

 Peranti teknologiAIIngin melatih model seperti Sora? You Yang team OpenDiT mencapai 80% pecutan
Peranti teknologiAIIngin melatih model seperti Sora? You Yang team OpenDiT mencapai 80% pecutanIngin melatih model seperti Sora? You Yang team OpenDiT mencapai 80% pecutan

Prestasi hebat Sora pada awal tahun 2024 telah menjadi penanda aras baharu, memberi inspirasi kepada semua yang mempelajari video Wensheng untuk tergesa-gesa mengejar ketinggalan. Setiap penyelidik tidak sabar-sabar untuk meniru keputusan Sora dan bekerja melawan masa.
Menurut laporan teknikal yang didedahkan oleh OpenAI, titik inovasi penting Sora adalah untuk menukar data visual kepada perwakilan bersatu bagi patch, dan menunjukkan kebolehskalaan yang sangat baik melalui gabungan Transformer dan model resapan. Dengan pengeluaran laporan itu, makalah "Model Resapan Skala dengan Transformer" yang dikarang bersama oleh William Peebles, pembangun teras Sora, dan Xie Saining, penolong profesor sains komputer di Universiti New York, telah menarik banyak perhatian daripada penyelidik. Komuniti penyelidikan berharap untuk meneroka cara yang boleh dilaksanakan untuk menghasilkan semula Sora melalui seni bina DiT yang dicadangkan dalam kertas itu.
Baru-baru ini, projek yang dipanggil OpenDiT sumber terbuka oleh pasukan You Yang dari Universiti Nasional Singapura telah membuka idea baharu untuk melatih dan menggunakan model DiT.
OpenDiT ialah sistem yang direka untuk meningkatkan kecekapan latihan dan inferens aplikasi DiT Ia bukan sahaja mudah untuk dikendalikan, tetapi juga pantas dan cekap memori. Sistem ini meliputi fungsi seperti penjanaan teks-ke-video dan penjanaan teks-ke-imej, bertujuan untuk menyediakan pengguna pengalaman yang cekap dan mudah.
Alamat projek: https://github.com/NUS-HPC-AI-Lab/OpenDiT
OpenDiT kaedah pengenalan
AI A pelaksanaan Transformer (DiT) berprestasi tinggi. Semasa latihan, maklumat video dan keadaan dimasukkan ke dalam pengekod yang sepadan masing-masing sebagai input kepada model DiT. Selepas itu, latihan dan pengemaskinian parameter dilakukan melalui kaedah penyebaran, dan akhirnya parameter yang dikemas kini disegerakkan kepada model EMA (Exponential Moving Average). Dalam peringkat inferens, model EMA digunakan secara langsung, mengambil maklumat keadaan sebagai input untuk menjana hasil yang sepadan.
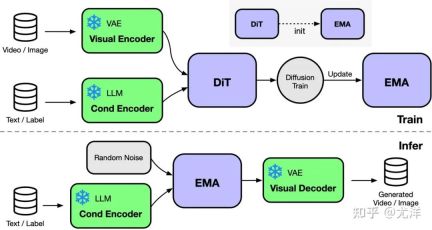
Sumber imej: https://www.zhihu.com/people/berkeley-you-yang
OpenDiT menggunakan strategi selari ZeRO untuk mengedarkan parameter DiT model Preliminary Reduced tekanan. Untuk mencapai keseimbangan yang lebih baik antara prestasi dan ketepatan, OpenDiT juga menggunakan strategi latihan ketepatan campuran. Khususnya, parameter model dan pengoptimum disimpan menggunakan float32 untuk memastikan kemas kini yang tepat. Semasa proses pengiraan model, pasukan penyelidik mereka bentuk kaedah ketepatan campuran float16 dan float32 untuk model DiT untuk mempercepatkan proses pengiraan sambil mengekalkan ketepatan model.
Kaedah EMA yang digunakan dalam model DiT ialah strategi untuk melicinkan kemas kini parameter model, yang boleh meningkatkan kestabilan dan keupayaan generalisasi model dengan berkesan. Walau bagaimanapun, salinan tambahan parameter akan dihasilkan, yang meningkatkan beban pada memori video. Untuk mengurangkan lagi bahagian memori video ini, pasukan penyelidik membahagikan model EMA dan menyimpannya pada GPU yang berbeza. Semasa proses latihan, setiap GPU hanya perlu mengira dan menyimpan bahagiannya sendiri dalam parameter model EMA dan tunggu ZeRO menyelesaikan kemas kini selepas setiap langkah untuk kemas kini segerak.
FastSeq
Dalam bidang model generatif visual seperti DiT, selari jujukan adalah penting untuk latihan jujukan panjang yang cekap dan inferens kependaman rendah.
Walau bagaimanapun, kaedah sedia ada seperti DeepSpeed-Ulysses, Megatron-LM Sequence Parallelism, dsb. menghadapi had apabila digunakan pada tugasan tersebut - sama ada memperkenalkan terlalu banyak komunikasi urutan atau kurang apabila menangani kecekapan selari jujukan berskala kecil.
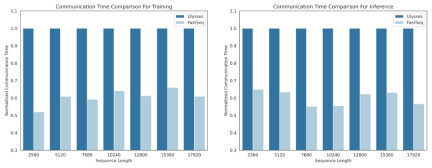
Untuk tujuan ini, pasukan penyelidik mencadangkan FastSeq, jenis selari jujukan baharu yang sesuai untuk jujukan besar dan selari berskala kecil. FastSeq meminimumkan komunikasi jujukan dengan menggunakan hanya dua operator komunikasi setiap lapisan pengubah, memanfaatkan AllGather untuk meningkatkan kecekapan komunikasi, dan secara strategik menggunakan gelang tak segerak untuk bertindih komunikasi AllGather dengan pengiraan qkv untuk terus mengoptimumkan prestasi.
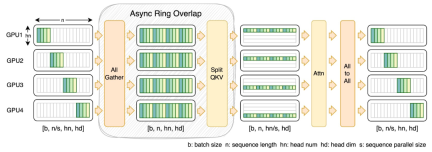
Pengoptimuman operator
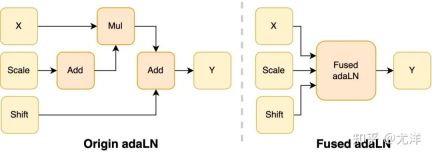
Modul adaLN diperkenalkan ke dalam model DiT untuk menyepadukan maklumat bersyarat ke dalam kandungan visual Walaupun operasi ini penting untuk meningkatkan prestasi model, ia juga membawa sejumlah besar operasi elemen demi elemen dan sering dipanggil. model, yang mengurangkan kecekapan pengiraan Keseluruhan. Untuk menyelesaikan masalah ini, pasukan penyelidik mencadangkan Fused adaLN Kernel yang cekap, yang menggabungkan berbilang operasi menjadi satu, dengan itu meningkatkan kecekapan pengkomputeran dan mengurangkan penggunaan I/O maklumat visual.
Sumber imej: https://www.zhihu.com/people/berkeley-you-yang
Secara ringkasnya, OpenDiT mempunyai kelebihan prestasi berikut:
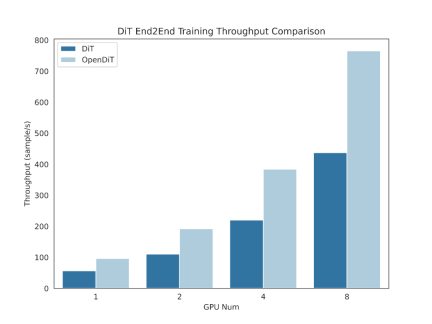
GPU Pecutan sehingga 80%, 50% penjimatan memori
- Direka pengendali cekap, termasuk Fused AdaLN direka untuk DiT, serta FlashAttention, Fused Layernorm dan HybridAdam.
- Menggunakan pendekatan selari hibrid termasuk ZeRO, Gemini dan DDP. Berkongsi model ema juga mengurangkan lagi kos memori.
2. FastSeq: pendekatan selari urutan novel
- direka untuk beban kerja seperti DiT, di mana jujukan biasanya lebih panjang tetapi parameternya lebih kecil.
- Keselarian jujukan intra-nod boleh menjimatkan sehingga 48% volum komunikasi.
- Hapuskan had memori satu GPU dan kurangkan keseluruhan latihan dan masa inferens.
3. Mudah digunakan
- Anda boleh mendapatkan peningkatan prestasi yang besar dengan hanya beberapa baris pengubahsuaian kod.
- Pengguna tidak perlu memahami bagaimana latihan yang diedarkan dilaksanakan.
4. Saluran paip lengkap penjanaan teks-ke-imej dan teks-ke-video
- Penyelidik dan jurutera boleh menggunakan saluran paip OpenDiT dan mengaplikasikannya pada aplikasi praktikal tanpa mengubah suai bahagian selari
- Pasukan penyelidik mengesahkan ketepatan OpenDiT dengan menjalankan latihan teks ke imej pada ImageNet dan mengeluarkan pusat pemeriksaan.
Stallation and Use
to Use Opendit, anda mesti terlebih dahulu memasang prasyarat:
- Python & gt; = 3.10
- pytorch & gt; = 1.13 (disyorkan untuk menggunakan & gt; 2. 0)
- CUDA >= 11.6
Adalah disyorkan untuk mencipta persekitaran baharu menggunakan Anaconda (Python >= 3.10) untuk menjalankan contoh:
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
Pasang OpenDiT :
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
(pilihan tetapi disyorkan) Pasang perpustakaan untuk mempercepatkan latihan dan inferens:
rreeerreee
Anda boleh berlatih model DiT dengan melaksanakan arahan berikut :
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
Semua kaedah pecutan dinyahdayakan secara lalai. Berikut ialah butiran tentang beberapa elemen utama dalam proses latihan:
- plugin: Menyokong pemalam penggalak yang digunakan oleh ColossalAI, zero2 dan ddp. Lalai ialah sifar2, adalah disyorkan untuk mendayakan sifar2.
- mixed_precision: Jenis data latihan ketepatan campuran, lalai ialah fp16.
- grad_checkpoint: Sama ada untuk mendayakan pusat pemeriksaan kecerunan. Ini menjimatkan kos ingatan proses latihan. Nilai lalai ialah Palsu. Adalah disyorkan untuk melumpuhkannya jika terdapat memori yang mencukupi.
- enable_modulate_kernel: Sama ada untuk mendayakan pengoptimuman kernel modulasi untuk mempercepatkan proses latihan. Nilai lalai ialah Palsu dan disyorkan untuk mendayakannya pada GPU
- enable_layernorm_kernel: Sama ada untuk mendayakan pengoptimuman kernel layernorm untuk mempercepatkan proses latihan. Nilai lalai ialah Palsu dan disyorkan untuk mendayakannya.
- enable_flashattn: Sama ada untuk mendayakan FlashAttention untuk mempercepatkan proses latihan. Nilai lalai ialah Palsu dan disyorkan untuk mendayakannya.
- saiz_selari_jujukan: saiz selari jujukan. Keselarian jujukan didayakan apabila menetapkan nilai > 1. Nilai lalai ialah 1, adalah disyorkan untuk melumpuhkannya jika terdapat memori yang mencukupi.
Jika anda ingin menggunakan model DiT untuk inferens, anda boleh menjalankan kod berikut Anda perlu menggantikan laluan pusat pemeriksaan dengan model terlatih anda sendiri.
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
DiT 复现结果
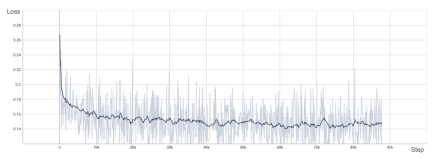
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
Atas ialah kandungan terperinci Ingin melatih model seperti Sora? You Yang team OpenDiT mencapai 80% pecutan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AM
Cara Membina Pembantu AI Peribadi Anda Dengan Huggingface SmollmApr 18, 2025 am 11:52 AMMemanfaatkan kuasa AI di peranti: Membina CLI Chatbot Peribadi Pada masa lalu, konsep pembantu AI peribadi kelihatan seperti fiksyen sains. Bayangkan Alex, seorang peminat teknologi, bermimpi seorang sahabat AI yang pintar, yang tidak bergantung
 AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AM
AI untuk Kesihatan Mental dianalisis dengan penuh perhatian melalui inisiatif baru yang menarik di Stanford UniversityApr 18, 2025 am 11:49 AMPelancaran AI4MH mereka berlaku pada 15 April, 2025, dan Luminary Dr. Tom Insel, M.D., pakar psikiatri yang terkenal dan pakar neurosains, berkhidmat sebagai penceramah kick-off. Dr. Insel terkenal dengan kerja cemerlangnya dalam penyelidikan kesihatan mental dan techno
 Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM
Kelas Draf WNBA 2025 memasuki liga yang semakin meningkat dan melawan gangguan dalam talianApr 18, 2025 am 11:44 AM"Kami mahu memastikan bahawa WNBA kekal sebagai ruang di mana semua orang, pemain, peminat dan rakan kongsi korporat, berasa selamat, dihargai dan diberi kuasa," kata Engelbert, menangani apa yang telah menjadi salah satu cabaran sukan wanita yang paling merosakkan. Anno
 Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Panduan Komprehensif untuk Struktur Data Terbina Python - Analytics VidhyaApr 18, 2025 am 11:43 AMPengenalan Python cemerlang sebagai bahasa pengaturcaraan, terutamanya dalam sains data dan AI generatif. Manipulasi data yang cekap (penyimpanan, pengurusan, dan akses) adalah penting apabila berurusan dengan dataset yang besar. Kami pernah meliputi nombor dan st
 Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AM
Tayangan pertama dari model baru Openai berbanding dengan alternatifApr 18, 2025 am 11:41 AMSebelum menyelam, kaveat penting: Prestasi AI adalah spesifik yang tidak ditentukan dan sangat digunakan. Dalam istilah yang lebih mudah, perbatuan anda mungkin berbeza -beza. Jangan ambil artikel ini (atau lain -lain) sebagai perkataan akhir -sebaliknya, uji model ini pada senario anda sendiri
 AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AM
AI Portfolio | Bagaimana untuk membina portfolio untuk kerjaya AI?Apr 18, 2025 am 11:40 AMMembina portfolio AI/ML yang menonjol: Panduan untuk Pemula dan Profesional Mewujudkan portfolio yang menarik adalah penting untuk mendapatkan peranan dalam kecerdasan buatan (AI) dan pembelajaran mesin (ML). Panduan ini memberi nasihat untuk membina portfolio
 AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AM
AI AI apa yang boleh dimaksudkan untuk operasi keselamatanApr 18, 2025 am 11:36 AMHasilnya? Pembakaran, ketidakcekapan, dan jurang yang melebar antara pengesanan dan tindakan. Tak satu pun dari ini harus datang sebagai kejutan kepada sesiapa yang bekerja dalam keselamatan siber. Janji Agentic AI telah muncul sebagai titik perubahan yang berpotensi. Kelas baru ini
 Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AM
Google Versus Openai: AI berjuang untuk pelajarApr 18, 2025 am 11:31 AMImpak segera berbanding perkongsian jangka panjang? Dua minggu yang lalu Openai melangkah ke hadapan dengan tawaran jangka pendek yang kuat, memberikan akses kepada pelajar A.S. dan Kanada.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

Dreamweaver CS6
Alat pembangunan web visual

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

