
Rumah >Peranti teknologi >AI >Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-28 19:20:031471semak imbas
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramal trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori!
Pengetahuan berkaitan pengenalan
1. Adakah kertas pratonton teratur?
J: Mari kita lihat dahulu rangkaian jujukan, rangkaian saraf graf dan Penilaian dalam tinjauan, perumusan masalah dan kaedah berasaskan pembelajaran mendalam.
2. Adakah ramalan trajektori ramalan tingkah laku tidak sama Penggabungjalinan biasanya merujuk kepada tindakan yang mungkin diambil oleh kereta sasaran, seperti menukar lorong, meletak kenderaan, memotong, memecut, membelok ke kiri, atau membelok ke kanan. berjalan lurus. Trajektori merujuk kepada titik lokasi masa hadapan tertentu dengan maklumat masa.
3 Antara komponen data yang dinyatakan dalam set data Argoverse, apakah yang dimaksudkan oleh label dan sasaran? Adakah label merujuk kepada kebenaran asas dalam tempoh masa yang akan diramalkan Dalam jadual di sebelah kanan, lajur OBJECT_TYPE biasanya mewakili kenderaan pandu sendiri itu sendiri. Set data biasanya menentukan satu atau lebih halangan untuk diramalkan untuk setiap adegan, dan sasaran yang akan diramalkan ini dipanggil sasaran atau agen fokus. Sesetengah set data juga menyediakan label semantik untuk setiap halangan, seperti kenderaan, pejalan kaki atau basikal.
S2: Adakah format data kenderaan dan pejalan kaki sama? Maksud saya, sebagai contoh, satu titik awan mewakili pejalan kaki, dan berpuluh-puluh titik mewakili kenderaan? A: Set data trajektori jenis ini sebenarnya memberikan koordinat xyz bagi titik tengah objek, kedua-dua pejalan kaki dan kenderaan
S3: Set data argo1 dan argo2 hanya menyatakan satu halangan yang diramalkan, bukan? Bagaimana untuk menggunakan kedua-dua set data ini apabila melakukan ramalan berbilang ejen Argo1 hanya menentukan satu halangan, manakala argo2 boleh menentukan sebanyak dua puluh. Walau bagaimanapun, walaupun hanya satu halangan dinyatakan, ini tidak menjejaskan keupayaan model anda untuk meramalkan berbilang halangan.
4. Perancangan laluan secara amnya mempertimbangkan kelajuan rendah dan halangan statik. ? Gambar utama?J: "Ramalkan" trajektori kenderaan sendiri sebagai trajektori perancangan kenderaan sendiri, anda boleh merujuk kepada uniad
5. Adakah ramalan trajektori mempunyai keperluan yang tinggi untuk model dinamik kenderaan? Adakah anda hanya memerlukan matematik dan teori automotif untuk mewujudkan model dinamik kenderaan yang tepat?J: Rangkaian nn pada asasnya tidak diperlukan, berasaskan peraturan perlu difahami
6 Seorang pemula yang samar-samar, dari mana saya harus mula meluaskan pengetahuan saya (saya belum tahu cara menulis kod lagi)J: Mula-mula baca ulasan dan susun peta minda Contohnya, untuk ulasan "Pembelajaran Mesin untuk Ramalan Trajektori Kenderaan Autonomi: Tinjauan komprehensif, Cabaran dan Arah Penyelidikan Masa Depan", pergi ke teks bahasa Inggeris asal
7. . Ramalan dan membuat keputusan Apa pentingnya? modul peraturan?J: Ramalan adalah berdasarkan trajektori kereta lain, dan kawalan adalah berdasarkan trajektori kereta tersebut juga mempengaruhi satu sama lain, jadi ramalan secara amnya berdasarkan peraturan.
S: Beberapa maklumat awam, seperti xnet persepsi Xiaopeng, akan meramalkan trajektori pada masa yang sama Pada masa ini, saya merasakan kerja ramalan diletakkan di bawah modul persepsi, atau kedua-dua modul mempunyai modul ramalan mereka sendiri, dan. matlamatnya berbeza?
J: Mereka akan mempengaruhi satu sama lain, jadi di sesetengah tempat ramalan dan membuat keputusan adalah satu kumpulan. Sebagai contoh, jika trajektori yang dirancang oleh kereta anda sendiri bertujuan untuk menghimpit kereta lain, kereta lain biasanya akan memberi laluan. Oleh itu, beberapa kerja akan menganggap perancangan kenderaan sendiri sebagai sebahagian daripada input model kenderaan lain. Anda boleh merujuk kepada M2I (M2I: Dari Ramalan Trajektori Marginal Berfaktor kepada Ramalan Interaktif Artikel ini mempunyai idea yang serupa Anda boleh mempelajari tentang PiP: Ramalan Trajektori Bermaklumat Perancangan untuk Pemanduan Berautonomi
9.peta garis tengah lorong argoverse. di dalam persimpangan Bagaimana anda mendapatkan tempat tanpa garisan lorongA: Ditanda secara manual
10 Jika anda menggunakan ramalan trajektori untuk menulis kertas, kod kertas manakah yang boleh digunakan sebagai garis dasar? boleh digunakan sebagai garis dasar, Ramai orang menggunakannya11 Pada masa kini, ramalan trajektori pada asasnya bergantung pada peta Jika anda menukar kepada persekitaran peta baharu, adakah model asal tidak lagi boleh digunakan?
A: Ia mempunyai keupayaan generalisasi tertentu, dan kesannya tidak buruk tanpa latihan semula12 Untuk output berbilang modal, apabila memilih trajektori terbaik, adakah ia berdasarkan yang mempunyai nilai kebarangkalian tertinggi
.
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组
Modul asas ramalan trajektori
1. Bagaimana untuk menggunakan HD-Map dalam set data Argoverse. Bolehkah ia digabungkan dengan ramalan gerakan sebagai input untuk membina graf pemandangan pemanduan?
J: Semuanya diliputi dalam kursus ini Anda boleh merujuk kepada Bab 2, yang juga akan diliputi dalam Bab 4. Perbezaan antara graf heterogen dan graf isomorfik: Dalam graf isomorfik, hanya terdapat satu jenis nod, satu. nod. Hanya ada satu hubungan sambungan dengan nod yang lain Contohnya, dalam rangkaian sosial, boleh dibayangkan bahawa nod hanya mempunyai satu jenis "orang" dan tepi hanya mempunyai satu jenis sambungan "pengetahuan". Dan orang sama ada mengenali satu sama lain atau tidak. Tetapi ia juga mungkin untuk membahagikan orang, suka, dan tweet. Kemudian orang mungkin dihubungkan melalui kenalan, orang mungkin dihubungkan melalui suka pada tweet, dan orang mungkin dihubungkan melalui suka pada tweet (laluan meta). Di sini, ungkapan pelbagai nod dan hubungan antara nod memerlukan pengenalan graf heterogen. Dalam graf heterogen, terdapat banyak jenis nod. Terdapat juga banyak jenis hubungan sambungan (tepi) antara nod, dan terdapat lebih banyak jenis kombinasi hubungan sambungan ini (meta-path Hubungan antara nod ini diklasifikasikan ke dalam keterukan, dan hubungan sambungan yang berbeza juga diklasifikasikan ke dalam). keterukan.
2.A-A interaksi mempertimbangkan kenderaan yang manakah berinteraksi dengan kenderaan yang diramalkan?
A: Anda boleh memilih kereta dalam radius tertentu, atau anda boleh mempertimbangkan kereta dengan K jiran terdekat. Anda juga boleh menghasilkan strategi penyaringan jiran heuristik yang lebih maju, malah model boleh mengetahui sama ada dua. kereta adalah sama.
S2: Mari kita pertimbangkan julat tertentu. Di samping itu, pada masa yang manakah kenderaan yang dipilih tiba
J: Sukar untuk mempunyai jawapan standard untuk pilihan jejari Ini pada asasnya menanyakan berapa banyak maklumat jauh yang diperlukan oleh model itu seperti memilih volum Saiz kernel pengumpulan Untuk soalan kedua, peraturan peribadi saya ialah jika anda ingin memodelkan interaksi antara objek pada masa itu, anda harus memilih jiran berdasarkan kedudukan relatif objek pada masa itu.
S3: Dalam kes ini, untuk masa sejarah Adakah semua domain perlu dimodelkan? Kenderaan di sekeliling dalam julat tertentu juga akan berubah pada langkah masa yang berbeza, atau patutkah kita hanya mempertimbangkan maklumat kenderaan di sekeliling pada masa semasa A: Sama ada cara, ia bergantung pada cara anda mereka bentuk model -akhir Apakah kelemahan dalam bahagian ramalan model?
J: Lihat sahaja Operasi pembentuk gerakan adalah agak konvensional Anda akan melihat SA dan CA yang serupa dalam banyak kertas. Banyak model Sota kini agak berat Contohnya, penyahkod akan mempunyai penapisan kitaranA2: Apa yang dilakukannya ialah ramalan marginal daripada ramalan bersama 2. Ramalan dan perancangan dilakukan secara berasingan, tanpa mempertimbangkan interaksi antara ego dan ejen di sekelilingnya; 3. Perwakilan berpusatkan pemandangan digunakan tanpa mengambil kira simetri, dan kesannya tidak dapat dielakkan
S2: Apakah ramalan marginalA: Untuk butiran, sila rujuk pengubah adeganS3: Berkenaan titik ketiga, scene centric tidak Memandangkan simetri, bagaimana anda memahaminyaA: Adalah disyorkan untuk melihat HiVT, QCNet, MTR++ Sudah tentu, reka bentuk simetri tidak mudah dilakukan untuk model hujung ke hujungA2: Boleh difahami bahawa input ialah data pemandangan , tetapi ia akan dimodelkan dalam rangkaian untuk melihat pemandangan di sekelilingnya dengan setiap sasaran sebagai perspektif pusat, supaya anda mendapat pengekodan setiap sasaran yang berpusat pada dirinya sendiri dalam ke hadapan, dan anda boleh mempertimbangkan perbezaan antara pengekodan ini nanti. . arah hadapan kereta
6 Apakah maksud atribut mempunyai_traffic_control dalam peta argoverse
A: Sebenarnya, saya tidak tahu sama ada saya rasa ia merujuk kepada sama ada lorong tertentu terhalang oleh lampu isyarat/tanda berhenti/tanda had laju dan lain-lain kedua-duanya, yang mana lebih baik? Untuk kerugian Laplace berkesan, terdapat beberapa butiran yang perlu diberi perhatian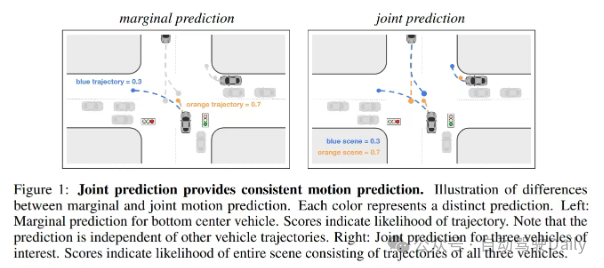 S2: Adakah ini bermakna parameter perlu dilaraskan A: Berbanding dengan kehilangan L1, kerugian Laplace sebenarnya meramalkan satu lagi parameter skala
S2: Adakah ini bermakna parameter perlu dilaraskan A: Berbanding dengan kehilangan L1, kerugian Laplace sebenarnya meramalkan satu lagi parameter skala
S3? : Ya, tetapi nampaknya ini saya tidak tahu apa gunanya jika anda hanya meramalkan satu trajektori. Rasanya seperti redundansi. Saya faham ia sebagai ketidakpastian. Saya tidak tahu sama ada ia betulA:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试
11 Adakah terdapat cara untuk menilai kelancaran skor Jika anda mesti melakukannya
J: Ini memerlukan anda memasukkan input mengalir seperti 0-19 dan 1-20 bingkai dan kemudian membandingkan trajektori yang sepadan. antara dua bingkai. Kuasa dua perbezaan antara markah boleh dikira secara statistik
S2: Apakah penunjuk yang saya cadangkan pada masa ini menggunakan terbitan tertib pertama dan terbitan tertib kedua. Tetapi nampaknya tidak begitu jelas Kebanyakan derivatif tertib pertama dan derivatif tertib kedua tertumpu berhampiran 0.
J: Saya merasakan bahawa perbezaan kuasa dua markah bagi trajektori yang sepadan bagi bingkai berturut-turut adalah mencukupi. Contohnya, jika anda mempunyai n input berturut-turut, jumlahnya dan bahagikan dengan n. Tetapi pemandangan berubah dalam masa nyata dan skor harus berubah secara tiba-tiba apabila terdapat interaksi atau daripada bukan persimpangan kepada persimpangan 12. Bukankah trajektori dalam hivt berskala, seperti ×0.01+10? Pengagihan adalah hampir 0 yang mungkin. Saya hanya menggunakan beberapa kaedah apabila saya melihatnya, dan saya tidak menggunakan beberapa kaedah. Bagaimana untuk menentukan pertukaran?
J: Seragamkan sahaja data. Ia mungkin agak berguna, tetapi mungkin tidak banyak
13 Mengapakah atribut kategori peta dalam HiVT ditambahkan pada atribut berangka selepas dibenamkan, bukannya concat?
J: Tidak banyak perbezaan antara penambahan dan concat, tetapi untuk gabungan pembenaman kategori dan pembenaman berangka, ia sebenarnya setara sepenuhnya
S2: Bagaimanakah kita harus memahami kesetaraan lengkap? A: Selepas menggabungkan kedua-duanya dan kemudian melalui lapisan linear, ia sebenarnya sama dengan membenamkan nilai melalui lapisan linear dan membenamkan kategori melalui lapisan linear, dan kemudian menambah kedua-duanya bersama-sama sebenarnya tidak bermakna. Secara teori, lapisan linear ini boleh disepadukan dengan parameter dalam nn.Embeddding
14 Sebagai pengguna, anda mungkin lebih mengambil berat tentang keperluan perkakasan minimum untuk HiVT untuk digunakan.
J: Saya tidak tahu, tetapi mengikut maklumat yang saya pelajari, saya tidak tahu sama ada itu NV atau pengeluar kereta mana yang menggunakan HiVT untuk meramalkan pejalan kaki, jadi penggunaan sebenar pasti boleh dilaksanakan
15. Ramalan berdasarkan rangkaian penghunian Adakah terdapat sesuatu yang istimewa? Adakah anda mempunyai sebarang cadangan kertas?
J: Penyelesaian yang paling menjanjikan untuk ramalan masa depan berdasarkan penghunian hendaklah yang ini: https://arxiv.org/abs/2308.01471
16 Adakah terdapat kertas cadangan yang mempertimbangkan ramalan trajektori yang dirancang? Adakah untuk mempertimbangkan trajektori yang dirancang kenderaan sendiri apabila meramalkan halangan lain?
J: Set data yang berpotensi awam ini sukar dan secara amnya tidak menyediakan trajektori kenderaan yang dirancang. Pada zaman dahulu, terdapat satu artikel yang dipanggil PiP, Hong Kong Ke Haoran Song. Saya rasa artikel mengenai ramalan bersyarat adalah perkara yang anda mahukan, seperti M2I
17 Adakah terdapat sebarang projek simulasi yang sesuai untuk ujian prestasi algoritma ramalan yang boleh anda pelajari dan rujuk
A (stu): Kertas kerja ini. Terdapat perbincangan: Pilih Simulator Anda dengan Bijak Satu Kajian tentang Simulator Sumber Terbuka untuk Pemanduan Autonomi
18 Bagaimana untuk menganggarkan jumlah memori GPU yang diperlukan Jika anda menggunakan set data Argoverse, bagaimana untuk mengiranya
A : Ia ada kaitan dengan cara menggunakannya dahulu saya boleh menjalankan hivt pada 1070 saya, tetapi kini ia sepatutnya baik pada komputer biasa
Pautan asal: https://mp.weixin.qq.com/ s/EEkr8g4w0s2zhS_jmczUiA
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试
Atas ialah kandungan terperinci Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!