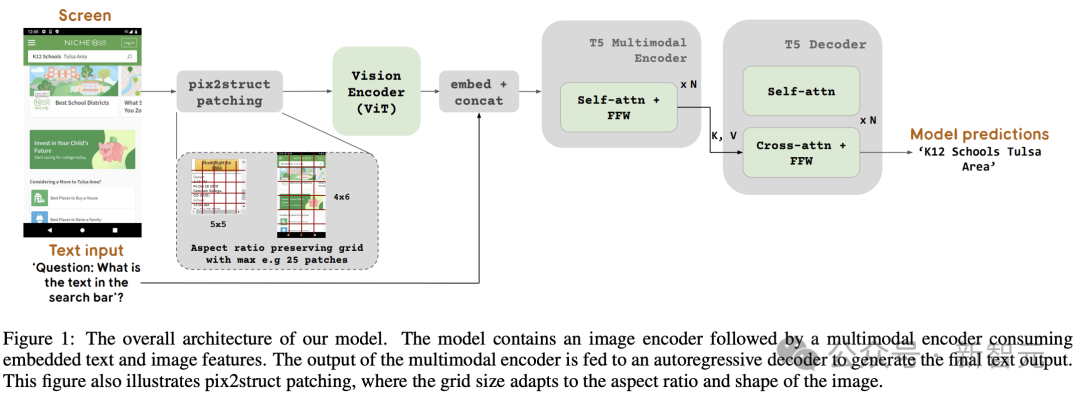
Seni bina PaLI asal hanya menerima tampalan imej dalam corak grid tetap untuk memproses imej input. Walau bagaimanapun, penyelidik dalam bidang berkaitan skrin menemui data yang merangkumi pelbagai jenis resolusi dan nisbah bidang.
Untuk membolehkan model tunggal menyesuaikan diri dengan semua bentuk skrin, perlu menggunakan strategi jubin yang berfungsi untuk imej pelbagai bentuk.
Untuk tujuan ini, pasukan Google meminjam teknologi yang diperkenalkan dalam Pix2Struct, yang membolehkan penjanaan blok imej berbentuk grid sewenang-wenangnya berdasarkan bentuk imej input dan bilangan maksimum blok yang telah ditetapkan, seperti yang ditunjukkan dalam Rajah 1.
Ini dapat menyesuaikan diri dengan memasukkan imej pelbagai format dan nisbah bidang tanpa perlu melapik atau meregangkan imej untuk membetulkan bentuknya, menjadikan model lebih serba boleh dan mampu mengendalikan kedua-dua mudah alih (iaitu potret) dan desktop (cth. landskap) format imej.
Tatarajah Model
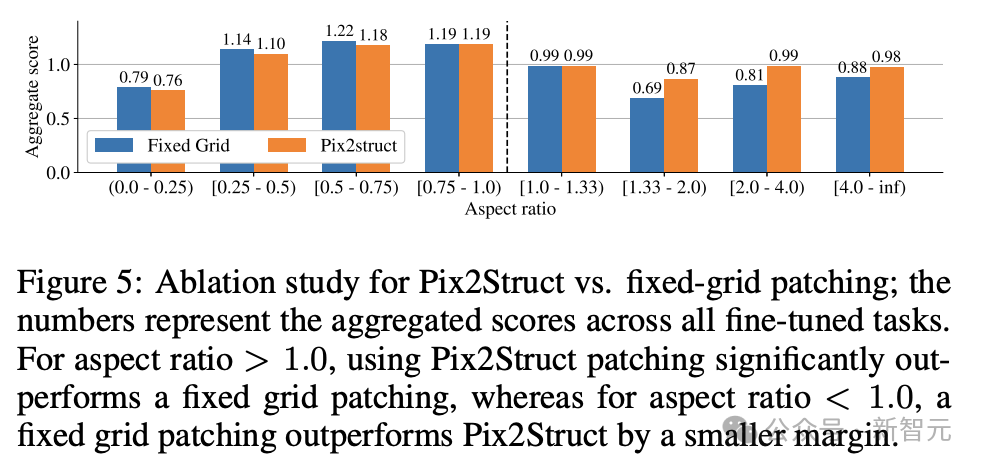
Para penyelidik melatih 3 model saiz berbeza, mengandungi parameter 670M, 2B dan 5B. Untuk model parameter 670M dan 2B, para penyelidik bermula dengan pusat pemeriksaan unimodal pra-latihan bagi model bahasa pengekod visual dan pengekod-penyahkod. Untuk model parameter 5B, mulakan dari pusat pemeriksaan pra-latihan pelbagai mod PaLI-3, di mana ViT dilatih dengan model bahasa penyahkod-pengekod berasaskan UL2. Taburan parameter antara penglihatan dan model bahasa boleh dilihat dalam Jadual 1. Penjanaan data automatik Penyelidik mengatakan bahawa fasa pra-latihan pembangunan model sebahagian besarnya bergantung pada akses kepada set data yang besar dan pelbagai. Walau bagaimanapun, pelabelan set data yang luas secara manual adalah tidak praktikal, jadi strategi pasukan Google ialah - penjanaan data automatik. Pendekatan ini memanfaatkan model kecil khusus, yang setiap satunya pandai menjana dan melabel data dengan cekap dan dengan ketepatan yang tinggi. Berbanding dengan anotasi manual, pendekatan automatik ini bukan sahaja cekap dan berskala, tetapi juga memastikan tahap kepelbagaian dan kerumitan data tertentu. Langkah pertama ialah memberikan model pemahaman yang menyeluruh tentang elemen teks, pelbagai komponen skrin dan struktur dan hierarki keseluruhannya. Pemahaman asas ini penting kepada keupayaan model untuk mentafsir dan berinteraksi dengan tepat dengan pelbagai antara muka pengguna. Di sini, penyelidik mengumpul sejumlah besar tangkapan skrin daripada pelbagai peranti termasuk desktop, peranti mudah alih dan tablet melalui aplikasi merangkak dan halaman web. Tangkapan skrin ini kemudian diberi anotasi dengan teg terperinci yang menerangkan elemen UI, hubungan ruangnya dan maklumat deskriptif lain. Di samping itu, untuk menyuntik kepelbagaian yang lebih besar ke dalam data pra-latihan, para penyelidik juga memanfaatkan kuasa model bahasa, khususnya PaLM 2-S untuk menjana pasangan QA dalam dua peringkat. Mulakan dengan menjana corak skrin yang diterangkan sebelum ini. Penulis kemudiannya mereka bentuk gesaan yang mengandungi corak skrin untuk membimbing model bahasa untuk menjana data sintetik. Selepas beberapa lelaran, petua boleh dikenal pasti yang berkesan menjana tugasan yang diperlukan, seperti yang ditunjukkan dalam Lampiran C. Untuk menilai kualiti respons yang dijana ini, penyelidik melakukan pengesahan manual pada subset data untuk memastikan keperluan kualiti yang telah ditetapkan dipenuhi. Kaedah ini diterangkan dalam Rajah 2, yang sangat meningkatkan kedalaman dan keluasan set data pra-latihan. Dengan memanfaatkan keupayaan pemprosesan bahasa semula jadi model ini, digabungkan dengan corak skrin berstruktur, pelbagai interaksi dan senario pengguna boleh disimulasikan. Seterusnya, penyelidik mentakrifkan dua set tugas yang berbeza untuk model: set awal tugasan pra-latihan dan satu set tugasan halus seterusnya. Kedua-dua kumpulan berbeza terutamanya dalam dua aspek: - Sumber data sebenar: Untuk tugas penalaan halus, label disediakan atau disahkan oleh penilai manusia. Untuk tugasan pra-latihan, label disimpulkan menggunakan kaedah pembelajaran yang diselia sendiri atau dijana menggunakan model lain. - Saiz set data: Biasanya tugas pralatihan mengandungi sejumlah besar sampel, oleh itu, tugasan ini digunakan untuk melatih model melalui siri langkah yang lebih lanjutan. Jadual 2 menunjukkan ringkasan semua tugasan pra-latihan. Dalam data bercampur, set data ditimbang secara berkadar dengan saiznya, dengan berat maksimum yang dibenarkan untuk setiap tugasan. Menggabungkan sumber berbilang modal ke dalam latihan berbilang tugas, daripada pemprosesan bahasa kepada pemahaman visual dan analisis kandungan web, membolehkan model mengendalikan senario berbeza dengan berkesan dan meningkatkan fleksibiliti dan prestasi keseluruhannya. Penyelidik menggunakan pelbagai tugas dan penanda aras untuk menganggar kualiti model semasa penalaan halus. Jadual 3 meringkaskan penanda aras ini, termasuk penanda aras skrin utama, maklumat grafik dan pemahaman dokumen sedia ada. Rajah 4 menunjukkan prestasi model ScreenAI dan membandingkannya dengan keputusan SOT terkini pada pelbagai tugasan berkaitan grafik dan skrin maklumat. Anda boleh melihat prestasi terkemuka yang dicapai oleh ScreenAI pada tugasan yang berbeza. Dalam Jadual 4, penyelidik membentangkan hasil penalaan halus tugas tunggal menggunakan data OCR. Untuk tugasan QA, menambah OCR boleh meningkatkan prestasi (cth. sehingga 4.5% pada Complex ScreenQA, MPDocVQA dan InfoVQA). Walau bagaimanapun, menggunakan OCR sedikit meningkatkan panjang input, menyebabkan latihan yang lebih perlahan secara keseluruhan. Ia juga memerlukan mendapatkan keputusan OCR pada masa inferens. Di samping itu, penyelidik menjalankan eksperimen tugasan tunggal menggunakan saiz model berikut: 670 juta parameter, 2 bilion parameter dan 5 bilion parameter. Seperti yang boleh diperhatikan dalam Rajah 4, untuk semua tugasan, peningkatan saiz model meningkatkan prestasi, dan peningkatan pada skala terbesar masih belum tepu. Untuk tugasan yang memerlukan teks visual dan penaakulan aritmetik yang lebih kompleks (seperti InfoVQA, ChartQA dan Complex ScreenQA), peningkatan antara model 2 bilion parameter dan model 5 bilion parameter adalah jauh lebih besar daripada model 670 juta parameter. dan model parameter 2 bilion. Akhirnya, Rajah 5 menunjukkan bahawa untuk imej dengan nisbah bidang >1.0 (imej mod landskap), strategi pembahagian pix2struct adalah jauh lebih baik daripada pembahagian grid tetap. Untuk imej mod potret, arah aliran adalah bertentangan, tetapi pembahagian grid tetap hanya lebih baik sedikit. Memandangkan penyelidik mahu model ScreenAI berfungsi pada imej dengan nisbah aspek yang berbeza, mereka memilih untuk menggunakan strategi pembahagian pix2struct. Penyelidik Google berkata bahawa model ScreenAI juga memerlukan lebih banyak kajian tentang beberapa tugas untuk merapatkan jurang dengan model yang lebih besar seperti GPT-4 dan Gemini. 
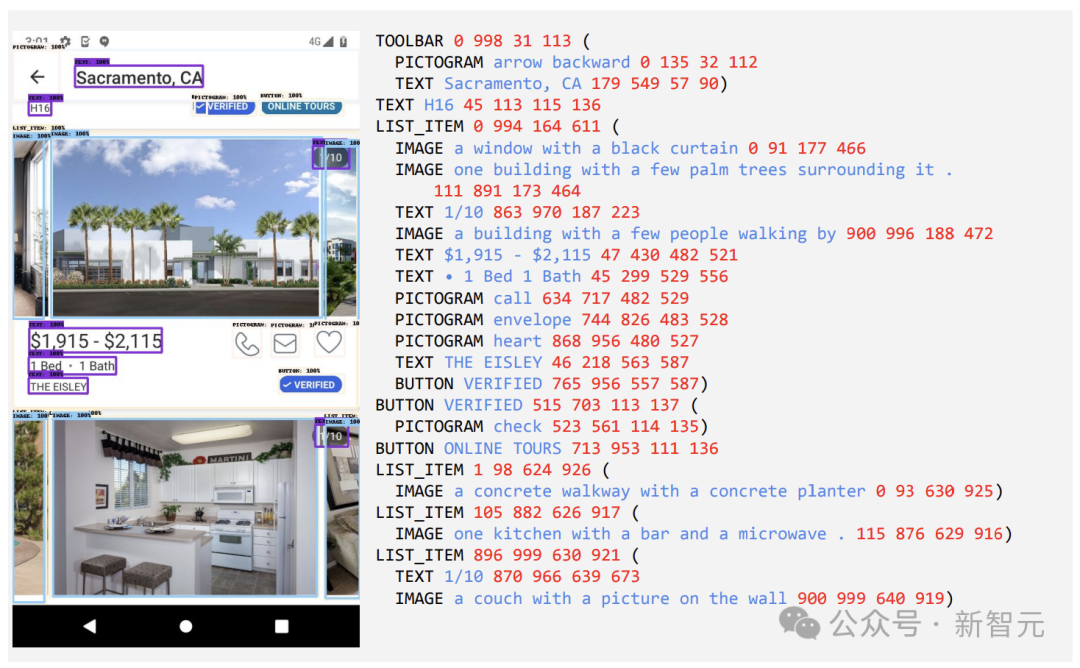
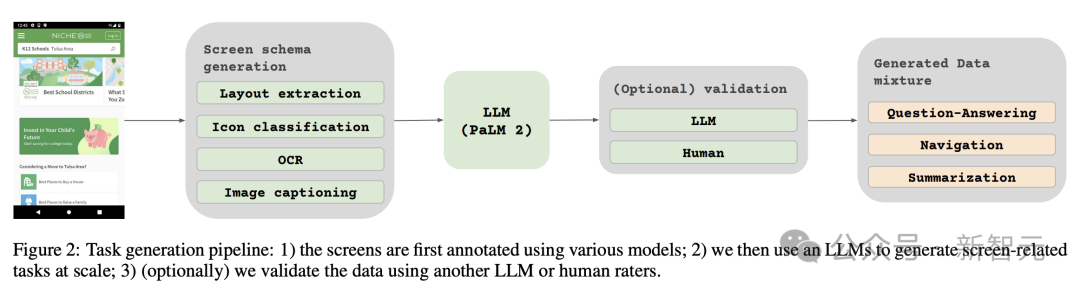
Dua set tugasan berbeza



Keputusan eksperimen
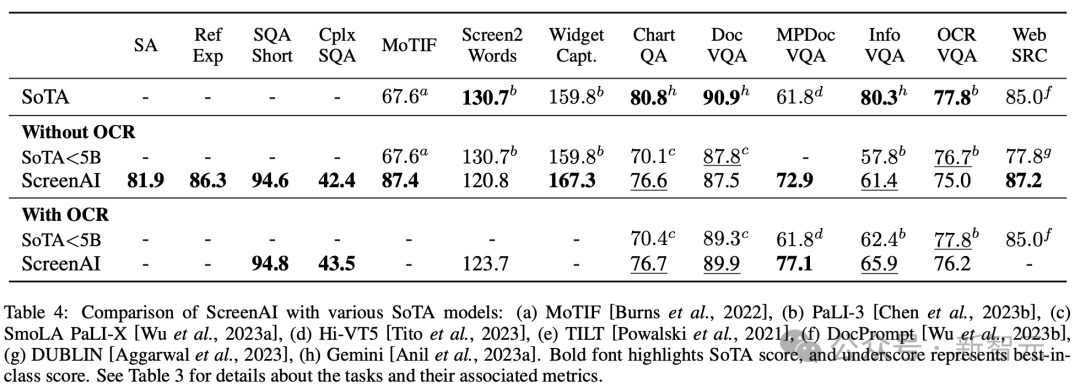
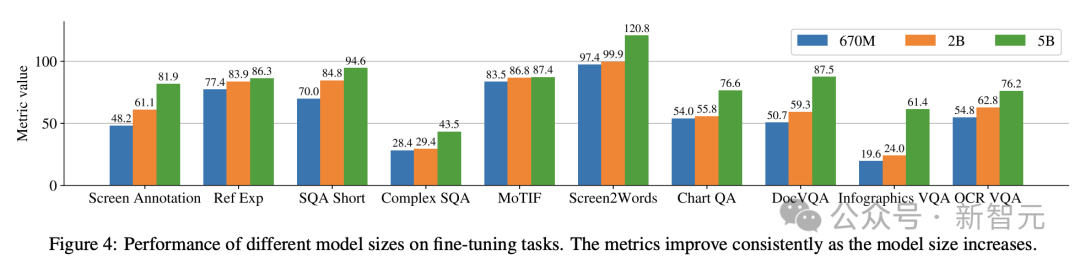
Atas ialah kandungan terperinci Google mengeluarkan AI 'bacaan skrin' terkini! PaLM 2-S menjana data secara automatik, dan pelbagai tugas pemahaman menyegarkan SOTA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!