
Rumah >Peranti teknologi >AI >Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori
Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori

- PHPzke hadapan
- 2024-03-01 12:20:04933semak imbas
Pasukan Chen Danqi baru sahaja mengeluarkan kaedah pengembangan tetingkap konteks LLM baharu:
Ia boleh memanjangkan tetingkap Llama-2 kepada 128k menggunakan hanya 8k dokumen token untuk latihan. Perkara yang paling penting ialah dalam proses ini, model hanya memerlukan1/6 daripada memori asal, dan model mencapai 10 kali pemprosesan.
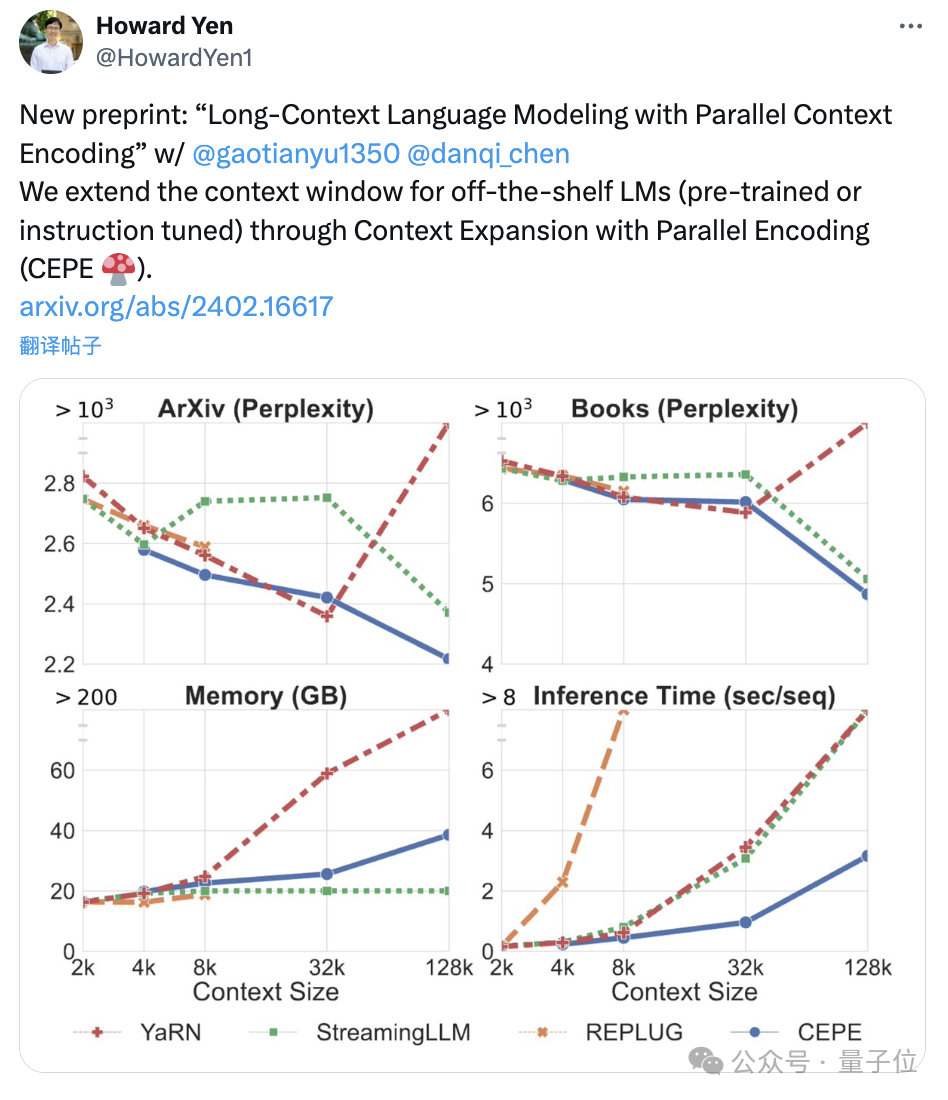
mengurangkan kos latihan:
Menggunakan kaedah ini untuk mengubah alpaca 7B 2 hanya memerlukansekeping A100.
Pasukan berkata:Kami berharap kaedah ini berguna dan mudah digunakan, serta menyediakan keupayaan konteks yangPada masa ini, model dan kod diterbitkan di HuggingFace dan GitHub.murah dan berkesan untuk LLM akan datang.
CEPE, nama penuhnya ialah "Pengembangan Konteks dengan Pengekodan Selari(Pengembangan Konteks dengan Pengekodan Selari)". Sebagai rangka kerja yang ringan, ia boleh digunakan untuk memanjangkan tetingkap konteks mana-mana model
dilatih dan arahan yang diperhalusi. Untuk mana-mana model bahasa penyahkod sahaja yang telah dilatih, CEPE memanjangkannya dengan menambahkan dua komponen kecil:
Satu ialah pengekod keciluntuk pengekodan blok konteks panjang
Satu adalah modul Daya perhatian silangke dalam setiap lapisan penyahkod, digunakan untuk memfokuskan pada perwakilan pengekod. Seni bina lengkap adalah seperti berikut:
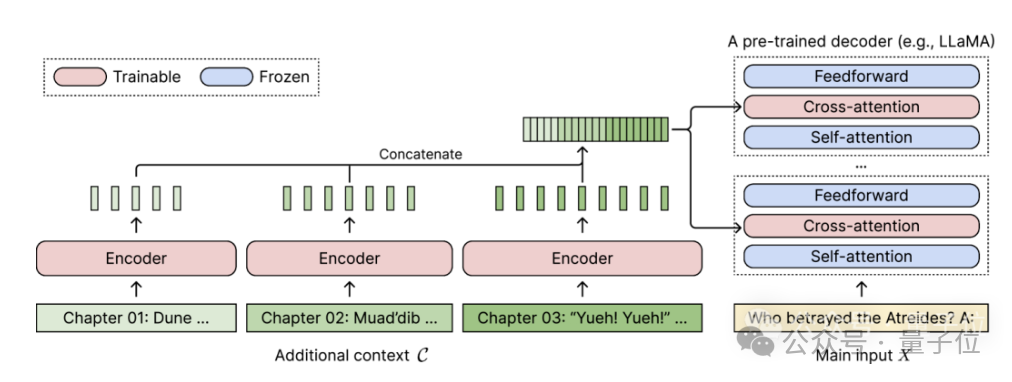 Dalam rajah ini, model pengekod mengekod 3 blok tambahan konteks secara selari dan digabungkan dengan perwakilan tersembunyi terakhir, yang kemudiannya digunakan sebagai input kepada perhatian silang penyahkod lapisan.
Dalam rajah ini, model pengekod mengekod 3 blok tambahan konteks secara selari dan digabungkan dengan perwakilan tersembunyi terakhir, yang kemudiannya digunakan sebagai input kepada perhatian silang penyahkod lapisan.
Di sini, lapisan perhatian silang tertumpu terutamanya pada perwakilan pengekod antara lapisan perhatian diri dan lapisan suapan ke hadapan dalam model penyahkod.
Dengan berhati-hati memilih data latihan yang tidak memerlukan pelabelan, CEPE membantu model mempunyai keupayaan konteks yang panjang dan juga mahir dalam pengambilan dokumen.
Pengarang memperkenalkan bahawa CEPE tersebut terutamanya mengandungi tiga kelebihan utama:
(1) Panjangnya boleh digeneralisasikankerana ia tidak dikekang oleh pengekodan kedudukan Sebaliknya, konteksnya dibahagikan dan dikodkan, dan setiap satu segmen adalah Mempunyai pengekodan lokasi sendiri.
(2) Kecekapan tinggiMenggunakan pengekod kecil dan pengekodan selari untuk memproses konteks boleh mengurangkan kos pengiraan.
Pada masa yang sama, memandangkan perhatian silang hanya menumpukan pada perwakilan lapisan terakhir pengekod, dan model bahasa yang hanya menggunakan penyahkod perlu cache pasangan nilai kunci setiap token dalam setiap lapisan, jadi dalam perbandingan, CEPE memerlukan banyak pengurangan memori.
(3) Kurangkan kos latihan
Tidak seperti kaedah penalaan halus penuh, CEPE hanya melaraskan pengekod dan perhatian silang sambil mengekalkan model penyahkod besar beku.
Pengarang memperkenalkan bahawa dengan mengembangkan dekoder 7B menjadi model
dengan pengekod 400M dan lapisan perhatian silang (jumlah 1.4 bilion parameter), ia boleh dilengkapkan dengan GPU A100 80GB. Kerisauan terus berkurang
Pasukan menggunakan CEPE pada Llama-2 dan dilatih pada versi 20 bilion token yang ditapis RedPajama
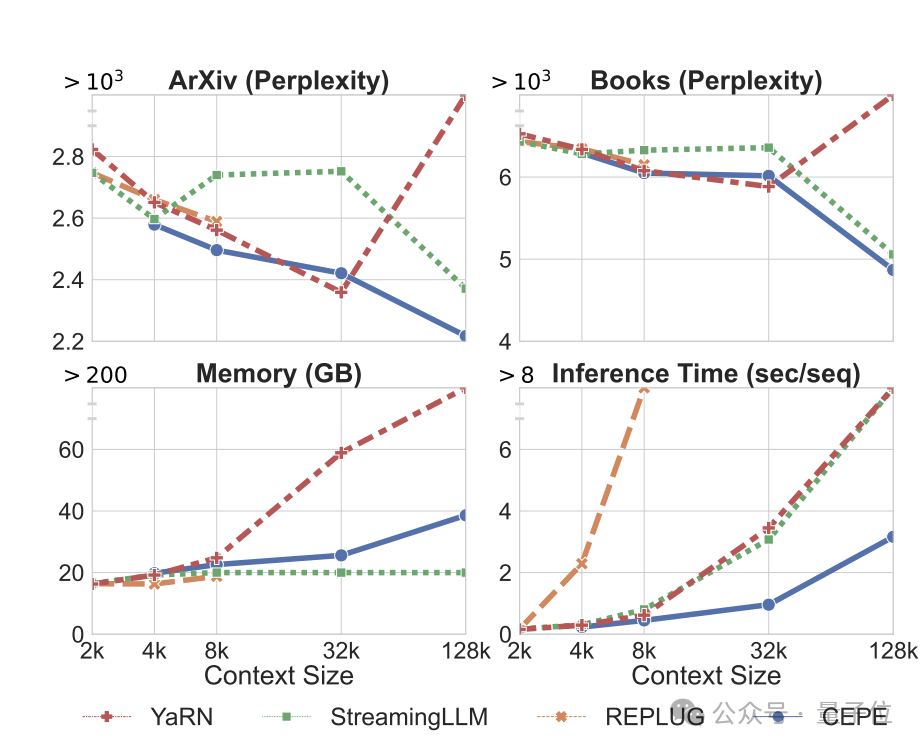
(hanya 1% daripada bajet pra-latihan Llama-2). Pertama, berbanding dengan dua model yang diperhalusi sepenuhnya, LLAMA2-32K dan YARN-64K, CEPE mencapai
perplexity yang lebih rendah atau setanding pada semua set data sambil mempunyai kadar penggunaan memori yang lebih rendah dan daya pemprosesan yang lebih tinggi.
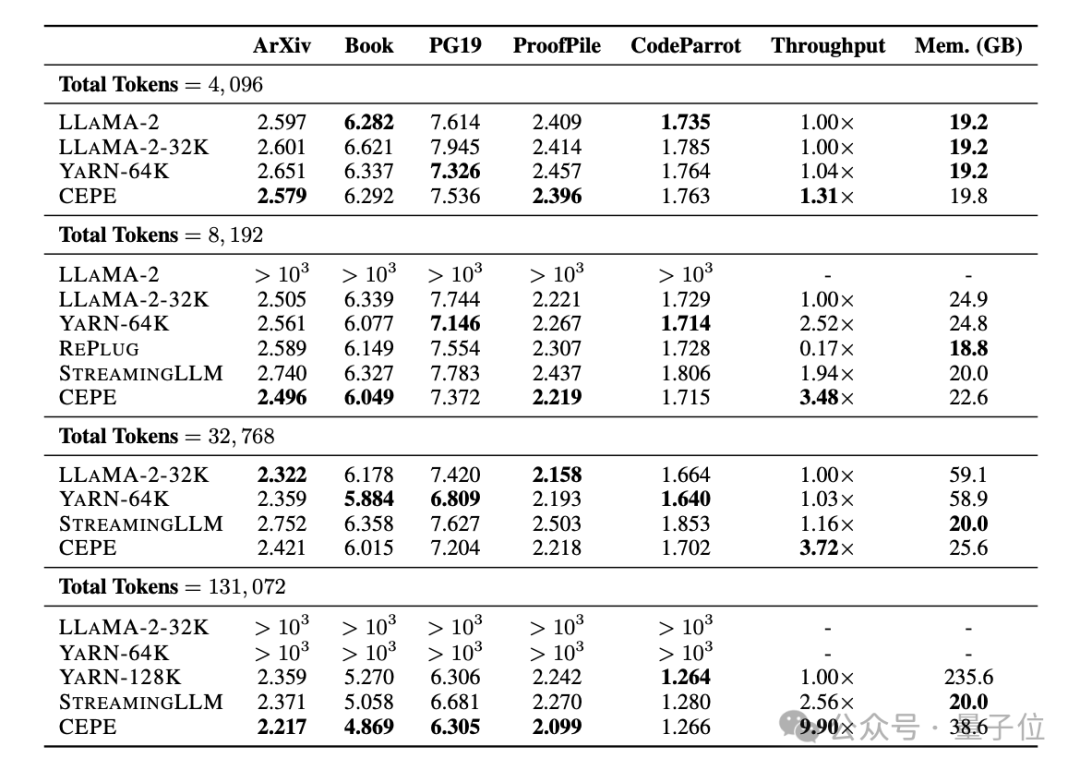 Apabila konteks ditingkatkan kepada 128k
Apabila konteks ditingkatkan kepada 128k
, kebingungan CEPE terus berkurangan sambil mengekalkan keadaan ingatan yang rendah. Sebaliknya, Llama-2-32K dan YARN-64K bukan sahaja gagal membuat generalisasi melebihi tempoh latihan mereka, tetapi juga disertai dengan peningkatan ketara dalam kos ingatan.
 Kedua,
Kedua,
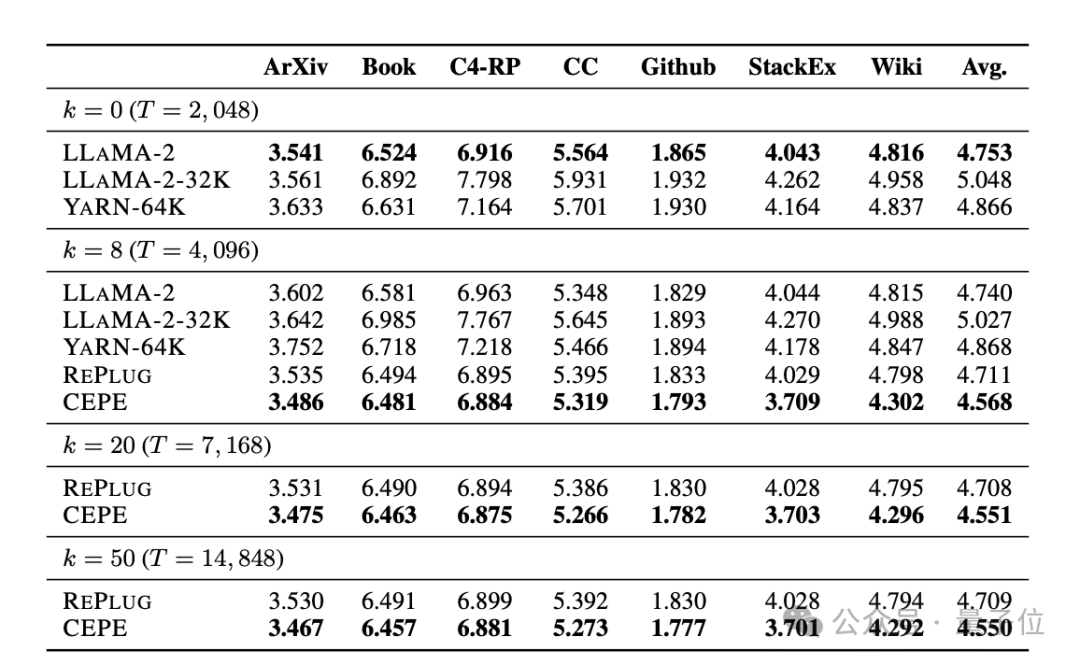
keupayaan mendapatkan semula dipertingkatkan. Seperti yang ditunjukkan dalam jadual berikut:
Dengan menggunakan konteks yang diperoleh semula, CEPE boleh meningkatkan kebingungan model dengan berkesan dan berprestasi lebih baik daripada RePlug.
Perlu diingat bahawa walaupun perenggan k=50 (latihan ialah 60), CEPE akan terus memperbaiki kebingungan.
Ini menunjukkan bahawa CEPE dipindahkan dengan baik ke tetapan peningkatan perolehan, manakala model penyahkod konteks penuh merosot dalam keupayaan ini.
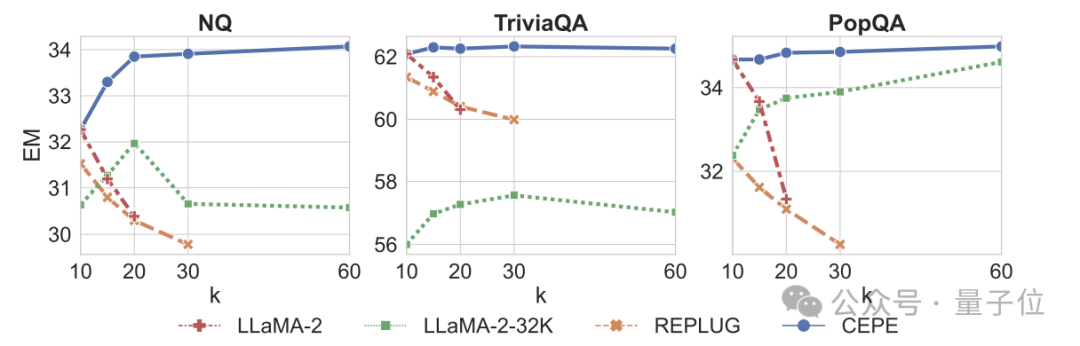
Ketiga, keupayaan soalan dan jawapan domain terbukamelebihi dengan ketara.
Seperti yang ditunjukkan dalam rajah di bawah, CEPE jauh lebih baik daripada model lain dalam semua set data dan parameter perenggan k, dan tidak seperti model lain, prestasi menurun dengan ketara apabila nilai k menjadi lebih besar dan lebih besar.
Ini juga menunjukkan CEPE tidak sensitif kepada sejumlah besar perenggan yang berlebihan atau tidak berkaitan.
Jadi untuk diringkaskan, CEPE mengatasi semua tugasan di atas dengan ingatan dan kos pengiraan yang jauh lebih rendah berbanding kebanyakan penyelesaian lain.
Akhir sekali, berdasarkan asas ini, penulis mencadangkan CEPE-Distilled (CEPED) khusus untuk model penalaan arahan.
Ia hanya menggunakan data yang tidak berlabel untuk mengembangkan tetingkap konteks model, menyaring gelagat model yang ditala arahan asal ke dalam seni bina baharu melalui kehilangan perbezaan KL yang dibantu, dengan itu menghapuskan keperluan untuk mengurus data penjejakan arahan konteks panjang yang mahal.
Akhirnya, CEPED boleh mengembangkan tetingkap konteks Llama-2 dan meningkatkan prestasi teks panjang model sambil mengekalkan keupayaan untuk memahami arahan.
Pengenalan pasukan
CEPE mempunyai 3 orang pengarang.
Satu ialah Yan Heguang(Howard Yen), pelajar sarjana dalam sains komputer di Princeton University.
Orang kedua ialah Gao Tianyu, pelajar kedoktoran di sekolah yang sama dan lulusan ijazah sarjana muda dari Universiti Tsinghua.
Mereka semua pelajar pengarang yang sepadan Chen Danqi.

Kertas asal: https://arxiv.org/abs/2402.16617
Pautan rujukan: https://twitter.com/HowardYen1/status/17624745161
Atas ialah kandungan terperinci Kerja baharu oleh pasukan Chen Danqi: Konteks Llama-2 dikembangkan kepada 128k, 10 kali pemprosesan hanya memerlukan 1/6 daripada memori. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!