
Rumah >Peranti teknologi >AI >ICLR 2024 Lisan: Pembelajaran korelasi bunyi dalam video panjang, latihan kad tunggal hanya mengambil masa 1 hari
ICLR 2024 Lisan: Pembelajaran korelasi bunyi dalam video panjang, latihan kad tunggal hanya mengambil masa 1 hari

- 王林ke hadapan
- 2024-03-05 22:58:13940semak imbas

Tajuk kertas: Multi-granularity Correspondence Belajar daripada Video Bising Jangka Panjang -
Alamat kertas: https://openreview.net/pdf?id=9Cu8MRmhq2 :Projek: https://openreview.net/pdf //lin-yijie.github.io/projects/Norton - Alamat kod: https://github.com/XLearning-SCU/2024-ICLR-Norton

-
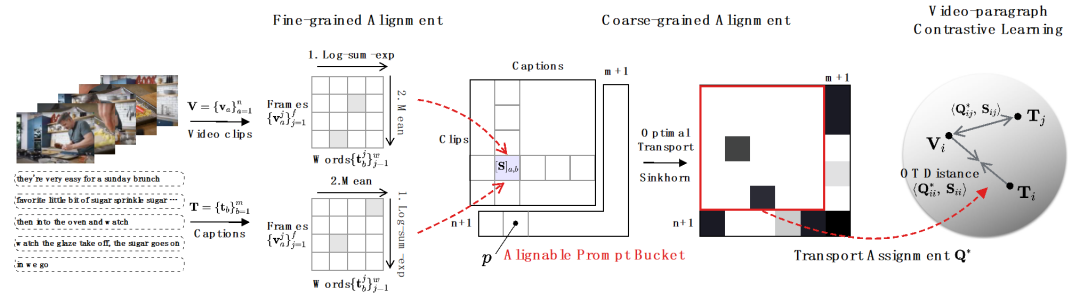
NC berbutir kasar (antara Klip-Kapsyen). NC berbutir kasar termasuk dua kategori: asynchronous (Asynchronous) dan tidak relevan (Irrelevant) Perbezaannya terletak pada sama ada klip video atau tajuk boleh sepadan dengan tajuk atau klip video yang sedia ada. "Asynchronous" merujuk kepada ketidakjajaran masa antara klip video dan tajuk, seperti t1 dalam Rajah 2. Ini mengakibatkan ketidakpadanan antara urutan pernyataan dan tindakan, seperti yang diterangkan oleh narator sebelum dan selepas tindakan sebenarnya dilakukan. "Tidak berkaitan" merujuk kepada tajuk tidak bermakna yang tidak boleh diselaraskan dengan klip video (seperti t2 dan t6), atau klip video yang tidak berkaitan. Menurut penyelidikan yang berkaitan oleh Oxford Visual Geometry Group [5], hanya kira-kira 30% daripada klip video dan tajuk dalam set data HowTo100M dijajarkan secara visual, dan hanya 15% pada asalnya diselaraskan; Bingkai-Perkataan) . Untuk klip video, hanya sebahagian daripada huraian teks mungkin berkaitan dengannya. Dalam Rajah 2, tajuk t5 "Taburkan gula padanya" sangat berkaitan dengan kandungan visual v5, tetapi tindakan "Perhatikan sayu mengelupas" tidak berkaitan dengan kandungan visual. Perkataan atau bingkai video yang tidak berkaitan mungkin menghalang pengekstrakan maklumat penting, menjejaskan penjajaran antara segmen dan tajuk.
. 
untuk NC berbutir halus
-
Untuk NC tak segerak berbutir kasar . Para penyelidik menggunakan jarak penghantaran optimum sebagai metrik jarak antara klip video dan tajuk. Memandangkan matriks persamaan tajuk klip video , dengan - mewakili bilangan klip dan tajuk Matlamat penghantaran optimum adalah untuk memaksimumkan persamaan penjajaran keseluruhan, yang secara semula jadi boleh mengendalikan pemasaan tak segerak atau satu-ke-banyak (seperti t3 dan. v4, v5 sepadan) situasi penjajaran kompleks.

di mana ialah pengagihan seragam yang memberikan berat yang sama kepada setiap segmen dan tajuk, ialah penugasan penghantaran atau momen penjajaran semula, yang boleh diselesaikan oleh algoritma Sinkhorn. Berorientasikan kepada NC yang tidak berkaitan berbutir kasar. Diilhamkan oleh SuperGlue [6] dalam padanan ciri, kami mereka bentuk baldi pembayang boleh diselaraskan penyesuaian untuk cuba menapis segmen dan tajuk yang tidak berkaitan. Baldi gesaan ialah vektor dengan nilai yang sama dalam satu baris dan satu lajur, disambung pada matriks persamaan , dan nilainya mewakili ambang persamaan sama ada ia boleh diselaraskan. Baldi Petua disepadukan dengan lancar ke dalam penyelesai Sinkhorn Pengangkutan Optimum.
Mengukur jarak jujukan melalui transmisi optimum dan bukannya memodelkan video panjang secara langsung boleh mengurangkan jumlah pengiraan dengan ketara. Fungsi kehilangan perenggan video terakhir adalah seperti berikut, di mana mewakili matriks persamaan antara video panjang ke dan perenggan teks ke . 2) Coretan - Perbandingan tajuk . Kehilangan ini memastikan ketepatan penjajaran segmen ke tajuk dalam perbandingan perenggan video. Memandangkan pembelajaran kontrastif yang diselia sendiri akan tersilap mengoptimumkan sampel yang serupa secara semantik sebagai sampel negatif, kami menggunakan pemindahan optimum untuk mengenal pasti dan membetulkan sampel negatif palsu yang berpotensi: di mana mewakili semua klip video dan tajuk dalam nombor kelompok latihan, identiti matriks mewakili sasaran penjajaran standard dalam kehilangan rentas entropi pembelajaran kontras, mewakili sasaran penjajaran semula selepas memasukkan sasaran pembetulan penghantaran optimum , dan ialah pekali berat. Eksperimen Artikel ini bertujuan untuk mengatasi korelasi hingar untuk meningkatkan keupayaan model memahami video yang panjang. Kami mengesahkannya melalui tugasan khusus seperti pengambilan video, soal jawab dan pembahagian tindakan Beberapa keputusan percubaan adalah seperti berikut. 1) Pencapaian video panjang Matlamat tugasan ini adalah untuk mendapatkan semula video panjang yang sepadan dengan perenggan teks. Pada set data YouCookII, penyelidik menguji dua senario: pengekalan latar belakang dan penyingkiran latar belakang, bergantung pada sama ada untuk mengekalkan klip video bebas teks. Mereka menggunakan tiga kriteria ukuran persamaan: Purata Kapsyen, DTW dan OTAM. Purata Kapsyen sepadan dengan klip video optimum untuk setiap tajuk dalam perenggan teks, dan akhirnya mengingati semula video panjang dengan bilangan padanan terbesar. DTW dan OTAM mengumpul jarak antara video dan perenggan teks dalam susunan kronologi. Keputusan ditunjukkan dalam Jadual 1 dan 2 di bawah. Jadual 1, 2 Perbandingan prestasi pengambilan video panjang 2) Analisis keteguhan korelasi bunyi
ini pembelajaran perkaitan[3][4 ]——Sambungan mendalam tentang ketidakpadanan data/korelasi ralat, mengkaji masalah korelasi hingar berbilang butiran yang dihadapi oleh pra-latihan teks video berbilang mod, kaedah pembelajaran video panjang yang dicadangkan boleh diperluaskan kepada julat data video yang lebih luas dengan bahagian tengah atas sumber yang lebih rendah. Melihat masa depan, penyelidik dapat meneroka korelasi antara pelbagai modaliti. (BLIP). -2) Untuk membersihkan dan menyusun semula korpus teks; dan meneroka kemungkinan menggunakan hingar sebagai rangsangan positif untuk latihan model, dan bukannya hanya menekan kesan negatif bunyi. Rujukan:
1 Tapak ini, "Yann LeCun: Model generatif tidak sesuai untuk memproses video, AI perlu membuat ramalan dalam ruang abstrak", 2024.
2 Sun, Y., Xue, H., Song, R., Liu, B., Yang, H., & Fu, J. (2022). dengan pembelajaran kontrastif temporal multimodal dalam sistem pemprosesan maklumat saraf, 35, 38032-38045.3. Huang, Z., Niu, G., Liu, X., Ding, W., Xiao, X . , Wu, H., & Peng, X. (2021 Pembelajaran dengan surat-menyurat yang bising untuk pemadanan silang modal dalam Sistem Pemprosesan Neural, 34, 29406-29419. 4 , Yang, M. , Yu, J., Hu, P., Zhang, C., & Peng, X. (2023 Padanan graf dengan surat-menyurat bising dwi-peringkat Dalam Prosiding persidangan antarabangsa IEEE/CVF tentang penglihatan komputer. . 5.Han, T., Xie, W., & Zisserman, A. (2022 Rangkaian penjajaran sementara untuk video jangka panjang Dalam Prosiding Persidangan IEEE/CVF tentang Penglihatan Komputer dan Pengecaman Corak (ms. 2906-2916) Persidangan IEEE/CVF mengenai penglihatan komputer dan pengecaman corak (ms 4938-4947).
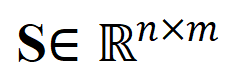
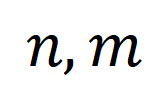
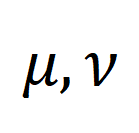 ialah pengagihan seragam yang memberikan berat yang sama kepada setiap segmen dan tajuk,
ialah pengagihan seragam yang memberikan berat yang sama kepada setiap segmen dan tajuk, 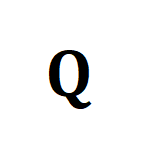 ialah penugasan penghantaran atau momen penjajaran semula, yang boleh diselesaikan oleh algoritma Sinkhorn.
ialah penugasan penghantaran atau momen penjajaran semula, yang boleh diselesaikan oleh algoritma Sinkhorn. 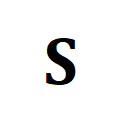 , dan nilainya mewakili ambang persamaan sama ada ia boleh diselaraskan. Baldi Petua disepadukan dengan lancar ke dalam penyelesai Sinkhorn Pengangkutan Optimum.
, dan nilainya mewakili ambang persamaan sama ada ia boleh diselaraskan. Baldi Petua disepadukan dengan lancar ke dalam penyelesai Sinkhorn Pengangkutan Optimum. 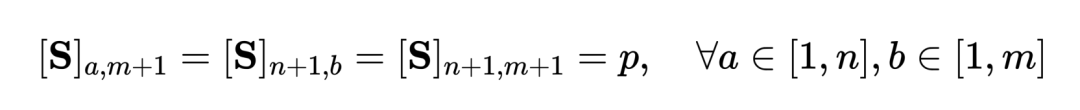
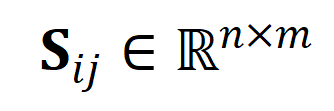 mewakili matriks persamaan antara video panjang ke
mewakili matriks persamaan antara video panjang ke 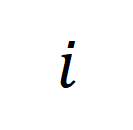 dan perenggan teks ke
dan perenggan teks ke 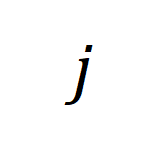 .
. 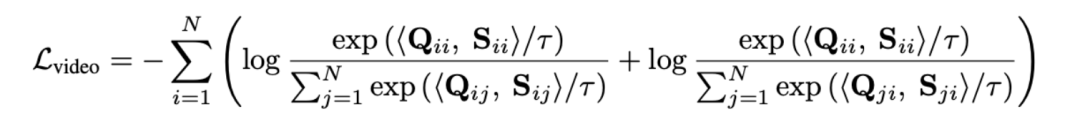
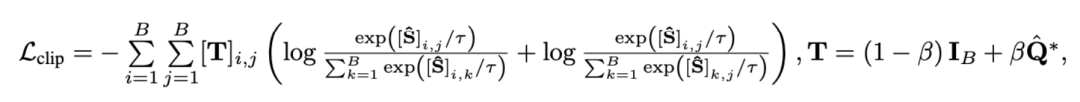
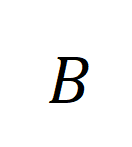 mewakili semua klip video dan tajuk dalam nombor kelompok latihan, identiti matriks
mewakili semua klip video dan tajuk dalam nombor kelompok latihan, identiti matriks 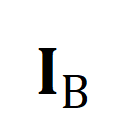 mewakili sasaran penjajaran standard dalam kehilangan rentas entropi pembelajaran kontras,
mewakili sasaran penjajaran standard dalam kehilangan rentas entropi pembelajaran kontras, 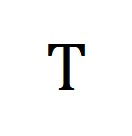 mewakili sasaran penjajaran semula selepas memasukkan sasaran pembetulan penghantaran optimum
mewakili sasaran penjajaran semula selepas memasukkan sasaran pembetulan penghantaran optimum 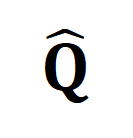 , dan
, dan 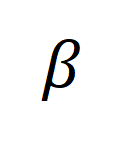 ialah pekali berat.
ialah pekali berat. 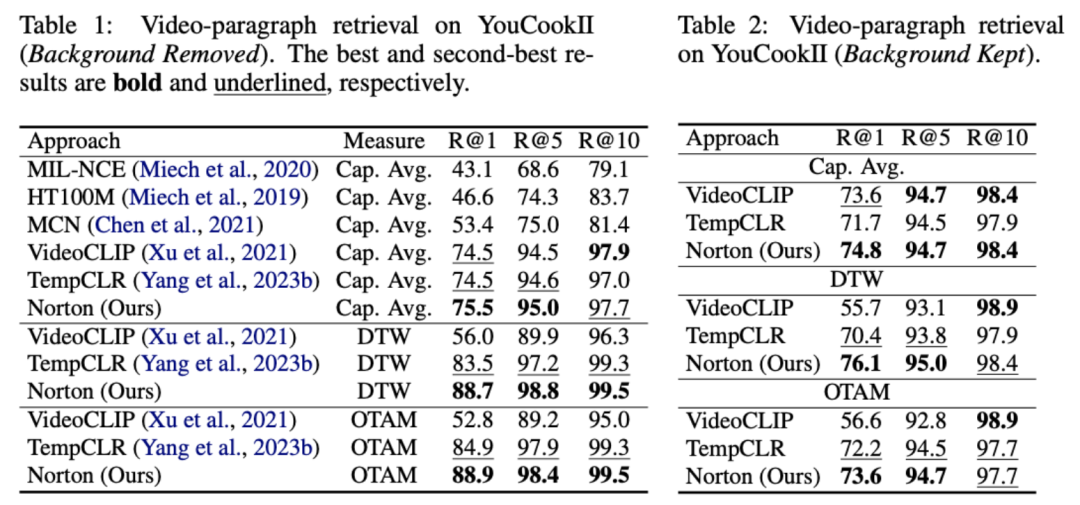

Atas ialah kandungan terperinci ICLR 2024 Lisan: Pembelajaran korelasi bunyi dalam video panjang, latihan kad tunggal hanya mengambil masa 1 hari. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:
Artikel ini dikembalikan pada:jiqizhixin.com. Jika ada pelanggaran, sila hubungi admin@php.cn Padam
Artikel sebelumnya:Llama3 akan dikeluarkan pada bulan Julai! Sedang menjalani penalaan halus!Artikel seterusnya:Llama3 akan dikeluarkan pada bulan Julai! Sedang menjalani penalaan halus!
Artikel berkaitan
Lihat lagi- 人工智能产业链包括
- Ronglian Cloud telah dipilih ke dalam Peta Industri AI Generatif Global 2023
- Artikel panjang 10,000 perkataan丨Menyahbina rantaian industri keselamatan AI, penyelesaian dan peluang keusahawanan
- Baidu melancarkan model perubatan 'peringkat industri' pertama China 'Model Perubatan Rohani': Baidu melancarkan model perubatan 'peringkat industri' pertama China 'Model Perubatan Rohani'
- Ahli CPPCC Daerah Xuhui menganjurkan aktiviti pemeriksaan intensif dan memberi perhatian kepada pembangunan industri kecerdasan buatan