
Rumah >Peranti teknologi >AI >10 Algoritma Kepintaran Buatan Yang Mesti Tahu
10 Algoritma Kepintaran Buatan Yang Mesti Tahu

- PHPzke hadapan
- 2024-03-06 09:37:13750semak imbas
Dengan populariti berterusan teknologi kecerdasan buatan (AI), pelbagai algoritma memainkan peranan penting dalam mempromosikan pembangunan bidang ini. Daripada algoritma regresi linear yang digunakan untuk meramalkan harga rumah kepada rangkaian saraf yang menjana kuasa kereta pandu sendiri, algoritma ini secara senyap-senyap menjana kuasa dan mengendalikan banyak aplikasi. Apabila jumlah data meningkat dan kuasa pengkomputeran bertambah baik, prestasi dan kecekapan algoritma kecerdasan buatan juga sentiasa bertambah baik. Skop aplikasi algoritma ini semakin luas dan meluas, meliputi diagnosis perubatan, penilaian risiko kewangan, pemprosesan bahasa semula jadi, dll.

Hari ini, kami akan membawa anda melihat algoritma kecerdasan buatan yang popular ini ( regresi linear, regresi logistik, Pepohon keputusan, Naive Bayes, Mesin Vektor Sokongan (SVM), pembelajaran ensemble, algoritma jiran terdekat K, algoritma K-means, rangkaian saraf, pembelajaran pengukuhan Deep Q-Networks), teroka prinsip kerja mereka, senario aplikasi dan aplikasi mereka dalam pengaruh dunia nyata dalam.
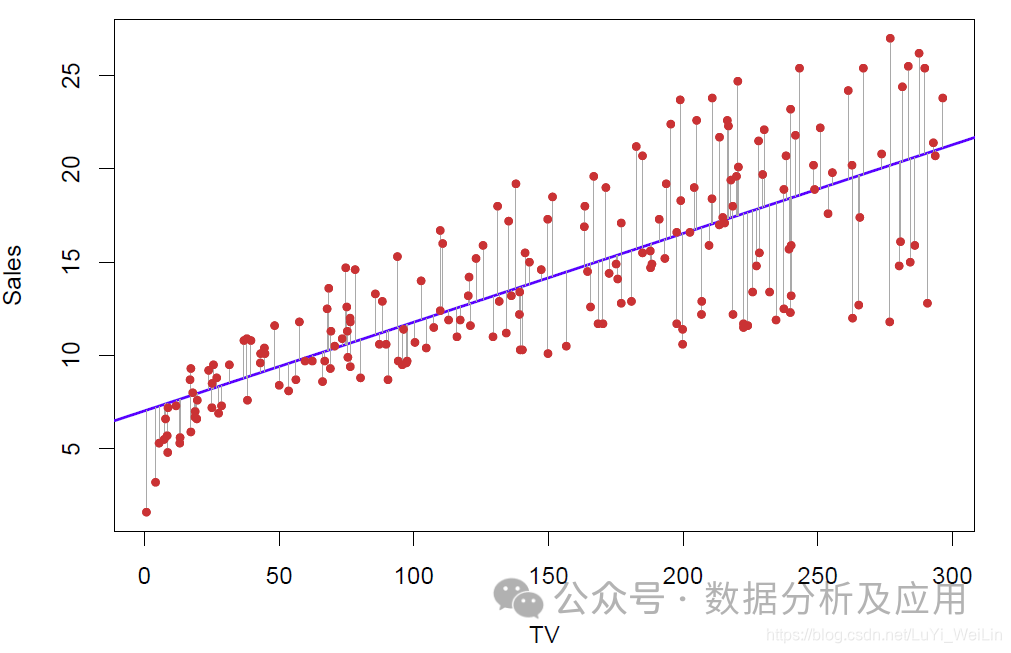
1. Regresi linear:
Prinsip regresi linear adalah untuk mencari garis lurus yang optimum untuk menyesuaikan taburan titik data ke tahap yang paling besar.
Latihan model ialah penggunaan data input dan output yang diketahui untuk mengoptimumkan model, biasanya dengan meminimumkan perbezaan antara nilai ramalan dan nilai sebenar.
Kelebihan: ringkas dan mudah difahami, kecekapan pengiraan yang tinggi.
Kelemahan: Keupayaan terhad untuk mengendalikan perhubungan bukan linear.
Senario penggunaan: Sesuai untuk masalah meramal nilai berterusan, seperti meramal harga rumah, harga saham, dll.
Sampel kod (gunakan Python's Scikit-learn library untuk membina model regresi linear yang mudah):
from sklearn.linear_model import LinearRegressionfrom sklearn.datasets import make_regression# 生成模拟数据集X, y = make_regression(n_samples=100, n_features=1, noise=0.1)# 创建线性回归模型对象lr = LinearRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
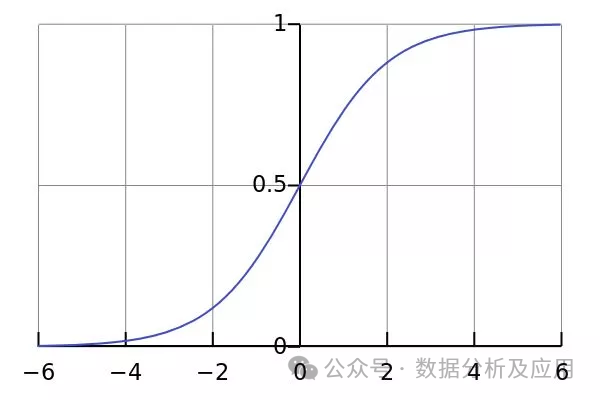
2. Regresi Logistik digunakan:
Logistik regression: . algoritma pembelajaran mesin yang menyelesaikan masalah klasifikasi binari dengan memetakan input berterusan kepada output diskret (biasanya binari). Ia menggunakan fungsi logistik untuk memetakan keputusan regresi linear ke dalam julat (0,1) untuk mendapatkan kebarangkalian pengelasan.
Latihan model: Gunakan data sampel klasifikasi yang diketahui untuk melatih model regresi logistik, dengan mengoptimumkan parameter model untuk meminimumkan kehilangan entropi silang antara kebarangkalian yang diramalkan dan klasifikasi sebenar.
Kelebihan: Mudah dan mudah difahami, lebih baik untuk masalah dua klasifikasi.
Kelemahan: Keupayaan terhad untuk mengendalikan perhubungan bukan linear.
Senario penggunaan: Sesuai untuk masalah klasifikasi binari, seperti penapisan spam, ramalan penyakit, dsb.
Sampel kod (gunakan Python's Scikit-learn library untuk membina model regresi logistik yang mudah):
from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import make_classification# 生成模拟数据集X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)# 创建逻辑回归模型对象lr = LogisticRegression()# 训练模型lr.fit(X, y)# 进行预测predictions = lr.predict(X)
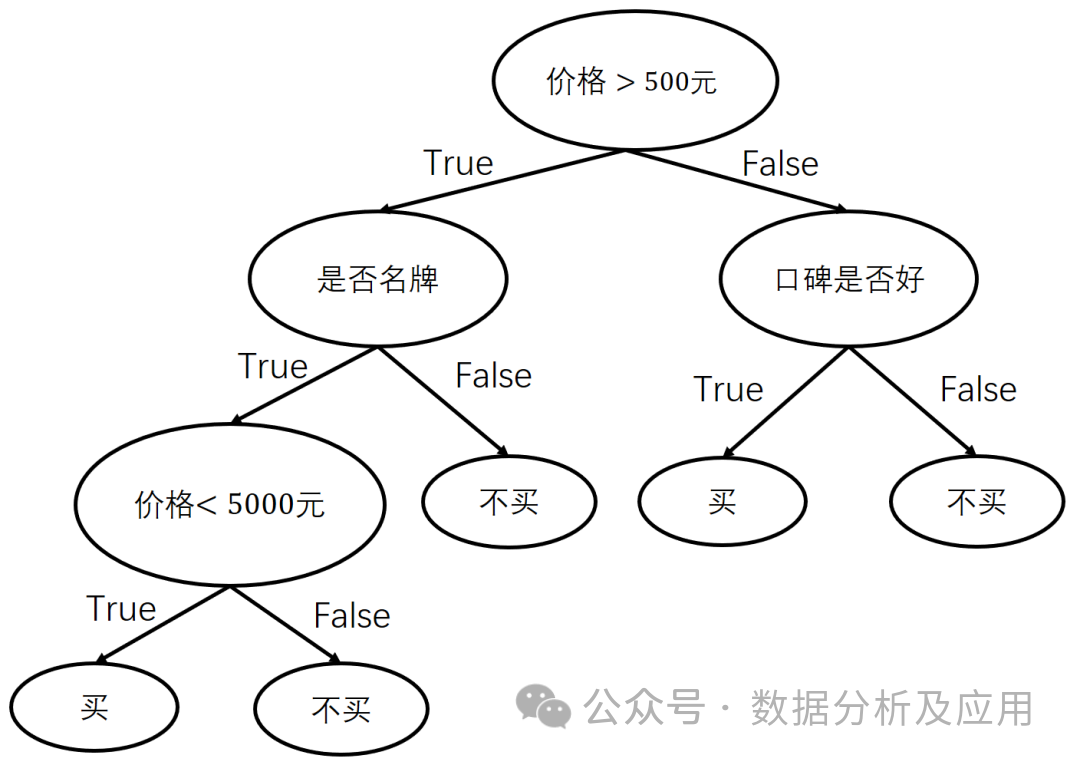
3. algoritma yang membina sempadan keputusan dengan membahagikan set data secara rekursif kepada subset yang lebih kecil. Setiap nod dalaman mewakili keadaan pertimbangan pada atribut ciri, setiap cawangan mewakili nilai atribut yang mungkin, dan setiap nod daun mewakili kategori.
Latihan model: Bina pepohon keputusan dengan memilih atribut pembahagian terbaik, dan gunakan teknik pemangkasan untuk mengelakkan pemasangan berlebihan.
Kelebihan: Mudah difahami dan dijelaskan, mampu menangani masalah klasifikasi dan regresi.
Keburukan: Mudah dipasang berlebihan, sensitif kepada bunyi bising dan outlier.
Senario penggunaan: Sesuai untuk masalah klasifikasi dan regresi, seperti pengesanan penipuan kad kredit, ramalan cuaca, dsb.
from sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树模型对象dt = DecisionTreeClassifier()# 训练模型dt.fit(X_train, y_train)# 进行预测predictions = dt.predict(X_test)
adalah prinsip Naive Baye:
: Naive Baye kaedah pengelasan berdasarkan teorem Bayes dan andaian kebebasan bersyarat ciri. Ia melaksanakan pemodelan kebarangkalian bagi nilai atribut sampel dalam setiap kategori, dan kemudian meramalkan kategori kepunyaan sampel baharu berdasarkan kebarangkalian ini.Latihan model: Bina pengelas Naive Bayes dengan menggunakan data sampel dengan kategori dan atribut yang diketahui untuk menganggarkan kebarangkalian terdahulu bagi setiap kategori dan kebarangkalian bersyarat bagi setiap atribut.
Kelebihan: Mudah, cekap, terutamanya berkesan untuk kategori besar dan set data kecil.
Kelemahan: Pemodelan kebergantungan yang lemah antara ciri.
Senario penggunaan: Sesuai untuk pengelasan teks, penapisan spam dan senario lain.

from sklearn.naive_bayes import GaussianNBfrom sklearn.datasets import load_iris# 加载数据集iris = load_iris()X = iris.datay = iris.target# 创建朴素贝叶斯分类器对象gnb = GaussianNB()# 训练模型gnb.fit(X, y)# 进行预测predictions = gnb.predict(X)
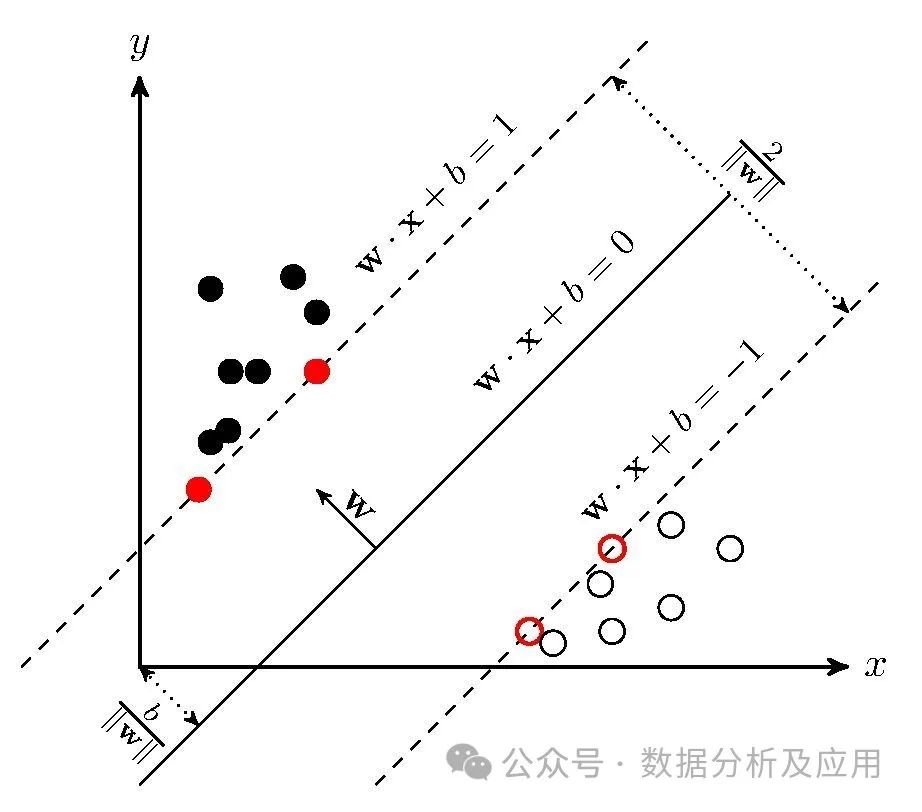
5、支持向量机(SVM):
模型原理:支持向量机是一种监督学习算法,用于分类和回归问题。它试图找到一个超平面,使得该超平面能够将不同类别的样本分隔开。SVM使用核函数来处理非线性问题。
模型训练:通过优化一个约束条件下的二次损失函数来训练SVM,以找到最佳的超平面。
优点:对高维数据和非线性问题表现良好,能够处理多分类问题。
缺点:对于大规模数据集计算复杂度高,对参数和核函数的选择敏感。
使用场景:适用于分类和回归问题,如图像识别、文本分类等。
示例代码(使用Python的Scikit-learn库构建一个简单的SVM分类器):
from sklearn import svmfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器对象,使用径向基核函数(RBF)clf = svm.SVC(kernel='rbf')# 训练模型clf.fit(X_train, y_train)# 进行预测predictions = clf.predict(X_test)
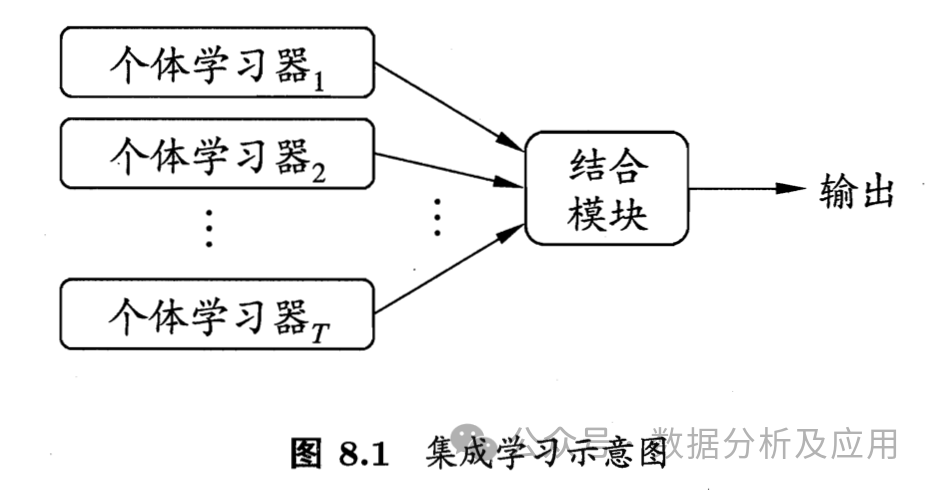
6、集成学习:
模型原理:集成学习是一种通过构建多个基本模型并将它们的预测结果组合起来以提高预测性能的方法。集成学习策略有投票法、平均法、堆叠法和梯度提升等。常见集成学习模型有XGBoost、随机森林、Adaboost等
模型训练:首先使用训练数据集训练多个基本模型,然后通过某种方式将它们的预测结果组合起来,形成最终的预测结果。
优点:可以提高模型的泛化能力,降低过拟合的风险。
缺点:计算复杂度高,需要更多的存储空间和计算资源。
使用场景:适用于解决分类和回归问题,尤其适用于大数据集和复杂的任务。
示例代码(使用Python的Scikit-learn库构建一个简单的投票集成分类器):
from sklearn.ensemble import VotingClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建基本模型对象和集成分类器对象lr = LogisticRegression()dt = DecisionTreeClassifier()vc = VotingClassifier(estimators=[('lr', lr), ('dt', dt)], voting='hard')# 训练集成分类器vc.fit(X_train, y_train)# 进行预测predictions = vc.predict(X_test)7、K近邻算法:
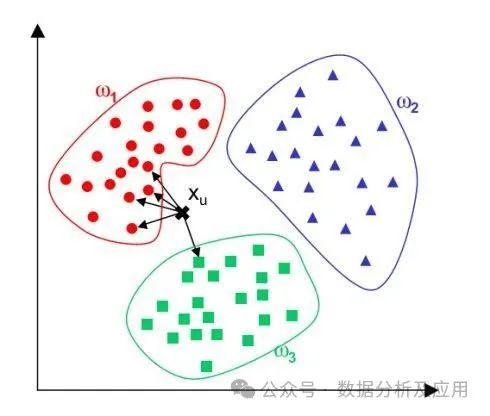
模型原理:K近邻算法是一种基于实例的学习,通过将新的样本与已知样本进行比较,找到与新样本最接近的K个样本,并根据这些样本的类别进行投票来预测新样本的类别。
模型训练:不需要训练阶段,通过计算新样本与已知样本之间的距离或相似度来找到最近的邻居。
优点:简单、易于理解,不需要训练阶段。
缺点:对于大规模数据集计算复杂度高,对参数K的选择敏感。
使用场景:适用于解决分类和回归问题,适用于相似度度量和分类任务。
示例代码(使用Python的Scikit-learn库构建一个简单的K近邻分类器):
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建K近邻分类器对象,K=3knn = KNeighborsClassifier(n_neighbors=3)# 训练模型knn.fit(X_train, y_train)# 进行预测predictions = knn.predict(X_test)
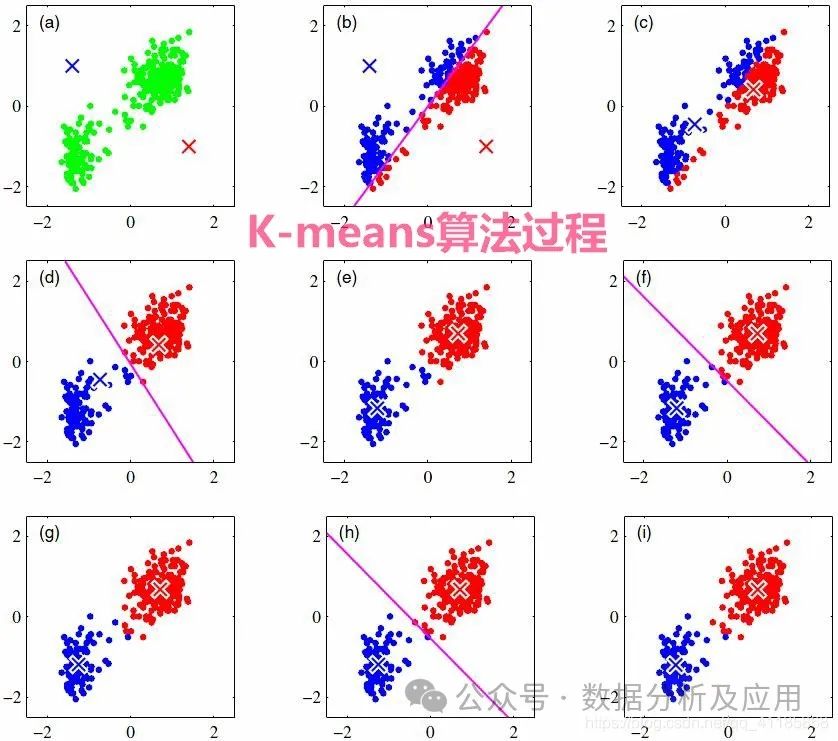
8、K-means算法:
模型原理:K-means算法是一种无监督学习算法,用于聚类问题。它将n个点(可以是样本数据点)划分为k个聚类,使得每个点属于最近的均值(聚类中心)对应的聚类。
模型训练:通过迭代更新聚类中心和分配每个点到最近的聚类中心来实现聚类。
优点:简单、快速,对于大规模数据集也能较好地运行。
缺点:对初始聚类中心敏感,可能会陷入局部最优解。
使用场景:适用于聚类问题,如市场细分、异常值检测等。
示例代码(使用Python的Scikit-learn库构建一个简单的K-means聚类器):
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as plt# 生成模拟数据集X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)# 创建K-means聚类器对象,K=4kmeans = KMeans(n_clusters=4)# 训练模型kmeans.fit(X)# 进行预测并获取聚类标签labels = kmeans.predict(X)# 可视化结果plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')plt.show()
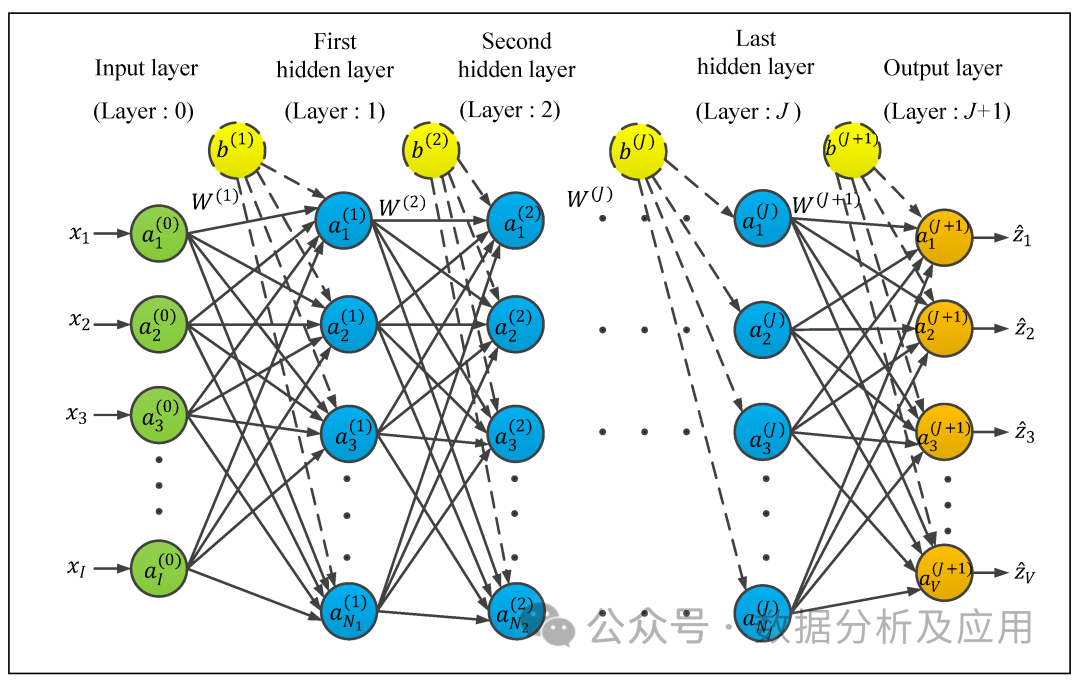
9、神经网络:
模型原理:神经网络是一种模拟人脑神经元结构的计算模型,通过模拟神经元的输入、输出和权重调整机制来实现复杂的模式识别和分类等功能。神经网络由多层神经元组成,输入层接收外界信号,经过各层神经元的处理后,最终输出层输出结果。
模型训练:神经网络的训练是通过反向传播算法实现的。在训练过程中,根据输出结果与实际结果的误差,逐层反向传播误差,并更新神经元的权重和偏置项,以减小误差。
优点:能够处理非线性问题,具有强大的模式识别能力,能够从大量数据中学习复杂的模式。
缺点:容易陷入局部最优解,过拟合问题严重,训练时间长,需要大量的数据和计算资源。
使用场景:适用于图像识别、语音识别、自然语言处理、推荐系统等场景。
示例代码(使用Python的TensorFlow库构建一个简单的神经网络分类器):
import tensorflow as tffrom tensorflow.keras import layers, modelsfrom tensorflow.keras.datasets import mnist# 加载MNIST数据集(x_train, y_train), (x_test, y_test) = mnist.load_data()# 归一化处理输入数据x_train = x_train / 255.0x_test = x_test / 255.0# 构建神经网络模型model = models.Sequential()model.add(layers.Flatten(input_shape=(28, 28)))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(10, activation='softmax'))# 编译模型并设置损失函数和优化器等参数model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 训练模型model.fit(x_train, y_train, epochs=5)# 进行预测predictions = model.predict(x_test)
10.深度强化学习(DQN):
模型原理:Deep Q-Networks (DQN) 是一种结合了深度学习与Q-learning的强化学习算法。它的核心思想是使用神经网络来逼近Q函数,即状态-动作值函数,从而为智能体在给定状态下选择最优的动作提供依据。
模型训练:DQN的训练过程包括两个阶段:离线阶段和在线阶段。在离线阶段,智能体通过与环境的交互收集数据并训练神经网络。在线阶段,智能体使用神经网络进行动作选择和更新。为了解决过度估计问题,DQN引入了目标网络的概念,通过使目标网络在一段时间内保持稳定来提高稳定性。
优点:能够处理高维度的状态和动作空间,适用于连续动作空间的问题,具有较好的稳定性和泛化能力。
缺点:容易陷入局部最优解,需要大量的数据和计算资源,对参数的选择敏感。
使用场景:适用于游戏、机器人控制等场景。
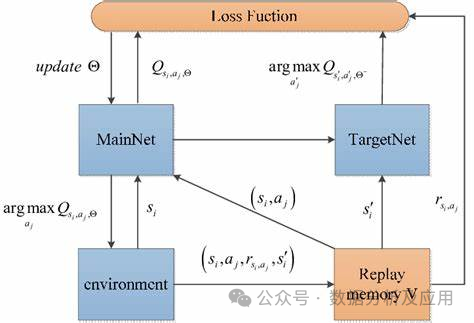
示例代码(使用Python的TensorFlow库构建一个简单的DQN强化学习模型):
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout, Flattenfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras import backend as Kclass DQN:def __init__(self, state_size, action_size):self.state_size = state_sizeself.action_size = action_sizeself.memory = deque(maxlen=2000)self.gamma = 0.85self.epsilon = 1.0self.epsilon_min = 0.01self.epsilon_decay = 0.995self.learning_rate = 0.005self.model = self.create_model()self.target_model = self.create_model()self.target_model.set_weights(self.model.get_weights())def create_model(self):model = Sequential()model.add(Flatten(input_shape=(self.state_size,)))model.add(Dense(24, activation='relu'))model.add(Dense(24, activation='relu'))model.add(Dense(self.action_size, activation='linear'))return modeldef remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if len(self.memory) > 1000:self.epsilon *= self.epsilon_decayif self.epsilon
Atas ialah kandungan terperinci 10 Algoritma Kepintaran Buatan Yang Mesti Tahu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!