
Rumah >Peranti teknologi >AI >Butiran teknikal gugusan Byte Wanka didedahkan: Latihan GPT-3 selesai dalam 2 hari, dan penggunaan kuasa pengkomputeran melebihi NVIDIA Megatron-LM
Butiran teknikal gugusan Byte Wanka didedahkan: Latihan GPT-3 selesai dalam 2 hari, dan penggunaan kuasa pengkomputeran melebihi NVIDIA Megatron-LM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-01 16:01:331102semak imbas
Apabila analisis teknikal Sora berlaku, kepentingan infrastruktur AI menjadi semakin menonjol.
Sebuah kertas baru dari Byte dan Universiti Peking menarik perhatian pada masa ini:
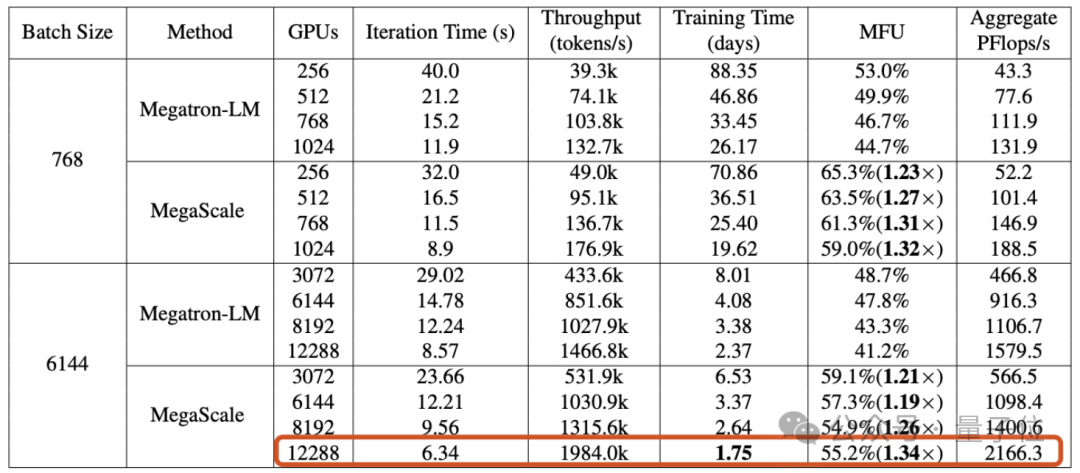
Artikel itu mendedahkan bahawa Wanka cluster yang dibina oleh Byte boleh melengkapkan model skala GPT-3 (175B) dalam 1.75 hari ) )
.
Secara khusus, Byte mencadangkan sistem pengeluaran yang dipanggil MegaScale
, yang bertujuan untuk menyelesaikan cabaran kecekapan dan kestabilan yang dihadapi semasa melatih model besar pada kelompok Wanka.Apabila melatih model bahasa besar 175 bilion parameter pada 12288 GPU, MegaScale mencapai penggunaan kuasa pengkomputeran sebanyak 55.2% (MFU)
, iaitu 1.34 kali ganda berbanding NVIDIA Megatron-LM.Makalah itu juga mendedahkan bahawa setakat September 2023, Byte telah menubuhkan GPU seni bina Ampere (A100/A800) gugusan dengan lebih daripada 10,000 kad, dan kini sedang membina seni bina Hopper berskala besar (H100/H800)
gugusan . Sesuai untuk sistem pengeluaran kluster WankaDalam era model besar, kepentingan GPU tidak lagi memerlukan perincian.Tetapi latihan model besar tidak boleh dimulakan terus apabila bilangan kad penuh - apabila skala kluster GPU mencapai tahap "10,000", bagaimana untuk mencapai latihan yang cekap dan stabil adalah satu cabaran tersendiri masalah kejuruteraan.

Cabaran pertama: kecekapan.
Melatih model bahasa yang besar bukanlah tugas selari yang mudah. Ia memerlukan pengedaran model antara berbilang GPU, dan GPU ini memerlukan komunikasi yang kerap untuk memajukan proses latihan secara bersama. Selain komunikasi, faktor seperti pengoptimuman operator, prapemprosesan data dan penggunaan memori GPU semuanya mempunyai kesan ke atas penggunaan kuasa pengkomputeran (MFU) , penunjuk yang mengukur kecekapan latihan.
MFU ialah nisbah daya pemprosesan sebenar kepada daya pemprosesan maksimum teori.
Cabaran kedua: kestabilan.
Kami tahu bahawa latihan model bahasa yang besar selalunya mengambil masa yang sangat lama, yang juga bermakna kegagalan dan kelewatan semasa proses latihan adalah perkara biasa.
Kos kegagalan adalah tinggi, jadi cara memendekkan masa pemulihan kegagalan menjadi sangat penting.
Untuk menangani cabaran ini, penyelidik ByteDance membina MegaScale dan telah mengerahkannya ke pusat data Byte untuk menyokong latihan pelbagai model besar.
MegaScale dipertingkatkan berdasarkan NVIDIA Megatron-LM.
Penambahbaikan khusus termasuk reka bentuk bersama algoritma dan komponen sistem, pengoptimuman pertindihan komunikasi dan pengkomputeran, pengoptimuman operator, pengoptimuman saluran paip data dan penalaan prestasi rangkaian, dsb.:
- Pengoptimuman Algoritma: Penyelidik memperkenalkan blok Transformer selari, mekanisme perhatian tingkap gelongsor (SWA) dan pengoptimum LAMB ke dalam seni bina model untuk meningkatkan kecekapan latihan tanpa mengorbankan penumpuan model.
- Pertindihan komunikasi: Berdasarkan analisis khusus bagi operasi setiap unit pengkomputeran dalam selari 3D (keselarian data, keselarian saluran paip, keselarian tensor) , penyelidik mereka strategi operasi teknikal yang tidak kritikal untuk mengurangkan operasi teknikal secara berkesan laluan Kelewatan yang disebabkan memendekkan masa lelaran setiap pusingan dalam latihan model.
- Operator Cekap: Pengendali GEMM telah dioptimumkan, dan operasi seperti LayerNorm dan GeLU telah disepadukan untuk mengurangkan overhed pelancaran berbilang teras dan mengoptimumkan corak akses memori.
- Pengoptimuman saluran paip data: Optimumkan prapemprosesan dan pemuatan data dan kurangkan masa melahu GPU melalui prapemprosesan data tak segerak dan penghapusan pemuat data berlebihan.
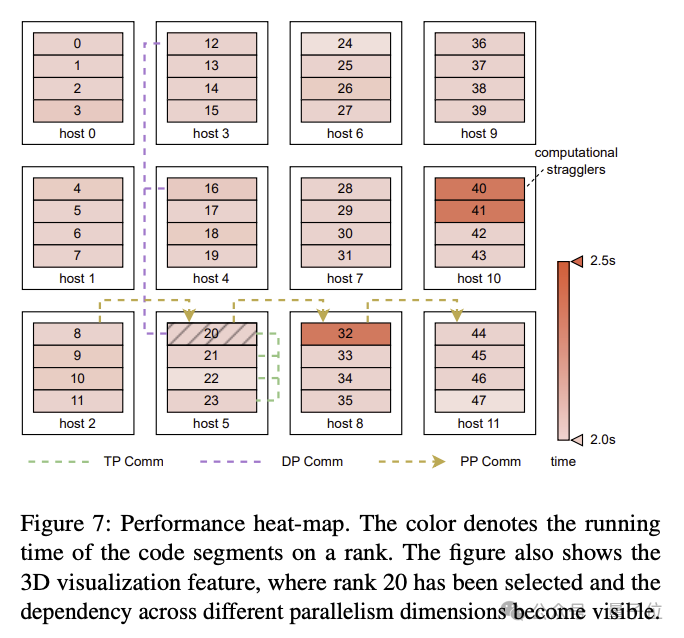
- Pengamatan kumpulan komunikasi kolektif: Mengoptimumkan proses pemulaan rangka kerja komunikasi berbilang kad NVIDIA NCCL dalam latihan yang diedarkan. Tanpa pengoptimuman, masa permulaan kluster 2048-GPU ialah 1047 saat, yang boleh dikurangkan kepada kurang daripada 5 saat selepas pengoptimuman; masa permulaan kluster GPU Wanka boleh dikurangkan kepada kurang daripada 30 saat.
- Penalaan Prestasi Rangkaian: Menganalisis trafik antara mesin dalam keselarian 3D, dan mereka bentuk penyelesaian teknikal untuk meningkatkan prestasi rangkaian, termasuk reka bentuk topologi rangkaian, pengurangan konflik cincang ECMP, kawalan kesesakan dan tetapan tamat masa penghantaran semula.
- Toleransi Kesalahan: Dalam kelompok Wanka, kegagalan perisian dan perkakasan tidak dapat dielakkan. Para penyelidik mereka bentuk rangka kerja latihan untuk mencapai pengecaman kerosakan automatik dan pemulihan pantas. Khususnya, ia termasuk membangunkan alat diagnostik untuk memantau komponen dan acara sistem, mengoptimumkan proses latihan penjimatan frekuensi tinggi pusat pemeriksaan, dsb.
Kertas tersebut menyebut bahawa MegaScale secara automatik boleh mengesan dan membaiki lebih daripada 90% kegagalan perisian dan perkakasan.
Hasil eksperimen menunjukkan bahawa apabila MegaScale melatih model bahasa besar 175B pada 12288 GPU, ia mencapai 55.2% MFU, iaitu 1.34 kali penggunaan kuasa pengkomputeran Megatrion-LM.
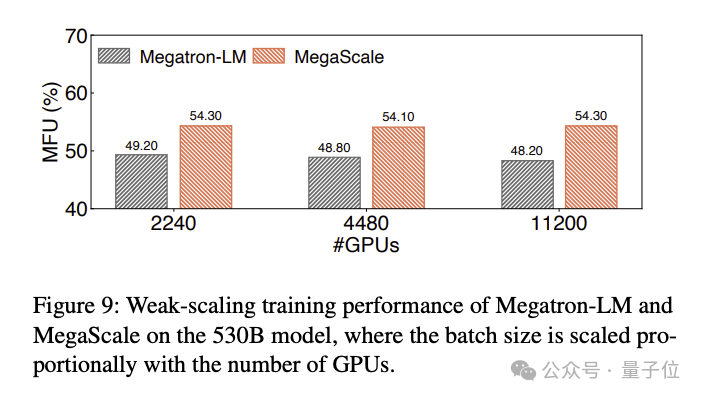
Hasil perbandingan MFU untuk melatih model bahasa besar 530B adalah seperti berikut:
One More Thing
Sama seperti kertas teknikal ini mencetuskan perbincangan, berita baharu keluar tentang produk Sora berasaskan bait:
Screenshot Alat video AInya yang serupa dengan Sora telah melancarkan ujian beta jemputan sahaja.

Nampaknya asas telah diletakkan, jadi adakah anda menantikan produk model besar Byte?
Alamat kertas: https://arxiv.org/abs/2402.15627
Atas ialah kandungan terperinci Butiran teknikal gugusan Byte Wanka didedahkan: Latihan GPT-3 selesai dalam 2 hari, dan penggunaan kuasa pengkomputeran melebihi NVIDIA Megatron-LM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!