
Rumah >Peranti teknologi >AI >ICLR 2024 |. Menyediakan perspektif baharu untuk pemisahan audio dan video, pasukan Hu Xiaolin Universiti Tsinghua melancarkan RTFS-Net
ICLR 2024 |. Menyediakan perspektif baharu untuk pemisahan audio dan video, pasukan Hu Xiaolin Universiti Tsinghua melancarkan RTFS-Net

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-06 18:28:13708semak imbas
Tujuan utama teknologi Audiovisual Speech Separation (AVSS) adalah untuk mengenal pasti dan memisahkan suara pembesar suara sasaran dalam isyarat campuran, menggunakan maklumat muka untuk mencapai matlamat ini. Teknologi ini mempunyai aplikasi yang luas dalam pelbagai bidang, termasuk pembantu pintar, persidangan jauh dan realiti tambahan. Melalui teknologi AVSS, kualiti isyarat pertuturan dalam persekitaran yang bising boleh dipertingkatkan dengan ketara, sekali gus meningkatkan kesan pengecaman pertuturan dan komunikasi. Perkembangan teknologi ini telah membawa kemudahan kepada kehidupan dan kerja harian manusia, menjadikannya lebih mudah untuk orang ramai
Kaedah pemisahan pertuturan audio-visual tradisional biasanya memerlukan model yang kompleks dan sejumlah besar sumber pengkomputeran, terutamanya apabila terdapat latar belakang yang bising atau banyak. orang bercakap Dalam kes ini, prestasinya mudah terhad. Untuk mengatasi masalah tersebut, penyelidik mula meneroka kaedah berdasarkan pembelajaran mendalam. Walau bagaimanapun, teknologi pembelajaran mendalam sedia ada menghadapi cabaran kerumitan pengiraan yang tinggi dan kesukaran untuk menyesuaikan diri dengan persekitaran yang tidak diketahui.
Secara khusus, kaedah pemisahan pertuturan audio-visual semasa mempunyai masalah berikut:
Kaedah domain masa: Ia boleh memberikan kesan pemisahan audio berkualiti tinggi, tetapi disebabkan lebih banyak parameter, kerumitan pengiraan lebih tinggi dan kelajuan pemprosesan adalah lebih perlahan.
Kaedah domain kekerapan masa: lebih cekap dari segi pengiraan, tetapi prestasi sejarahnya lemah berbanding kaedah domain masa. Mereka menghadapi tiga cabaran utama:
1 Kekurangan pemodelan bebas bagi dimensi masa dan kekerapan.
2. Isyarat visual daripada pelbagai medan penerimaan tidak digunakan sepenuhnya untuk meningkatkan prestasi model.
3 Pemprosesan ciri kompleks yang tidak betul membawa kepada kehilangan maklumat amplitud dan fasa utama.
Untuk menangani cabaran ini, penyelidik daripada pasukan Profesor Madya Hu Xiaolin dari Universiti Tsinghua mencadangkan model pemisahan pertuturan audio-visual baharu yang dipanggil RTFS-Net. Model ini menggunakan kaedah pembinaan semula mampatan, yang mengurangkan kerumitan pengiraan dan bilangan parameter model dengan ketara sambil meningkatkan prestasi pemisahan. RTFS-Net ialah kaedah pemisahan pertuturan audiovisual pertama menggunakan kurang daripada 1 juta parameter, dan ia juga merupakan kaedah pertama untuk mengatasi semua model domain masa dalam pemisahan berbilang mod domain frekuensi masa.

Alamat kertas: https://arxiv.org/abs/2309.17189
-
Laman utama kertas: https://cslikai.cn/RTFS-Net/AV-Model🜎Demo
Alamat kod: https://github.com/spkgyk/RTFS-Net (akan datang) - Pengenalan kaedah
Seni bina rangkaian keseluruhan RTFS-Net ditunjukkan dalam Rajah 1 di bawah:
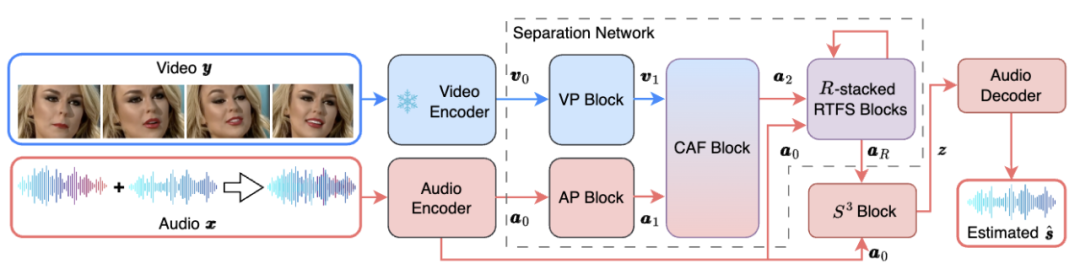
di antara mereka, blok RTFS (ditunjukkan dalam Rajah 2) memampatkan dan secara bebas model dimensi akustik (masa dan kekerapan), cuba membuat subspace kompleksitas rendah sementara cuba Mengurangkan kehilangan maklumat. Khususnya, blok RTFS menggunakan seni bina dwi-laluan untuk pemprosesan isyarat audio yang cekap dalam kedua-dua dimensi masa dan kekerapan. Dengan pendekatan ini, blok RTFS dapat mengurangkan kerumitan pengiraan sambil mengekalkan sensitiviti dan ketepatan yang tinggi kepada isyarat audio. Berikut ialah aliran kerja khusus blok RTFS:
1 Mampatan frekuensi masa: Blok RTFS terlebih dahulu memampatkan ciri audio input dalam dimensi masa dan kekerapan. 2 Pemodelan dimensi bebas: Selepas melengkapkan pemampatan, blok RTFS memodelkan dimensi masa dan kekerapan secara bebas. 3 Gabungan dimensi: Selepas memproses dimensi masa dan kekerapan secara bebas, blok RTFS menggabungkan maklumat dua dimensi melalui modul gabungan. 4 Pembinaan semula dan keluaran: Akhir sekali, ciri yang dicantumkan dibina semula ke ruang frekuensi masa asal melalui satu siri lapisan penyahkonvolusi.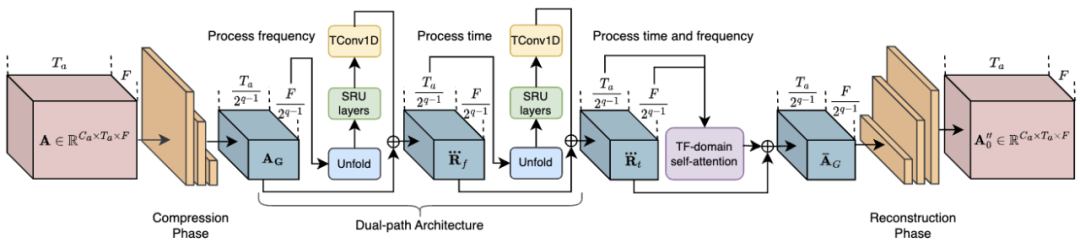
Modul gabungan perhatian silang dimensi (CAF) (ditunjukkan dalam Rajah 3) menggabungkan maklumat audio dan visual dengan berkesan, meningkatkan kesan pemisahan pertuturan dan mengurangkan kerumitan pengiraan Ia hanya 1.3% daripada kaedah SOTA sebelumnya. Khususnya, modul CAF mula-mula menjana pemberat perhatian menggunakan kedalaman dan operasi konvolusi berkumpulan. Pemberat ini melaraskan secara dinamik berdasarkan kepentingan ciri input, membolehkan model memfokus pada maklumat yang paling berkaitan. Kemudian, dengan menggunakan pemberat perhatian yang dijana pada ciri visual dan pendengaran, modul CAF dapat memfokuskan pada maklumat utama dalam pelbagai dimensi. Langkah ini melibatkan pemberat dan penggabungan ciri dimensi berbeza untuk menghasilkan perwakilan ciri yang komprehensif. Sebagai tambahan kepada mekanisme perhatian, modul CAF juga boleh menggunakan mekanisme gating untuk mengawal lagi tahap gabungan ciri daripada sumber yang berbeza. Pendekatan ini boleh meningkatkan fleksibiliti model dan membolehkan kawalan aliran maklumat yang lebih halus.
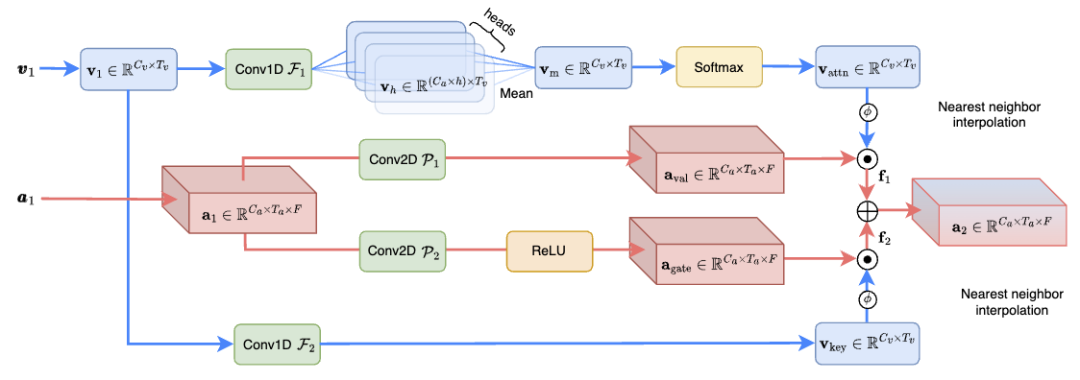
Rajah 3. Gambarajah struktur skematik modul gabungan kafe pembesar suara sasaran daripada ciri audio campuran. Kaedah ini menggunakan sepenuhnya maklumat fasa dan amplitud isyarat audio, meningkatkan ketepatan dan kecekapan pemisahan sumber. Dan menggunakan rangkaian yang kompleks membolehkan blok S^3 memproses isyarat dengan lebih tepat apabila mengasingkan pertuturan pembesar suara sasaran, terutamanya dalam memelihara butiran dan mengurangkan artifak, seperti yang ditunjukkan di bawah. Begitu juga, reka bentuk blok S^3 membolehkan penyepaduan mudah ke dalam rangka kerja pemprosesan audio yang berbeza, sesuai untuk pelbagai tugas pengasingan sumber, dan mempunyai keupayaan generalisasi yang baik.
Hasil eksperimen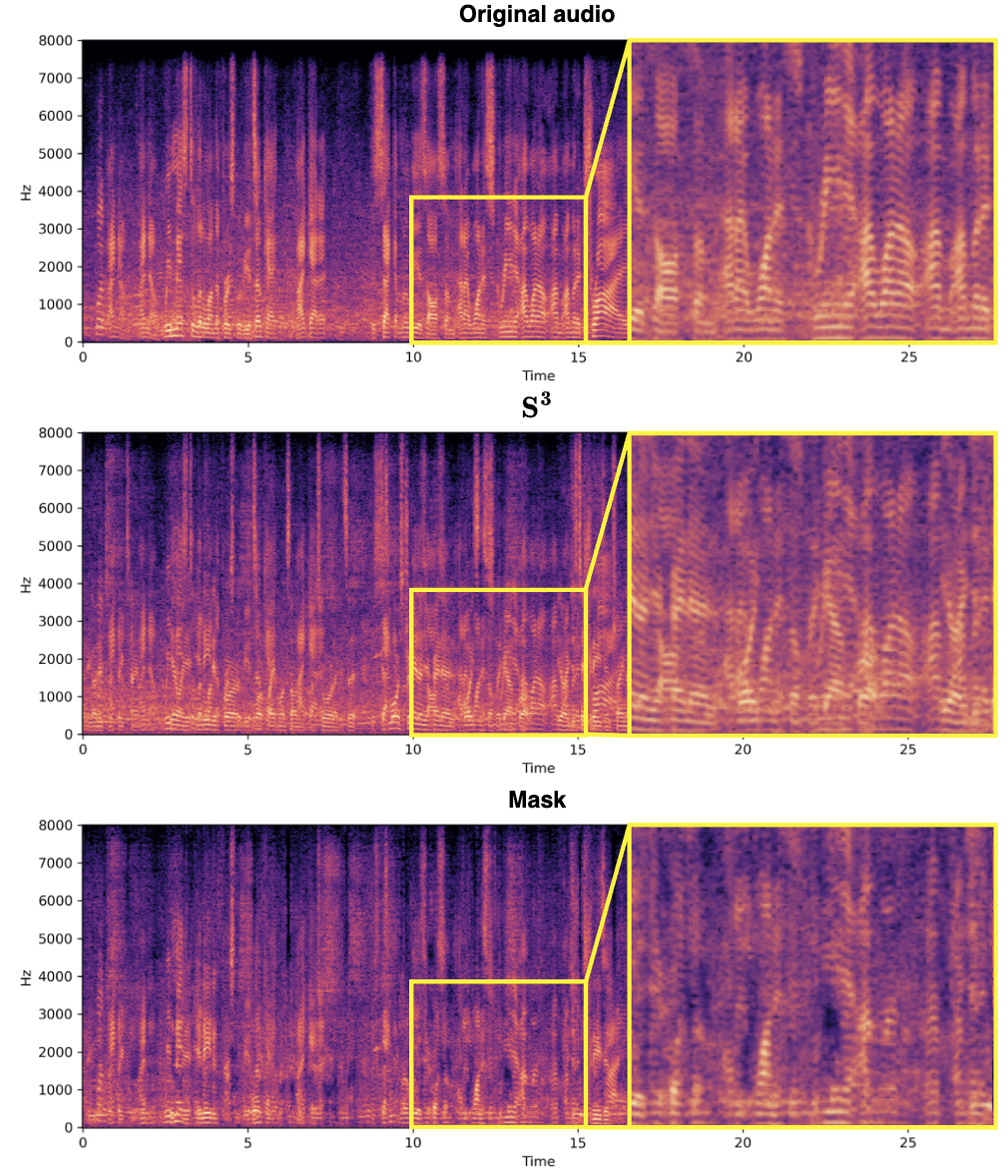
Kesan pemisahan
Pada tiga penanda aras tanda aras pemisahan pertuturan berbilang mod (LRS2, LRS3 dan Voxutational set data kompaun yang ketara) ditunjukkan di bawah parameter VoxCeleb di bawah kerumitan, menghampiri atau melebihi prestasi terkini. Pertukaran antara kecekapan dan prestasi ditunjukkan melalui varian dengan bilangan blok RTFS yang berbeza (4, 6, 12 blok), di mana RTFS-Net-6 memberikan keseimbangan prestasi dan kecekapan yang baik. RTFS-Net-12 menunjukkan prestasi terbaik pada semua set data yang diuji, membuktikan kelebihan kaedah domain kekerapan masa dalam mengendalikan tugas pemisahan penyegerakan audio dan video yang kompleks.
Kesan sebenar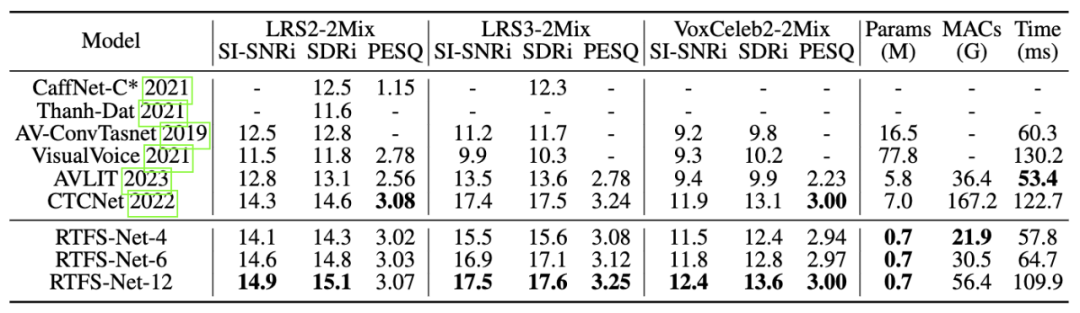
Video campuran:
Audio pembesar suara wanita: Audio pembesar suara lelaki:
Audio pembesar suara lelaki: 

ke kemajuan berterusan pembangunan teknologi model besar, audiovisual The bidang pemisahan pertuturan juga mengejar model besar untuk meningkatkan kualiti pemisahan. Walau bagaimanapun, ini tidak boleh dilaksanakan untuk peranti akhir. RTFS-Net mencapai peningkatan prestasi yang ketara sambil mengekalkan kerumitan pengiraan yang berkurangan dengan ketara dan bilangan parameter. Ini menunjukkan bahawa meningkatkan prestasi AVSS tidak semestinya memerlukan model yang lebih besar, sebaliknya seni bina yang inovatif dan cekap yang lebih menangkap interaksi rumit antara modaliti audio dan visual.
Atas ialah kandungan terperinci ICLR 2024 |. Menyediakan perspektif baharu untuk pemisahan audio dan video, pasukan Hu Xiaolin Universiti Tsinghua melancarkan RTFS-Net. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Direka khusus untuk pokok keputusan, Universiti Nasional Singapura & Universiti Tsinghua bersama-sama mencadangkan sistem pembelajaran bersekutu baharu yang pantas dan selamat
- Zhou Bowen dari Universiti Tsinghua: Populariti ChatGPT mendedahkan kepentingan tinggi kerjasama generasi baharu dan kecerdasan interaktif
- Aplikasi teknologi pengkomputeran yang dipercayai dalam bidang keselamatan industri
- Persidangan Pengkomputeran Kecerdasan Buatan 2023 AICC telah diadakan di Beijing, memfokuskan pada perbincangan hangat industri mengenai model berskala besar dan kuasa pengkomputeran pintar
- Universiti Tsinghua memenangi pertandingan aplikasi AI penghantaran kuasa kelima dengan skor sempurna dan pertandingan itu berakhir dengan jayanya!