
Rumah >Peranti teknologi >AI >Biarkan gadis Sora Tokyo menyanyi, Gao Qiqiang menukar suaranya kepada Luo Xiang, dan video penyegerakan bibir watak Alibaba dijana dengan sempurna
Biarkan gadis Sora Tokyo menyanyi, Gao Qiqiang menukar suaranya kepada Luo Xiang, dan video penyegerakan bibir watak Alibaba dijana dengan sempurna

- 王林ke hadapan
- 2024-03-01 11:34:021000semak imbas
Dengan EMO Alibaba, ia menjadi lebih mudah untuk "bergerak, bercakap atau menyanyi" dengan imej yang dijana AI atau sebenar.
Baru-baru ini, model video Vincent yang diwakili oleh OpenAI Sora kembali popular.
Selain video yang dihasilkan teks, sintesis video berpusatkan manusia sentiasa menarik perhatian ramai. Contohnya, fokus pada penjanaan video "kepala pembesar suara", yang matlamatnya adalah untuk menjana ekspresi muka berdasarkan klip audio yang disediakan pengguna.
Pada peringkat teknikal, penjanaan ekspresi memerlukan penangkapan dengan tepat pergerakan wajah pembesar suara yang halus dan pelbagai, yang merupakan cabaran besar untuk tugasan sintesis video yang serupa.
Kaedah tradisional biasanya mengenakan beberapa had untuk memudahkan tugas penjanaan video. Contohnya, sesetengah kaedah menggunakan model 3D untuk mengekang mata utama muka, manakala yang lain mengekstrak urutan gerakan kepala daripada video mentah untuk membimbing gerakan keseluruhan. Walaupun pengehadan ini mengurangkan kerumitan penjanaan video, mereka juga mengehadkan kekayaan dan keaslian ekspresi muka akhir.
Dalam kertas kerja baru-baru ini yang diterbitkan oleh Ali Intelligent Computing Research Institute, para penyelidik menumpukan pada penerokaan hubungan halus antara isyarat audio dan pergerakan muka untuk meningkatkan keaslian, keaslian dan ekspresi video kepala pembesar suara.
Penyelidik telah mendapati bahawa kaedah tradisional sering gagal menangkap dengan secukupnya ekspresi muka dan gaya unik penceramah yang berbeza. Oleh itu, mereka mencadangkan rangka kerja EMO (Emote Portrait Alive), yang secara langsung memaparkan ekspresi muka melalui kaedah sintesis audio-video tanpa menggunakan model 3D perantaraan atau tanda tempat muka.

paper Tajuk: Emo: Potret Emote Alive- Menjana Video Potret Ekspresif dengan Model Penyebaran Audio2Video di bawah keadaan lemah
Addresspaper Alamat: https://arxiv.org/pdf/2402.17485.pdf
-
Laman utama projek: https://humanaigc.github.io/emote-portrait-alive/
Dari segi kesan, kaedah Ali boleh memastikan peralihan bingkai yang lancar sepanjang video dan mengekalkan identiti yang konsisten, dengan itu menghasilkan prestasi yang berkuasa dan video avatar watak yang lebih realistik adalah jauh lebih baik daripada kaedah SOTA semasa dari segi ekspresif dan realisme.
Sebagai contoh, EMO boleh membuatkan watak gadis Tokyo yang dihasilkan oleh Sora menyanyikan lagu "Don't Start Now" yang dinyanyikan oleh penyanyi wanita dwi-negara British/Albania, Dua Lipa.  EMO menyokong lagu dalam pelbagai bahasa termasuk bahasa Inggeris dan Cina Ia boleh mengenal pasti perubahan tonal audio secara intuitif dan menjana avatar watak AI yang dinamik dan ekspresif. Sebagai contoh, biarkan wanita muda yang dihasilkan oleh model lukisan AI ChilloutMix menyanyikan "Melody" oleh Tao Zhe.
EMO menyokong lagu dalam pelbagai bahasa termasuk bahasa Inggeris dan Cina Ia boleh mengenal pasti perubahan tonal audio secara intuitif dan menjana avatar watak AI yang dinamik dan ekspresif. Sebagai contoh, biarkan wanita muda yang dihasilkan oleh model lukisan AI ChilloutMix menyanyikan "Melody" oleh Tao Zhe. 
EMO juga boleh membenarkan avatar mengikuti lagu-lagu Rap pantas, seperti meminta Leonardo DiCaprio mempersembahkan bahagian "Godzilla" oleh penyanyi rap Amerika Eminem. 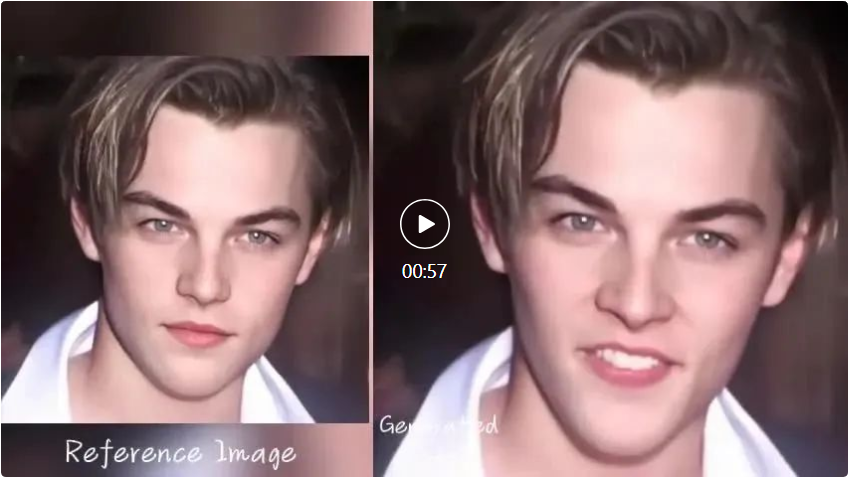 Sudah tentu, EMO bukan sahaja membenarkan watak untuk menyanyi, tetapi juga menyokong audio yang dituturkan dalam pelbagai bahasa, mengubah gaya potret, lukisan serta model 3D dan kandungan yang dijana AI yang berbeza kepada video animasi seperti hidup. Seperti ceramah Audrey Hepburn.
Sudah tentu, EMO bukan sahaja membenarkan watak untuk menyanyi, tetapi juga menyokong audio yang dituturkan dalam pelbagai bahasa, mengubah gaya potret, lukisan serta model 3D dan kandungan yang dijana AI yang berbeza kepada video animasi seperti hidup. Seperti ceramah Audrey Hepburn. 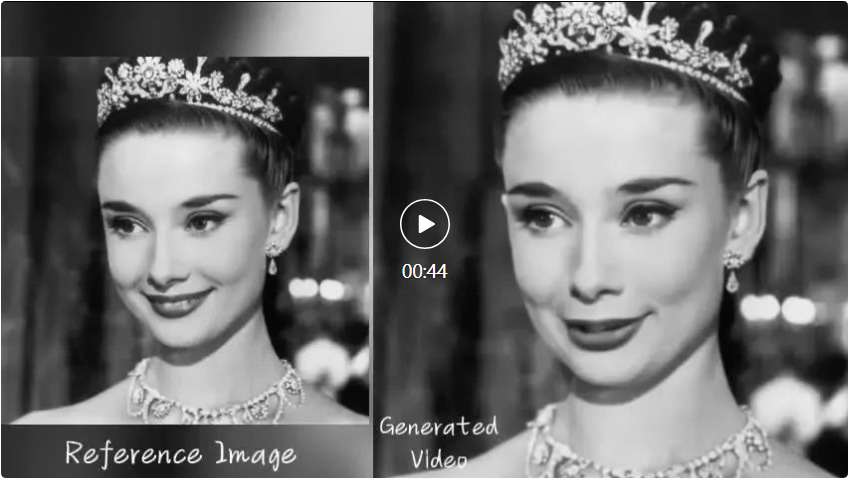
Akhirnya, EMO juga boleh mencapai hubungan antara watak yang berbeza, seperti Gao Qiqiang yang menghubungkan dengan Teacher Luo Xiang dalam "Cyclone". 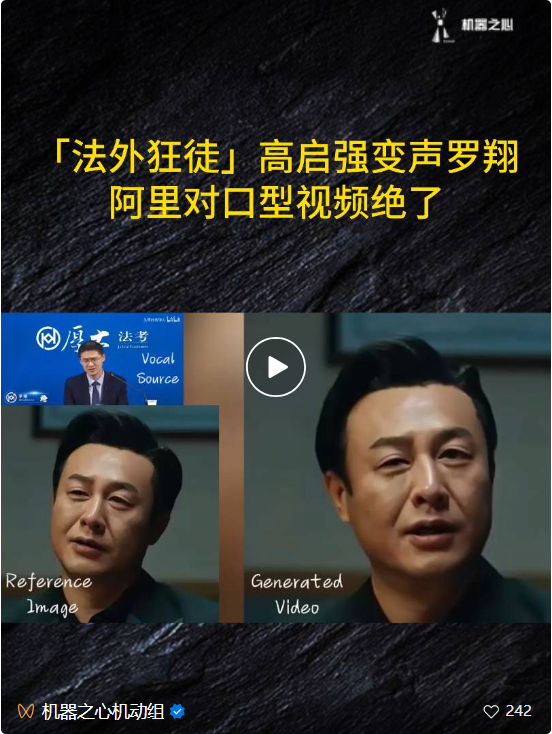
Gambaran Keseluruhan Kaedah
Memandangkan satu imej rujukan potret watak, kaedah kami boleh menjana video yang disegerakkan dengan klip audio pertuturan input, mengekalkan pergerakan kepala watak yang sangat semula jadi dan ekspresi jelas serta konsisten dengan perubahan nada audio suara yang disediakan . Dengan mencipta siri video berlatarkan yang lancar, model ini membantu menjana video panjang potret bercakap dengan identiti yang konsisten dan gerakan koheren, yang penting untuk aplikasi dunia sebenar. Gambaran keseluruhan kaedah
Rangkaian Paip
ditunjukkan dalam rajah di bawah. Rangkaian tulang belakang menerima berbilang bingkai input berpotensi hingar dan cuba untuk menyatukannya ke dalam bingkai video berturut-turut pada setiap langkah masa Rangkaian tulang belakang mempunyai konfigurasi struktur UNet yang serupa dengan versi SD 1.5 yang asal, khususnya
seperti sebelumnya berfungsi dengan cara yang sama, untuk memastikan kesinambungan antara bingkai yang dihasilkan, rangkaian tulang belakang membenamkan modul temporal.
Untuk mengekalkan ketekalan ID potret dalam bingkai yang dijana, penyelidik menggunakan struktur UNet selari dengan rangkaian tulang belakang, yang dipanggil ReferenceNet, yang memasukkan imej rujukan untuk mendapatkan ciri rujukan.
Untuk memacu pergerakan watak semasa bercakap, penyelidik menggunakan lapisan audio untuk mengekodkan ciri bunyi.
Untuk menjadikan pergerakan watak pertuturan boleh dikawal dan stabil, penyelidik menggunakan pengesan muka dan lapisan halaju untuk menyediakan keadaan yang lemah.
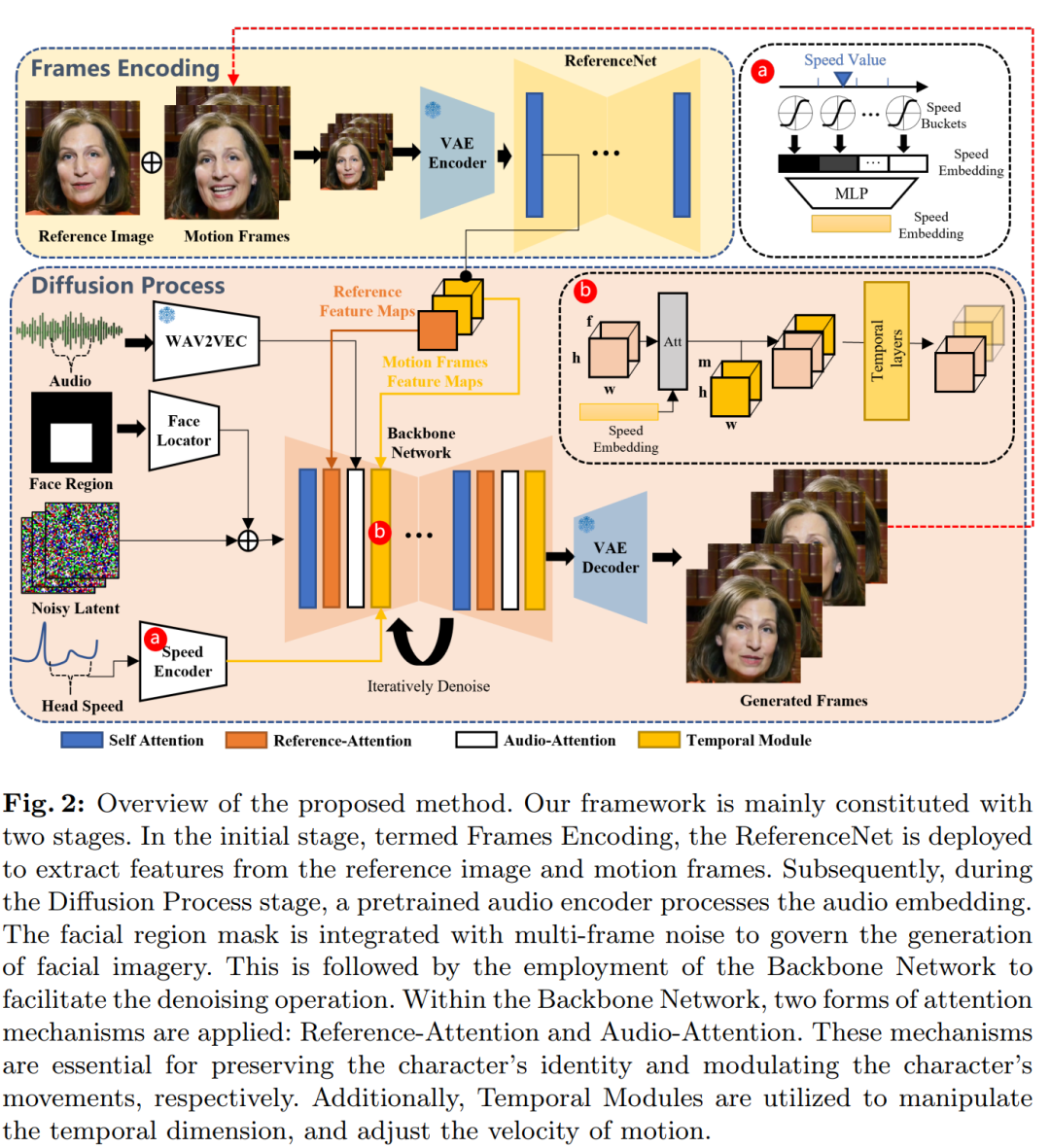
Untuk rangkaian tulang belakang, penyelidik tidak menggunakan benam pembayang, jadi mereka melaraskan lapisan perhatian silang dalam struktur SD 1.5 UNet kepada lapisan perhatian rujukan. Lapisan yang diubah suai ini akan mengambil ciri rujukan yang diperoleh daripada ReferenceNet sebagai input dan bukannya pembenaman teks.
Strategi latihan
Proses latihan terbahagi kepada tiga peringkat:
Peringkat pertama ialah imej pra-latihan, di mana rangkaian tulang belakang, ReferenceNet dan penyetempat muka dimasukkan ke dalam proses latihan rangkaian tulang belakang dilatih dalam bingkai tunggal Sebagai input, ReferenceNet memproses bingkai yang berbeza, dipilih secara rawak daripada klip video yang sama. Kedua-dua Backbone dan ReferenceNet memulakan pemberat daripada SD mentah.
Pada peringkat kedua, penyelidik memperkenalkan latihan video, menambah modul temporal dan lapisan audio, dan sampel n+f bingkai berturut-turut daripada klip video, di mana n bingkai pertama ialah bingkai gerakan. Modul masa memulakan pemberat daripada AnimateDiff.
Peringkat terakhir mengintegrasikan lapisan kelajuan, dan penyelidik hanya melatih modul masa dan lapisan kelajuan dalam peringkat ini. Pendekatan ini dilakukan dengan sengaja mengabaikan lapisan audio semasa latihan. Kerana kekerapan ekspresi pembesar suara, pergerakan mulut dan pergerakan kepala dipengaruhi terutamanya oleh audio. Oleh itu, nampaknya terdapat korelasi antara unsur-unsur ini, dan model mungkin memacu pergerakan watak berdasarkan isyarat halaju dan bukannya audio. Keputusan eksperimen menunjukkan bahawa melatih lapisan kelajuan dan lapisan audio secara serentak melemahkan keupayaan audio untuk memacu pergerakan watak.
Hasil eksperimen
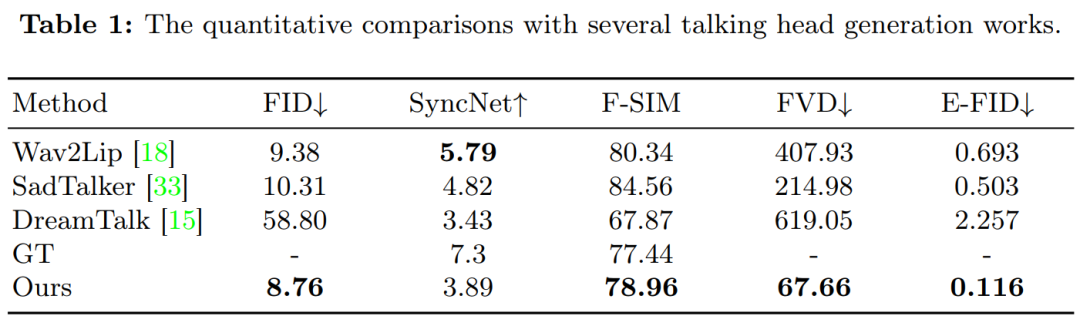
Kaedah yang dibandingkan semasa percubaan termasuk Wav2Lip, SadTalker dan DreamTalk.
Rajah 3 menunjukkan hasil perbandingan antara kaedah ini dan kaedah sebelumnya. Dapat diperhatikan bahawa apabila disediakan dengan imej rujukan tunggal sebagai input, Wav2Lip biasanya mensintesis kawasan mulut yang kabur dan menghasilkan video yang dicirikan oleh pose kepala statik dan pergerakan mata yang minimum. Dalam kes DreamTalk, hasilnya boleh memesongkan wajah asal dan juga mengehadkan julat ekspresi muka dan pergerakan kepala. Berbanding dengan SadTalker dan DreamTalk, kaedah yang dicadangkan dalam kajian ini mampu menjana julat pergerakan kepala yang lebih besar dan ekspresi muka yang lebih jelas.

Kajian ini meneroka penjanaan video avatar dalam pelbagai gaya potret, seperti realistik, anime dan 3D. Watak-watak telah dianimasikan menggunakan input audio vokal yang sama, dan keputusan menunjukkan bahawa video yang dihasilkan menghasilkan penyegerakan bibir yang kira-kira konsisten merentas gaya yang berbeza.

Rajah 5 menunjukkan bahawa kaedah kami boleh menjana ekspresi muka dan tindakan yang lebih kaya apabila memproses audio dengan ciri ton yang jelas. Sebagai contoh, dalam baris ketiga gambar di bawah, nada tinggi akan mencetuskan ekspresi yang lebih kuat dan lebih jelas dalam watak. Selain itu, bingkai gerakan membolehkan anda memanjangkan video yang dijana, iaitu menjana video berdurasi lebih lama berdasarkan panjang audio input. Seperti yang ditunjukkan dalam Rajah 5 dan 6, kaedah kami mengekalkan identiti watak dalam urutan lanjutan walaupun semasa pergerakan besar.


Jadual 1 Keputusan menunjukkan kaedah ini mempunyai kelebihan yang ketara dalam penilaian kualiti video:
Atas ialah kandungan terperinci Biarkan gadis Sora Tokyo menyanyi, Gao Qiqiang menukar suaranya kepada Luo Xiang, dan video penyegerakan bibir watak Alibaba dijana dengan sempurna. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- MySQL 数据库保存 Emoji 表情及特殊符号
- Tesla merancang untuk menubuhkan sebuah kilang kenderaan elektrik di India untuk mengaktifkan industri kenderaan elektrik India
- Gunakan pertandingan untuk menggalakkan pembelajaran dan keputusan ujian untuk membantu industri Internet Perkara mencapai pembangunan berkualiti tinggi
- Industri robot: medan panas seterusnya dalam era AI, salah satu daripada sembilan industri utama pada masa hadapan!