Selamat datang ke bling zoo! 
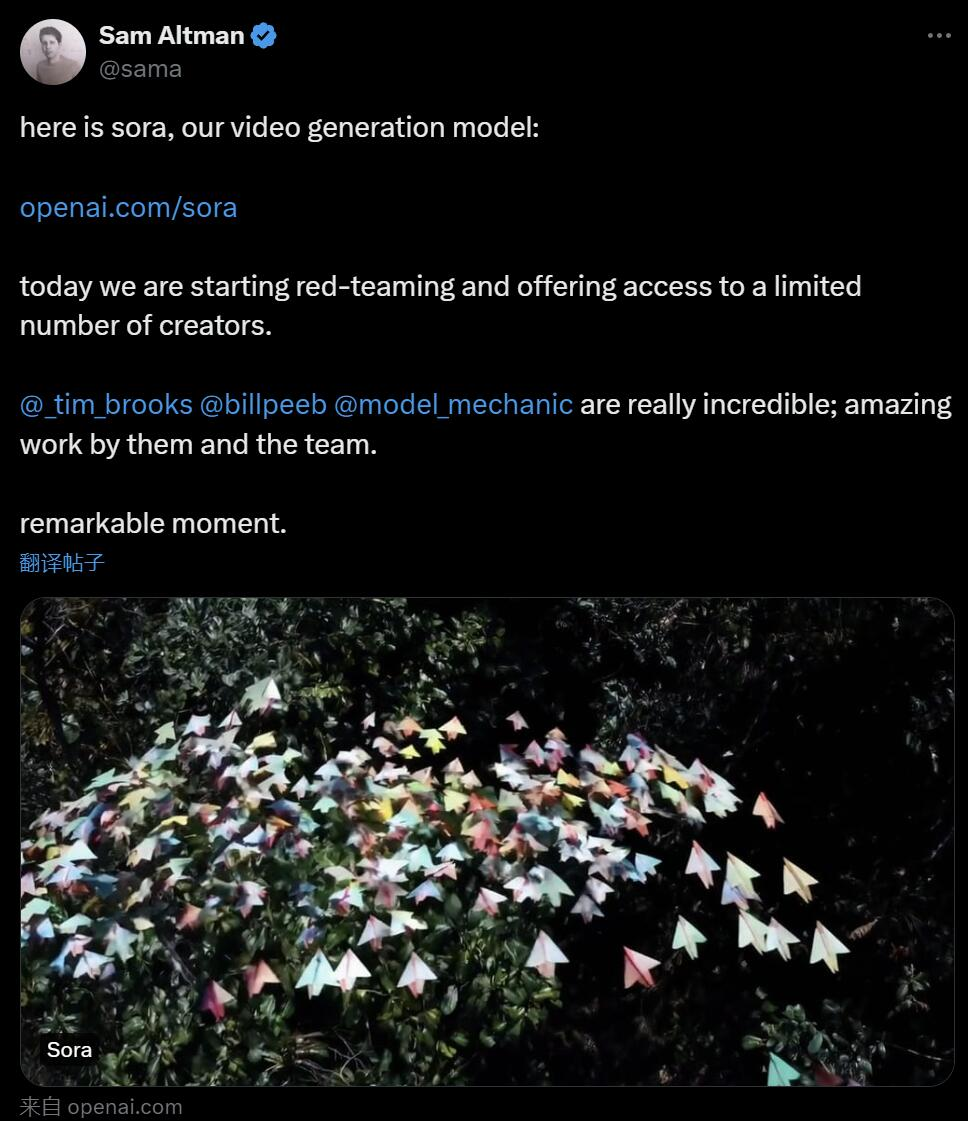
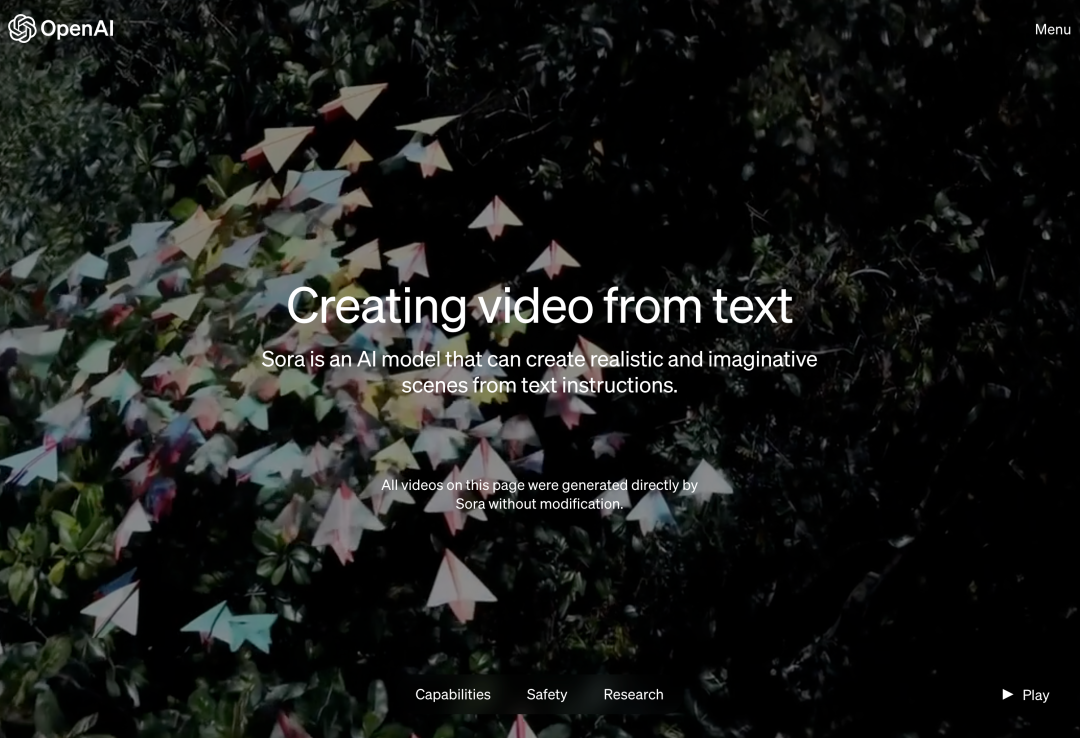
Awal pagi ini waktu Beijing, OpenAI secara rasmi mengeluarkan model generasi teks-ke-video Sora Mengikuti Runway, Pika, Google dan Meta, OpenAI akhirnya menyertai perang dalam bidang penjanaan video. Selepas berita Ultraman Sam dikeluarkan, orang ramai melihat kesan video yang dihasilkan oleh AI yang ditunjukkan oleh jurutera OpenAI buat kali pertama Orang ramai mengeluh: Adakah era Hollywood sudah berakhir? OpenAI mendakwa bahawa diberikan penerangan ringkas atau terperinci atau imej statik, Sora boleh menjana adegan 1080p seperti filem dengan berbilang watak, jenis tindakan dan butiran latar belakang yang berbeza. Apa yang istimewa tentang Sora? Ia mempunyai pemahaman bahasa yang mendalam, mampu mentafsir gesaan dengan tepat dan menjana watak menarik yang menyatakan emosi yang bersemangat. Pada masa yang sama, Sora bukan sahaja dapat memahami permintaan pengguna dalam gesaan, tetapi juga mendapat cara ia wujud dalam dunia fizikal. Dalam blog rasmi, OpenAI menyediakan banyak contoh video yang dihasilkan oleh Sora, menunjukkan hasil yang mengagumkan, sekurang-kurangnya berbanding dengan teknologi video janaan teks sebelumnya. Sebagai permulaan, Sora boleh menjana video dalam pelbagai gaya (cth., fotorealistik, animasi, hitam dan putih) sehingga seminit—lebih lama daripada kebanyakan model teks-ke-video. Video mengekalkan konsistensi yang munasabah, dan mereka tidak selalu tunduk kepada apa yang dipanggil "keanehan AI", seperti objek yang bergerak ke arah yang mustahil secara fizikal. Mula-mula biarkan Sora menjana video tarian naga pada Tahun Naga Cina.
Sebagai contoh, masukkan segera: rakaman sejarah California Gold Rush.
Masukkan gesaan: Pandangan dekat bola kaca dengan taman zen di dalamnya. Di dalam sfera adalah kerdil mencipta corak di dalam pasir.
Masukkan gesaan: Jarak dekat melampau seorang wanita berusia 24 tahun yang berkelip, berdiri di Marrakech semasa Magic Hour, penggambaran filem dalam 70mm, kedalaman medan, warna terang, sinematik.
Masukkan gesaan: Pantulan di tingkap kereta api yang melalui pinggir bandar Tokyo.
Masukkan promosi: kisah hidup robot dalam suasana cyberpunk.
Gambar itu terlalu nyata dan terlalu pelik pada masa yang samaTetapi OpenAI mengakui model semasa juga mempunyai kelemahan. Ia mungkin mengalami kesukaran mensimulasikan fenomena fizikal dengan tepat dalam senario yang kompleks, dan ia mungkin gagal memahami perhubungan sebab dan akibat tertentu. Model ini juga boleh mengelirukan butiran spatial isyarat, seperti kiri dan kanan, dan boleh mengalami kesukaran untuk menerangkan peristiwa dengan tepat dari semasa ke semasa, seperti mengikuti trajektori kamera tertentu. Sebagai contoh, mereka mendapati haiwan dan manusia muncul secara spontan semasa proses penjanaan, terutamanya dalam adegan yang mengandungi banyak entiti. Dalam contoh di bawah, Prompt pada asalnya ialah "Lima anak serigala kelabu bermain dan mengejar antara satu sama lain di jalan batu terpencil yang dikelilingi oleh rumput. Anak anjing itu berlari, melompat, mengejar, menggigit dan bermain antara satu sama lain." Tetapi gambar "salin dan tampal" yang dihasilkan sangat mengingatkan beberapa legenda hantu misteri:
Ada juga contoh berikut Sebelum dan selepas meniup lilin, api tidak berubah sama sekali, ia adalah pelik :
Kami tahu serba sedikit tentang butiran model di belakang Sora. Menurut blog OpenAI, lebih banyak maklumat akan dikeluarkan dalam kertas teknikal berikutnya. Beberapa maklumat asas yang didedahkan dalam blog: Sora ialah model resapan yang menghasilkan video yang pada mulanya kelihatan seperti bunyi statik, dan kemudian secara beransur-ansur mengubah video dengan mengalih keluar hingar dalam beberapa langkah. Penjana imej dan video Midjourney dan Stable Diffusion juga berdasarkan model resapan. Tetapi kita dapat melihat bahawa kualiti video yang dihasilkan oleh OpenAI Sora adalah lebih baik. Sora berasa seperti mencipta video sebenar, manakala model terdahulu daripada pesaing ini berasa seperti animasi henti-gerakan imej yang dijana oleh AI. Sora boleh menjana keseluruhan video sekali gus atau memanjangkan video yang dihasilkan untuk menjadikannya lebih panjang. Dengan meminta model meramalkan berbilang bingkai pada satu masa, OpenAI menyelesaikan masalah mencabar untuk memastikan subjek kekal utuh walaupun ia meninggalkan garis penglihatan buat sementara waktu. Sama seperti model GPT, Sora juga menggunakan seni bina transformer untuk mencapai prestasi kebolehskalaan yang sangat baik. OpenAI mewakili video dan imej sebagai koleksi unit data yang lebih kecil dipanggil patch, setiap patch adalah serupa dengan token dalam GPT. Dengan menyatukan perwakilan data, OpenAI boleh melatih pengubah resapan pada julat data visual yang lebih luas berbanding sebelum ini, termasuk tempoh, resolusi dan nisbah bidang yang berbeza. Sora dibina berdasarkan kajian lepas tentang model DALL・E dan GPT. Ia menggunakan teknologi rekapitulasi daripada DALL・E 3 untuk menjana sari kata yang sangat deskriptif untuk data latihan visual. Hasilnya, model ini dapat mengikuti petunjuk teks pengguna dengan lebih setia dalam video yang dihasilkan. Selain dapat menjana video berdasarkan penerangan teks semata-mata, model ini boleh menjana video berdasarkan imej statik sedia ada dan menghidupkan kandungan imej dengan tepat dan teliti. Model ini juga boleh mengekstrak video sedia ada dan mengembangkannya atau mengisi bingkai yang hilang. Pautan rujukan: https://openai.com/soraAtas ialah kandungan terperinci Pakej hadiah Festival Musim Bunga! OpenAI mengeluarkan model penjanaan video pertamanya, karya agung definisi tinggi 60 saat yang membuatkan netizen kagum. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!